演讲 | 林咏华 智源人工智能研究院副院长
整理 | 何苗
出品 | CSDN(ID:CSDNnews)
2018 年以来,超大规模预训练模型的出现推动了 AI 科研范式从面向特定应用场景、训练专有模型,转变为大模型+微调+模型服务的AI工业化开发模式。直至对话大模型 ChatGPT 引发全球广泛关注,人们终于欢呼 AI 2.0 时代来了。当我们立足由大模型推动的AIGC元年,AI 正在迎来新的一轮全球应用和研发热。
随着两波AI崛起浪潮接连在寒冬中袭来,人们终于看到了大模型+AIGC 将人工智能从当前低谷带到下一个拐点的星火。在过去十年的尾声,以深度学习为基础的人工智能为何在产业落地方面变得缓慢?人工智能的下一个十年将是何图景?或许要从 AI 的开发范式变迁说起。

AI开发范式三重变
过去多年,每年虽有几万篇 AI 领域的 Paper 产出,但其产业落地进展依然缓慢,究其原因主要有以下几点:
第一,AI研发的人力成本太高,且大量依赖算力研究者。人工智能是知识密集型产业,聘用算法研究人员和算法工程师的成本通常在 5 万~ 8 万元/月,在AI产业中的企业,人力资源的支出占比非常高;
第二,训练数据的成本太高。在传统AI项目里,60 %-80 %的时间和成本花在了数据上。通常,在算法研发项目中,购买数据所需的成本大约占整个项目的 60 %,而 80 %的时间被数据准备相关的工作占据,如采集,清洗和标注等。因为在不同的场景下,数据标注的标准并不一致,因此即使是同样的数据标注任务,也需要针对新的场景标注新的数据集;
第三,AI训练需要的算力资源成本颇高。如果从零开始训练一个模型,计算资源的消耗将会非常高,特别是大于 100 亿参数规模的模型,训练所需算力的成本会超过 100 万人民币。
而AI开发范式很大程度上决定了产业落地的成本。那么过去十年以及未来十年的开发范式给我们带来怎样的改变?
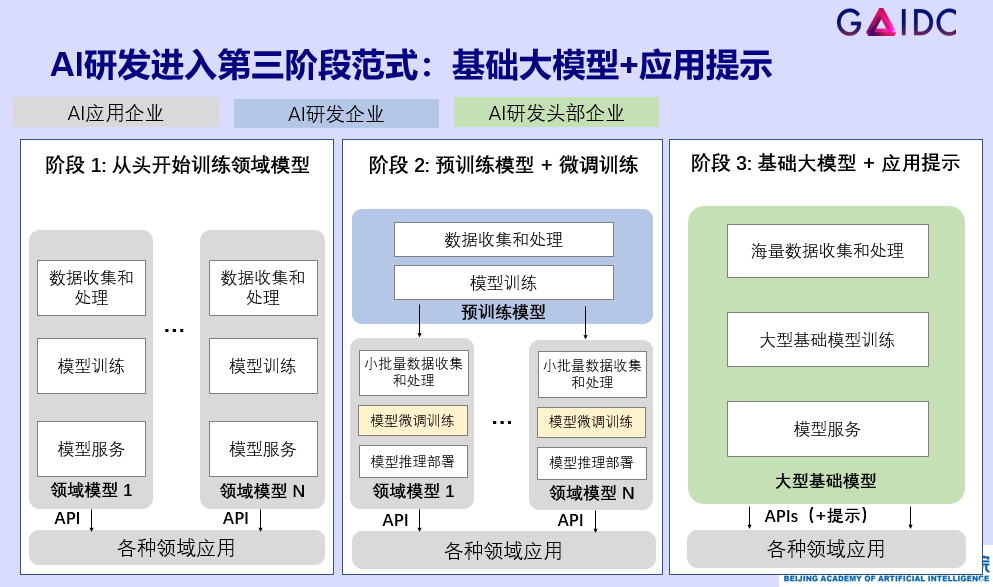
第一阶段开发范式:从头开始训练模型和准备数据
过去,每个应用企业面对不同 AI 应用都需要从头开始训练领域模型,这就要求每个企业都有一批全栈算法工程师,海量训练百万级标注数据,使用高昂的算力从 0 到 1 训练一个模型。目前来看此路不通,因此十年前,预训练模型加微调开始在计算机视觉领域迅速发展。在 2014 年的 NIPS、CVPR 等学术顶尖会议上发布了此方向的多篇开创性文章。
第二个阶段开发范式:预训练模型+微调训练的迁移学习开发范式
在迁移学习的开发范式下,由有实力的 AI 团队通过海量的数据(如百万、千万级数据)进行基础模型训练。AI 应用团队再通过收集少量数据(如千~万数量级的图片或文本),对预训练的基础模型进行微调训练。相比起第一种范式,对大量 AI 应用团队而言,可以大大减少需要收集的训练数据、缩短训练的时间和所需的计算资源。因此,在过去 10 年,迁移学习广泛被应用在计算机视觉的 AI 开发中,后来也演进到语言模型的开发中。
但在这种范式下,使用的预训练模型规模不大,因此泛化性低。针对不同的小场景,往往需要微调训练不同的模型来适配,企业在同一个场景中需要维护多个小模型,无形增大了应用开发、维护和迭代的复杂度。此外,对众多应用企业而言,依然需要有 AI 算法团队来实现微调训练和模型迭代,对 AI 应用的落地形成不小的门槛。
第三种 AI 开发范式:基础大模型+指令提示(prompt)
近年大模型的迅速发展带来了第三种 AI 开发范式。由实力强劲的 AI 头部企业将巨量数据(数以千亿级、万亿级的文字 token,或者上亿级的图片、文章或者图文对),通过数百到上千张 GPU 加速卡来训练百亿以上参数规模的大模型。该大模型诞生之后,不需针对各种应用场景分别进行微调训练,只需应用企业通过带提示的指令进行 API 调用即可。

大模型驱动 AI 新十年
随着人工智能开发范式进入预训练基础大模型+应用提示,AI 应用也从单种模态迈向多种模态的 AI 应用。当模型参数量很大,所吸纳的数据量够高,就具备了足够的泛化性和融合的能力,而模型能力也从过去十年的感知和理解类应用能力,迈向了众多生成类的新应用。人们再也无法忽视大模型的两个重要发展趋势:模型越来越大,从最初一亿参数级的模型到上万亿参数的模型;从单一的语言模态走向了跨模态。
当预训练模型由小变大,人工智能从理解到生成,业界迎来了怎样的挑战?
超大参数量
当 AI 面临产业落地问题,就需要考虑,多大参数量的基础模型才能够满足应用需求。Google 去年有文章分析语言基础大模型,在 Few-shot 情况下,训练计算量基本都在 1022 FLOPs 以上,才能出现对不同任务的涌现能力,这至少对应着百亿参数以上的模型规模。不同难度的任务,其涌现能力出现的模型规模拐点不尽相同。对于其它视觉、跨模态基础大模型,还有待总结。
超大的训练数据量
到底要多大的训练数据才足够?Meta AI 最新公布了模型 LLaMA,它是以 1 万亿 token 的数据量训练 130 亿参数的模型,超过了使用 4000 亿 token 训练的 1750 亿参数的 GPT-3。过往实验也呈现过类似的情况,通过使用更多数据、把大模型的参数量控制在一定范围,将更加适合产业的广泛落地。
大模型的评测
当模型越来越巨大时,下游行业企业已经不再自己训练模型,而是选择基础大模型,大模型的评测变得尤其重要。那么产业该如何对一个训练好的大模型进行评测?以当前的语言大模型为例,可以从三个层级的能力——理解能力、生成能力、认知能力入手。现有的语言模型评测体系,包括之前的 GLUE 和最新的 HELM 等,都以评测理解能力居多;对于模型的生成能力,目前大量依赖人的主观评测;对于认知能力,由于边界难以确定,更加缺乏统一的评测方法。因此当模型的模态从单一走向多样,对评测提出了新的挑战。
持续学习和定点纠错
当模型庞大,如何让其拥有持续学习以及定点纠错的能力?如果你在训练数据中存在了一个错误的知识点,该怎样从庞大的已经训练好的模型里把错误修正?
还有如何提升训练效率和推理效率等问题,以上都是未来十年产业落地中很重要的挑战。
如何迈向 AI 新十年?或由大模型来驱动。
作为人工智能领域的非盈利性质的新型研发机构,智源研究院是中国最早进行大模型研究的科研机构,“大模型”一词,也是自 2021 年 3 月智源发布悟道 1.0—— 中国首个人工智能大模型之后,渐渐成为约定俗成的术语。
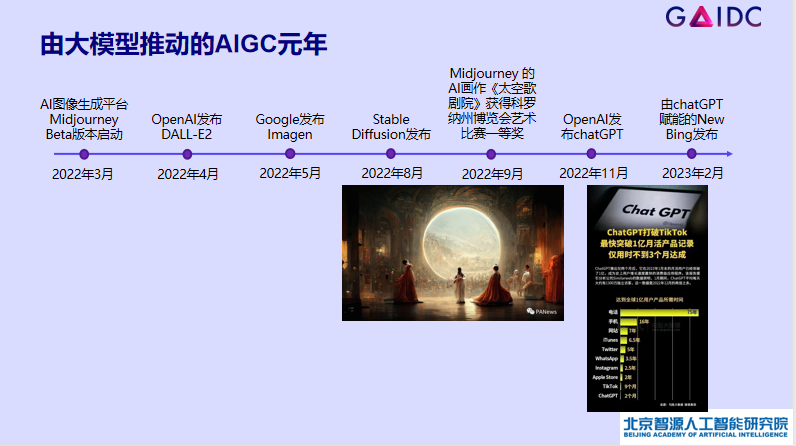
文生图与 ChatGPT 两个标志性的AI应用,让我们看到了大模型推动的 AIGC 发展元年。尽管当前更多人将关注点聚焦于 ChatGPT,但难度更大的 GPT3.5 才是整个大模型的底座。
可以说没有语言大模型,就没有爆款 ChatGPT。它的成功不在于“Chat”,更重要的是下层强有力的基座——预训练的语言大模型 GPT3.5。文生图应用的重要基座是文图的表征模型,又叫做图文预训练大模型,再往下层又需要很强的语言模型和视觉模型作为双塔支撑。而这一切,仅构成了大模型基座的第一行。强大的数据和数据处理能力、大模型的评测方法也都是支撑大模型更重要部分。再加上算力、整套 AI 系统相关技术、智算平台算力的调度、底层算子的优化,以及各种 AI 芯片技术的加持,这些才真正支撑起了 AIGC 的成功。

人工智能必须开源开放
火爆的文生图应用、ChatGPT 等生成式模型只是大模型领域的冰山一角。在冰山之下,还有层层的技术栈,需要各种模态的预训练大模型、海量数据集以及优秀的数据集工具、大模型评测以及一系列的 AI 系统优化工具和技术以作支撑。没有从底至上的技术栈,就垒不起水面上的冰山一角。

在过去几年智源一直全力积累冰山下的大模型技术栈。如今,它已不再沉迷于做某个一枝独秀的大模型,而是选择将多年积累的优秀大模型技术栈整体开源,推动产业在大模型创新上的快速发展。
开源开放本就是 2017 年国务院《国家新一代人工智能发展规划》提出的四项基本原则之一。智源认同不该由任何一家企业来封闭式主导对人类而言如此重要的方向,而是应该共建开源开放技术体系的产学研单位与生态。
现已经进入“人人大练模型”的无序发展阶段,为了实现AI的有序创新,在数据、测试、开源算法上,智源联合多所高校与企业共同发布了 FlagOpen(飞智)大模型技术开源体系。该体系是一站式、高质量的大模型开源开放软件体系,可助推全球开发者开展各种大模型的开发和研究工作,形态可类比为大模型领域的 Linux,主要包括 FlagAI、FlagPerf、FlagEval、FlagData、FlagBoot 和 FlagStudio 六个部分。
基于 FlagOpen,国内外开发者可快速开启各种大模型的尝试、开发和研究工作,企业可大大降低大模型的研发门槛。同时,FlagOpen 大模型基础软件开源体系正逐步实现对多种深度学习框架、多种AI芯片的完整支持,支撑 AI 大模型软硬件生态的百花齐放。
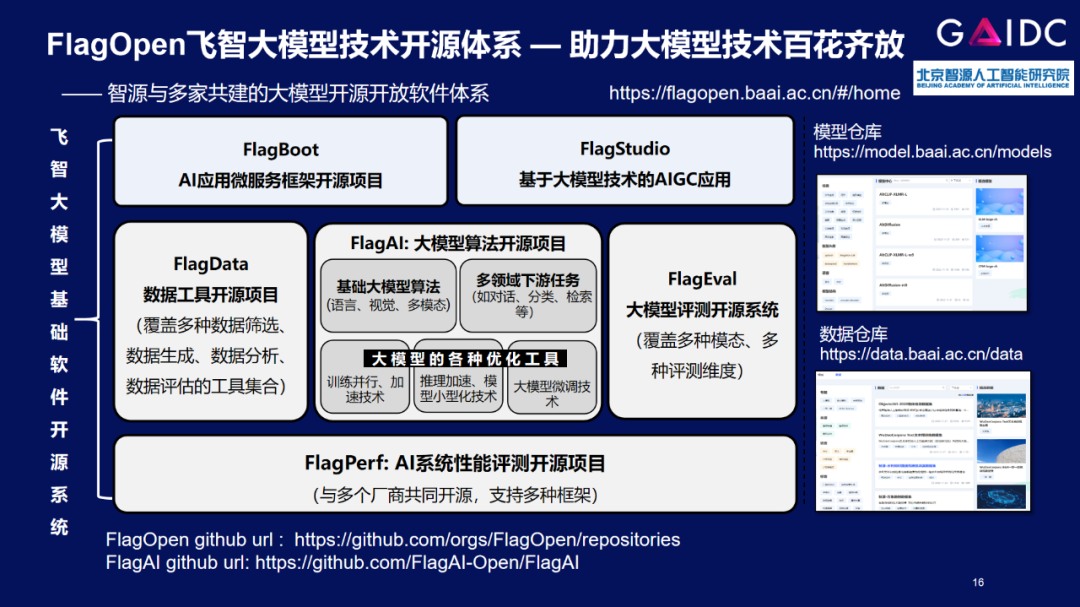
FlagAI
FlagAI 是 FlagOpen 的核心部分,作为一站式高效、灵活的大模型算法和工具,它集合了全球主流的大模型算法,也包括智源的大模型悟道 2.0 到 3.0 的核心算法,同时配备了完整的多领域下游任务。对开发者而言,选择该算法仓库后就知道如何配下游任务,不需要在外面寻找下游任务的实现算法,使其效率得到大幅提升。此外,该项目还集成了各种优化工具,如广泛流行的 DeepSpeed、Magtron 和最新的国内高校并行优化技术 BMTrain 等,算法开发者只需做配置选择,就可以游刃有余地切换在不同的加速技术上。
FlagEval
FlagEval 打造一个了完整的评测体系,更重要的是试图探索未来如何借助 AI 来辅助进行生成型的模型评测。它的诞生主要依据以下几大痛点:
大模型时代,更多下游企业已经不再训练自己的模型,而是考虑怎么选择一个被训练出来的模型。下游用户急需一套完整的评测体系帮助自己选择,但当前的评测体系比较割裂,在语言、视觉、语音多模态都各自不同的评测方法、评测体系。
模型本身的训练效率、推理效率、微调效率难以评测,这些都与成本息息相关。考虑到大模型本身是个“黑箱子”,对大模型的评测仍需要满足多种模态的领域以及多种维度。
对AIGC生成性的评测,对生成图、生成文的评测目前仍然过度依赖人力。与感知性、理解性的评测不一样,生成类的评测没有物理世界的准确答案,大量依靠人力来评测不但效率低下,其公平、客观性也不可考证。
针对以上痛点,智源依托自身在多模态上领先的技术积累,开放了多模态领域——CLIP 系列模型评测工具。这是业内首个完整支持多种语言、多种评测难度和任务的文-图跨模态评测工具。
FlagPerf
FlagPerf 是面向AI的加速、异构系统打造的整体 AI 系统评测工具。它相较于许多商业公司自行研发的评测标准,位置更加中立,可针对不同的 AI 芯片进行评测,支持多种框架,如 Pytorch、Paddle 等。
建立相应的标准体系以及背后评测的手段、体系是产业走向成熟的一个标志。一直以来,新架构的 AI 芯片落地时,最难的问题是被用户评测。为了支撑 AI 芯片评测,需要考虑多种厂商 AI 芯片架构差异、国内外多种深度学习框架、以及数十上百种应用模型。这是一个十分复杂的多重组合问题,因此导致整个适配、评测工作量巨大。FlagPerf 联合多家芯片厂商、系统厂商共同打造了向下支持多种芯片,向上支持多种深度学习框架的AI芯片评测开源系统,力图用中立、开源共建来支撑业界统一、易用的评测工具,并通过引入自动化方法来提高评测的效率,加快 AI 芯片的产业落地。
FlagDATA
它是帮助用户对海量的训练数据集进行数据高质量处理的工具。智源在过去三年积累的多种模态数据达几百 TB。在收集、清理、标注数据,把它变成高质量数据集的过程中,也沉淀了许多数据处理经验和工具软件,此次将其开源,以便所有大模型开发团队和开发者能便捷地进行高质量的数据处理,加快大模型的研发。
以上是 FlagOpen 飞智大模型技术开源体系的整体情况。当越来越多的产品不同程度地建立在开源基础上,成为技术发展的一大趋势,这种集约化的方式,也将汇聚人类智慧,让产业实现更快速的发展。
开源在全球多年的发展已经证明了它的优势,它在某种程度降低了风险。成功的开源项目往往由多家企业共同维护,同时有很多开发者在使用过程中汇报、反馈BUG,因此开源软件往往会比闭源软件在技术风险上、技术问题上得到更快解 决、漏洞更快被捕杀。这也是云计算、操作系统、大数据,以及如今的 AI 都倾向于开源的原因。

漫漫摘星路
如今大模型声量宏大,但是实际来看其技术还需不断深耕才能在未来十年成功落地。智源在此时开源 FlagOpen 飞智体系,更像是撒下一粒种子,让更多的企业和团队联手,帮助国内大模型初创团队前进,带动 AI 芯片产业紧抓大模型十年发展的黄金机遇,推动全球开放创新。
同时,智源也立下了几大目标:在未来三年打造最大高质量的多种模态评测数据集;构建全球覆盖领域、维度最为完整的大模型评测平台,做到人人贡献、人人测评;打造全球领先的大模型技术开源体系。
大模型技术落地并非一蹴而就,国内的发展更是需要构建扎实的技术栈。在这股浪潮中所有科研、技术团队,需要更加脚踏实地,做最扎实的技术,勇敢寻求创新,才能摘到未来十年最亮的那颗星星。
演讲嘉宾简介:

林咏华现任北京智源人工智能研究院副院长兼总工程师, 主管大模型研究中心、人工智能系统及基础软件研究、产业生态合作等重要方向。IEEE 女工程师亚太区领导组成员,IEEE 女工程师协会北京分会的创始人。曾任 IBM 中国研究院院长,同时也是IBM 全球杰出工程师,在 IBM 内部引领全球人工智能系统的创新。从事近 20 年的系统架构、云计算、AI 系统, 计算机视觉等领域的研究。本人有超过 50 个全球专利,并多次获得 ACM/IEEE 最佳论文奖。获评 2019 年福布斯中国50位科技领导女性。
推荐阅读:
>>微软 154 页研究论文刷屏,对 GPT-4 最全测试曝光,称其初次叩开 AGI 的大门!
>>ChatGPT 已成为下一代的新操作系统!
>>谜题科技发布Enigma Alpha平台,开启AI生成决策动作篇章!