一、前言
这篇文章找来了有关药品销售数据进行案例分析练习,利用适当的统计方法对相关数据进行月均消费次数、月均消费金额、客单价和消费趋势等几个业务指标进行分析。
分析过程为:数据获取、数据清洗、建模分析、可视化
二、数据获取
(文末有数据获取方式)
这是我们的原始数据,xlsx格式
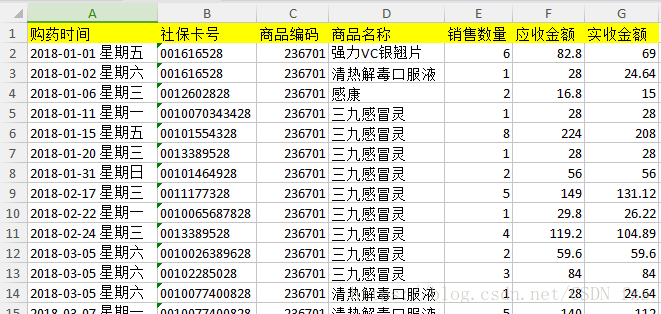
导入相关的包并读取数据,读取的时候用object读取,防止有些数据读取不了。
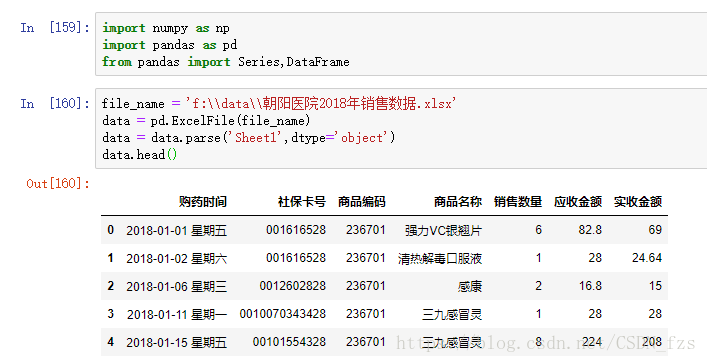
接着可以查看数据的相关信息
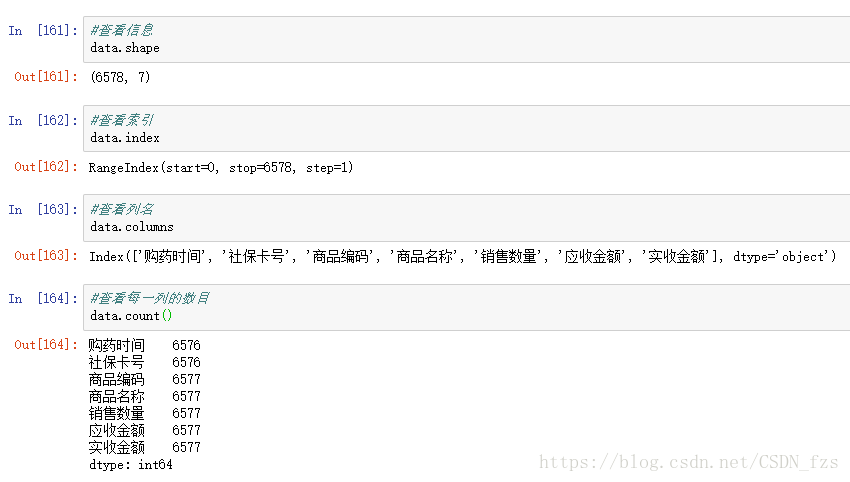
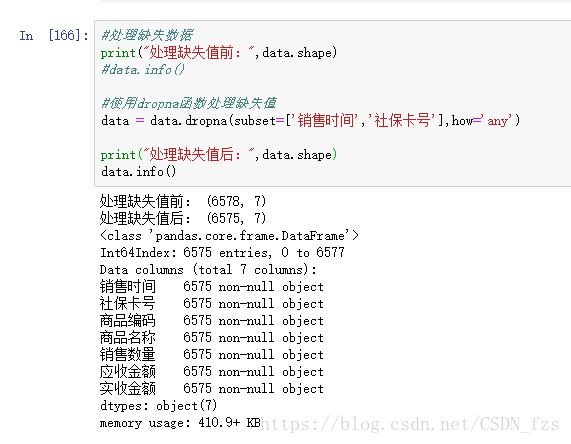
从上图中我们可以看到该数据集一共有6578行数据,其中第一行是标题,有7列。“购药时间”和“社保卡号”有6576条数据,而其余的有6577条,说明数据中存在这缺失值。“购药时间”和“社保卡号”各缺失一行数据,在这里我们要对数据进行缺失值等进一步处理。
三、数据清洗
数据清洗的过程包括:选择子集、列名重命名、缺失值处理、数据类型转换、异常值处理以及数据排序。
3.1选择子集。
在数据分析的过程中,有可能数据量会非常大,但并不是每一列都有分析的价值,这时候就要从这些数据中选择有用的子集进行分析,这样才能提高分析的价值和效率。但是本例子中暂不需要选择子集,可以忽略这一步。
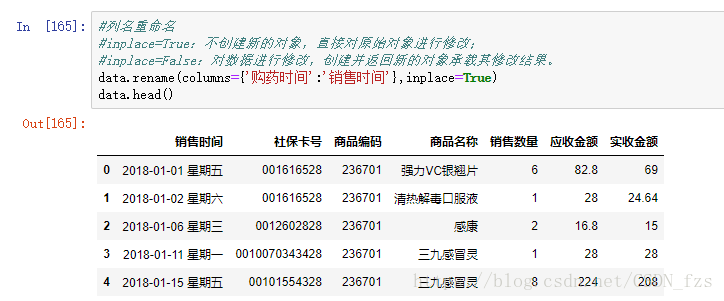
3.2列名重命名。
在数据分析的过程中,有些列名和数据容易混淆或者让人产生歧义。比如说本数据集的第一列是“购药时间”,然而我们做数据分析的时候应该是站在商家的角度来看,因此将列名改为“销售时间”就会更清晰明了。在这里可以采用rename函数来实现:
3.3缺失值处理。
获取的数据中很可能存在这缺失值,这会对分析的结果造成影响。我们经过查看数据集基本的信息,发现“购药时间”和“社保卡号”各缺失一行数据。在这里可以使用dropna函数进行删除缺失值:
3.4数据类型的转换。
在导入数据的时候为了防止导入不进来,python会强制转换为object类型,然是这样的数据类型在分析的过程中不利于运算和分析。比如“销售数量”、“实收金额”等应该是浮点型。
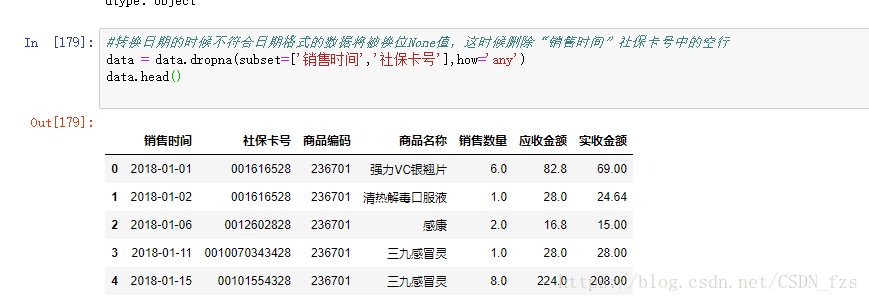
在“销售时间”这一列数据中存在星期这样的数据,但在数据分析过程中不需要用到,因此要把销售时间列中日期和星期使用split函数进行分割,分割后的时间,返回的是Series数据类型:

接着把切割后的日期转为时间格式,方便后面的数据统计,并且可以用astype()函数对其它数据进行类型转换:

3.5异常值处理。
到这一步,我们可以利用describe()函数查看数据是否还存在异常:
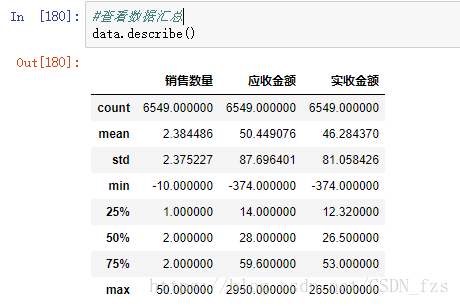
我们可以看出最小值min出现了负数,这些都是异常值,这里要去掉异常值,排除异常值造成影响。
我们可以创建一个掩模,来筛选出正常的数据,也就是大于0的值,排除“销售数量”这一列中的负值:
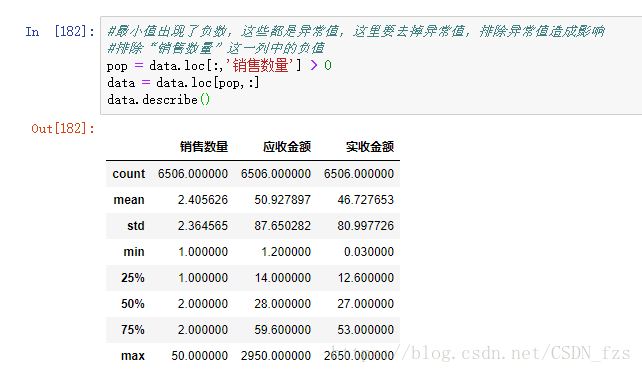
接下来可以利用drop_duplicates()函数删除重复的数据:

3.6数据排序。
此时的数据还是比较混乱,没有按照一定的顺序进行排序。按照习惯,我们可以根据时间的顺序对数据进行排序:
这一步也要重新设置索引index了
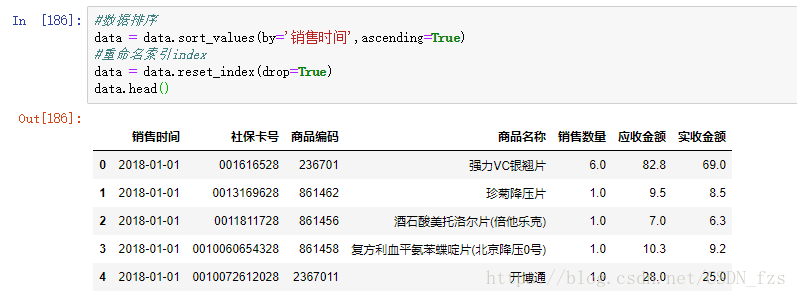
到这里,我们的数据清洗工作顺利完成。
四、建模分析
对数据进行处理之后,需要利用数据构建模型,计算相关的业务指标并用可视化的方式呈现结果。
4.1月均消费次数
月均消费次数 = 总消费次数 / 月份数

4.2月均消费金额
月均消费金额 = 总消费金额 / 月份数

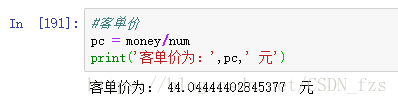
4.3客单价
客单价 = 总消费金额 / 总消费次数
五、可视化
5.1消费趋势
消费趋势图呈现出每天销售药品的情况。
首先导入相关的包:

接着画图:
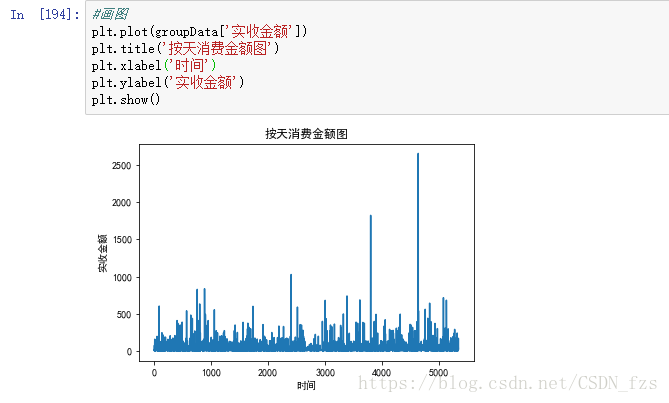
从结果可以看出,每天消费总额差异较大,除了个别天出现比较大笔的消费,大部分人消费情况维持在500元以内。
5.2每月消费金额

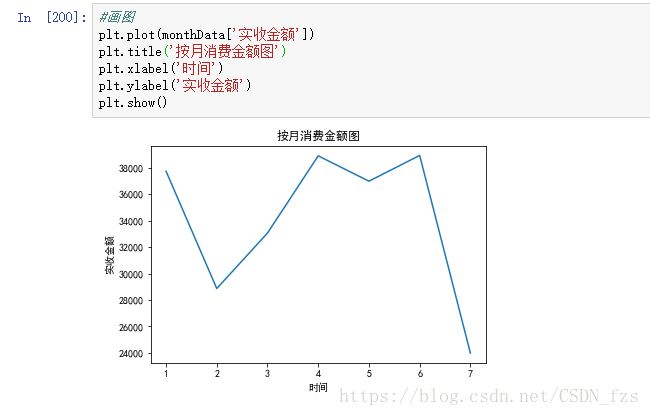
结果显示,7月消费金额最少,这是因为7月份的数据不完整,所以不具参考价值。
1月、4月、5月和6月的月消费金额差异不大,2月和3月的消费金额迅速降低,这可能是2月和3月处于春节期间,大部分人都回家过年的原因。
5.3药品销售情况
对“商品名称”和“销售数量”这两列数据进行聚合为Series形式,方便后面统计,并按降序排序:
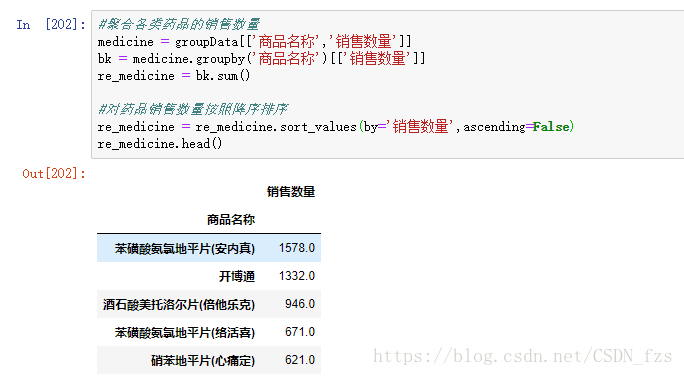
截取销售数量最多的前十种药品,并用条形图展示结果:

最后画图展示:
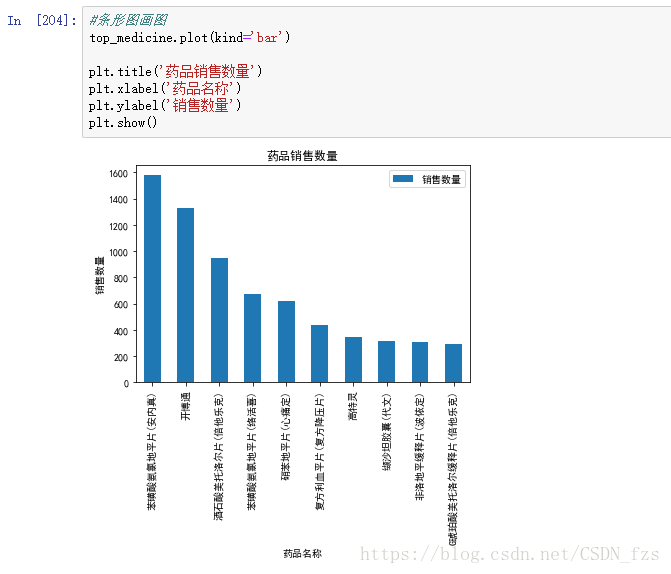
得到销售数量最多的前十种药品信息,这些信息将会有助于加强医院对药房的管理。
获取数据集:扫码关注微信公众号“价值智生”,回复“药品销售数据”即可获得。

数据来源于网络,仅供学习使用,请勿用于其它用途。