本文转载自 读芯术

图源:unsplash
通过分析数千条推文,我们找到了热门的星座推特账号,利用机器学习Bertmoticon包来分析预测每个星座的表情。结果让我们大吃一惊!
首先,我们在推特上进行搜索,通过粉丝的数量和最近推文的热度(点赞数)找到每个星座的最热推特账号,然后从每个推特账号中检索最近的推文。为过滤掉垃圾信息,我们找的这些推文至少要有100个赞。

占星在推特上的点击量接近400万次,每个星座的潜在点击量平均达到11万次,可见占星学在推特上有相当多的粉丝。
我们对推文文本进行了预处理和清理,筛去了杂项信息,删除了标签、URL、用户名、停止词。这样,当我们把关于各星座的推文输入到Bertmoticon库中时,结果将更加准确。它推断出一本表情字典,我们将其转换为概率。
以一条来自@VirgoTerms且经过清理的推文为例:“处女座的人喜欢把工作中的收获带到家里的餐桌上,他们喜欢和家人分享这些事情。”
以下是Bertmoticon根据这条推文推断出的相关表情的前四名(已删去停止词):😂概率为26.2%,😍概率为18.0%,😊概率为10.3%,🙏概率为5.7%。
为了帮助理解如何在Python中清理推文,我们导入了上一步的CSV文件,并编写了几个不同的函数应用到CSV中的文本列。实现的功能如下:
- 去掉停止词:停止词指的是那些不能增加信息价值的常见词,如“the”、“and”。这就减少了估计误差,尤其是在数据点较少的情况下。
stop_words =set(stopwords.words("english"))text = tokenization(text) # breaks up text into a list of wordsfiltered_tweet = [w for w in text if not w in stop_words]
- 使用SnowballStemmer进行词根处理:将单词还原为词根(例如“loves” “loved” “loving”都还原为 “love”)。虽然要以增加贝叶斯误差作为代价,但这大大降低了估计误差。
sb = SnowballStemmer("english")# assumes text has already been tokenizedfor word in text:print(word, " : ",sb.stem(word))
- 从提取的推文中删除不必要的文本:链接、话题标签、@用户名、转发标志(“RT”)、数字,这些都与文本整体信息无关。
import re# removes urls or image links with httppattern = r"httpS+"text = re.sub(pattern, "",text)
清理完文本后,我们运行Bertmoticon,以给定的概率推断出每条推文相关表情的前四名。我们从CSV文件中生成一个推文列表,并对列表中的每个字符串运行Bertmoticon。
import bertmoticonfrom csv import DictReaderwith open( gemini.csv , newline= ) as f:ls_of_strings =[row["text"] for row in DictReader(f)]emojis = bertmoticon.infer(ls_of_strings, 4)
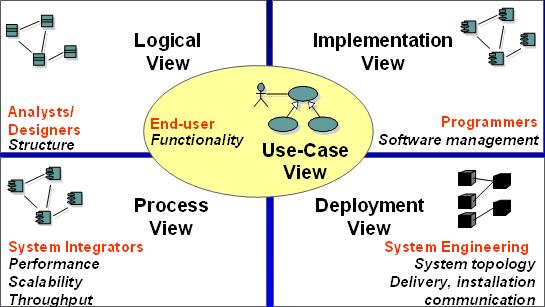
风象星座
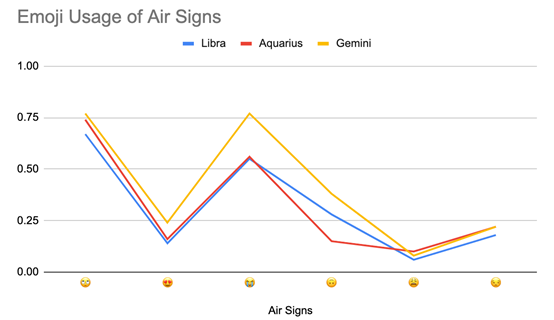
y轴上的概率表示表情符号被列入与推文相关表情符号前四名的次数。
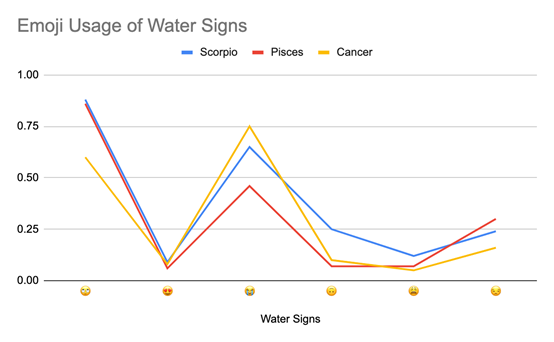
水象星座
火象星座
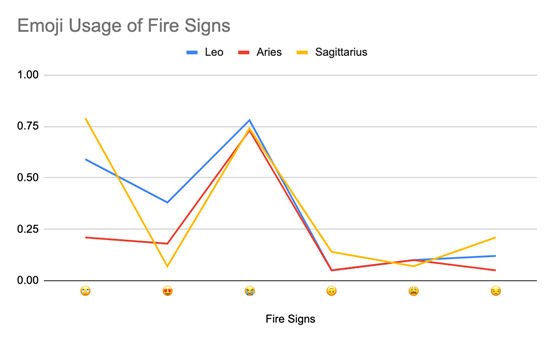
火象星座与其他象星座的共通模式相差最大。
土象星座
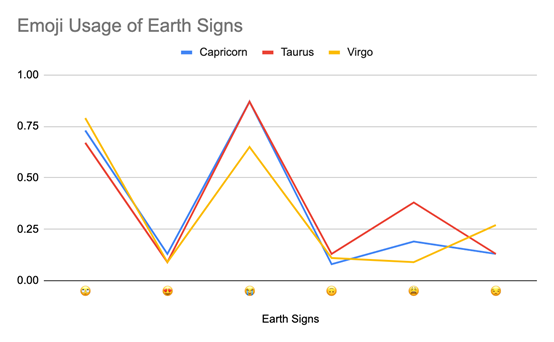
结果
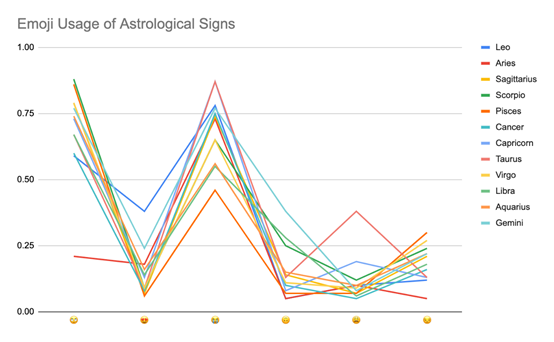
尽管按土象、气象、风象、火象进行了分组,除了一些异常值,检测到的各星座表情符号总体模式非常相似。
虽然我们不能根据表情符号的使用和选择来判断人们的性格特征,但各星座常用表情的大致趋势能帮助我们推断出,不同星座的性格特征比我们想象的更为相近。
例如,按照互联网上讨论的星座刻板印象内容来说,会是白羊座和双子座最常用的表情,因为他们被称为最情绪化和最有态度的星座。然而,最终结果告诉我们,表情符号对于处女座、射手座、双鱼座和天蝎座来说最为常见,而这些星座是不该有无礼或情绪化的特点的。
当根据不同星座的性格特征分析表情符号的类型时,可以发现很多方面都存在这种偏差。每个星座和表情的使用频率比其他4种表情的使用频率都要高。
尽管人们对不同星座有着相应的刻板印象,但从我们从代表各星座的推文中发现,这些星座特征比我们想象的更为相近。如上文的折线图所示,同一表情符号在不同的星座里出现的概率大致相同。快去看看自己星座的折线图吧!
原文链接:https://blog.csdn.net/duxinshuxiaobian/article/details/111713924





![移动端IM产品RainbowChat[专业版] iOS端 v6.0版已发布!](https://img-blog.csdnimg.cn/img_convert/a6eadc0f97a0c9d7213fe11a59acc52e.jpeg)

![[iPhone高级] 基于XMPP的IOS聊天客户端程序(IOS端三)](https://img-my.csdn.net/uploads/201207/16/1342411906_4192.png)


