本篇内容将介绍TsMaster中常用的Panel面板控件以及使用Panel控件通过系统变量以及c小程序来修改信号的值,控制报文的发送等。
目录
一、常用的Panel控件介绍
1.1系统——启动停止按钮
1.2 显示控件——文本框
1.3 显示控件——分组框
1.4 读写控件——按钮
1.5读写控件——输入输出框
1.6读写控件——开关
1.7读写控件——选择器
1.8读写控件——文件选择器
1.9显示控件——图形
1.10显示控件——指示灯
1.11显示控件——仪表
1.12显示控件——饼图
二、系统变量的创建与使用
2.1 系统变量的类型
2.2 用户变量的变量类型
2.3 创建系统变量
三、c小程序简单使用,c小程序发送报文
3.1 粘贴代码法
3.2 系统变量与panel,c小程序简单结合使用
一、常用的Panel控件介绍
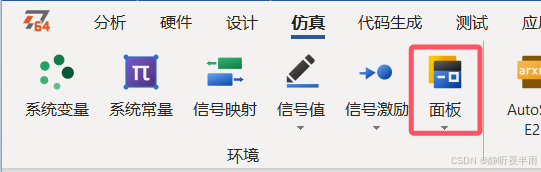
在仿真菜单栏,点击面板下的箭头,创建一个新的面板

如图所示,是刚刚创建的空面板,在面板的右上角有着(工具箱,属性,对象)。
切换到工具箱视角
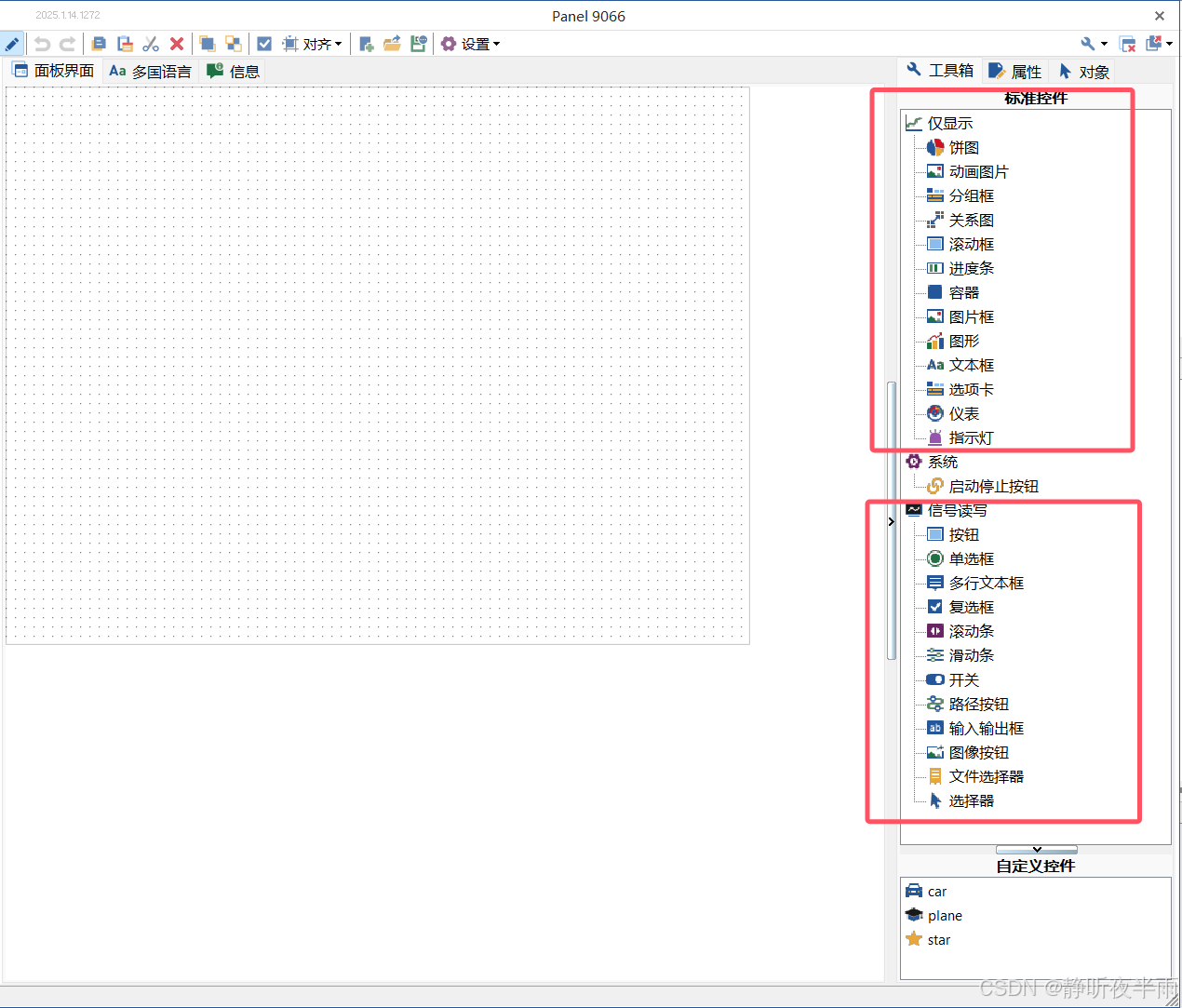
可以看到,工具箱内提供了许多的基础控件,我们可以基于这些系统提供的基础控件来实现一些需要的功能。
添加控件的方法:在工具箱选择空间后,按住鼠标左键不松,拖动到编辑区即可。
每个控件都有着各自的属性设置,当添加一个控件到编辑区之后,鼠标单击刚刚添加的控件即可显示这个控件的属性。
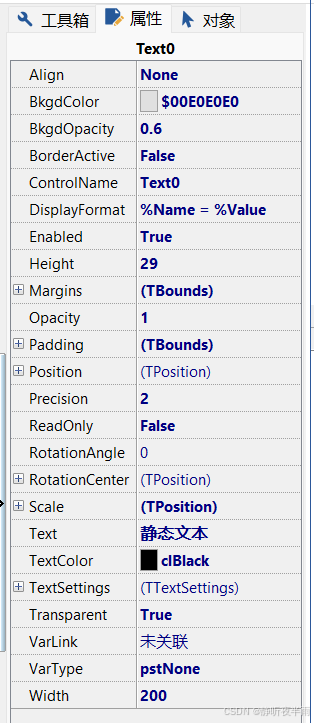
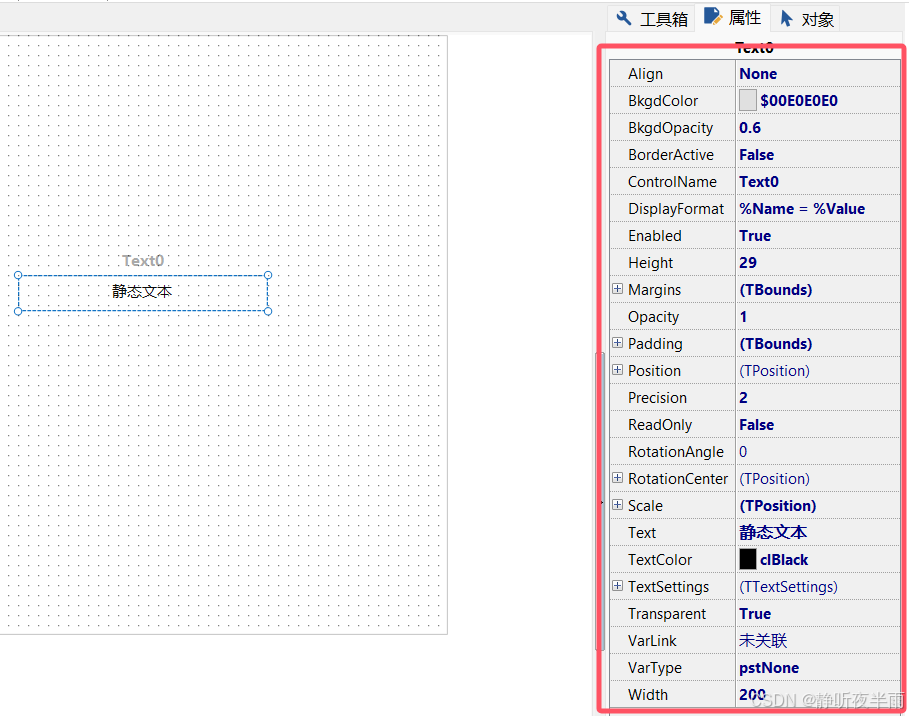
这里以静态文本框的属性界面为例,介绍一下控件的大多数通用属性。
从上往下依次是:
Align,控件的排列设置,可以设置控件在编辑区(工作区)内的排列位置。
bkgdColor,控件的背景颜色
bkgdOpacity,控件的背景不透明度,取值范围0~1(0完全透明,1完全不透明)
BorderActive,边界使能,如果为false,则控件不显示边框,为true显示边框。
Controlname,控件的名字
DisplayFormat,典型设置,没发现有什么作用(有大佬可以告诉我)
Enable,使能属性,如果为true,则可以响应鼠标和按键的操作,为false,则不响应
Height,控件的高度
Margins,控件的边距,用于设置此控件到父控件或者父控件内的其他控件的距离,一般不常用
Opacity,不透明度,同上面的
padding,控件的填充,用于设置的子控件到每个边的距离,一般也不用
Position,设置当前控件对于其父控件的位置
ReadOnly,如果设置为true,则只能显示不能编辑,为false可以编辑
RotationAngle,设置控件的旋转角度
Scale,设置控件的比例,也不怎么用
Text,控件显示的文字
TextColor,显示的文字的颜色
TextSetting,可以设置文本的样式
Transparent,设置透明度使能
VarLink,绑定的对象(可以是系统变量,信号等)
VarType,绑定的对象的类型
Width,控件的宽度
1.1系统——启动停止按钮
此控件的功能十分的粗暴,是用于在Panel面板上控制TsMaster工程的启动与停止的,无需其他额外属性。
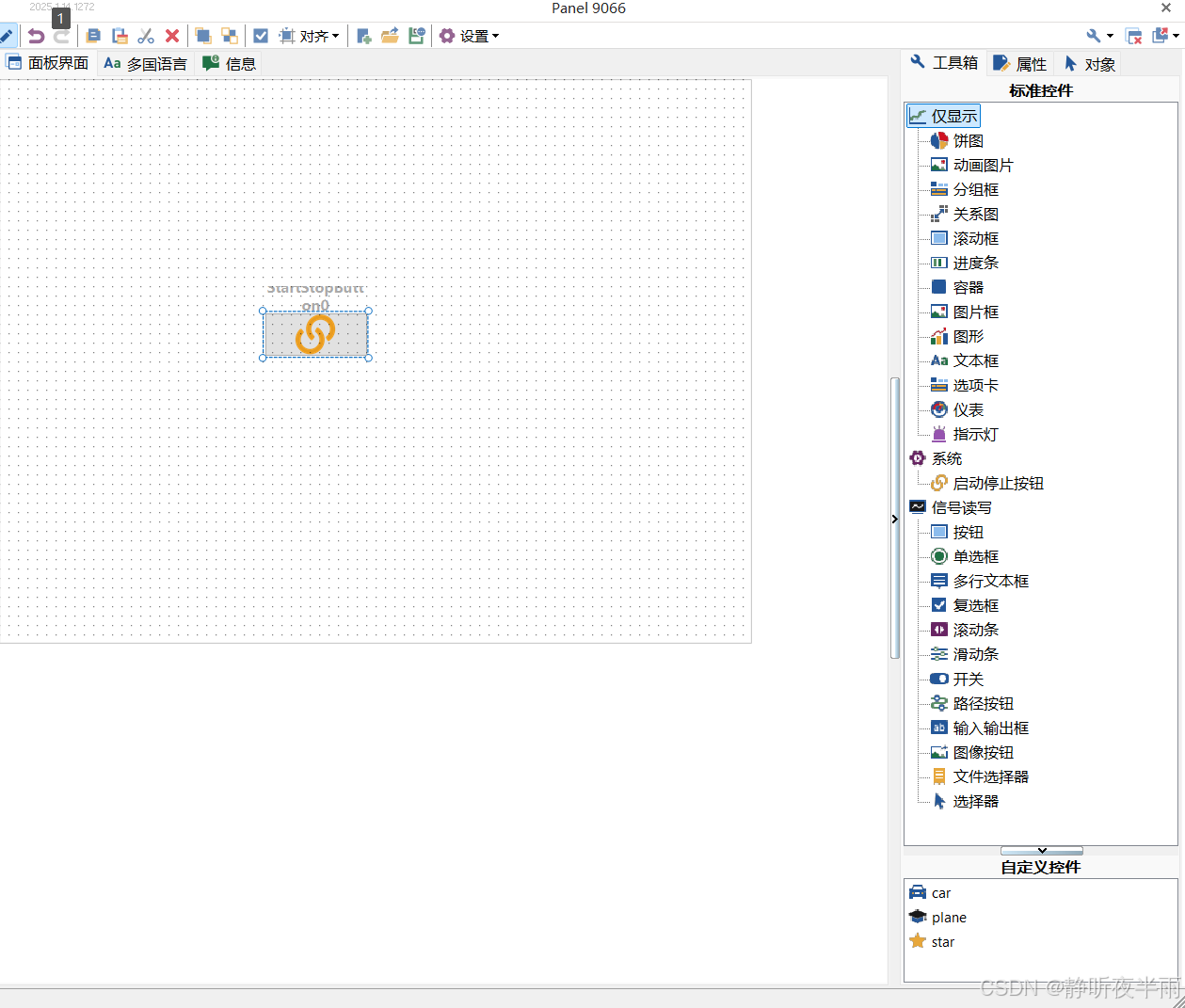
添加一个启动停止按钮在Panel面板上。随后点击左上角的铅笔,退出编辑模式。
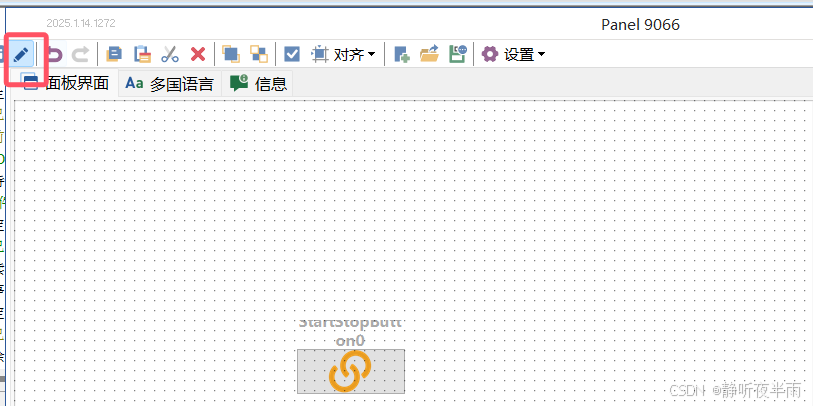
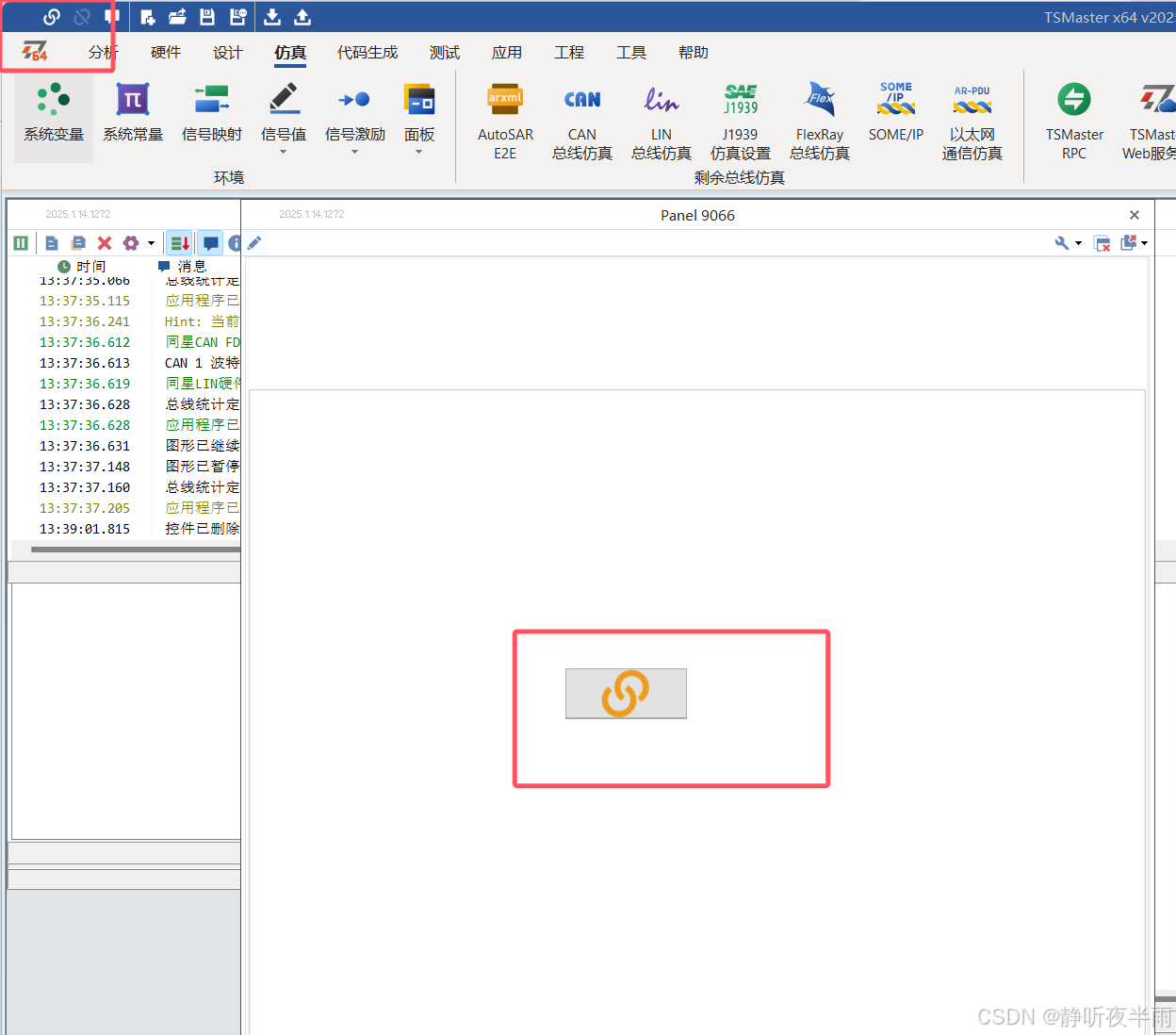
当TS工程处于未启动状态时,Panel控件上的启动停止按钮式一个链接的图标(样式同TS左上角的启动图标)。
当我们点击一下Panel上的这个按钮,TS工程将被启动,并且启动后这个按钮图标将变为断开连接的图标(如图TS左上角的停止按钮)
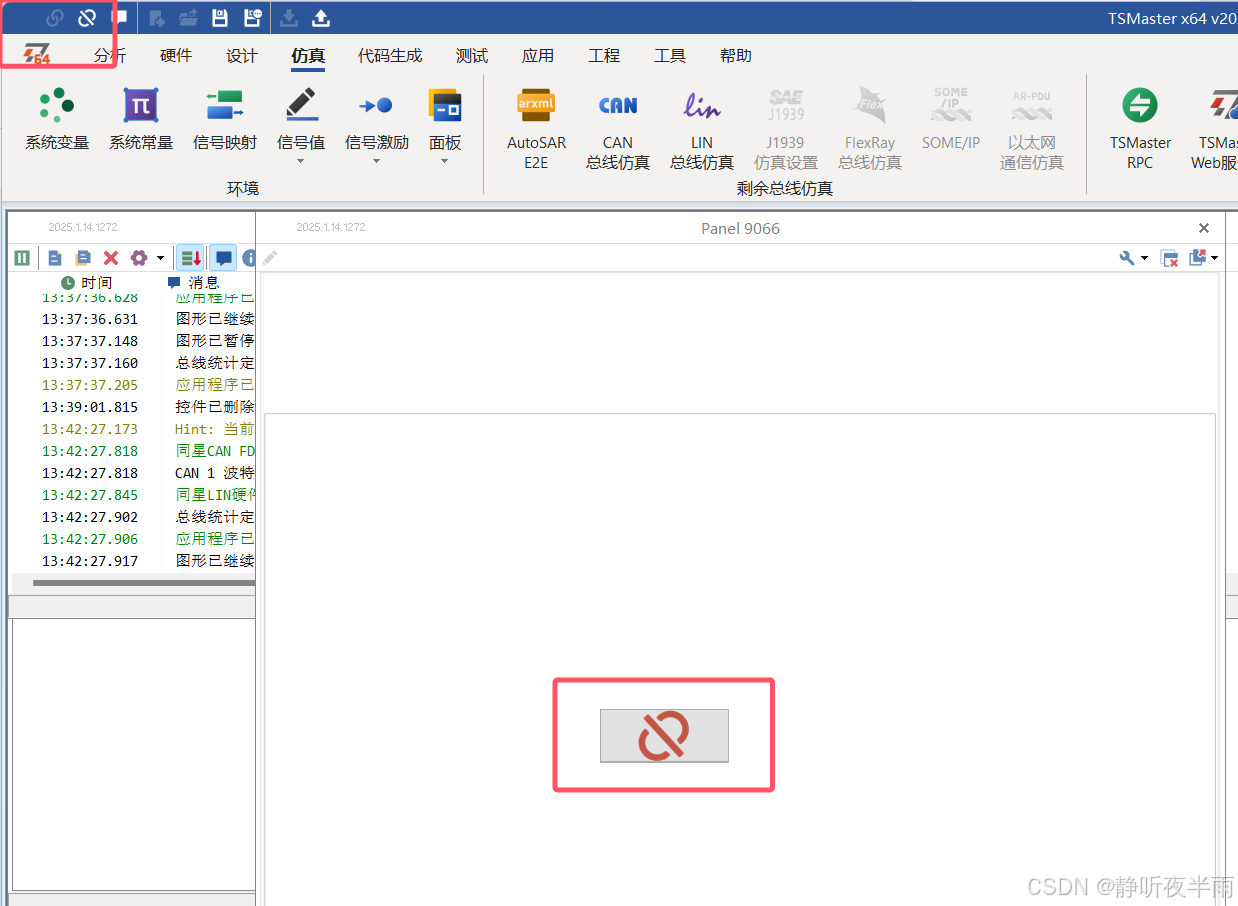
此时再次点击Panel上的这个图标,TS工程将被断开。
1.2 显示控件——文本框
如图控件名称,文本框就是用来显示一段固定的标签文字的。
在属性栏的Text栏目中即可修改文本显示的内容。

修改后回车即可生效。
1.3 显示控件——分组框
此控件作用就是给出一个分组,可以将所需要分组的控件放在一个分组框中,便于提示用户这些控件用于操作一组xxx数据等

1.4 读写控件——按钮
按钮通常用于跟一个bool量或者一个整形变量进行绑定,当按钮按下时,绑定的对象值即为1或者其他设置值,当按钮松开后,绑定的对象值也不会恢复

可以通过设置varLink和vartype属性来设置按钮绑定的对象。
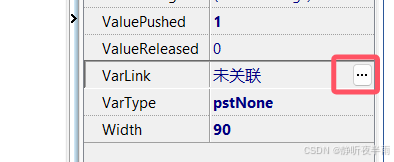
点击选择VarLink属性,VarLink属性后便会出现选择按钮,点击此按钮可选择绑定的对象,这里我以一个事先创建了的系统变量为例。
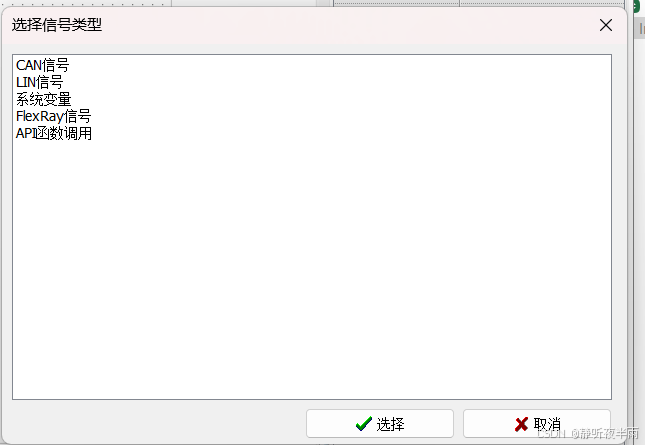
选择对应的对象类型,选择完毕后点击确定
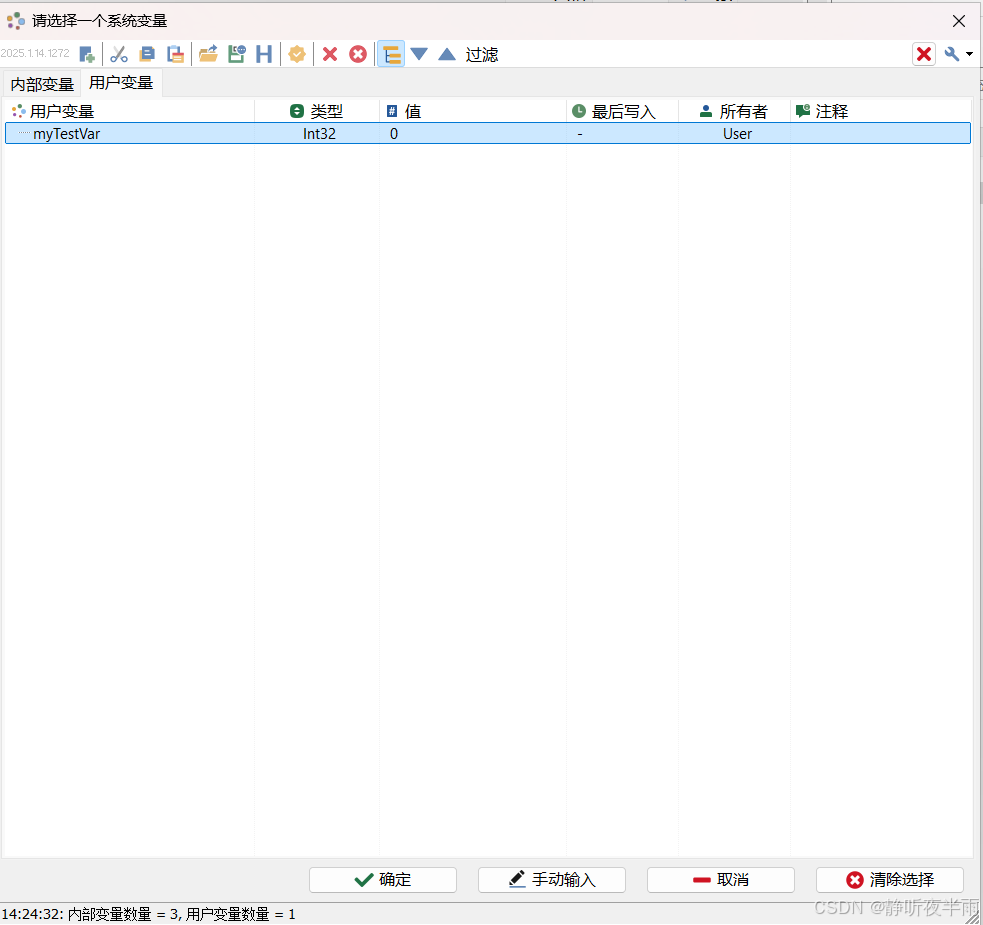
绑定完成,看看效果。

按钮未按下时,对应的变量值为0,按下后松开,变量的值变为了1,且不会恢复为0

其具备一个名为ValuePushed的属性,可以设置当按钮按下时对应的变量改变的值。
1.5读写控件——输入输出框
输入输出框可以用于信息的输入输出,通常适用于输入字符串,输入数字等。
同样的,这里我创建一个输入输出框,并将其绑定为我的系统变量。

当输入0时,我绑定的系统变量值变为0,当输入5时,我绑定的系统变量值变为5

1.6读写控件——开关
开关一般用来跟可以表示两种状态的信号或者变量进行绑定,这个控件具备两个可以修改的属性,
ValueLeft和ValueRight
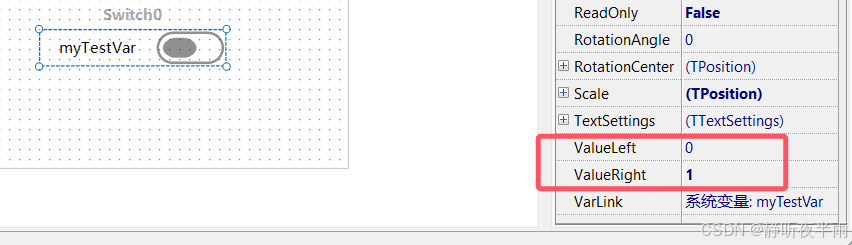
当开关的焦点的左侧时,对应的值为ValueLeft,当开关焦点在右侧时,对应的值为valueRight
如图我的左值和右值分别为0和1。所以当我的开关焦点在左侧时,变量的值为0,在右侧时,变量值为1.
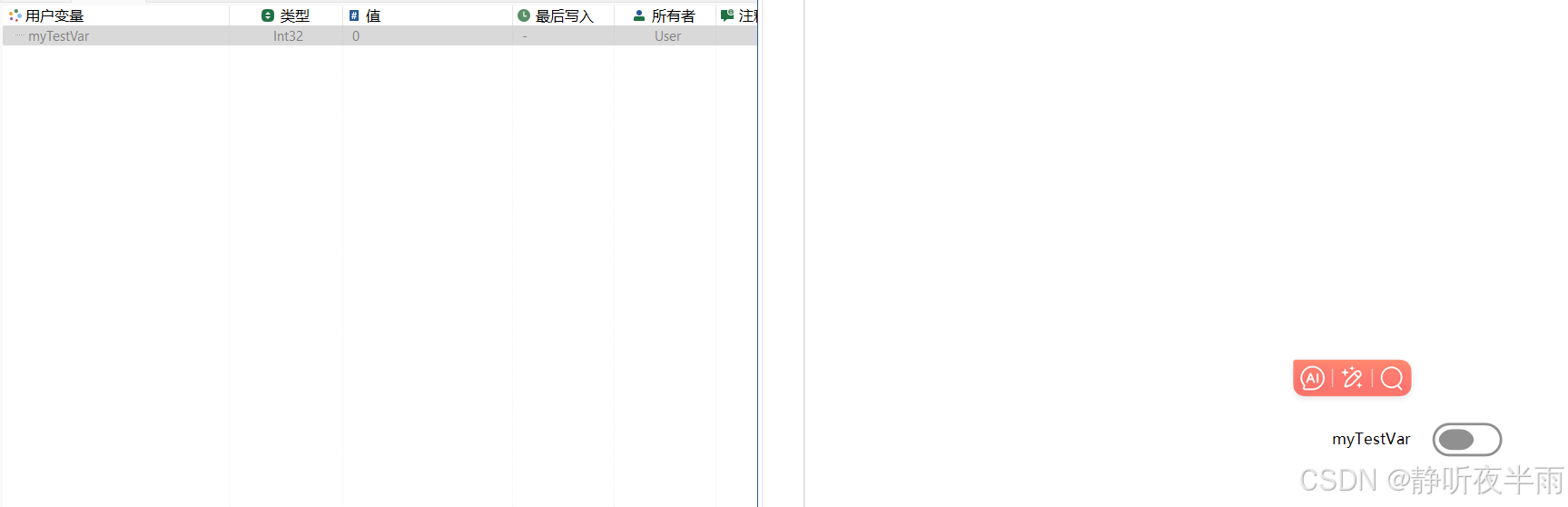
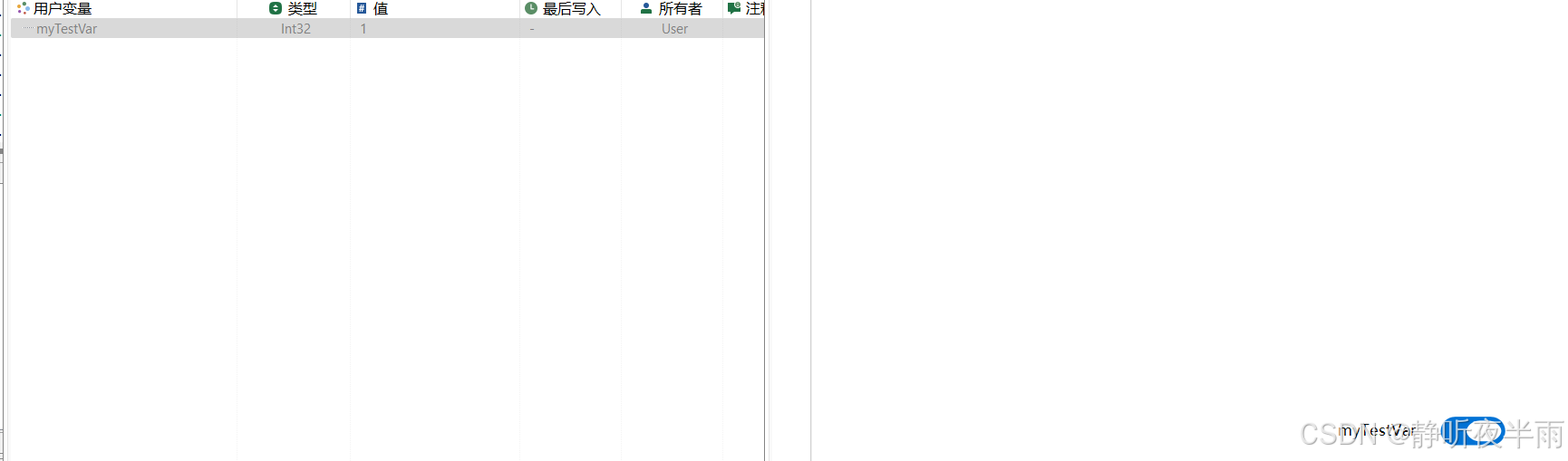
接着,我们可以修改下这个开关的左值和右值看看。

如图,我为这个开关设置了两个新的左值和右值,再次操作开关,对应变量的值也会随之改变。
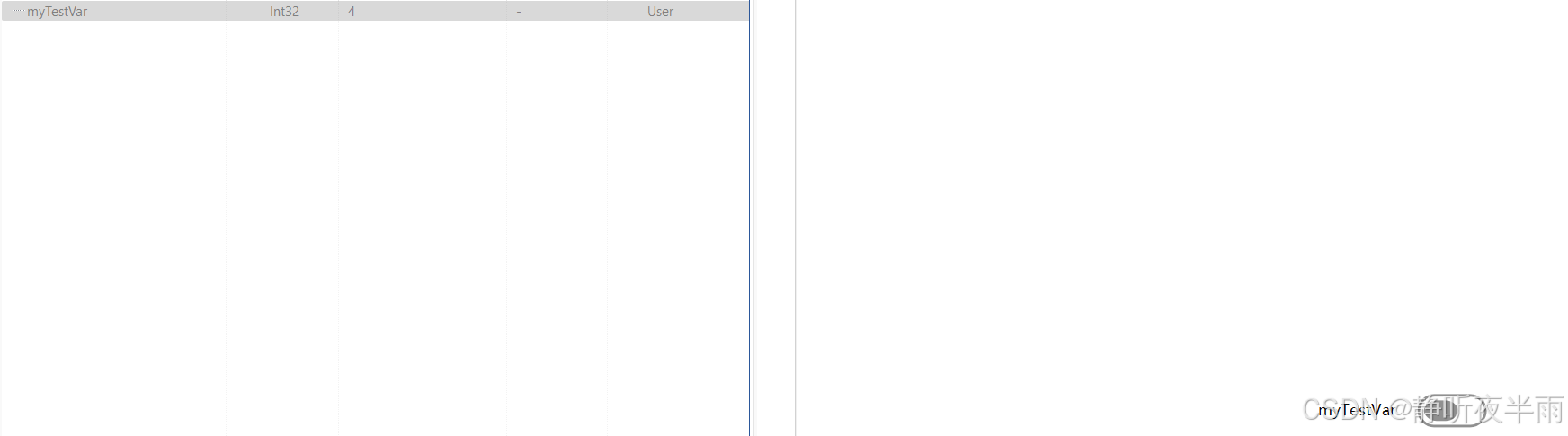
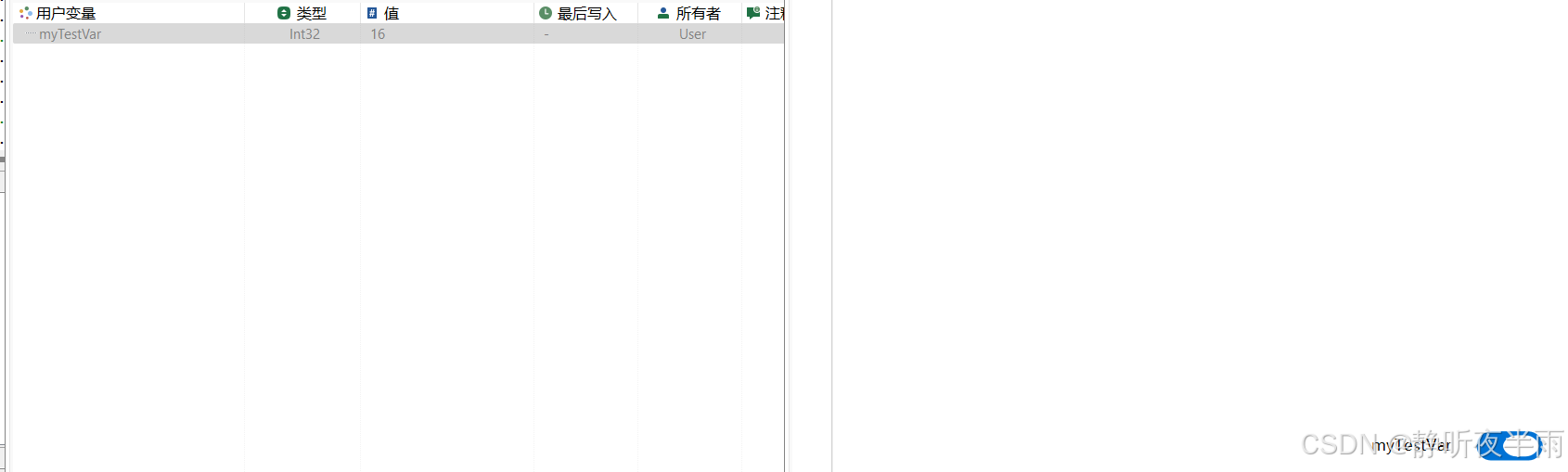
1.7读写控件——选择器
![]()
选择器可以根据绑定的变量(信号,本文中统一使用变量表示)的取值表,生成一个下拉框,并在下拉框中显示对应的取值表。
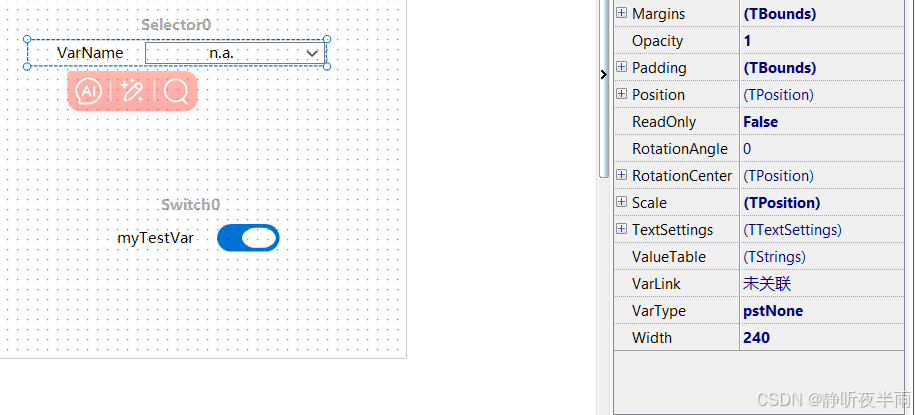
创建一个选择器,并将选择器绑定一个具有取值表的变量。
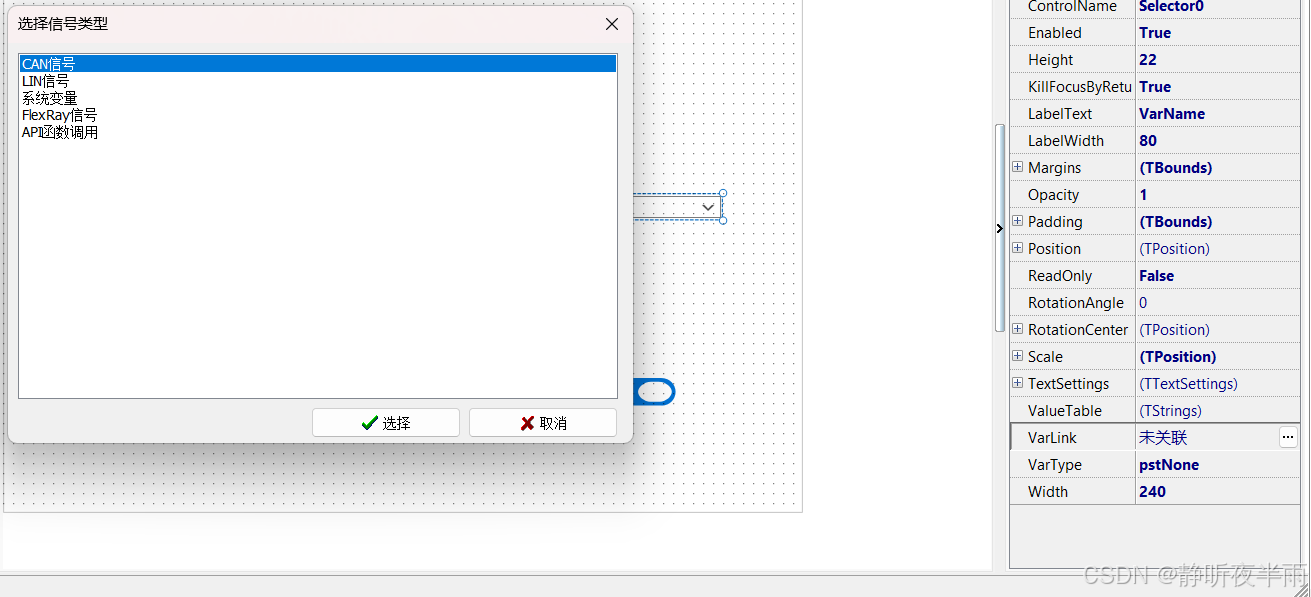
这里我选择绑定一个can信号,
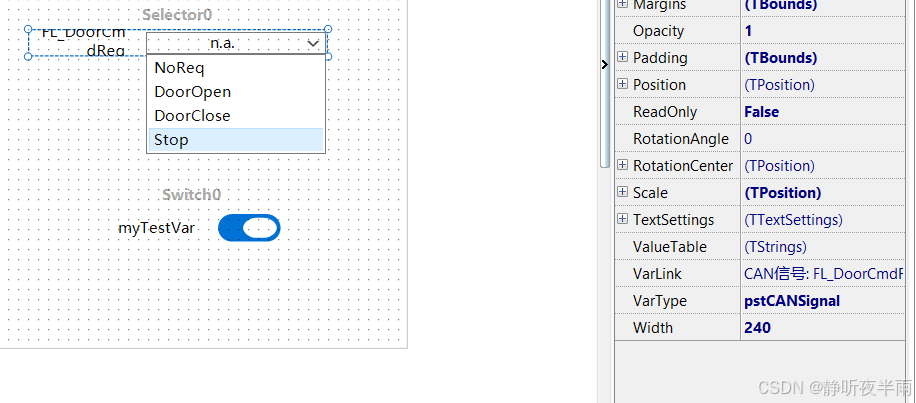
绑定完成后点击下拉箭头,即可看到绑定的变量的取值表,并且当修改下拉选项时,被绑定的变量值也将发生改变。
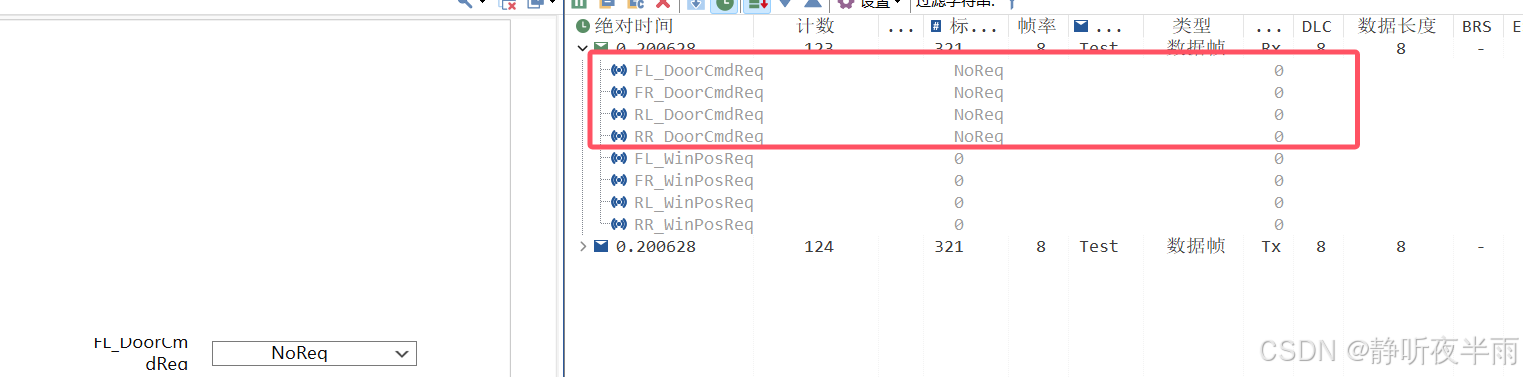
当我的选择器下拉列表选择的时NoReq时,我绑定的CAN信号值也为NoReq(0)
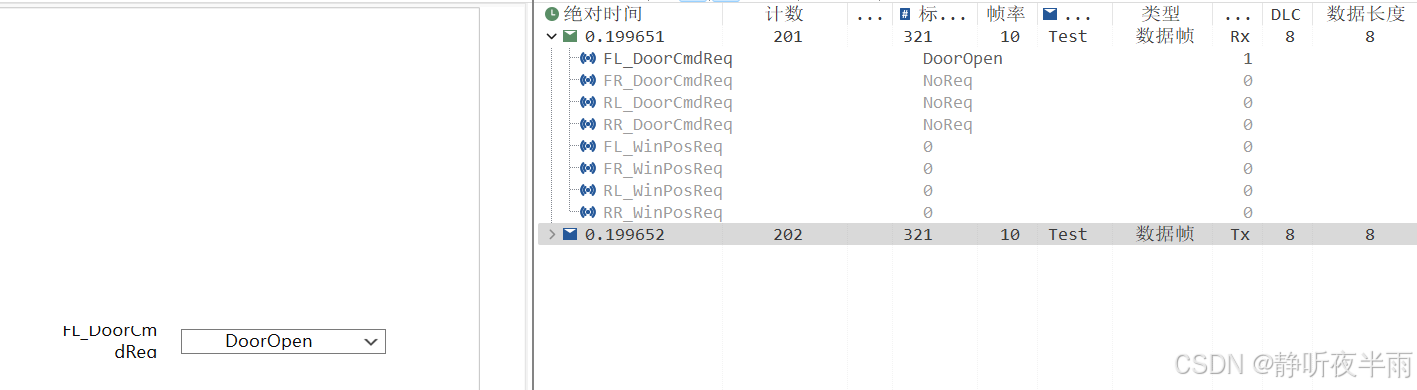
当我将下拉选择器改为doorOpen时,对应的信号值也变为了doorOpen(1)
1.8读写控件——文件选择器
此控件的作用为点击后弹出一个对话框用于选择一个文件,并且会将选择的文件路径返回给绑定的字符串类型变量
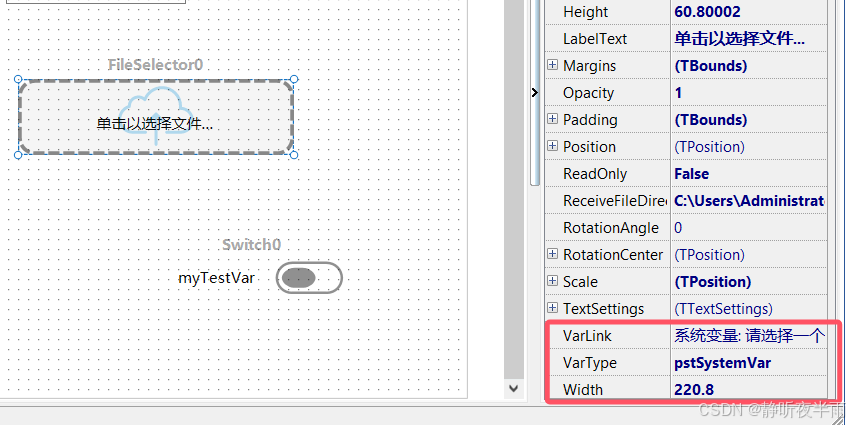
创建一个文件选择器,随后为其绑定一个String类型系统变量

当未选择文件时,路径处为0,随后启动TS工程,点击文件选择器,选择一个文件
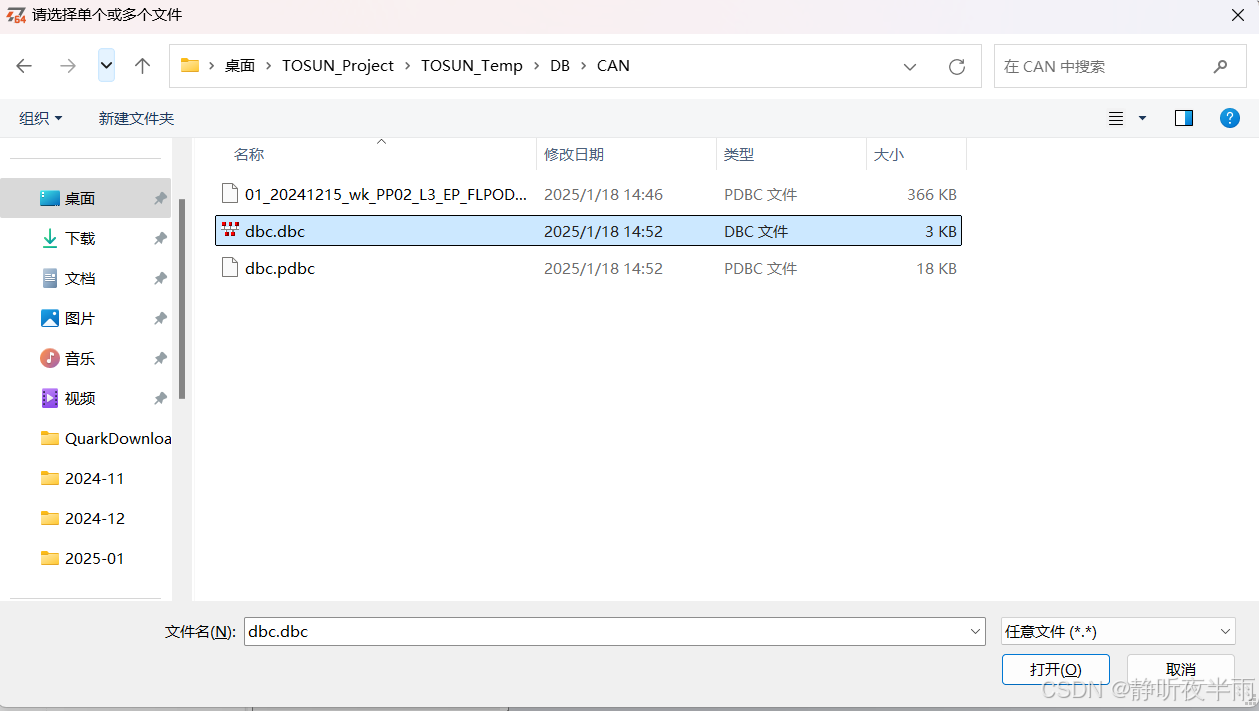
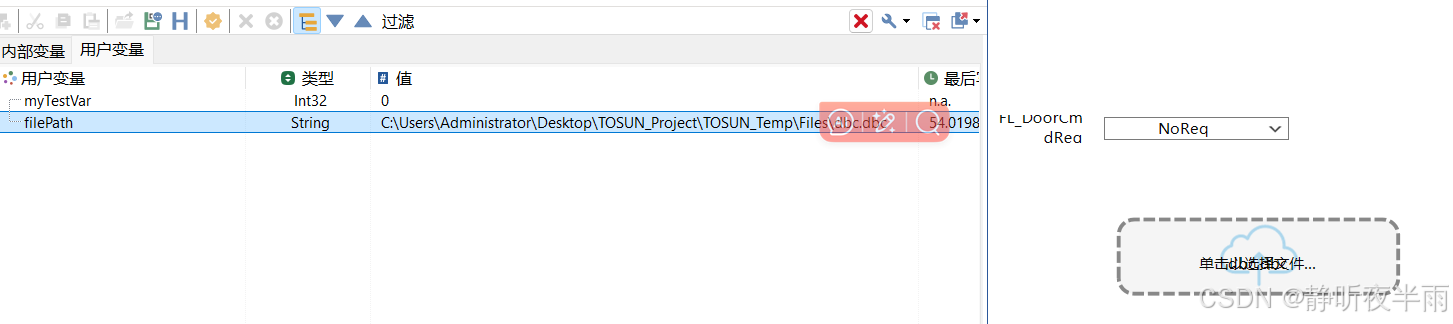
选择完毕后,字符串变量的值就变成了刚刚选择的文件的地址。
1.9显示控件——图形
图形可以当做一个简单的Graphics窗口来使用

图形控件默认是2条信号曲线,如果需要修改信号的数量,可以通过修改SignalCount来设置
通过这个图形的属性我们可以看到,默认编辑的信号索引为0,即为这个图形控件关联变量时,关联的是索引为0的那条曲线(即第一条曲线)

现在我们添加两个信号来观察一下

选择varLink,关联第一个变量。
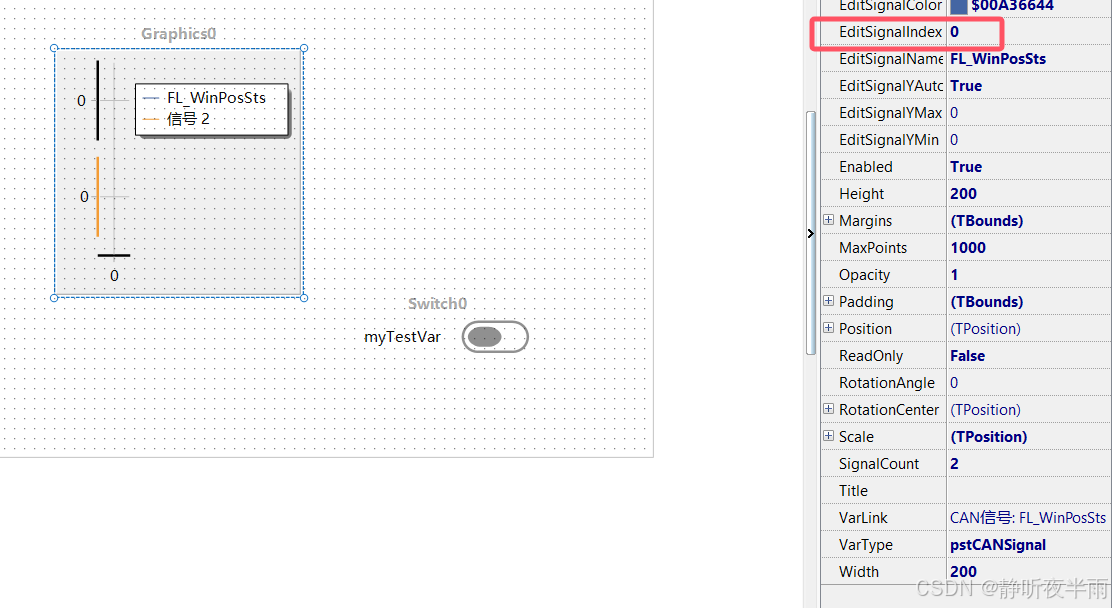
关联完成后,将EditSignalIndex修改为1即可编辑第二条曲线,这里修改一下,然后关联第二个信号
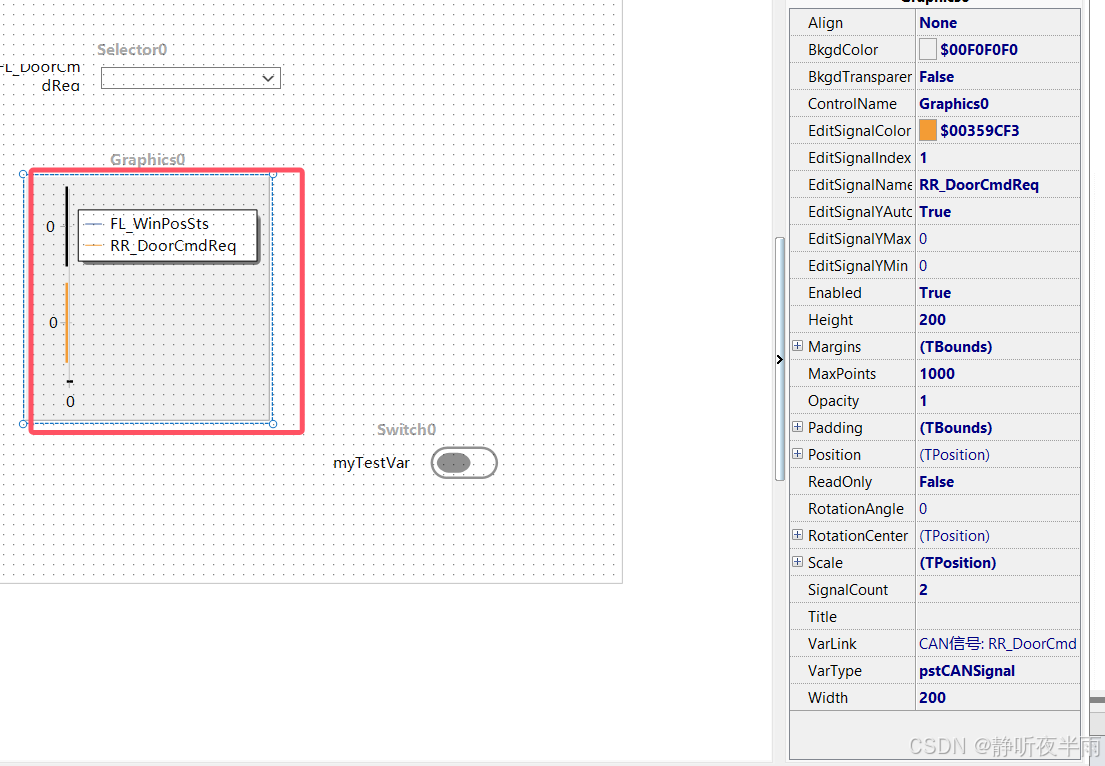
关联完成,可以看到图形上的两条曲线都有了名字
鼠标拖动图形右侧边界,将图形放大一些
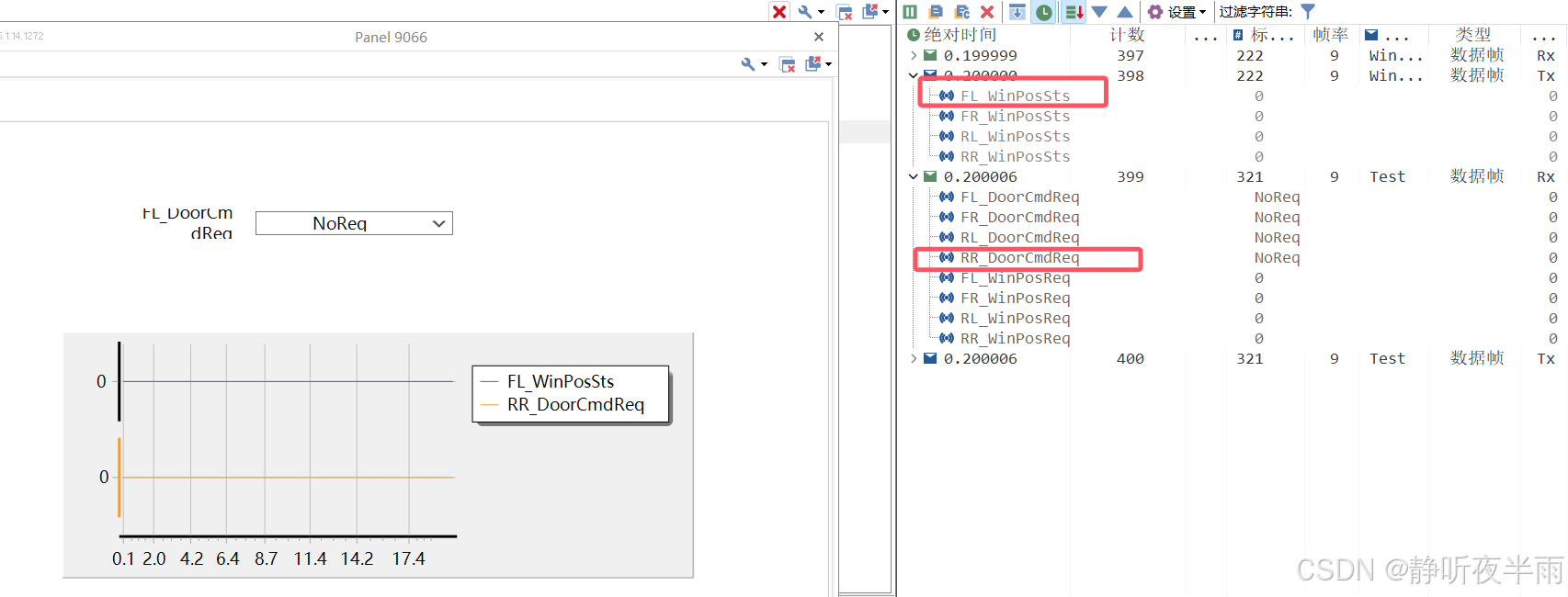
运行工程,当两个信号值都是0的时候,图形上的曲线也保持为0,当这两个信号发生变化之后,图形上的曲线也同步发生了改变。
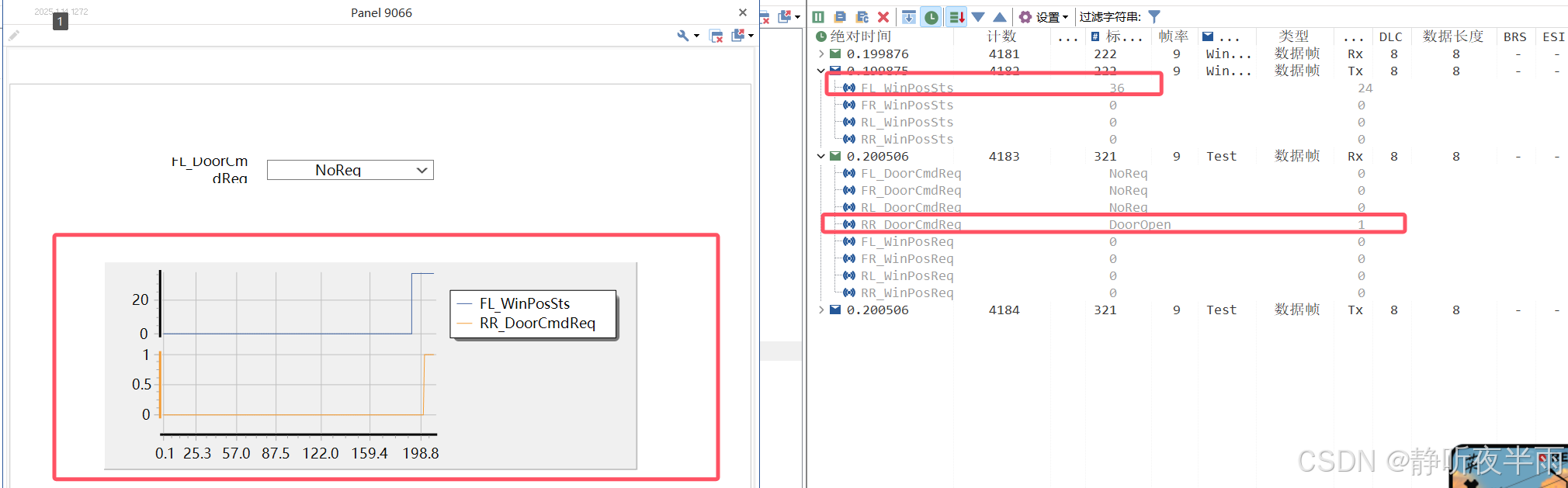
1.10显示控件——指示灯
指示灯是一个非常简单的控件,也主要用来绑定只有两种值的信号,与开关不同的是,它是只读的,用户没法改变他的状态。
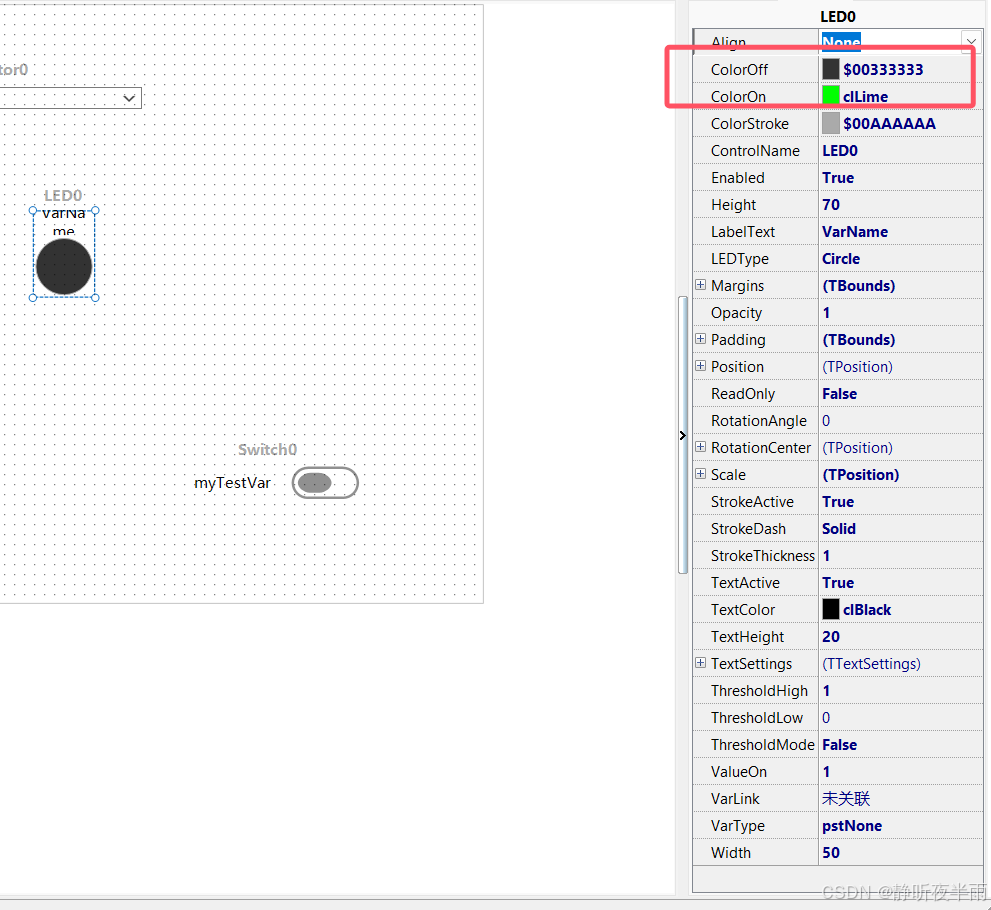
其的属性中,ColorOff用来设置当指示灯关闭时的颜色,Color用来设置当指示灯打开时的颜色。。
ThresholdHigh和ThresholdLow用来设置高低阈值,当ThresholdMode设置为true时,只要绑定的变量值大于等于High值时,指示灯就打开,小于等于Low值时,指示灯就关闭。
ValueOn用来设置指示灯打开时的值(绑定的变量值等于该值时,指示灯亮起),需要ThresholdMode为false的前提下才有效。
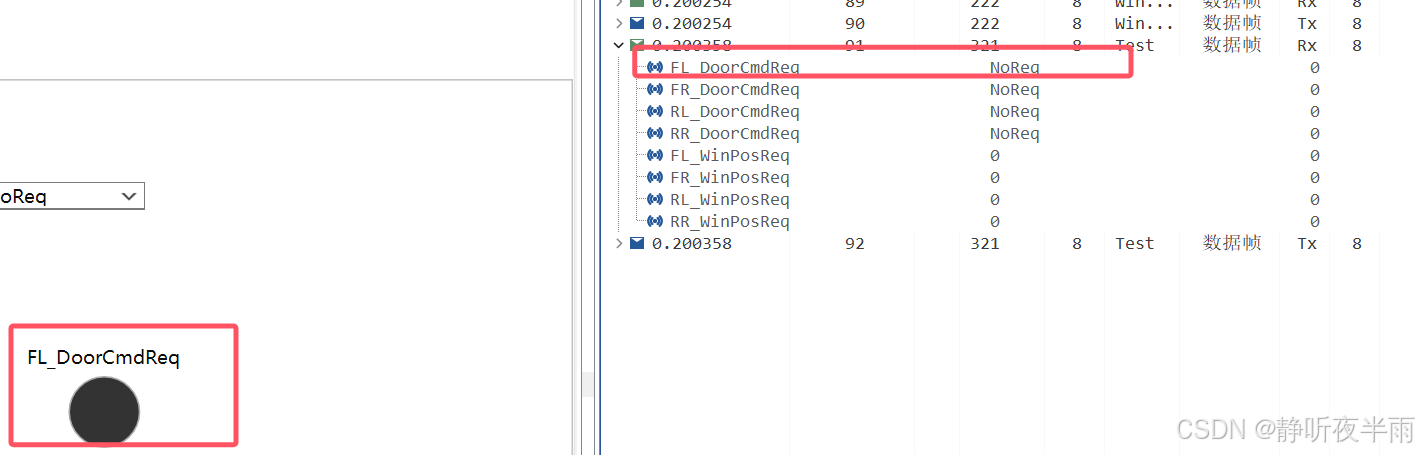
绑定信号后,当信号值为0时,led熄灭,当值为1时,led亮起。
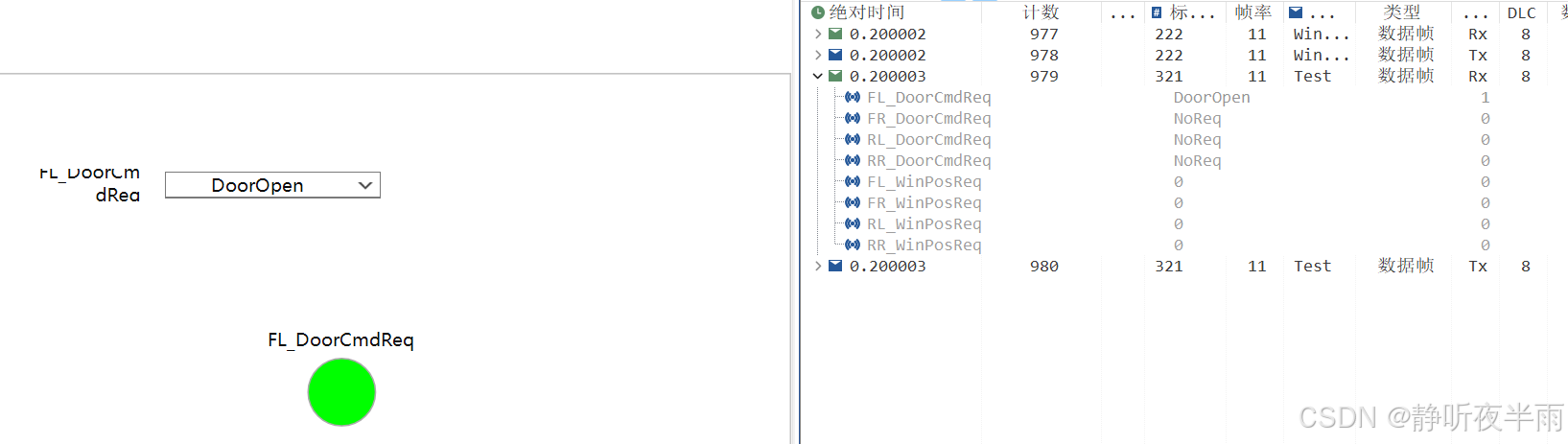
1.11显示控件——仪表
仪表就像一个汽车上的仪表一样,通常用来指示车速,电机的位置,车窗车门的开度等用于表示位置或者大小范围。
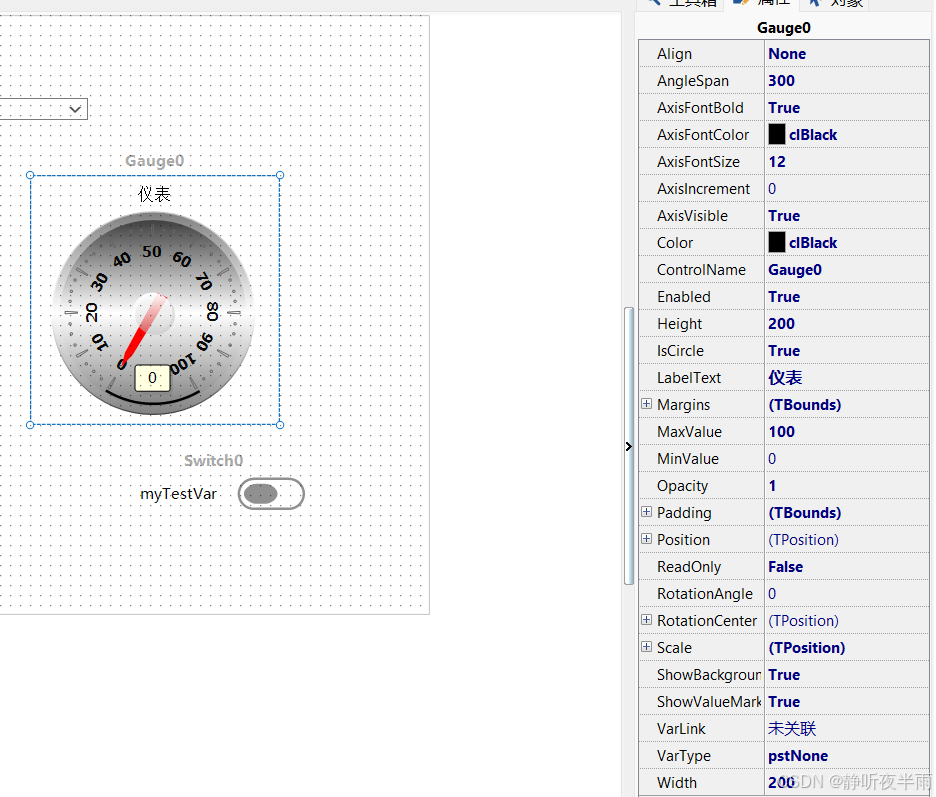
其中,属性AngleSpan用于设置仪表显示刻度的范围,即仪表最小值0~最大值之间的角度。
AxisIncrement用于设置刻度的细密度,默认为0,为0时系统自动调节细密度,当设置为非0时,需要手动调节,设置值越小,细密度越大。
MaxValue和MinValue用于设置仪表显示刻度的上下限值。
Showvaluemask用于设置仪表的当前值是否能显示出来
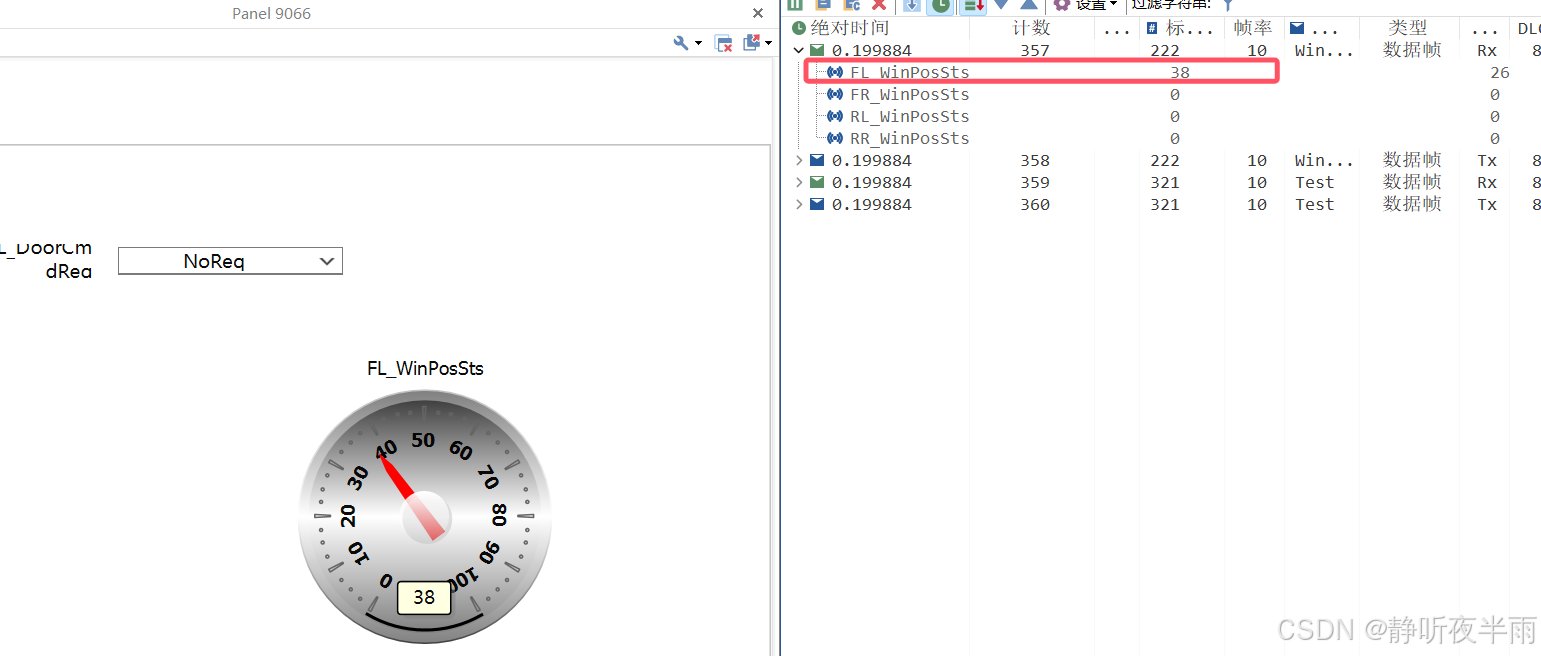
当绑定的变量值发生改变时,仪表控件上的值跟随变化,并且指针移动。
1.12显示控件——饼图
饼图可以用来表示两个或多个变量值之间的占比关系
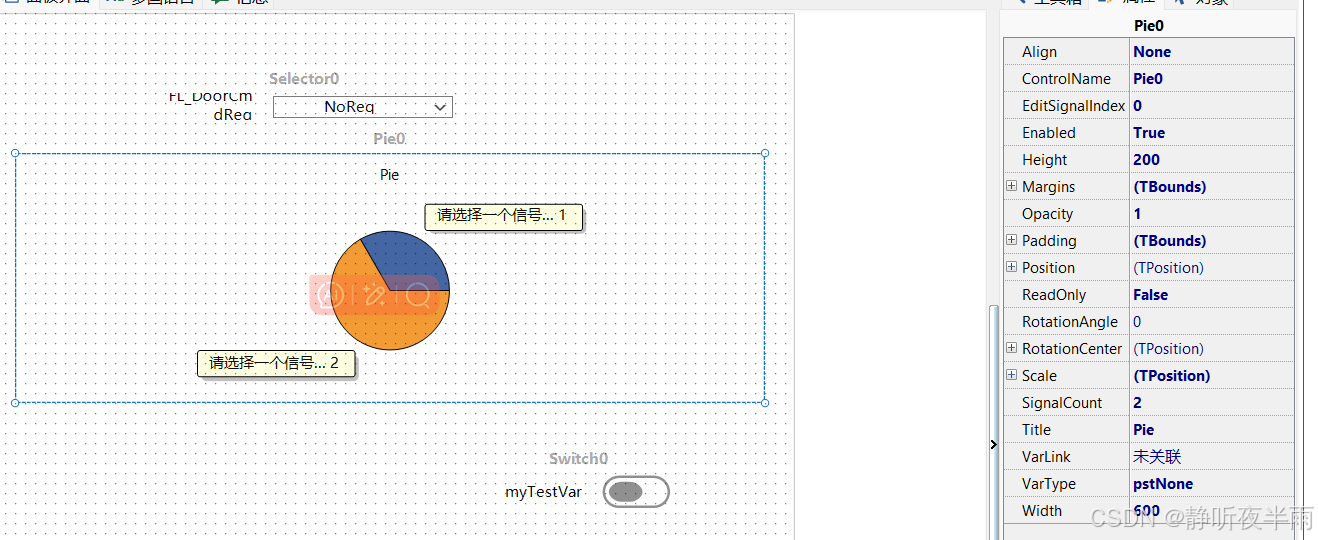
属性EditSignalIndex表示当前编辑的变量的索引,索引为0表示第一个信号
SignalCount用于设置饼图中的变量数量
和图形控件一样,绑定多个信号需要一次修改索引后进行绑定。
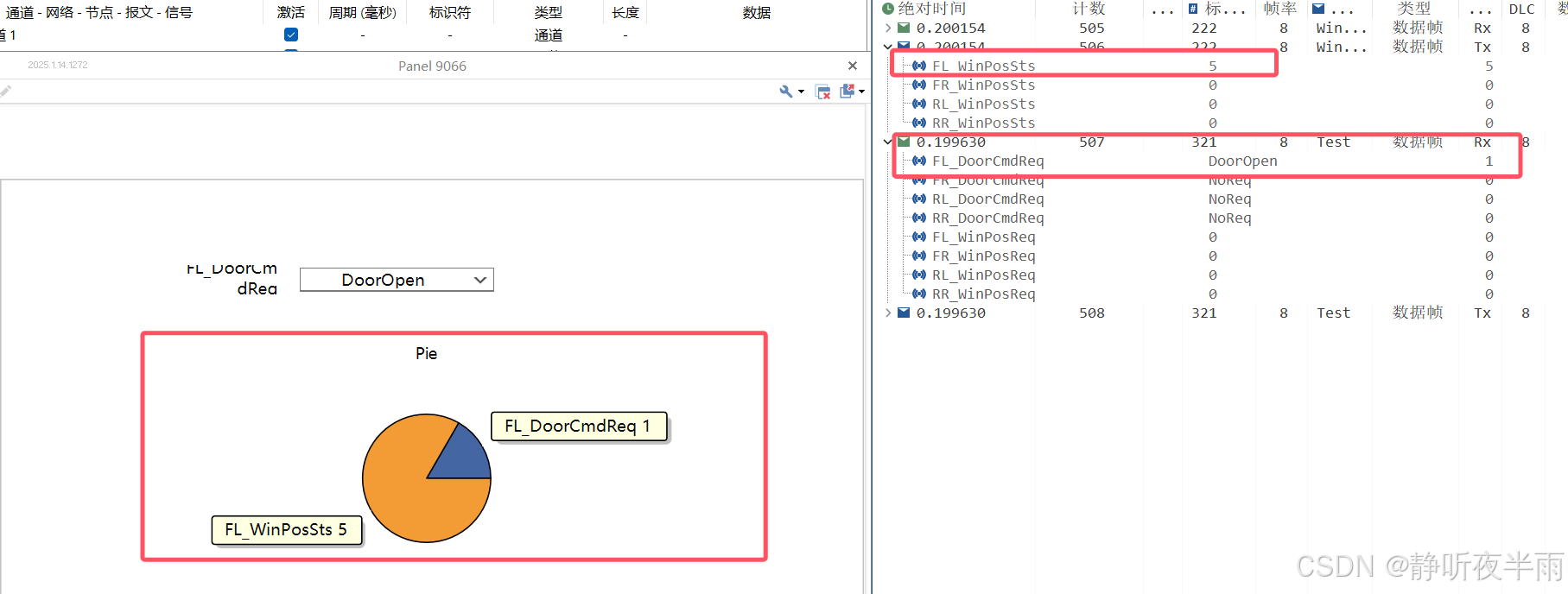
这里我绑定两个信号,当信号值发生变化时,饼图关系也随之改变。由于我的信号值加起来总共6份,其中一个占5,一个占1。显示的饼图就是六等分,一个六分之五,一个六分之一的情景。
二、系统变量的创建与使用
2.1 系统变量的类型
TS的系统变量分为内部变量与用户变量两种,用户只能创建用户变量,内部变量是TS程序自己生成的,无权更改与使用。
在仿真菜单栏下,点击系统变量,打开系统变量视图。
左上角左侧是内部变量,右侧是用户变量。
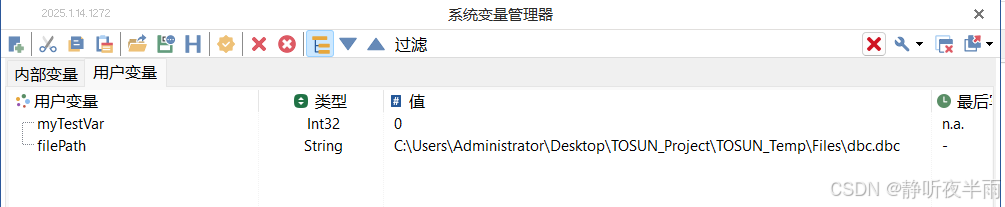
2.2 用户变量的变量类型
用户变量类型跟常用的编程语言中的数据类型基本相同
int32——有符号32位整数类型
uint32——无符号32位整数类型
int64——有符号64位整数
uint64——无符号64位整数
uint8Array——无符号8位整数数组,即字节数组
int32Array——有符号32位整形数组
int32Array——有符号64位整形数组
double——双精度浮点型变量
doubleArray——双精度浮点型数组
String——字符串类型
2.3 创建系统变量
在空白处右击鼠标,选择创建用户变量,弹出的界面如图所示
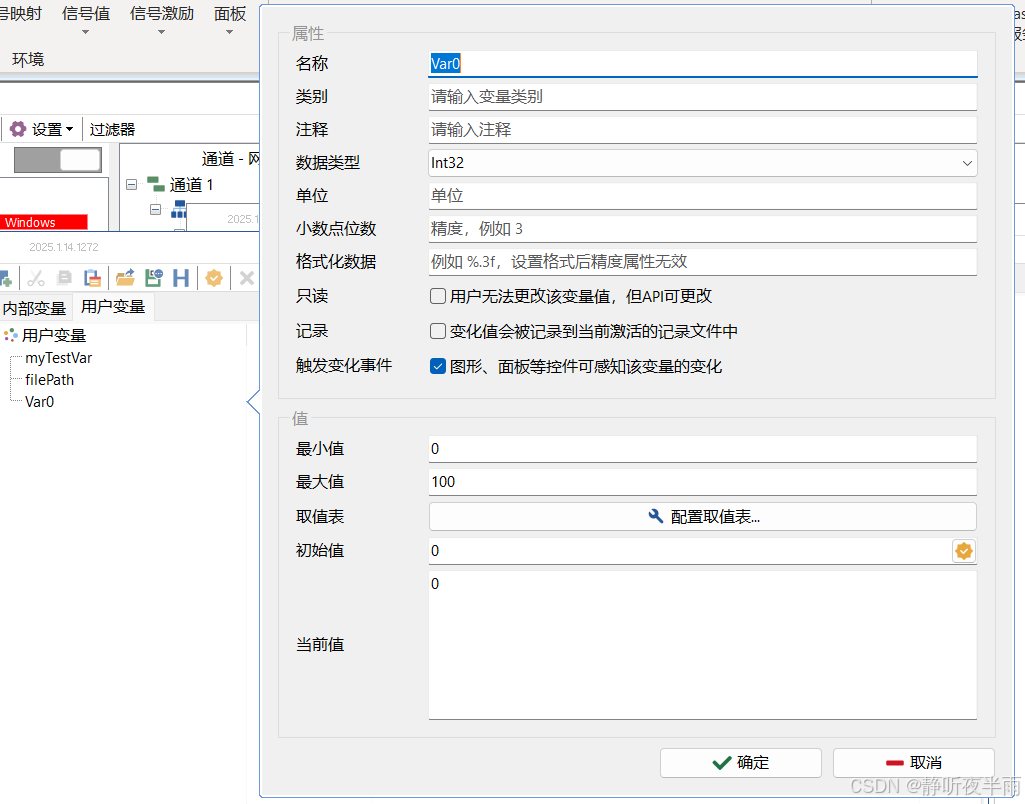
名称:变量的名字,可在小程序和panel中访问
类别:类似于命名空间的概念,当设置得有类别名"a"的变量"name"时,变量名则为"a.name",非必须
注释:变量的注释,用于描述这个变量,非必须
数据类型:变量的数据类型,用于定义变量表示数据的表示范围
单位:变量代表的数据的单位,非必须
小数点位数:如果为浮点数,表示的精度,非必须
格式化数据:变量的显示格式,和精度只能有一个生效,非必须
只读:设置为只读则只能通过小程序代码修改,无法在外部修改
记录:如果勾选,则此变量的值的变化会记录到log中
触发事件变化:如果取消勾选,则Panel绑定此值无法发生变化
取值表:该变量的每个不同的值代表的含义,通过取值表配置
点击配置取值表,可以在弹出的界面中设置取值表
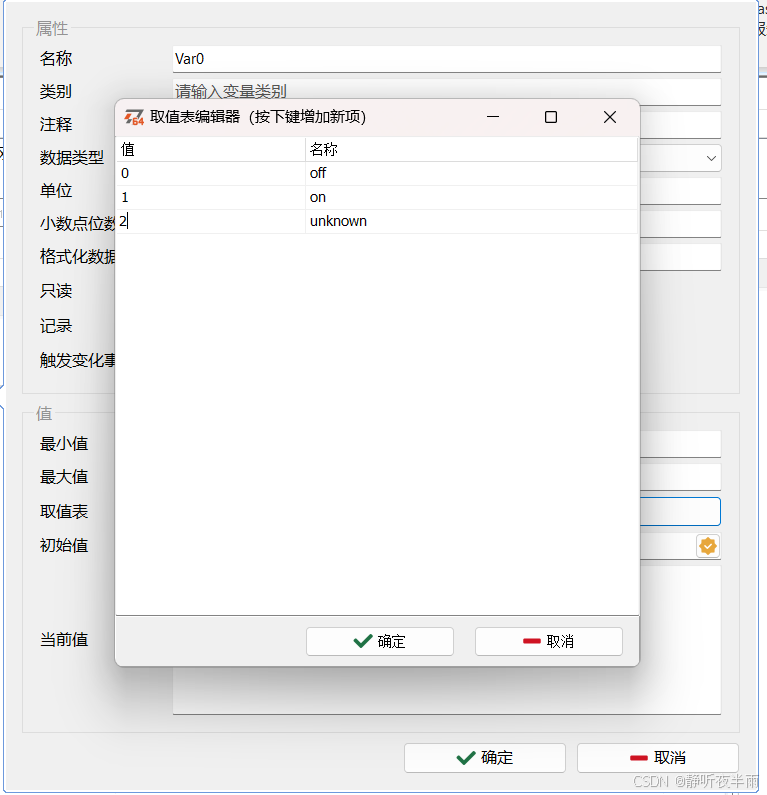
如果配置了取值表,则Panel中关联时,如果变量值处于有取值表的值,则会显示取值表中对应值的描述(名称)。
三、c小程序简单使用,c小程序发送报文
TS的c小程序编程除去自身提供的函数库以外,完全兼容标准c/c++语法,这里暂时不做过多介绍
在设计菜单栏,选择c小程序下的箭头,创建一个新的c小程序
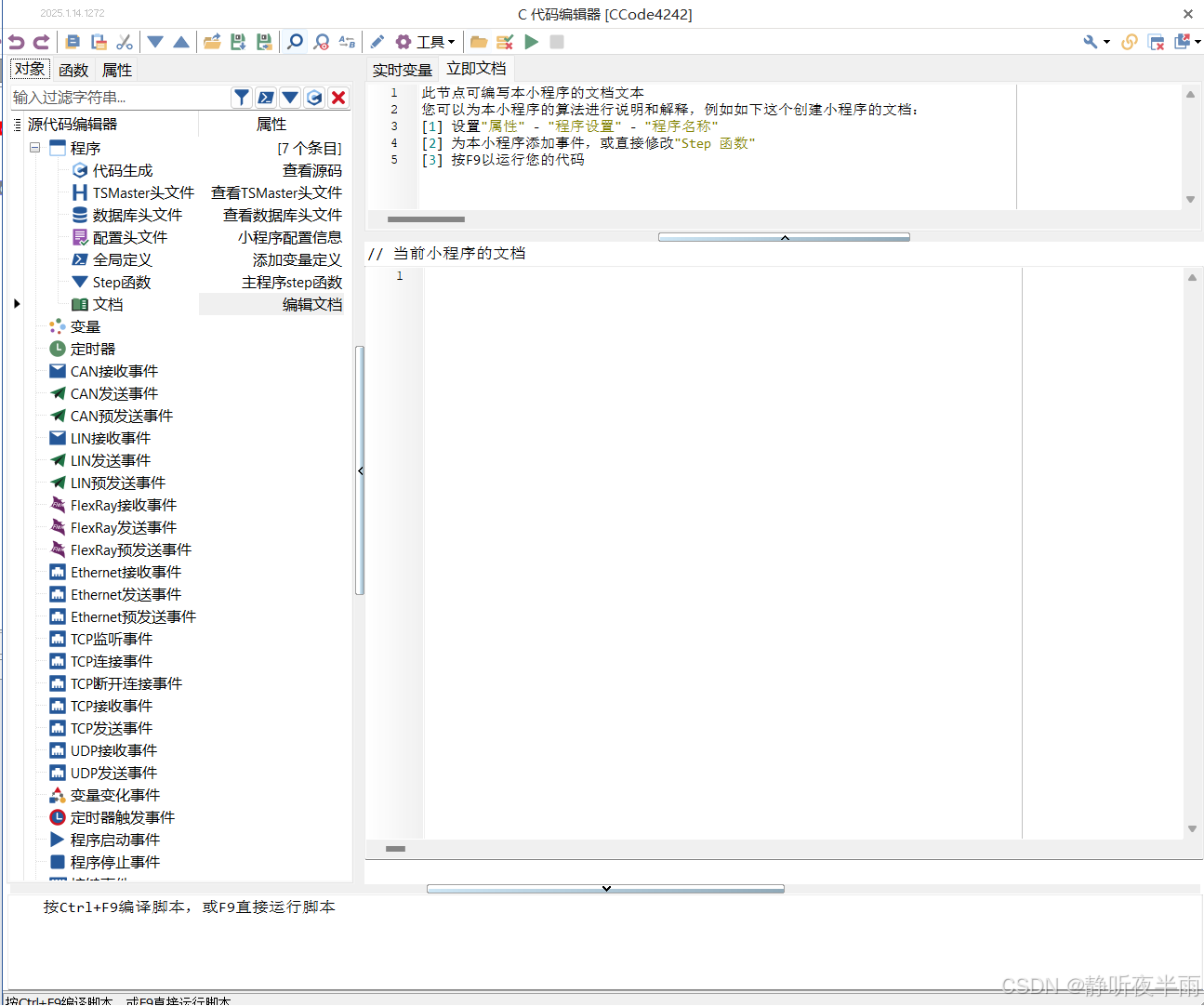
TS的C小程序中提供了一个Step函数,Step函数是一个以5ms为周期循环调度的函数,在这里可以简单的做一些需要重复做的事情,但不宜执行耗时过长的代码。
除了Step函数外,C小程序还提供了一套较为完备的事件驱动系统,类似与CANoe与C++的Qt框架,可以通过事件机制,在事件触发时来比较便捷的执行自己的逻辑。
3.1 粘贴代码法
对TS的C编程不熟悉的朋友,如果想利用c小程序进行某些操作,可以使用代码粘贴法。
何为代码粘贴法?
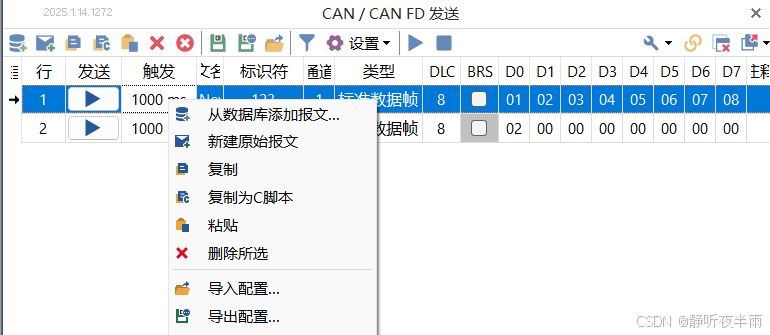
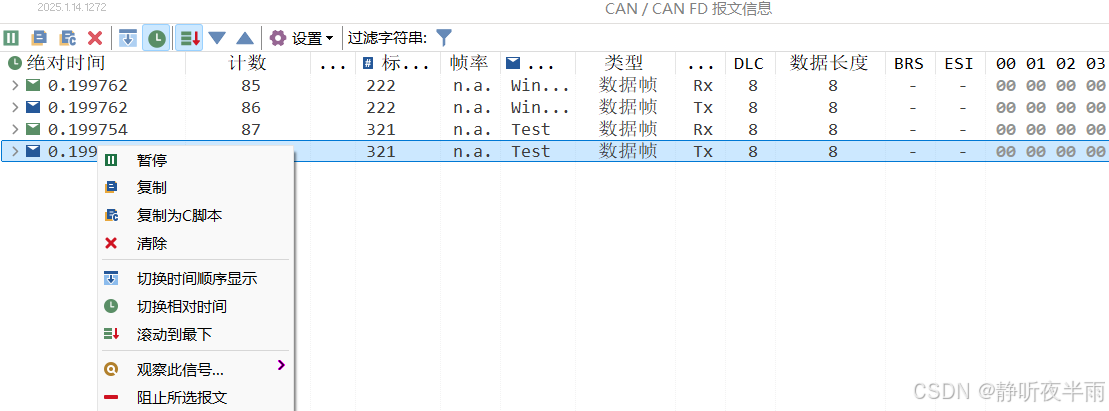
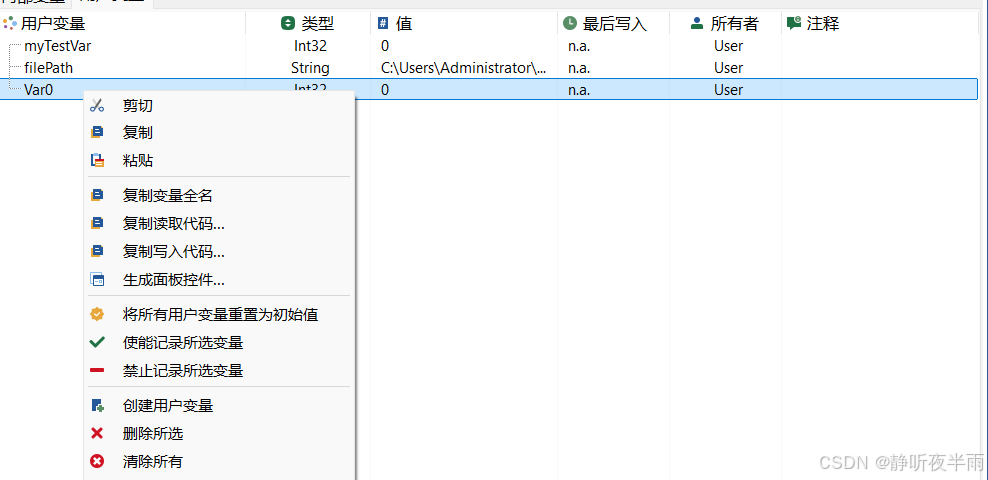
如图所示,在TS程序中,许多地方都提供了鼠标右键可以生成对应代码的功能,当对TS的c编程不熟悉之时,可以使用这种方法来学习。
比如在报文发送模块,新建一个报文,随后右键选择复制为c代码
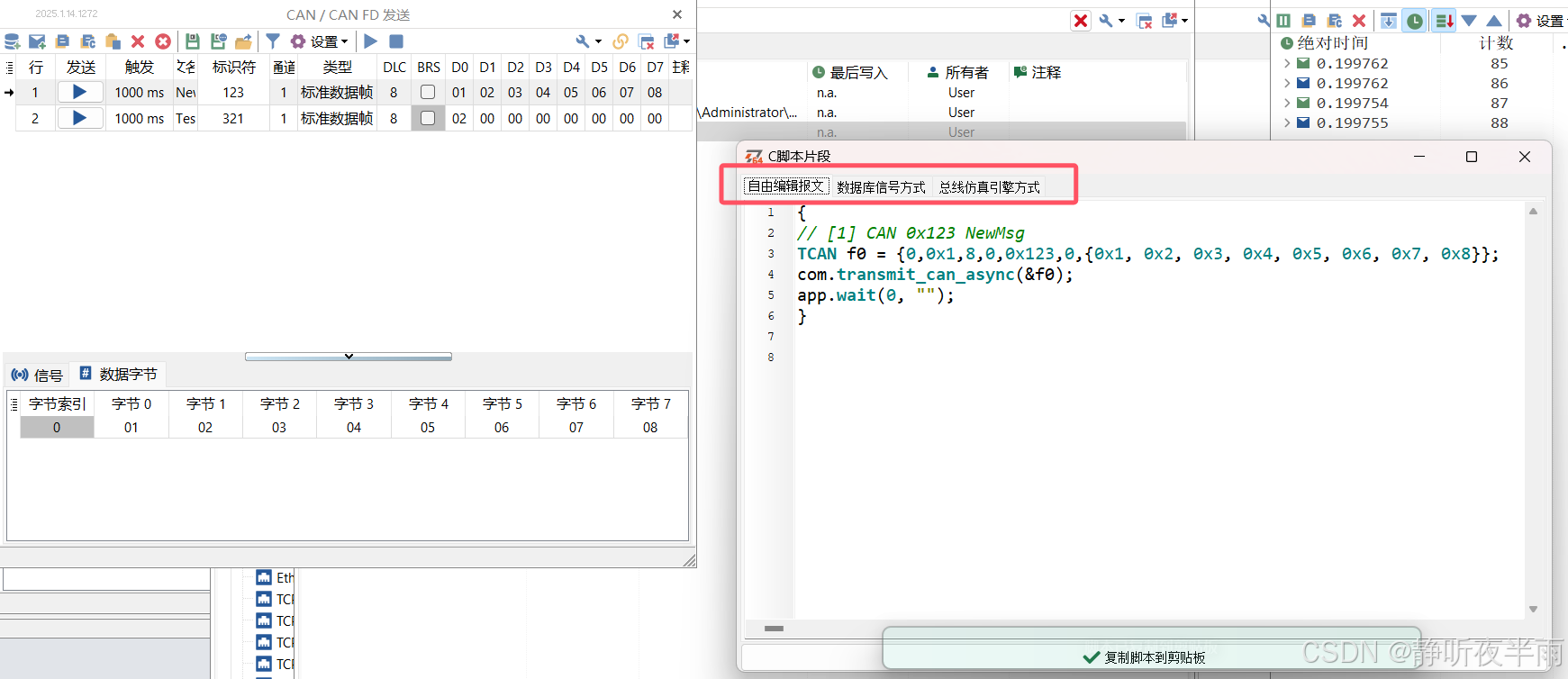
就会跳出对应功能的代码,我们可以直接复制这段代码达到想要的功能。
并且TS还提供了三种发送报文的方式。
自由编辑方式:直接操作报文的字节和ID,dlc等属性,随后调用发送函数发送
数据库信号方式:以数据库信号定义的方式,将当前报文的各个信号的状态定义出来并修改信号发送
总线仿真引擎方式:以rbs仿真的形式发送报文,直接设置数据库中的信号。
这里我直接复制自由编辑模式的代码,随后打开c编辑器,将代码复制在Step函数中,并将报文ID修改为0x456
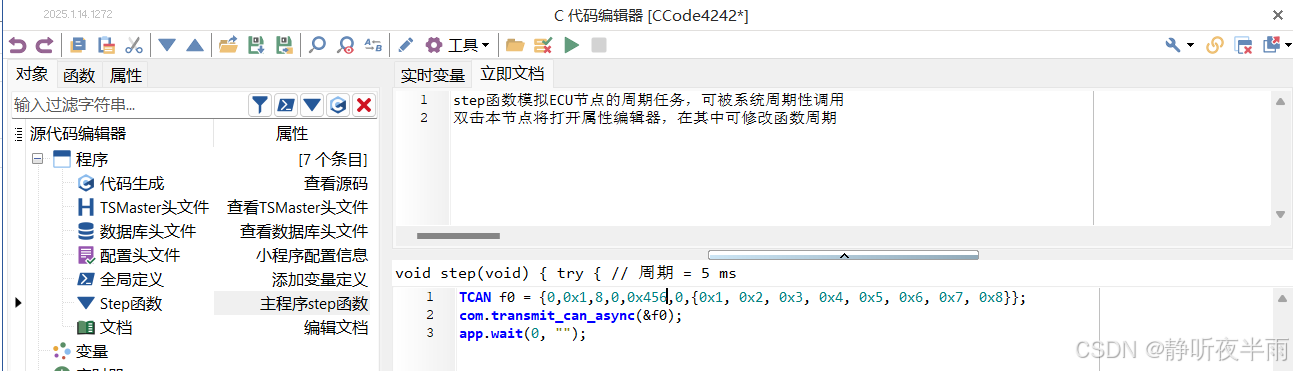
随后点击编译图标,编译这段c代码,并为c小程序节点勾选自启动模式

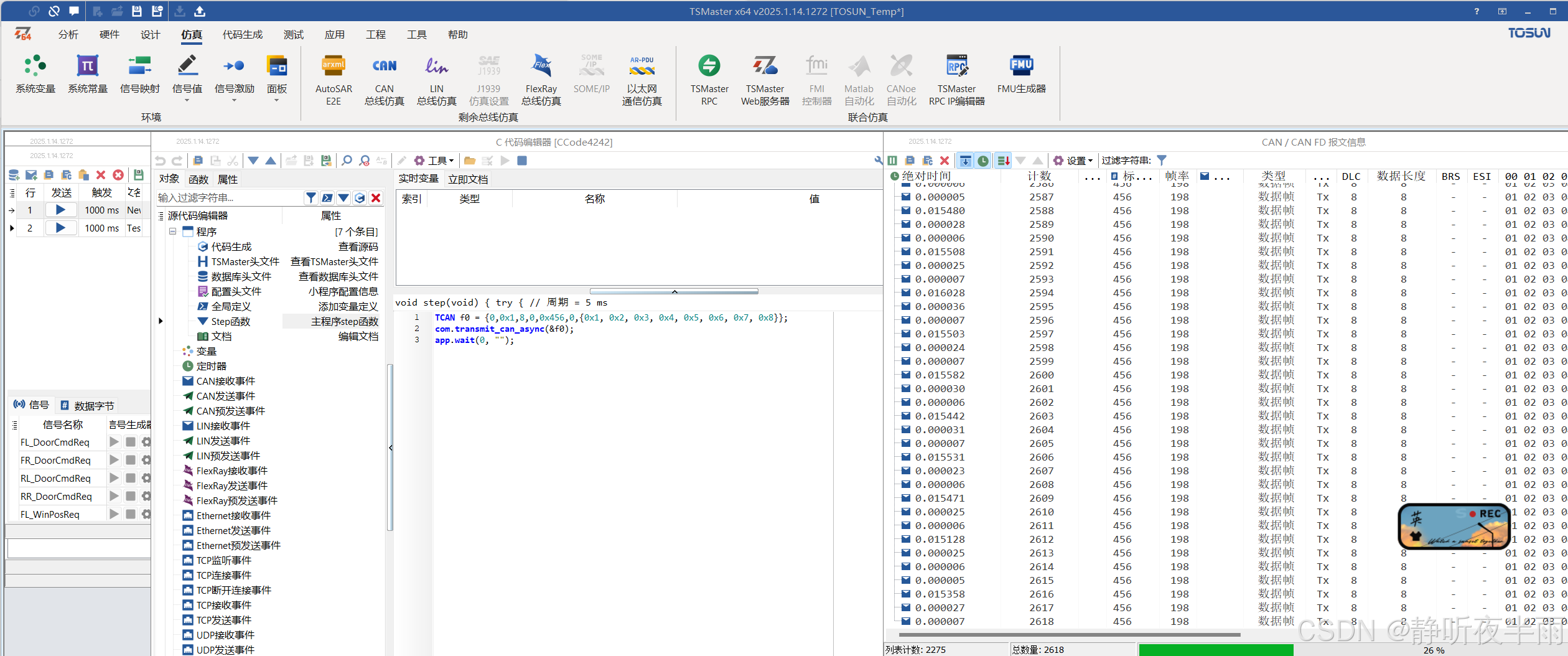
启动TS工程,可以看到我们定义的报文就已经在自动发送了。
3.2 系统变量与panel,c小程序简单结合使用
现在使用零代码粘贴方法实现以下利用panel控制TS发送报文。
以上文中介绍的方法创建两个系统变量sendMsg234和sendMsg456

在Panel面板中创建两个按钮,并分别绑定这两个变量。
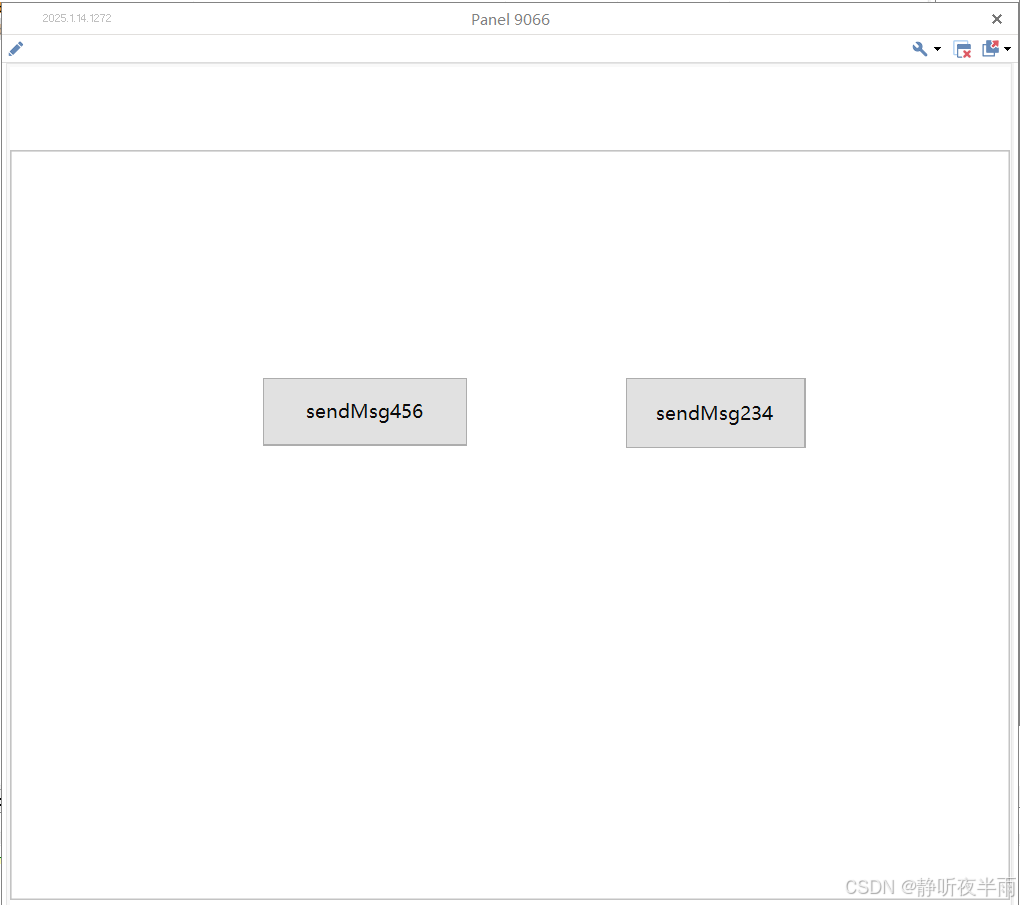
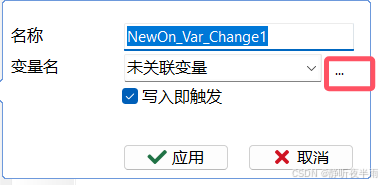
在c小程序中,找到变量变化事件,创建两个事件

鼠标右击添加事件,分别添加两个系统变量对应的事件,使用选项找到刚刚创建的变量,选择完毕后点击应用
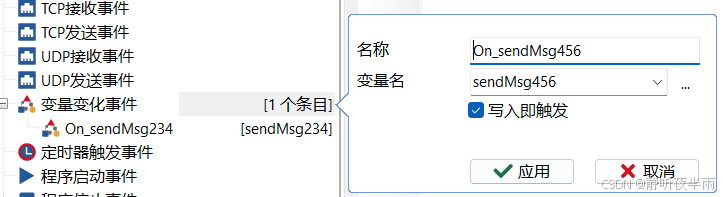
ok,创建完成后得到了如图所示的两个变量变化事件
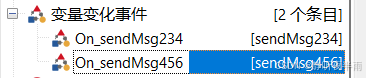
现在打开刚刚复制的发送报文的代码,剪切一下粘贴到这两个变量变化事件内,并分别修改下对应的报文ID
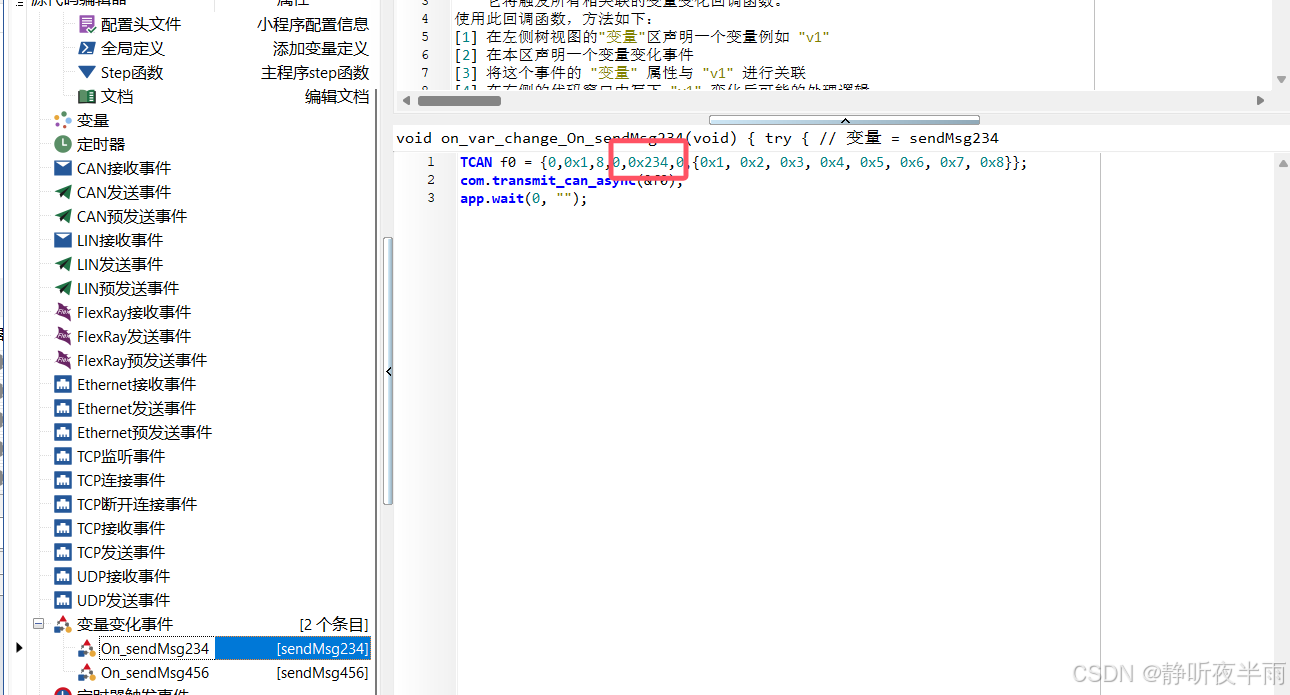
随后编译代码,启动工程。
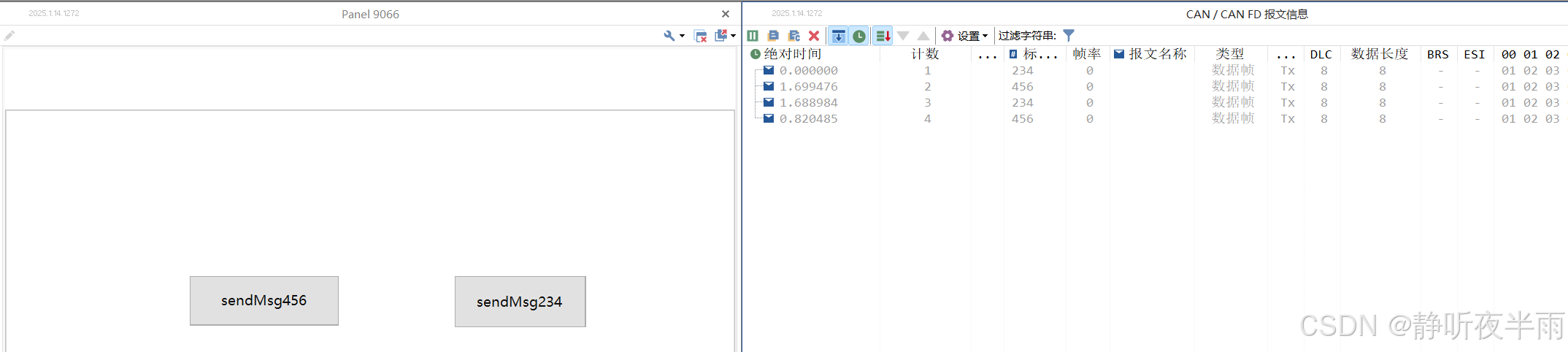
现在就可以做到,点击一次就发送一次对应的报文了。
本期介绍到此为止,以后将会详细介绍TS的一些库函数使用,或者大家有什么想知道的,也可以在评论区提出,谢谢。






![[Qt]事件-鼠标事件、键盘事件、定时器事件、窗口改变事件、事件分发器与事件过滤器](https://i-blog.csdnimg.cn/direct/239dfc121568403297082dcff2a6c1e0.png)











