Python 能够自动进行内存分配和释放,但了解 python 垃圾回收 (garbage collection, GC) 的工作原理可以帮助你写出更好更快的 Python 程序。Python 使用两种算法进行垃圾回收,分别是引用计数 (Reference Counting) 和分代回收 (Generational garbage collection)。
引用计数
引用计数,简而言之就是如果没有变量引用某一对象,那么该对象将会被回收。Python 中的每个变量都是对对象的引用,而不是对象本身。例如,赋值语句只是给右侧对象或右侧变量所对应的对象建立一个引用;一个对象都可以有许多引用。
核心概念:变量是指向一个对象的指针;有n个变量指向某一个对象,那该对象的引用计数则为n,又称该对象有n个引用
import sys
a = [1, 2, 3]
b = a # 赋值操作本身不会对数据进行复制,仅仅是建立引用关系print(id(a), id(b)) # 4483101696 4483101696,变量a b的id相同,说明a b指向同一对象
print(sys.getrefcount(a)) # 3, 其中调用getrefcount函数会使引用+1
为了跟踪每个对象的引用次数,每个对象都有一个名为引用计数的额外属性,当创建或删除指向对象的指针时,该属性的值会相应的增加或减少。以下三种情况会使对象的引用次数增加:
- 赋值运算
- 参数传递
- 将对象附加到容器对象中
如果某对象引用计数属性的值为零,CPython 会自动调用该对象特定的内存释放函数。如果该对象还包含对其他对象的引用,那么所包含的其他对象的引用计数也会自动减少。因此,可以依次释放其他对象。
值得注意的是,在函数、类和代码块(如if-else代码块)之外声明的变量称为全局变量(global variables)。通常,这些变量会一直存在直到 Python 进程结束。因此,全局变量引用的对象的引用计数永远不会下降到零。在python进程中,所有全局变量都存储在一个字典中,可以通过调用globals()函数来获取全局变量。那反过来呢?在代码块内(例如,在函数或类中)定义的变量则具有一个局部作用域,可以通过调用locals()函数来获取局部变量。当 Python 解释器执行完一个代码块时,它会破坏在块内创建的局部变量及其引用。
我们举个例子:
import sysfoo = []
print(sys.getrefcount(foo)) # 2 references, 1 from the foo var and 1 from getrefcountdef bar(a):print(sys.getrefcount(a))bar(foo) # 4 references, from the foo var, function argument, getrefcount and Python's function stack
print(sys.getrefcount(foo)) # 2 references, the function scope is destroyed
当你想删除全局或局部变量时,可以使用删除变量及其引用(而不是对象本身)的 del语句。这在 jupyter notebook中工作时通常很有用,因为在jupyter notebook中所有单元格变量都是全局变量。CPython 使用引用计数的主要原因是历史原因,现在有很多关于这种技术的弱点的争论。比如,有人认为现代的垃圾回收算法可以更高效,无需使用引用计数。引用计数算法存在很多问题,例如循环引用、线程锁定以及额外内存和性能开销。必须指出的是,引用计数是 Python 无法摆脱全局解释锁 (GIL) 的原因之一。
分代回收
上面讲到了引用计数的缺点包括循环引用、线程锁定以及额外内存和性能开销。线程锁定,所以在python中使用多线程;额外内存和性能开销,我们也认了;但是循环引用的问题不解决的话,就会造成内存泄露问题。因此,python引入了分代回收的算法专门来解决循环引用的问题。
引用计数算法非常有效和直接,但它无法检测循环引用,所以python在引用计数的基础上,还需要分代回收。引用计数是 Python必需的功能,不能禁用;而分代回收是可选的,可以手动设置。
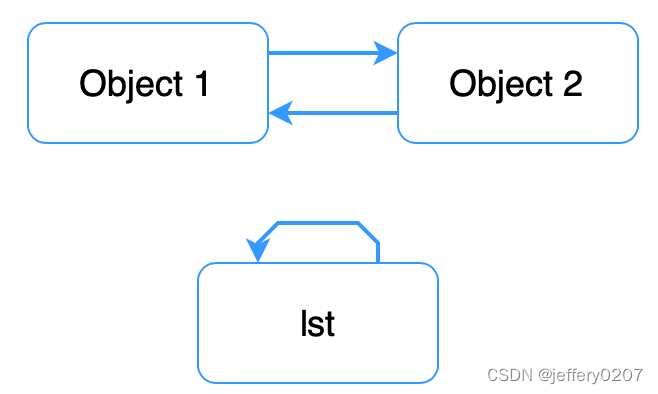
如上图示例所示,lst对象指向自身,而且Object 1 和 Object 2 相互引用。在这两种情况下,这些对象的引用数永远至少为1。我们可以用代码来演示一下:
import gc
import sys
import ctypes# 通过内存地址去访问没有引用的对象(unreachable objects)
class PyObject(ctypes.Structure):_fields_ = [("refcnt", ctypes.c_long)]gc.disable() # 禁用分代回收算法
lst = []
lst.append(lst)
lst_address = id(lst)
del lstobject_1, object_2 = {}, {}object_1['obj2'] = object_2
object_2['obj1'] = object_1
obj_address = id(object_1)
del object_1, object_2# 手动对象回收
# gc.collect()# 获取对象引用数量
print(PyObject.from_address(obj_address).refcnt)
print(PyObject.from_address(lst_address).refcnt)# 或者通过以下方式获取引用数量
# tmp = PyObject.from_address(obj_address)
# print(sys.getrefcount(tmp))# # output
1
1
2
在上面的示例中,del语句删除了对我们对象的引用(引用计数减 1)。 Python 执行 del语句后,我们的对象不再可以从 Python 代码访问。但是,这些对象仍然存在于内存中。发生这种情况是因为它们仍在相互引用,并且每个对象的引用计数为 1。因为我们前面通过gc.disable()禁用了分代回收,因为循环引用对象无法释放;这时,我们可以通过调用gc.collect()手动触发对象回收。
我们知道,在python中对象分为可变对象和不可变对象。不可变对象包括int, float, complex, strings, bytes, tuple, range 和 frozenset;可变对象包括list, dict, bytearray和 set。循环引用仅存在于container对象(比如,list, dict, classes, tuples),python垃圾回收算法主要追踪可变对象及不可变对象tuple。如果tuple, dict包含的元素都是不可变对象,那么回收算法可以不对该对象进行追踪。
垃圾回收的触发
不同于引用计数,循环引用的垃圾回收不是实时作用的,而是定期运行。垃圾回收器将container对象分成三代(0, 1, 2),每个新对象都从第一代开始。如果一个对象在一个垃圾回收轮次中幸存下来,它将移至较旧(更高)的一代。较低代的回收频率高于较高代,因为大多数新对象往往会被先销毁。这样分代回收的策略能提高性能并减少垃圾回收带来的暂停时间。
为了决定何时进行一轮垃圾回收,每一代都有一个单独的计数器和阈值。计数器存储自上次收集以来的对象分配数减去释放数的差值。每次分配新的容器对象时,CPython 都会检查第0代的计数器是否超过阈值(通过gc.get_count()获得三代对象计数器存储的数值)。如果超过阈值,Python 将触发垃圾回收。我们可以通过gc.get_threshold()和gc.set_threshold()查看、设置阈值:
import gc
gc.get_threshold() # (700, 10, 10) 分别对应三代计数器的阈值
gc.set_threshold(threshold0=800, threshold0=10, threshold0=10) # 当threshold0设置为0时,禁用循环GC
在写程序时,可以通过将调试标志设置为gc.DEBUG_SAVEALL,从而将所有unreachable对象添加到gc.garbage 中,帮助提升程序质量:
import gcgc.set_debug(gc.DEBUG_SAVEALL)print(gc.get_count())
lst = []
lst.append(lst)
list_id = id(lst)
del lst
gc.collect()
for item in gc.garbage:print(item)
参考
python documentation: GC
Garbage collection in Python: things you need to know
stacloverflow reference count




![Python之美[从菜鸟到高手]--Python垃圾回收机制及gc模块详解](https://img-blog.csdn.net/20130908205712390)