1、jieba分词及词频统计
import jieba
import pandas as pd# 加载自定义分词词典(txt内容格式:自定义关键词+空格+空格 ----->换行继续)
jieba.load_userdict("./dict.txt")content = open('./测试.txt',encoding='utf-8').read()
#分词
words = jieba.cut(content)
word_list = list(word for word in words)#使用pandas统计并降序排列
df = pd.DataFrame(word_list,columns=['word'])
# result = df.groupby(['word']).size()
result = df.groupby(['word']).size().sort_values(ascending=False)# print(result.sort_values(ascending=False))result.to_excel('./分词词频统计结果.xlsx')2、TextRank和TF-IDF关键词提取(包括权重,词云图)
import jieba.analyse
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np#准备语料
corpus = "《知否知否应是绿肥红瘦》是由东阳正午阳光影视有限公司出品,侯鸿亮担任制片人,张开宙执导,曾璐、吴桐编剧,赵丽颖、冯绍峰领衔主演,朱一龙、施诗、张佳宁、曹翠芬、刘钧、刘琳、高露、王仁君、李依晓、王鹤润、张晓谦、李洪涛主演,王一楠、陈瑾特别出演的古代社会家庭题材电视剧"#TextRank关键词提取
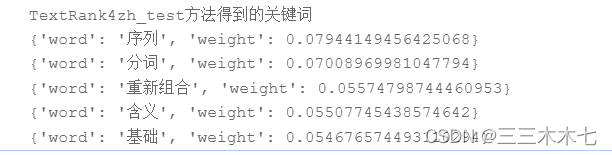
keywords_textrank = jieba.analyse.textrank(corpus,topK=10,withWeight=True)
print(keywords_textrank) #['有限公司', '出品', '社会', '家庭', '制片人', '担任', '影视', '题材', '电视剧', '知否', '东阳', '出演', '执导']#TF-IDF关键词提取
keywords_tfidf = jieba.analyse.extract_tags(corpus,topK=10,withWeight=True)
print(keywords_tfidf) # ['知否', '领衔主演', '刘钧', '刘琳', '侯鸿亮', '张晓谦', '王一楠', '张佳宁', '李依晓', '冯绍峰', '王鹤润', '施诗', '陈瑾', '赵丽颖', '吴桐', '朱一龙', '曹翠芬', '王仁君', '曾璐', '高露']#提取关键词及权重
freq = {i[0]: i[1] for i in keywords_tfidf}
# 生成对象(自定义背景图片)
# mask = np.array(Image.open("color_mask.png"))wc = WordCloud( font_path='SIMLI.ttf',width=800, height=600, mode='RGBA', background_color='white').generate_from_frequencies(freq)# 显示词云
plt.imshow(wc,interpolation='bilinear')
plt.axis('off')
plt.show()# 保存到文件
wc.to_file('wordcloud3.png')
3、jieba 借助停用词、自定义字典词频统计(针对excel的某列数据做词频统计)
import jieba
import pandas as pd
import time# 导入数据
df = pd.read_excel('51job.com销售岗位(未去重).xlsx',encoding = 'utf-8')
df = df.dropna() #去除空值
content = df.values.tolist() #将数据内容按行转换成列表
# print(content)
# print(len(content))# 加载自定义分词词典(txt内容格式:自定义关键词+空格+空格 ----->换行继续)
jieba.load_userdict("./jieba_userdict.txt")base_text = [] #取目标字段的文本内容
for i in range(len(content)):base_text.append(content[i][0])words_ = [] #存放目标文本的分词结果
for words_row in base_text:try:words = jieba.cut(words_row)for word in words:if len(word) >1 and word !='/r/n':words_.append(word)except:print('抛出异常:\n',words_row)continueprint('1.目标文本初步分词结果:\n',words_)#加载停用词
stopwords=[]
for word in open('stopwords.txt','r',encoding='utf-8'):stopwords.append(word.strip())
print('2.停用词列表:\n',stopwords)
#存放已去除停用词的文本数据
res = []
#存放被禁用的词
res_no = []#筛选分词结果使其不包含停用词
for word in words_:if word in stopwords:res_no.append(word)else:res.append(word)
res_no_ = set(res_no)
print('3.存放已去除停用词的文本数据列表:\n',res)
print('4.存放被禁用的词:\n',res_no_)# 将分词结果转换为df对象,使用pandas统计词频并降序排列
df = pd.DataFrame(res, columns=['word'])
print('5.word_df对象:\n',df)
# result = df.groupby(['word']).size()
result = df.groupby(['word']).size().sort_values(ascending=False)
print('6.词频统计结果:\n',result)
# print(result.sort_values(ascending=False))result.to_excel('./分词词频统计结果'+time.strftime('%Y%m%d%H%M%S')+'.xlsx')4、jieba pandas做词频统计并制作词云
import warnings
warnings.filterwarnings("ignore")
import jieba
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
from wordcloud import WordCloud #制作词云的包
import timematplotlib.rcParams['figure.figsize'] = (10.0,5.0) #指定画布的大小尺寸# 导入数据
df = pd.read_excel('51job.com销售岗位(未去重).xlsx',encoding = 'utf-8')
df = df.dropna() #去除空值
content = df.values.tolist() #将数据内容按行转换成列表
# print(content)
# print(len(content))# 加载自定义分词词典(txt内容格式:自定义关键词+空格+空格 ----->换行继续)
jieba.load_userdict("./jieba_userdict.txt")base_text = [] #取目标字段的文本内容
for i in range(len(content)):base_text.append(content[i][0])words_ = [] #存放目标文本的分词结果
for words_row in base_text:try:words = jieba.cut(words_row)for word in words:if len(word) >1 and word !='/r/n':words_.append(word)except:print('抛出异常:\n',words_row)continueprint('1.目标文本初步分词结果:\n',words_)#加载停用词
stopwords=[]
for word in open('stopwords.txt','r',encoding='utf-8'):stopwords.append(word.strip())
print('2.停用词列表:\n',stopwords)
#存放已去除停用词的文本数据
res = []
#存放被禁用的词
res_no = []#筛选分词结果使其不包含停用词
for word in words_:if word in stopwords:res_no.append(word)else:res.append(word)
res_no_ = set(res_no)
# print('3.存放已去除停用词的文本数据列表:\n',res)
# print('4.存放被禁用的词:\n',res_no_)# 将分词结果转换为df对象,使用pandas统计词频并降序排列
df = pd.DataFrame(res, columns=['word'])
# print('5.word_df对象:\n',df)
# result = df.groupby(['word']).size()
result = df.groupby(['word']).size().sort_values(ascending=False)
print('6.词频统计结果:\n',result)
# print(result.sort_values(ascending=False))
file_name = './分词词频统计结果'+time.strftime('%Y%m%d%H%M%S')+'.xlsx'
result.to_excel(file_name)# 导入词频数据
cs_data =pd.read_excel(file_name,encoding = 'utf-8')
word_counts = cs_data.values.tolist() #将数据内容按行转换成列表
# print(word_counts)
word_frequence = {x[0]:x[1] for x in word_counts[:20]} #取前20行数据做词云
# 生成对象(自定义背景图片)
# mask = np.array(Image.open("color_mask.png"))
#初始化词云对象
wordCloudObj = WordCloud( font_path='SIMLI.ttf',width=800, height=600, mode='RGBA', background_color='white').generate_from_frequencies(word_frequence)plt.imshow(wordCloudObj)
plt.axis('off')
plt.show()png_file_name = 'wordcloud'+time.strftime('%m%d%H%M%S')+'.png'
wordCloudObj.to_file(png_file_name)

5.简易词云图生成(不适合中文直接生成词云,需要分词处理)
import wordcloud# 创建词云对象,赋值给w,现在w就表示了一个词云对象
w = wordcloud.WordCloud( font_path='SIMLI.ttf',width=800, height=600, mode='RGBA', background_color='white')# 生成背景对象(自定义背景图片)
# mask = np.array(Image.open("color_mask.png"))# 调用词云对象的generate方法,将文本传入
w.generate('今天天气不错,and that government of the people, by the people, for the people, shall not perish from the earth.')# 将生成的词云保存为output1.png图片文件,保存出到当前文件夹中
w.to_file('output1.png')