前言:本文教程为,上传文件到服务器并训练深度学习模型,与下载服务器文件到本地。演示指令输入,完整的上传文件到服务器,并训练模型过程;并演示完整的下载服务器文件到本地的过程。
本文使用的服务器为云服务器,为蓝耘云平台,注册登录链接如下:
https://cloud.lanyun.net/#/registerPage?promoterCode=11f606c51e![]() https://cloud.lanyun.net/#/registerPage?promoterCode=11f606c51e目录
https://cloud.lanyun.net/#/registerPage?promoterCode=11f606c51e目录
1.上传文件到服务器并训练模型
2.下载服务器文件到本地
1.上传文件到服务器并训练模型
需要的指令如下,命令行终端Terminal依次输入:
unzip Archie_yolo11.zip
conda create -n Archie_yolo11 python=3.8.18
conda init
conda activate Archie_yolo11
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
pip install -e .
python main.py
接下来演示指令输入,完整的上传文件到服务器,并训练模型过程(指令可按需,更换自己需要的版本,例如Python、pytorch版本等)
首先,登录服务器,我用的是蓝耘元生代智算云平台
注册,登录链接如下:
https://cloud.lanyun.net/#/registerPage?promoterCode=11f606c51e![]() https://cloud.lanyun.net/#/registerPage?promoterCode=11f606c51e进入后,选择容器云
https://cloud.lanyun.net/#/registerPage?promoterCode=11f606c51e进入后,选择容器云

选择租用新实例

租一个服务器,如下为我租用的服务器详情,可按需自行选择
镜像:lanyun/pytorch-2.0.1-py3.8-cuda11.8-u20.04:v1.5
GPU:RTX 3090 * 1卡
CPU:Intel(R) Xeon(R) Gold 6152 CPU * 10核
内存:30GB
硬盘:系统盘: 30GB,数据盘: 50GB
然后点击如下JupyterLab进入

进入后,界面如下 ,点击进入lanyun-tmp文件夹

将本地工程文件压缩包(我上传的是yolo11工程,文件名为Archie_yolo11),压缩包拖进该文件夹下,底部是上传压缩包文件进度,等待上传完成。

上传文件完成后,在该文件夹下,点击Terminal进入命令行终端界面
输入如下指令,进行解压缩,等待解压缩完成(Archie_yolo11是压缩包文件夹名字)
unzip Archie_yolo11.zip- 这是一个解压命令,用于解压名为
Archie_yolo11.zip的压缩文件。在执行此命令前,确保当前目录下存在该压缩文件,并且你有读取该文件的权限。

解压完成后,输入如下指令
conda create -n Archie_yolo11 python=3.8.18conda是一个流行的开源包管理系统和环境管理系统。create表示创建一个新的环境。-n Archie_yolo11指定新环境的名称为Archie_yolo11。python=3.8.18指定在新环境中安装的 Python 版本为 3.8.18。

碰到这个情况就输入y

进入解压后的文件夹打开Terminal进入命令行终端界面,输入如下指令
conda init - 这个命令用于初始化
conda,使conda能够在当前的终端环境中正常工作。它会修改终端的配置文件(如.bashrc、.zshrc等,取决于你使用的终端),以便在每次启动终端时能够正确加载conda。

接着输入如下指令
conda activate Archie_yolo11- 用于激活名为
Archie_yolo11的conda环境。激活后,后续安装的包和执行的命令都会在这个环境中进行,避免不同项目之间的包依赖冲突。

接着输入如下指令
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia- 这是在当前激活的
conda环境(Archie_yolo11)中安装 PyTorch 及其相关库。 pytorch==2.0.1指定安装的 PyTorch 版本为 2.0.1。torchvision==0.15.2指定安装的torchvision版本为 0.15.2,torchvision提供了计算机视觉相关的工具和数据集。torchaudio==2.0.2指定安装的torchaudio版本为 2.0.2,用于音频处理。pytorch-cuda=11.7指定安装支持 CUDA 11.7 的 PyTorch 版本。-c pytorch -c nvidia指定从pytorch和nvidia这两个conda通道下载和安装这些包。

接着输入如下指令
pip install -e .pip是 Python 的包管理工具。-e表示 “可编辑模式”(editable mode),“.” 表示当前目录。这个命令会在当前激活的conda环境中以可编辑模式安装当前目录下的 Python 项目。这意味着你对项目源代码所做的任何更改都会立即生效,而不需要重新安装包。

修改例如dataset.yaml文件里的数据集路径为服务器下的路径,如有其他路径修改也一样
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /root/lanyun-tmp/Archie_yolo11/datasets # dataset root dir
train: /root/lanyun-tmp/Archie_yolo11/datasets/images/train # train images (relative to 'path') 6471 images
val: /root/lanyun-tmp/Archie_yolo11/datasets/images/val # val images (relative to 'path') 548 images
test: /root/lanyun-tmp/Archie_yolo11/datasets/images/test # test images (optional) 1610 images
然后输入如下指令,运行main.py文件
python main.py- 这是在当前环境中执行名为
main.py的 Python 脚本。在执行此命令前,确保main.py文件存在于当前目录,并且该脚本的依赖项都已正确安装。
即可开始训练模型

以上,完成上传文件到服务器并训练深度学习模型
2.下载服务器文件到本地
接下来演示完整的下载服务器文件到本地的过程。
需要下载两个软件:Xshell、Xftp(网上下载教程很多,自行下载)
如下为我使用的版本信息


安装完成以上两个软件后,打开Xshell软件,点击如下新建会话,或点击文件新建会话

进入如下界面

复制服务器的如下登录指令,SSH和密码

例如我的SSH如下
ssh -p 22xxx root@link.lanyun.net用户名为root
协议为SSH
主机为link.lanyun.net
端口号为22xxx
如下名称为:新建会话(3),可自定义名称
然后点击连接即可
 然后弹出如下界面,可选择为接受并保存,或一次性接受
然后弹出如下界面,可选择为接受并保存,或一次性接受

然后输入用户名为root

然后会弹出输入密码,输入在服务器复制的密码输入即可


如下所示,成功连接上服务器

然后在Xshell软件点击如下图标,会自动打开Xftp软件,弹出的Xftp软件的右侧为服务器的文件夹

弹出如下窗口则选择接受并保存或选择一次性接受

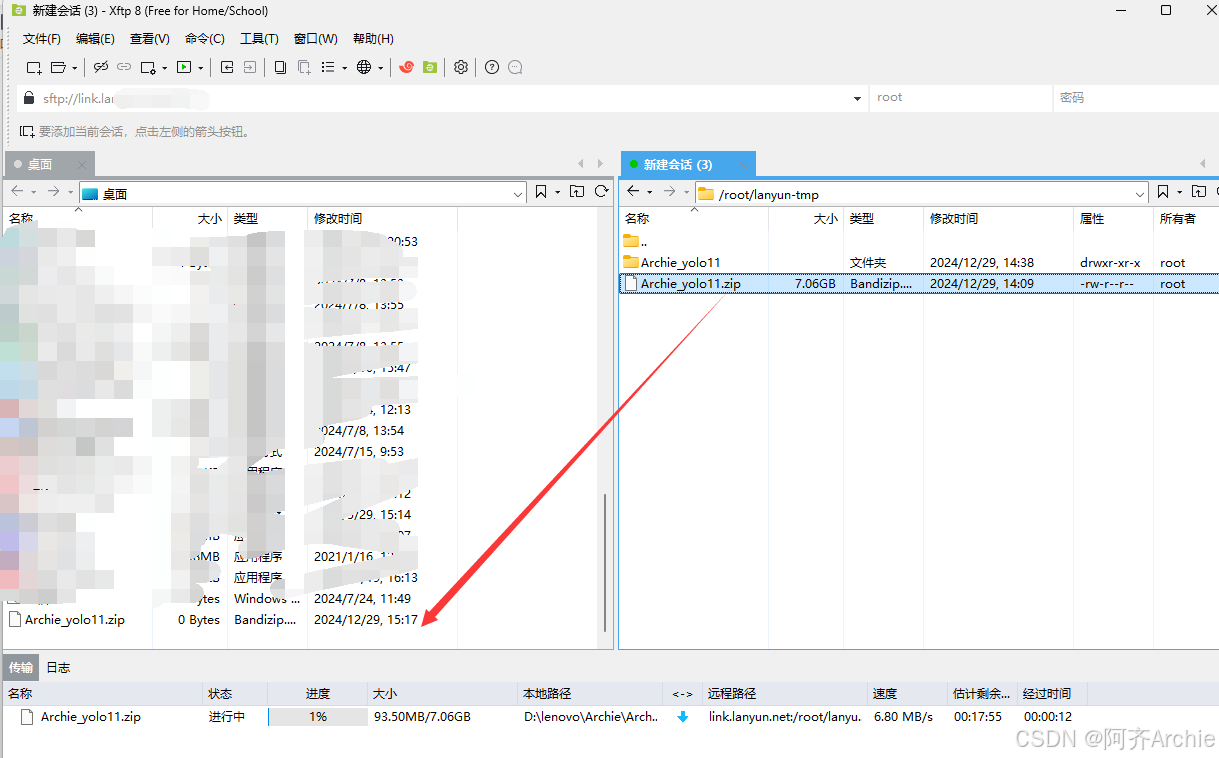
在Xftp软件中,将右侧服务器里的文件拖动到左侧即可下载到本地(本地电脑),底部为传输进度。
以上,完成了详细介绍上传文件到服务器并训练深度学习模型&下载服务器文件到本地










![Postman[2] 入门——界面介绍](https://i-blog.csdnimg.cn/direct/67eed5d0f4fa43dc9f999805994c35a1.png)








