本博客为博主论文阅读记录,原论文和github地址如下:
原论文下载:https://ojs.aaai.org/index.php/AAAI/article/view/17723/17530
代码:https://github.com/RowitZou/topic-dialog-summ
本篇博客所介绍论文为AAAI 2021论文
NLP领域有哪些国际顶级会议?
对话文本摘要概述
仅供学习,请勿转载。如有侵权,请联系作者删除。
Topic-Oriented Spoken Dialogue Summarization for Customer Service with Saliency-Aware Topic Modeling
摘要
在客户服务系统中,对话摘要可以通过自动创建长时间的用户和客服试图解决有关特定主题的问题对话的摘要来提高服务效率。在这项工作中,我们专注于主题导向(topic-oriented)的对话摘要,它生成高度抽象的摘要,保留了对话的主要思想(main ideas)。在口语对话中,大量的对话噪音和常用语可能会模糊潜在的信息内容,使一般主题建模方法难以应用。此外,对于客户服务来说,特定于角色的信息很重要,也是摘要中不可或缺的一部分。为了有效地对对话进行主题建模并捕获多角色信息,在这项工作中,我们提出了一种新的主题增强两阶段对话摘要器(TDS)和显著性感知神经主题模型(SATM),用于面向主题的客服对话摘要。对真实的中国客户服务数据集的综合研究表明,我们的方法相对于几个强大的基线具有优越性。
这里common semantics指的是常用语,例如thanks,humm,please?还是共同语义的表达?我认为作者的意思是前者。
1 Introduction
在一个活跃的客户服务系统中,在用户(customers)和客服(agents)之间实时生成大量传递重要信息的对话。在这样的背景下,如何有效地利用对话信息成为一个非常重要的问题。对话摘要是一项旨在浓缩对话,同时保留显著(salient)信息的任务,它可以通过自动创建简明摘要来提高服务效率,避免耗时的对话阅读和理解。
大多数现有的对话摘要工作主要集中在冗长而复杂的口头对话,如会议和法庭辩论,通常通过串联所有对话点来摘要,以保持完整的对话流程。然而,在客服场景中,对话演讲者通常有强烈而明确的动机,并致力于解决有关特定主题的问题。更好地了解用户和客服的意图,在这项工作中,我们专注于面向主题的对话摘要,它旨在提取语义一致的主题并生成高度抽象的摘要,以保持对话的主要思想。
最近,已经引入了数十种主题感知模型(topic-aware models)来帮助文档摘要任务。然而,口语对话往往是由话语(utterances)组成的,而不是传统文献中符合语法规则的句子。突出信息(Salient information)在这些话语中被稀释,并伴随着常用语(common semantics)。此外,噪音以不相关的聊天和转录错误的形式大量存在。这些常见或嘈杂的单词,例如,请(please)、谢谢(thanks)和哼(humm),通常频率很高,并与其他信息性单词同时出现。因此,一般的基于主题的方法很难统计地区分有用和无用内容的混合,从而导致对主题分布的不准确估计。此外,在客服对话场景,参与角色是稳定的:用户倾向于提出问题,客服需要提供解决方案。图1显示了一个真实的客服对话以及一个摘要,其中包括两位发言者的关键信息。因此,该模型还被期望捕获角色信息,以帮助显著信息估计。

C表示用户,A表示客服。摘要包含客户的问题(红色)和客服的解决方案(蓝色),分别以红色和蓝色突出显示。
在这项工作中,我们提出了一种新的两阶段神经模型和一种增强的主题建模方法,用于口语对话摘要。第一,为了更好地将潜在信息内容与丰富的常用语和对话噪声区分开来,我们引入了一种显著性感知主题模型(SATM),其中主题被分成两组:信息性主题(informative topics)和其他主题(other topics)。在话题建模的生成过程中,我们限制了与黄金摘要(gold summary)相对应的每个突出单词从信息性话题中生成,而对话中的其他单词(包括噪声和常见的单词)仅从其他话题中生成。通过这个训练过程,SATM可以将对话中的每个单词与显著性(信息主题)或不显著性(其他主题)联系起来。第二,为了获取角色信息并从对话中提取语义主题,我们使用SATM分别对用户话语、客服话语和整体对话进行多角色主题建模。然后,设计了一个主题增强的两阶段对话摘要器(TDS),它由一个话语提取器(utterance extractor)和抽象提取器(abstractive refiner)组成。它可以通过了解主题的注意力机制(topic-informed attention mechanism)在话语水平和单词水平上提取与主题相关的显著信息。
此外,由于缺乏合适的公共基准,我们收集了一个具有高度抽象摘要的真实客服对话数据集。在所提出的数据集上的实验结果表明,我们的模型在各种指标下表现出一系列强基线。代码、数据集和补充可以在Github上找到。
总之,我们的贡献如下:
- 我们引入一种新的主题模型,通过直接学习单词显著性对应关系,可以感知对话中潜在的信息内容。
- 基于多角色主题建模,我们提出了一个主题增强的两阶段模型,该模型具有了解主题的注意力机制用于执行显著性评估和客服对话摘要。
- 在收集数据集上的实验结果表明我们的方法在不同方面的有效性。
2 Method
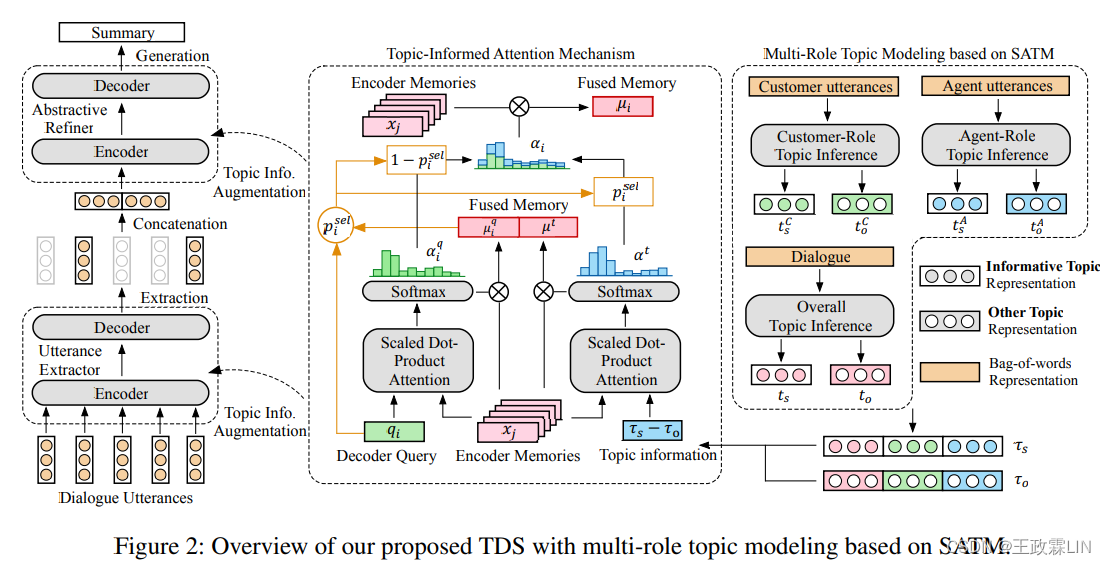
在本节中,我们将详细介绍显著性感知主题模型(SATM)和主题增强的两阶段对话摘要模型(TDS)。SATM基于信息主题和其他主题推断多角色主题表示。然后,主题信息通过主题通知注意机制被合并到TDS的提取器和精炼器中。
我们模型的总体架构如图2所示。
总体结构很重要!!!图二很重要!!!结合第二部分Method的所有内容理解。
extract提取出显著性的语句,通过refine,refine是精炼/提炼?
2.1 Saliency-Aware Neural Topic Model(SATM)
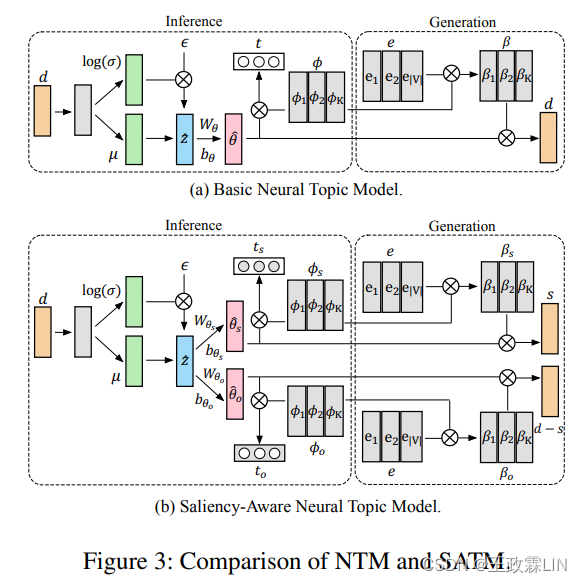
我们提出的SATM基于具有变分推理的神经主题模型(NTM),该模型通过神经网络从每个对话d中推断主题分布θ。我们用一种新的生成策略来扩展NTM,以学习单词显著性相关性。SATM与NTM的架构比较如图3所示。
图3得结构很重要,注意图3-(b)
SATM公式整理

2.1.1 Basic NTM with Variational Inference
从形式上讲,在去掉停止词的情况下给定对话d∈R^|V|的词袋表示,我们构建了一个推理网络q(θ|d)来近似后验p(θ| d),其中V是词典(vocabulary)。q(θ|d)由一个函数θ=f(z)组成,该函数以对角高斯分布z∼ N(µ(d),σˆ2(d))为条件,其中其中µ(d)和σ(d)是神经网络。在实践中,我们可以采样zˆ使用重新参数化技巧通过ˆz=µ(d)+eps·σ(d),eps从N(0,Iˆ2)中采样。然后,采样的ˆθ∈ RˆK导出为:
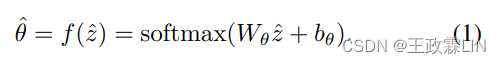
Wθ,bθ是可训练参数,K表示主题数。然后,我们定义β∈ RˆK×|V|, φ ∈ RˆK×H,e∈Rˆ|V |×H分别表示主题词分布、主题向量和词向量。这里,H是向量的维数。φ是随机初始化的,e可以是预先训练的词嵌入。β用φ和e计算如下:
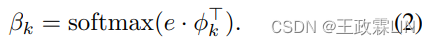
在生成部分,我们将p(d|β,θ)参数化,并将神经话题模型的损失函数定义为:
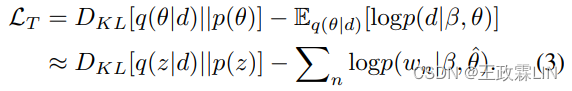
第一项使用KL散度来确保变量分布q(θ|d)类似于真实先验p(θ),其中p(θ)表示标准高斯先验N(0,Iˆ2)。在第二项中,wn表示d中的第n个观察词,d的对数似然可以用log(ˆθ·β)计算。
2.1.2 Learning Word-Saliency Correspondences
在口语对话中,大量的噪声和常用语随机出现,并与信息性词汇共同出现。同时,重要信息要被概括在对话摘要中。因此,我们假设每一段对话都是信息词语和其他词语的混合体,其中对应于黄金摘要(gold summary)的词语基本上是信息性的。我们将K个主题分为两组:信息主题和其他主题,其中主题编号分别为Ks和Ko(K=Ks+Ko)。给定从d导出的zˆ,信息主题ˆθs ∈ RˆK和其他主题ˆθo∈RˆK上的分布由具有不同参数的fs(·)和fo(·)推出:
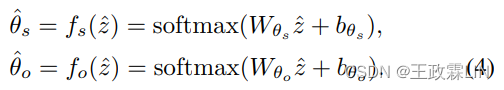
在主题建模的生成部分,我们使用s∈Rˆ|V|表示d的单词子集,其中每个单词出现在黄金摘要和原始对话中。因此,p(d|β,θ)的参数化被分解为:
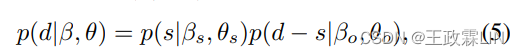
其中βs∈ RˆKs×|V|,βo∈ RˆKo×|V|以及φs∈RˆKs×H,φo∈ RˆKo×H是在两个主题组通过分裂β和φ得到的。等式5表明,摘要单词的主题分配受限在”信息主题“中,而对话中的其他单词则由“其他主题”收集。因此,对话中的每个单词都与显著性或不显著性相关。因此,给定wˆsˆn和wˆd−sˆn分别表示s和d中的第n个观察词,损失函数变为:
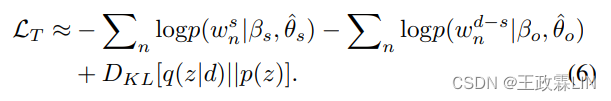
与NTM相比,所提出的SATM利用对话摘要将信息词从噪声和常用语中分离出来,避免了对混合了有用和无用的内容进行直接主题建模。因此,噪声和常用语很难掩盖潜在的信息词,从而使主题推理更加鲁棒(robust)。此外,只要有黄金摘要(gold summary),SATM可以很容易地用作外部模块,并与其他摘要模型相结合。
gold summary是什么?正确的理解应该是?
bag-of-words:词袋(参考:Bag-of-words 词袋模型基本原理、词袋模型(bag-of-words)学习记录 2020-12)
什么是幻觉? 【论文笔记】On Faithfulness and Factuality in Abstractive Summarization
2.1.3 Multi-Role Topic modeling
基于SATM,我们输入d(对话)并推导主题表示ts∈RˆH和to∈RˆH根据:
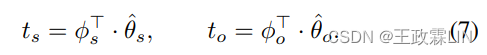
在这里,ts可以被视为一个主题向量在捕获"信息主题"的信息的同时to收集噪声和常用语,这两者都将被纳入到TDS模型中,以促进显著性估计。此外,为了捕获角色特定信息,我们分别对用户话语和客服话语进行主题建模。给定词袋表示用户话语dˆC∈Rˆ|V|和客服话语dˆA∈Rˆ|V|,我们可以推出主题分布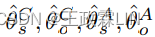 使用等式4。然后,不同角色的主题表示
使用等式4。然后,不同角色的主题表示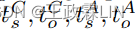 可以类似等式7获得。因此,我们总共有三个主题模型,分别在用户话语、客服话语和整体对话上有不同的参数。
可以类似等式7获得。因此,我们总共有三个主题模型,分别在用户话语、客服话语和整体对话上有不同的参数。
2.2 Topic-Augmented Two-Stage Dialogue Summarizer(TDS)
在客服场景中,口头对话很长并且有时是被扭曲的,其中大多数话语都是无关紧要的,甚至是噪声,是可以直接过滤掉的。因此,我们采用两阶段摘要器,首先选择突出话语,然后**精练(refine)**它们。基本的两级摘要器由话语提取器和抽象精炼器组成。提取器将每个话语ui编码为话语表示hi,并使用指针网络(Pointer Network)基于hi反复提取话语。精炼器是一个标准的Seq2seq模型,可以根据提取的语句生成简明摘要。为了连接提取器和精炼器,应用了策略梯度技术(PG)来训练整体摘要模型,其中我们使用LS来表示损失函数。
在这项工作中,我们使用Transformer作为TDS的基本编码器层和解码器层。对于对话中的第i个语句,我们有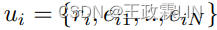 其中ri是一个角色嵌入表示ui说话者,可以是用户或客服,eij是第j个词的词嵌入。有关基本两阶段模型和我们的实施的更多详细信息,请参阅Chen and Bansal(2018)以及由于篇幅限制的补充。
其中ri是一个角色嵌入表示ui说话者,可以是用户或客服,eij是第j个词的词嵌入。有关基本两阶段模型和我们的实施的更多详细信息,请参阅Chen and Bansal(2018)以及由于篇幅限制的补充。
2.2.1 Topic Information Augmentation
为了捕获角色信息并突出整体主题,我们通过主题知情的注意力机制将多角色主题表示引入Transformer解码器用于显著性评估,这是多头注意力的扩展。形式上,假设qi表示第i个查询解码步骤( decoding step of the query),xj表示j记忆模块(memory)中的第j个元素,则每头的原始注意机制定义为:
这个式子没搞懂?
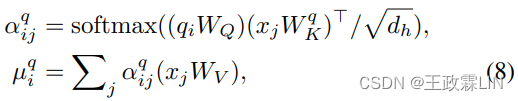 其中WQ、Wq-K、WV是可训练参数,dh是每个头的维度。µq-i是基于第i个解码步中的查询融合显著信息向量。在一般的解码过程中,融合记忆模块在每一步的状态取决于先前解码序列,其中可能会累积错误。这里,我们还使用全局主题和角色信息作为指导,通过测量记忆元素和多角色主题之间的相关性来帮助序列解码。形式上,我们设计了一个辅助注意力操作,如下所示:
其中WQ、Wq-K、WV是可训练参数,dh是每个头的维度。µq-i是基于第i个解码步中的查询融合显著信息向量。在一般的解码过程中,融合记忆模块在每一步的状态取决于先前解码序列,其中可能会累积错误。这里,我们还使用全局主题和角色信息作为指导,通过测量记忆元素和多角色主题之间的相关性来帮助序列解码。形式上,我们设计了一个辅助注意力操作,如下所示:
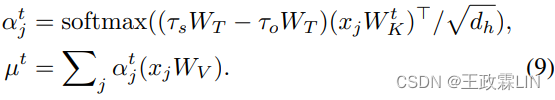
这里,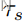 和
和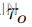 代表特定角色的主题表示,其中,当xj对应于用户说话者
代表特定角色的主题表示,其中,当xj对应于用户说话者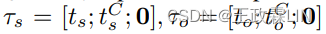 当xj对应于客服说话者
当xj对应于客服说话者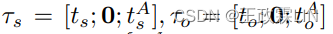 [·; ·] 表示连接,0是所有元素都设置为0的向量。在等式9中,我们设计αt-j,使得τs与τo由于对比注意(contrastive attention)引起相反,这鼓励对话题相关元素的关注,而不鼓励对噪声和常用语的关注。因此,τs和τo以相反的方式对总体目标做出贡献。µt可以被视为一个主题感知向量,它基本上丢弃了记忆中的噪声和无信息元素。最后,我们将上述两种注意力操作结合起来,在每个解码步骤中考虑全局主题和当前查询,并通过以下方式形成集成的记忆融合µi:
[·; ·] 表示连接,0是所有元素都设置为0的向量。在等式9中,我们设计αt-j,使得τs与τo由于对比注意(contrastive attention)引起相反,这鼓励对话题相关元素的关注,而不鼓励对噪声和常用语的关注。因此,τs和τo以相反的方式对总体目标做出贡献。µt可以被视为一个主题感知向量,它基本上丢弃了记忆中的噪声和无信息元素。最后,我们将上述两种注意力操作结合起来,在每个解码步骤中考虑全局主题和当前查询,并通过以下方式形成集成的记忆融合µi:
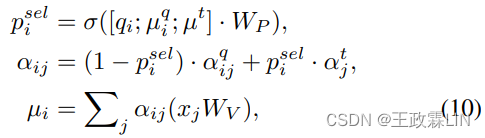 其中p sel-i∈(0,1)表示被用作在原始的基于查询的注意力或主题引导的注意力之间进行选择的软切换的选择性概率。注意力机制被进一步调整为多头方式。值得注意的是,我们将主题知情注意机制应用于话语提取器和抽象精炼器。对于提取器,xj表示第j个语句的隐藏状态。对于精炼者来说,xj表示所选语句中第j个单词的隐藏状态。因此,我们可以在语句水平和单词水平上进行由多角色主题信息辅助的显著性估计。
其中p sel-i∈(0,1)表示被用作在原始的基于查询的注意力或主题引导的注意力之间进行选择的软切换的选择性概率。注意力机制被进一步调整为多头方式。值得注意的是,我们将主题知情注意机制应用于话语提取器和抽象精炼器。对于提取器,xj表示第j个语句的隐藏状态。对于精炼者来说,xj表示所选语句中第j个单词的隐藏状态。因此,我们可以在语句水平和单词水平上进行由多角色主题信息辅助的显著性估计。
对比注意contrastive attention?
Transformer详解:(参考:史上最小白之Attention详解(上篇)、史上最小白之Transformer详解(下篇)
multi-head attention:(参考Attention,Multi-head Attention–注意力,多头注意力详解)
2.3 Joint Training
为了联合训练摘要模型和多角色主题模型,我们设计了一个联合损失,其中包括摘要器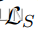 的损失函数和三个主题模型
的损失函数和三个主题模型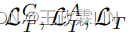 的损失函数,分别对应于用户话语、客服话语和整体对话。联合损失函数定义为:
的损失函数,分别对应于用户话语、客服话语和整体对话。联合损失函数定义为:
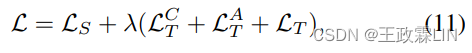 其中λ是用于平衡摘要模型和主题模型之间的损失的系数。
其中λ是用于平衡摘要模型和主题模型之间的损失的系数。
3 Experimentation
在本节中,我们描述了在真实的客户服务数据集上进行的实验。我们将我们提出的TDS+SATM与强基线进行了比较,并进一步分析了模型中不同部分的影响。所有超参数调整均在验证集上进行。完整的训练细节见补充资料。
3.1 Dataset
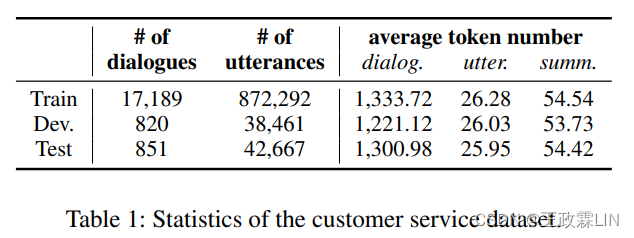
我们的客户服务对话数据集是从电子商务公司的客服中心收集。所有对话都是在用户和客服之间用汉语普通话进行的客户服务。每一轮服务结束后,客服都需要写一份关于对话的简短描述,其中主要包括用户面临的问题和客服提供的解决方案。对于每个对话示例,我们将客服人员的书面描述作为黄金摘要(gold summary)。所有对话最初都是音频形式,我们使用在客户服务对话中预先训练的ASR模型将其转录为文本(,字符错误率为9.3%。因此,最终的数据集包括由对话翻译和人写的书面摘要组成的对话-摘要对。我们总共收集了18.86K个对话和953K个语句,并将它们分成训练集(90%)、开发集(5%)和测试集(5%)。表1显示了收集的数据集的详细统计信息。
【深度学习】训练集、开发集和测试集
3.2 Comparison Methods
Ext Oracle(Nallapati et al.2017),其中贪婪算法被应用于选择话语,其组合使黄金摘要的被用作抽取方法的上限评估得分最大化。
**Seq2seq+Att(Nallapati et al.2016)**是一种标准的基于RNN的编码器-解码器模型,具有注意力机制。
**PGNet(See et al.2017)**有一个指针机制,其中解码器可以选择从词汇表中生成单词或从源文本中复制单词。
**Transformer(Vaswani et al.2017)**是一个基于注意力的模型,为此我们还使用复制机制实现了一个变体,称为CopyTransformer。
**BERT+Transformer(Liu and Lapata 2019)**由BERT编码器和Transformer解码器组成。它们使用不同的优化器进行调整,以减轻BERT和其他参数之间的不匹配。
**HiBERT(Zhang et al.2019b)**可以在单词层面和句子层面上对文档进行编码。这里,我们用BERT替换了单词水平的编码器,并添加了一个基本的Transformer解码器以实现Seq2seq学习。
**FastRL(Chen and Bansal 2018)**是基本的两阶段框架。我们基于Transformers来实现它,并使用BERT对其进行预训练,因为Transformer编码器可以很容易地与预训练的LMs相结合。
TDS+Topic Model是我们采用不同主题模型的方法,包括NTM和SATM。为了公平比较,我们还使用BERT作为单词水平(word-level)编码器。
3.3 Automatic Evaluation
表2显示了客户服务数据集的自动评估结果(系统输出示例见补充资料)。
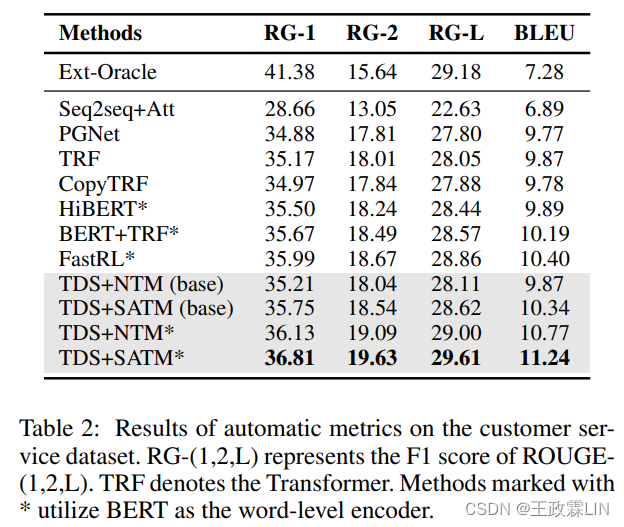 我们使用ROUGE F1(Lin 2004)和BLEU(Papineni等人,2002)评估摘要质量。我们使用系统输出和黄金摘要之间的unigram和bigram overlap(ROUGE 1,ROUGE 2)来评估信息性,使用最长公共子序列(ROUGE-L)来评估流利性。对于BLEU,我们最多使用4-grams,并平均不同gram的分数。所有度量(metrics)都是基于汉字计算的,以避免分词的影响。
我们使用ROUGE F1(Lin 2004)和BLEU(Papineni等人,2002)评估摘要质量。我们使用系统输出和黄金摘要之间的unigram和bigram overlap(ROUGE 1,ROUGE 2)来评估信息性,使用最长公共子序列(ROUGE-L)来评估流利性。对于BLEU,我们最多使用4-grams,并平均不同gram的分数。所有度量(metrics)都是基于汉字计算的,以避免分词的影响。
ngram:(参考:『NLP学习笔记』什么是ngram、NLP中的Ngram算法简易原理及overlap)
表2中的第一个块包含Oracle作为抽取方法的上限。第二块显示了抽象模型的结果。从表2中我们可以看到,大多数抽象方法在ROUGE-(2/L)和BLEU上都取得了有竞争力的结果,甚至超过了Ext-Oracle。它提供了证据表明我们的数据集收集了高度抽象的摘要,这需要一个系统来整合对话内容并产生连贯的话语。当引入SATM时,基本TDS+主题模型与其他基线相比取得了更好的的结果,并优于一些基于BERT的模型。在结合BERT之后,两阶段系统(FastRL/TDS)与其他Seq2seq方法相比表现出了优越的性能,该方法探讨了提取精炼(extract-refine)策略的有效性,并表明有用信息在长对话中会被稀释。当引入主题信息时,结果会进一步提高。TDS+NTM使用了基本的神经主题模型,并删除了等式9中的对比机制,这对FastRL带来了轻微的改进。相比之下,TDS+SATM在ROUGE(+0.82,+0.96,+0.75 on ROUGE-1/2/L)和BLEU(+0.84)上比FastRL性能显著提高,且p<0.05。它验证了主题信息有助于客户服务对话摘要,而带有单词显著性学习的SATM可以通过提高主题模型的质量进一步提高整体效果。
3.4 Human Evaluation
基于n-grams的自动评估指标可能不能真正反映生成式摘要的质量。因此,我们进一步随机抽取测试集中的100个样本进行人为评估。我们模仿Narayan at al.(2018)设计了实验,其中邀请三名志愿者比较PGNet、BERT+TRF、HiB-ERT、FastRL、我们提出的TDS+SATM和黄金摘要。每个志愿者都会收到一个对话和六个系统中两个系统的两个摘要,并被要求按照两个维度的顺序决定哪个摘要更好:信息性(哪一个摘要能捕捉对话中更重要的信息?)和流畅度(哪一个总结更流畅、更符合语法标准?)。我们根据随机对话和摘要的顺序,收集三名志愿者每项比较的判断结果。
表3给出了人为评估的系统排名结果。
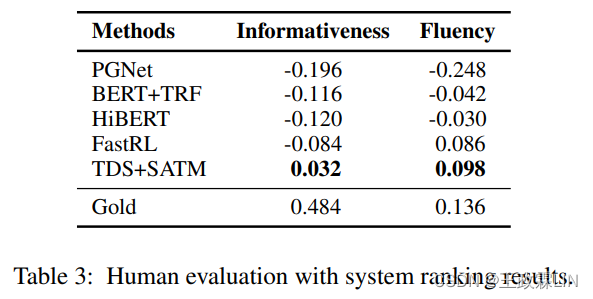 一个系统的得分计算为它被选为最佳的次数百分比减去被选为最差的次数百分比,范围从-1(最差)到1(最佳)。黄金摘要在两个维度上都排名最佳,这一点不足为奇。在信息性方面,TDS+SATM排名第二,其次是其他系统,这验证了我们提出的SATM和主题增强机制在帮助显著性估计方面的有效性。就流畅性而言,两阶段模型(FastRL/TDS)比其他基线考虑得更好,这表明extract-refine策略可以生成更流畅的摘要。我们还对系统进行了两两比较(使用二项双尾检验;空假设:两个系统同样好;p<0.05)。就信息性而言,TDS+SATM与所有其他系统有显著不同。就流畅度而言,两级系统与其他系统有显著不同,FastRL与TDS+SATM没有显著不同。
一个系统的得分计算为它被选为最佳的次数百分比减去被选为最差的次数百分比,范围从-1(最差)到1(最佳)。黄金摘要在两个维度上都排名最佳,这一点不足为奇。在信息性方面,TDS+SATM排名第二,其次是其他系统,这验证了我们提出的SATM和主题增强机制在帮助显著性估计方面的有效性。就流畅性而言,两阶段模型(FastRL/TDS)比其他基线考虑得更好,这表明extract-refine策略可以生成更流畅的摘要。我们还对系统进行了两两比较(使用二项双尾检验;空假设:两个系统同样好;p<0.05)。就信息性而言,TDS+SATM与所有其他系统有显著不同。就流畅度而言,两级系统与其他系统有显著不同,FastRL与TDS+SATM没有显著不同。
3.5 Analysis and Discussion
为了更好地理解角色信息、关注显著性的主题建模以及了解主题的注意力机制,我们进行以下定性分析。
3.5.1 Contribution of Role Information
表4显示了具有不同类型主题模型的TDS+SATM的结果。
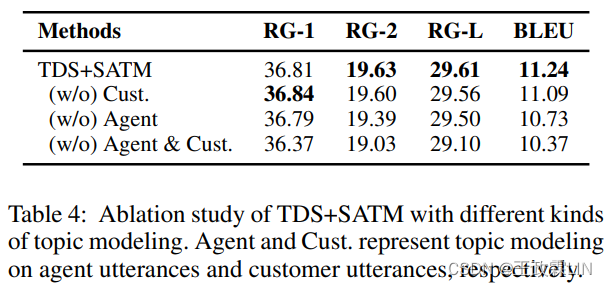 当我们删除用户话语或客服话语的主题模型时,结果不会受到明显影响。然而,在删除两个主题模型后,系统的性能显著下降(p<0.05)。这表明角色特定信息对于对话模型是有益的,并且至少应指定一个说话人以使角色内容可区分。
当我们删除用户话语或客服话语的主题模型时,结果不会受到明显影响。然而,在删除两个主题模型后,系统的性能显著下降(p<0.05)。这表明角色特定信息对于对话模型是有益的,并且至少应指定一个说话人以使角色内容可区分。
3.5.2 Effect of Topic Numbers in SATM
主题数是主题模型中的一个关键超参数,因为它可能影响收敛速度和推理质量。在这里,我们在图4中报告了具有不同主题数的TDS+SATM的结果。
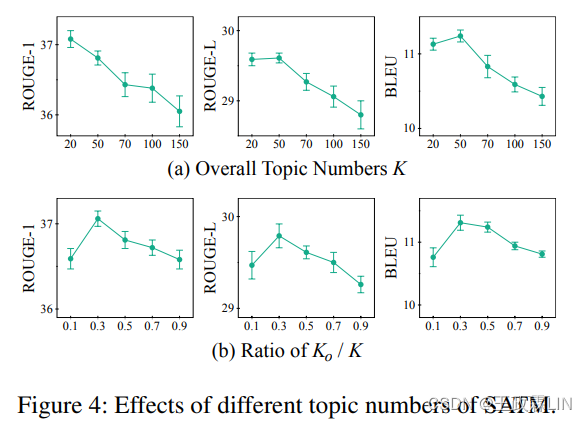 图4(a)显示了Ks=Ko时,K的影响范围为20至150。当K超过50后持续增加时,表现出性能下降趋势和方差增加趋势。它表明,适当的主题数足以捕获主要主题,而较大的主题数会使主题推断不稳定。图4(b)显示了Ko/K的不同比率的影响,其中我们固定K=50,并将Ko调整在5至45的范围内。结果表明,过于不平衡的Ks和Ko会影响性能。它表明,每个对话都是有用的和无信息的内容的混合体,在对话进行主题建模时,这两种内容都不能忽略。
图4(a)显示了Ks=Ko时,K的影响范围为20至150。当K超过50后持续增加时,表现出性能下降趋势和方差增加趋势。它表明,适当的主题数足以捕获主要主题,而较大的主题数会使主题推断不稳定。图4(b)显示了Ko/K的不同比率的影响,其中我们固定K=50,并将Ko调整在5至45的范围内。结果表明,过于不平衡的Ks和Ko会影响性能。它表明,每个对话都是有用的和无信息的内容的混合体,在对话进行主题建模时,这两种内容都不能忽略。
3.5.3 Comparison between NTM and SATM
为了彻底比较标准NTM和我们提出的SATM,我们分析了由TDS+主题模型学习的主题词分布β和主题向量φ。表5显示了不同主题组的主题示例,其中列出了β中概率最高的前10个单词。
 我们发现,信息性话题中的词语可以更好地反映特定的对话场景。例如,带有地址、发货和退款的主题1是关于发货问题;主题3与帐户、绑定和用户名有关的是帐户问题。相比之下,其他主题倾向于收集噪声和常用语,其中主题1的单词经常出现在不相关的闲聊中,而主题2包括客户服务场景中的常见单词。对于整体的NTM的主题,前10个单词显示了信息和常见内容的混合。此外,我们分析了主题向量φ,并使用t-SNE对SATM和NTM在实现二维可视化潜在空间。在图5(a)中,通过学习单词显著性对应关系和对比机制,SATM中两个主题组的向量被有效地映射到单独的区域,而在图5中(b),NTM的主题向量没有显示出明显的聚类。
我们发现,信息性话题中的词语可以更好地反映特定的对话场景。例如,带有地址、发货和退款的主题1是关于发货问题;主题3与帐户、绑定和用户名有关的是帐户问题。相比之下,其他主题倾向于收集噪声和常用语,其中主题1的单词经常出现在不相关的闲聊中,而主题2包括客户服务场景中的常见单词。对于整体的NTM的主题,前10个单词显示了信息和常见内容的混合。此外,我们分析了主题向量φ,并使用t-SNE对SATM和NTM在实现二维可视化潜在空间。在图5(a)中,通过学习单词显著性对应关系和对比机制,SATM中两个主题组的向量被有效地映射到单独的区域,而在图5中(b),NTM的主题向量没有显示出明显的聚类。

3.5.4 Case Study of Topic-Informed Attention Mechanism
图6显示了一个示例对话的注意力图,其中包含由TDS+SATM生成的翻译摘要。αˆq,αˆt,α分别表示基于查询的注意力、主题引导的注意力和最终的组合注意力。
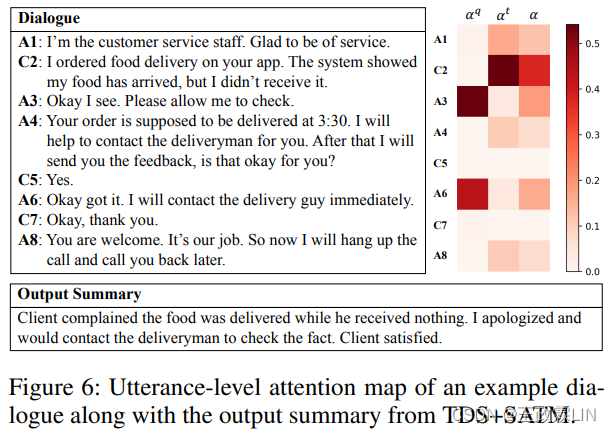 注意力分数从提取器的解码器中获取,以演示话语水平解码过程中的开始步骤。从这个例子中我们可以看出,话题引导注意力αˆt成功地将注意力集中在提及用户问题的突出话语上。然后组合注意力α比αˆt更好,并专注于最终有助于总结生成的适当话语。
注意力分数从提取器的解码器中获取,以演示话语水平解码过程中的开始步骤。从这个例子中我们可以看出,话题引导注意力αˆt成功地将注意力集中在提及用户问题的突出话语上。然后组合注意力α比αˆt更好,并专注于最终有助于总结生成的适当话语。
4 Related Work
4.1 Dialogue Summarization
对话摘要是一项具有挑战性的任务,已经在各种场景中进行了广泛的探索。以往的工作通常侧重于通过串接关键点来总结对话,以保持完整的对话流程:Mehdad等人(2013)和Shang等人(2018)首先通过community detection对共享相似语义的话语进行分组,然后为每个话语组生成一个摘要句子。Liu等人(2019a)提出了一种分层模型,以生成关键点序列并同时生成客户服务对话的摘要。Duan等人(2019b)训练对相应争议焦点的话语分配,以得到法庭辩论对话摘要。几项工作(Zech ner 2001;Xie等人2008;Oya等人2014;Liu等人2019b;Li等人2019a)在进行摘要时,通过主题分割将对话分成多个片段。与上述工作不同,Pan等人(2018)首先尝试为整个对话生成一个高度抽象的摘要,该摘要使用基于Transformer的方法生成了一个简洁的事件/对象描述。相比之下,在这项工作中,对话摘要通常强调特定角色的内容,这要求系统在执行显著性估计时进一步关注角色信息。
4.2 Text Summarization with Topic Modeling
主题模型已被广泛研究用于文档建模和信息检索。概率主题模型,如pLSA(Hofmann 1999)和LDA(Blei、Ng和Jor-dan 2003)为不覆盖文档的底层语义提供了理论上可靠的基础。最近,引入了神经主题模型(Miao等人,2017)来推断文档的潜在表示,该模型利用深度神经网络作为学习主题分布的近似器(approximators)。一些工作已经使用了这些主题模型来促进摘要任务。Wang等人(2018年)和Narayan等人(2018)使用LDA来推断话题嵌入,并设计对合并主题信息的联合注意力机制。Fu等人(2020)将主题推理模块与摘要模型合并,而不是简单地使用预先训练的主题模型。关于对话摘要的一些早期著作(Higashinaka等人,2010;Wang and Cardie 2012;Sood等人2013)直接对对话进行主题建模以提取突出的单词或短语。所有上述方法都利用标准主题建模框架作为辅助工具来进行主题挖掘以进行摘要。相比之下,我们使用摘要信息作为指导,促使主题模型学习单词显著性对应。因此,潜在的语义很难被无信息的内容所掩盖,从而使显著的信息更容易被感知。
5 Conclusion and Future Work
在本文中,我们提出了一种主题增强的两阶段总和摘要模型,它具有用于客户服务对话的多角色主题建模机制,可以生成突出特定角色信息的高度抽象的摘要。此外,我们为主题建模引入了一种新的训练机制,该机制直接学习单词显著性对应关系,以减轻非信息内容的影响。在真实客户服务数据集上的实验验证了我们方法的有效性。未来的方向可能是探索模板指导的抽象方法,以使摘要更标准化更易于汇报。
6 Acknowledgments
作者希望感谢匿名审稿人的有益评论。这项工作得到了国家重点研发计划(No.2018YFC0831105)、国家自然科学基金(No.61751201、62076069、61976056)、上海市科技重大项目(No.2018SHZDZX01)和上海市科学技术委员会资助(No.18DZ201000、17JC1420200)的部分资助。这项工作得到了阿里巴巴集团通过阿里巴巴创新研究计划(AIR)的支持。
7 References
略