DragGAN图像生成原理与实现
- DragGAN模型是什么呢
- 1. DragGAN背景介绍
- 2. 模型方法
- 2.1 算法原理
- 2.1.1 Motion Supervision
- 2.1.2 点跟踪
- 3. 实现部署步骤
- 3.1 安装PyTorch
- 3.2 安装 DragGAN
- 3.3 运行 DragGAN Demo
- 3.4 功能介绍

项目地址:https://github.com/Zeqiang-Lai/DragGAN
论文地址:https://vcai.mpi-inf.mpg.de/projects/DragGAN/
代码地址:https://github.com/XingangPan/DragGAN
它说6月份发布

DragGAN模型是什么呢
简单来说就是可以通过用鼠标扮演手柄的角色,在图片中实现图像点拖拽,进而来实现人动物的五官,形态变换。如下图一样,



实现如上面视频那样符合用户需求的视觉内容通常需要对生成对象的姿态、形状、表情和布局具有灵活和精确的可控性。在现有的方法通过手动注释的训练数据或先前的3D模型来获得生成对抗网络(GANs)的可控性,但这往往缺乏灵活性、精确性和普适性,因此提出了DragGAN模型
DragGAN模型,探索了一种强大但鲜为人知的控制GANs的方法,即以用户交互的方式“拖动”图像中的任何点以精确达到目标点,如图1所示。为了实现这一目标,我们提出了DragGAN,它由两个主要组件组成:
- 基于特征的运动监督:驱动手柄点向目标位置移动
- 一种新的点跟踪方法,利用判别式生成器特征来不断定位手柄点的位置。通过DragGAN,任何人都可以对图像进行变形,并精确控制像素的位置,从而操纵姿态、形状、表情等。由于这些操作是在GAN的学习生成图像流形上执行的,它们倾向于在挑战性场景下产生逼真的输出,例如幻想遮挡内容和形变形状,同时保持对象的刚性。定性和定量比较证明了DragGAN在图像操作和点跟踪任务中相对于先前方法的优势。
这里的手柄点就是我们的鼠标点,通过鼠标点击需要拖拽的位置,进行向目标位置移动
1. DragGAN背景介绍
深度生成模型,如生成对抗网络(GANs),在合成逼真图像方面取得了重大进展。然而,在实际应用中,对合成图像内容的可控性是一个关键需求。为了满足用户的多样化需求,理想的可控图像合成方法应该具备灵活性、精确性和普适性。
先前的方法只能满足其中一些特性,因此我们的目标是在本研究中实现所有这些特性。先前的方法通常通过3D模型或依赖手动注释数据的监督学习来实现对GANs的可控性。然而,这些方法无法推广到新的对象类别,且在编辑过程中缺乏精确控制。最近,文本引导的图像合成引起了关注,但在编辑空间属性方面缺乏精确性和灵活性。
为了实现GANs的灵活、精确和通用的可控性,本研究探索了一种强大但较少被探索的交互式基于点的操作方法。我们允许用户在图像上选择手柄点和目标点,并旨在通过这些点使手柄点达到相应的目标点。这种基于点的操作方法允许用户灵活地控制空间属性,且不受对象类别的限制。
2. 模型方法
在这里,我们先简要的介绍一下图像生成模型中必备的基础知识 - 图像潜在空间向量
潜在空间向量:在StyleGAN中,潜在空间向量是一种表示图像特征的潜在变量。这些向量被用作输入,通过生成器网络来生成逼真的图像。潜在空间向量在StyleGAN中扮演着关键的角色,它们决定了生成的图像的外观、风格和特征。
潜在空间向量的每个元素都代表了生成图像的某种特征。通过修改潜在向量的不同元素,可以控制生成图像的各个方面,如颜色、纹理、形状等。这使得潜在空间向量成为一种强大的工具,可以实现对生成图像的可控编辑。
也可以说潜在空间就是图像在计算机视角下的特征表示
2.1 算法原理
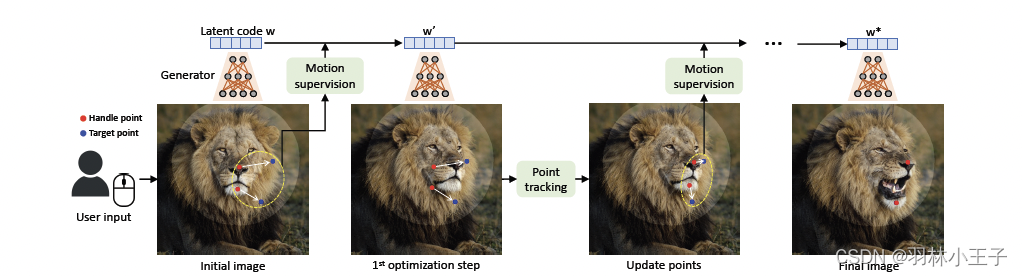
在DragGAN算法流程概览如上图所示。
算法流程用一句话来说:
先将原始的图像生成为潜在空间 w w w, I ∈ R 3 × H × W I \in R^{3 \times H \times W} I∈R3×H×W,并通过Motion Supervision实现图像的拖拽交互转换,映射为新的潜在空间 w ′ w' w′,并由潜在空间转换为生成后的图像
图像潜在空间的转换,其实就是每一个像素点的移动,转换。
在这里我们可以假设原始图像的潜在空间像素点为:
p i = ( x p , i , y p , i ∣ i = 1 , 2 , . . , n ) {p_i = (x_{p,i},y_{p,i}|i=1,2,..,n)} pi=(xp,i,yp,i∣i=1,2,..,n)
对应到交互转换后的潜在空间像素点为:
t i = ( x t , i , y t , i ∣ i = 1 , 2 , . . , n ) {t_i = (x_{t,i},y_{t,i}|i=1,2,..,n)} ti=(xt,i,yt,i∣i=1,2,..,n)
(即 𝒑𝑖 的对应目标点是 𝒕𝑖)。
目的是移动图像中的对象,使得这些点达到它们相应的目标点。
还可以允许用户选择性地绘制一个二进制掩码 M,指示图像中可移动的区域。
DragGAN算法步骤包括两个子步骤
- Motion Supervision
- 点跟踪。
在Motion Supervision中,使用使控制点向目标
点移动的损失函数来优化潜在空间 w w w。经过一次优化步骤,我们得到一个新的潜在空间 w ′ w' w′和一个新的图像 I ′ I' I′。更新会导致图像中对象轻微移动。
需要注意的是,运动监督步骤只会使每个控制点向其目标点移动一小步,但具体步长不清楚,因为它受到复杂的优化动态的影响,因此对于不同的对象和部分来说是不同的。
因此,我们更新控制点的位置 p i p_i pi,以跟踪对象上的相应点。这个跟踪过程是必要的,因为如果控制点(例如,狮子的鼻子)没有准确跟踪,那么在下一个运动监督步骤中,会监督错误的点(例如,狮子的脸),导致不期望的结果。在跟踪之后,我们基于新的控制点和潜在空间重复上述优化步骤。这个优化过程会一直持续,直到控制点 p i p_i pi达到目标点 t i t_i ti的位置,在我们的实验中通常需要30-200次迭代。用户也可以在任何中间步骤停止优化。编辑完成后,用户可以输入新的控制点和目标点,并继续编辑,直到满意为止。
2.1.1 Motion Supervision
如何计算GAN生成图像中二个点之间的损失呢
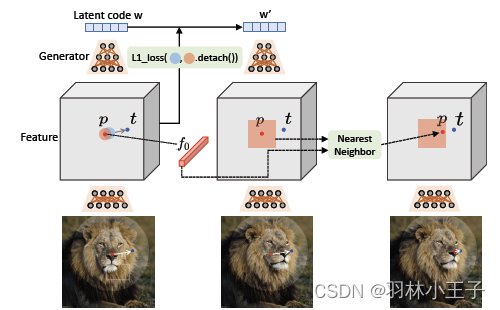
在计算损失中,论文提出了一种Motion Supervision损失。具体而言,使用StyleGAN2第6个块后的特征图F,它在所有特征中表现最好,因为在分辨率和辨别性之间取得了良好的平衡。我们通过双线性插值将F调整为与最终图像具有相同的分辨率,
然后通过将图中的(蓝色圆圈)围绕 p i p_i pi(红色圆圈)的一个小区域移动 t i t_i ti。我们使用 Ω 1 ( p i , r 1 ) \Omega_1 (p_i,r_1) Ω1(pi,r1)表示到 p i p_i pi的距离到 r 1 r_1 r1的像素点,然后我们的运动监督损失为:
L = ∑ i = 0 n ∑ q i ∈ Ω 1 ( p i , r 1 ) ∣ ∣ F ( q i ) − F ( q i + d i ) ∣ ∣ 1 + λ ∣ ∣ ( F − F 0 ) ⋅ ( 1 − M ) ∣ ∣ 1 L=\sum_{i=0}^n \sum_{q_i \in \Omega_1(p_i,r_1)} ||F(q_i)-F(q_i+d_i)||_1+\lambda||(F-F_0) \cdot (1-M)||_1 L=i=0∑nqi∈Ω1(pi,r1)∑∣∣F(qi)−F(qi+di)∣∣1+λ∣∣(F−F0)⋅(1−M)∣∣1
其中, F ( q ) F(q) F(q)表示q处F的特征值, d i = t i − p i ∣ ∣ t i − p i ∣ ∣ 2 d_i=\frac{t_i-p_i}{||t_i-p_i||_2} di=∣∣ti−pi∣∣2ti−pi是从 p i p_i pi指向 t i t_i ti的归一化向量(如果 t i = p i t_i=p_i ti=pi,则 d i d_i di=0),
F 0 F_0 F0是对应于初始图像的特征图。需要注意的是,第一项是在所有控制点 p i p_i pi上求和。由于 q i + d i q_i+d_i qi+di的分量不是整数,因此 F ( q i + d i ) F(q_i + d_i) F(qi+di)是通过双线性插值获得的。
如果给定了二值掩码M,就需要使用损失函数的第二项的重构损失来固定未被掩码覆盖的区域。在每个运动监督步骤中,使用此损失来优化潜在空间 w w w的一个步骤。 w w w可以在 w w w空间或 w + w^+ w+空间中进行优化。
2.1.2 点跟踪
在之前的Motion Supervision中,我们得到了一个新的潜在空间 w ′ w′ w′,新的特征图 F ′ F′ F′ 和新的图像 I ′ I′ I′。由于Motion Supervision步骤不能直接提供手柄点的精确新位置,我们的目标是更新得到每个手柄点 p i p_i pi,使其跟踪物体上的相应点。
因此,论文为GAN提出了一种新的点跟踪方法。其关键思想是GAN的判别特征很好地捕捉到了密集对应关系,论文通过在特征周围进行最近邻搜索来,找到最邻近的那个点,来有效地执行跟踪。
这里有点像卡曼滤滤波 sort目标跟踪一样,通过前后两帧检测框的中心点的距离来判断是否是同一个目标
具体而言,我们将初始手柄点的特征表示为 f i = F 0 ( p i ) f_i = F_0(p_i) fi=F0(pi)。
p i p_i pi的周围点可以表示为
Ω 2 ( p i , r 2 ) = { ( x , y ) ∣ ∣ x − x p , i ∣ < r 2 , ∣ y − y p , i ∣ < r 2 } \Omega_2(p_i,r_2) = \lbrace (x,y)| \space |x − x_{p,i} | < r_2, |y − y_{p,i} | < r_2 \rbrace Ω2(pi,r2)={(x,y)∣ ∣x−xp,i∣<r2,∣y−yp,i∣<r2}
然后通过在 Ω 2 ( p i , r 2 ) \Omega_2(p_i,r_2) Ω2(pi,r2) 中搜索与 f i f_i fi 最近的邻居来获取跟踪点:
p i = a r g m i n q i ∈ Ω 2 ( p i , r 2 ) ∣ ∣ F ′ ( q i ) − f i ∣ ∣ 1 p_i=argmin_{q_i \in \Omega_2(p_i,r_2)} ||F′(q_i)-f_i||_1 pi=argminqi∈Ω2(pi,r2)∣∣F′(qi)−fi∣∣1
通过这种方式, p i p_i pi被更新以跟踪物体。对于多个手柄点,我们对每个点应用相同的过程。
大白话来说,我感觉原理就是,先通过对多个目标,多角度多形态拍摄,然后有监督的,学习这些变化,最后为了使每个图像生成出的图像每个五官位置细节都能对应上,用了一种最近邻的跟踪匹配算法
3. 实现部署步骤
项目环境要求python3.7
进入到终端环境中
conda create -n draggan python=3.7
3.1 安装PyTorch
激活一下刚刚创建的环境,输入以下指令即可
conda activate draggan
参考PyTorch的 官方安装教程

我的GPU环境是CUDA11.2
pip install torch torchvision torchaudio -f https://download.pytorch.org/whl/cu112/torch_stable.html
没有GPU的用户用这个指令安装
pip install torch torchvision torchaudio
3.2 安装 DragGAN
安装完成之后,我们安装DragGAN,这可以通过以下指令进行、
pip install draggan
3.3 运行 DragGAN Demo
你可以通过以下指令运行 DragGAN 的 Demo
python -m draggan.web
没有GPU的用户,使用
python -m draggan.web --device cpu
当出现这个网址的时候 http://127.0.0.1:7860 ,说明程序已经成功运行
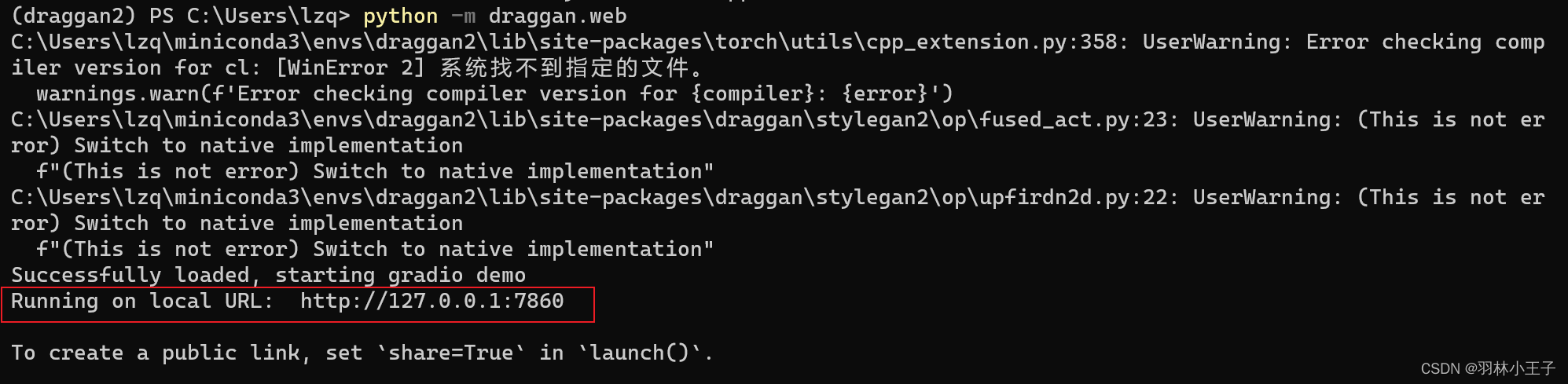
将这个网址输入到浏览器里就可以访问到 DragGAN 的 Demo 了
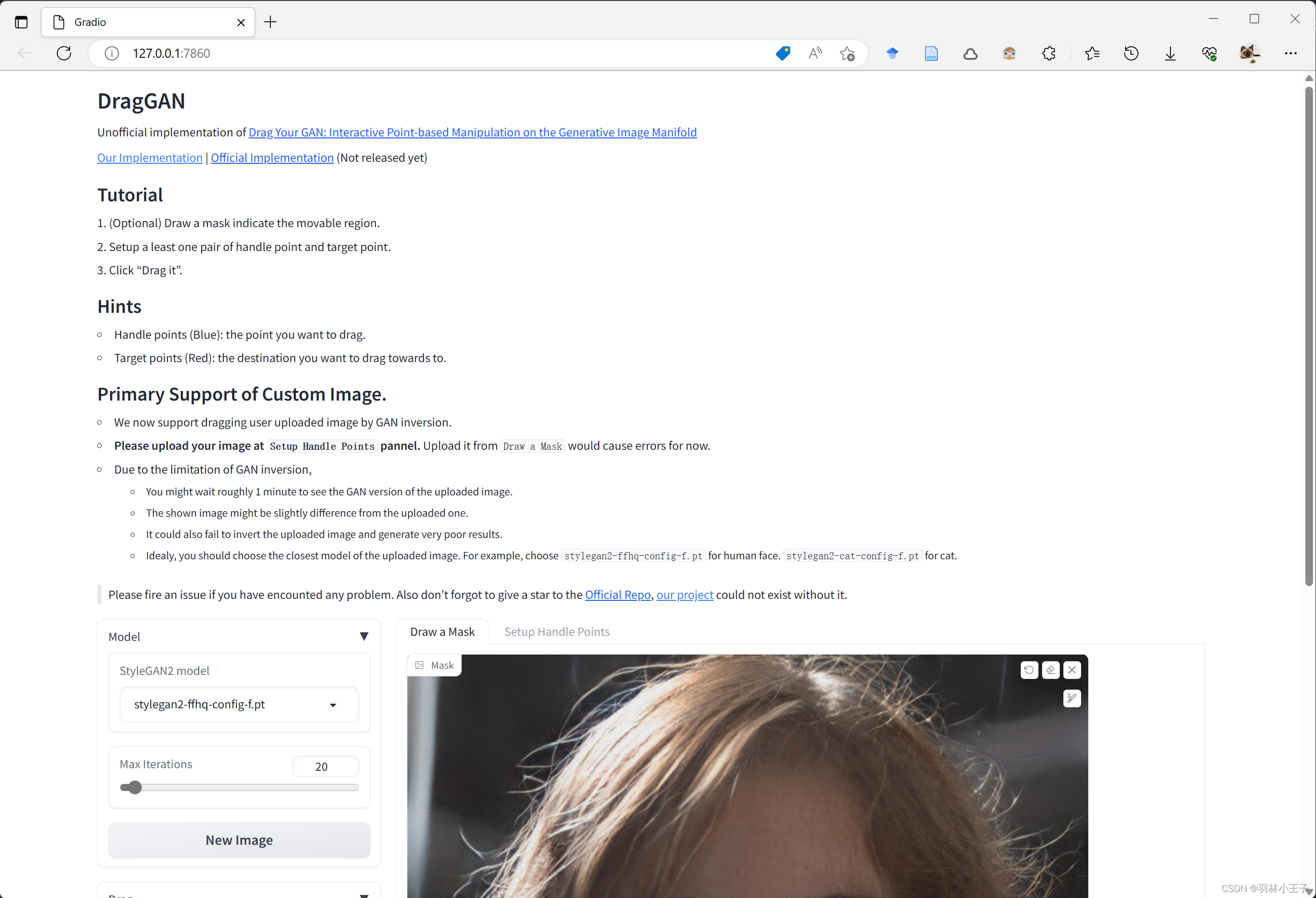
3.4 功能介绍
界面功能介绍如下
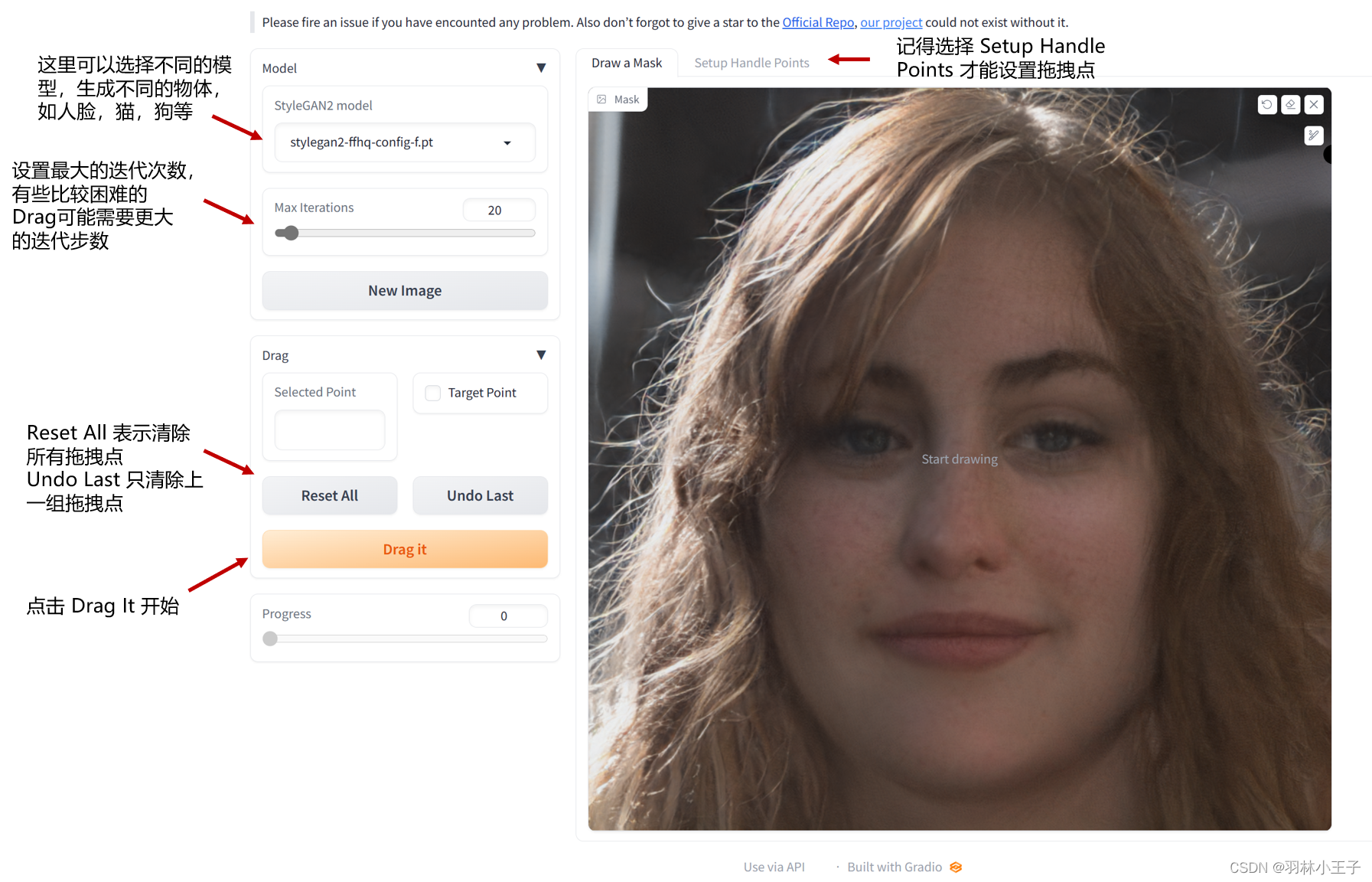
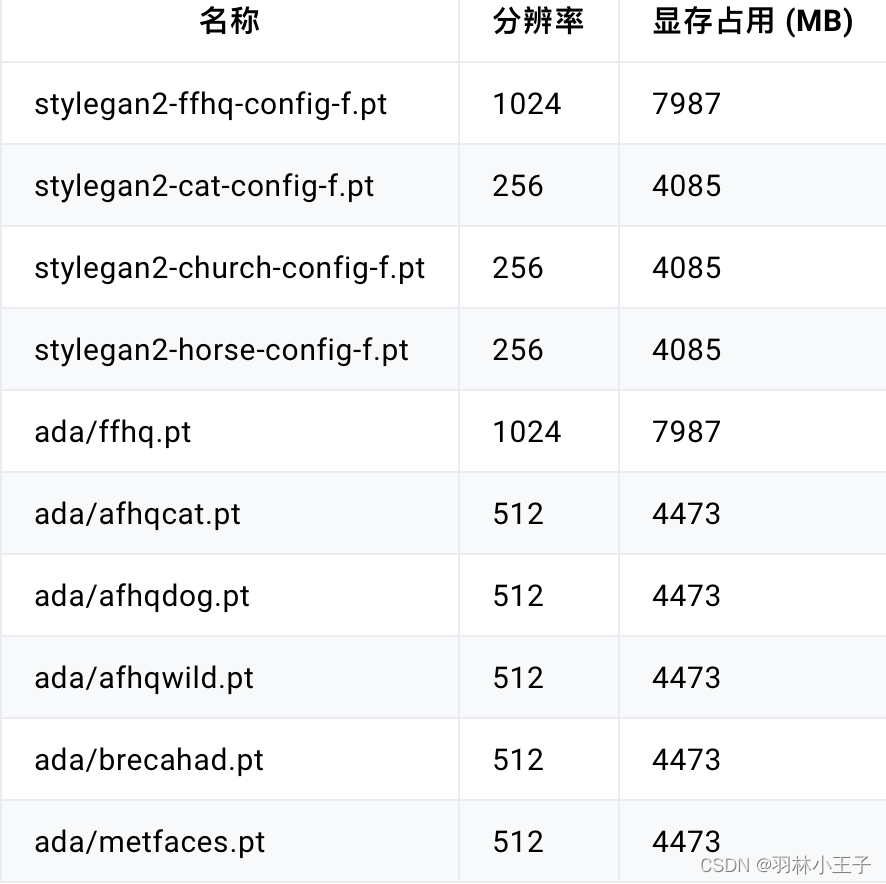
选择模型:目前我们提供了10个模型(在web界面选择后会自动下载),不同模型输出图片分辨率,和对显存要求不一样,具体如下
模型信息汇总
- 最大迭代步数:有些比较困难的拖拽,需要增大迭代次数,当然简单的也可以减少。
- 设置拖拽点对,模型会将蓝色的点拖拽到红色点位置。记住需要在 Setup handle points 设置拖拽点对。
- 设置可变化区域(可选):这部分是可选的,你只需要设置拖拽点对就可以正常允许。如果你想的话, 你可以在 Draw a mask 这个面板画出你允许模型改变的区域。注意这是一个软约束,即使你加了这个mask,模型还是有可能会改变超出许可范围的区域。





![移动端IM产品RainbowChat[专业版] iOS端 v6.0版已发布!](https://img-blog.csdnimg.cn/img_convert/a6eadc0f97a0c9d7213fe11a59acc52e.jpeg)

![[iPhone高级] 基于XMPP的IOS聊天客户端程序(IOS端三)](https://img-my.csdn.net/uploads/201207/16/1342411906_4192.png)



