ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
1.工具&框架

工具库:PaddleMM - 多模态学习工具包
PaddleMM以百度 PaddlePaddle 平台为主,兼容 PyTorch 提供 torch 版本,旨在于提供模态联合学习和跨模态学习算法模型库,为处理图片文本等多模态数据提供高效的解决方案,助力多模态学习应用落地
‘PaddleMM - Multi-Modal learning toolkit based on PaddlePaddle and PyTorch, supporting multiple applications such as multi-modal classification, cross-modal retrieval and image caption.’ by njustkmg
GitHub: https://github.com/njustkmg/PaddleMM



工具库:pytorch-lifestream - 基于自监督在离散事件序列上实现嵌入的PyTorch库
‘pytorch-lifestream - A library built upon PyTorch for building embeddings on discrete event sequences using self-supervision’ by Dmitri Babaev
GitHub: https://github.com/dllllb/pytorch-lifestream

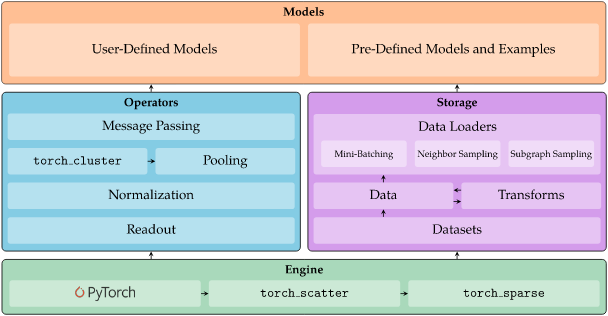
工具库:PyG - PyTorch图神经网络(GNN)库
‘PyG (PyTorch Geometric) - a library built upon PyTorch to easily write and train Graph Neural Networks (GNNs) for a wide range of applications related to structured data’
GitHub: github.com/pyg-team/pytorch_geometric



工具:Macaron - 可视化Web开发编辑器
‘Macaron - Visual component editor for Web development’ by macaron-elements
GitHub: https://github.com/macaron-elements/macaron


工具:Please - 漂亮的极简终端新标签页工具
‘Please - Minimalistic New Tab Page with a greeting, date and time, inspirational quotes and your personal tasks and to-do list’ by NayamAmarshe
GitHub: https://github.com/NayamAmarshe/please

2.项目&代码

NTIRE 2022压缩视频超分辨率和质量增强挑战优胜方案代码
‘How We Win the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video’ by Qunliang Xing
GitHub: https://github.com/ryanxingql/winner-ntire22-vqe

3.博文&分享

免费书籍资源:深度学习数学工程
《The Mathematical Engineering of Deep Learning》by Benoit Liquet
Link: https://deeplearningmath.org/

4.数据&资源

资源列表:Awesome Software Architecture - 软件架构相关资源大列表
‘Awesome Software Architecture - A curated list of awesome articles, videos, and other resources to learn and practice software architecture, patterns, and principles.’ by Mehdi Hadeli
GitHub: https://github.com/mehdihadeli/awesome-software-architecture

资源列表:域自适应目标检测相关文献列表
‘awesome-domain-adaptation-object-detection - A collection of papers about domain adaptation object detection’ by wangs311
GitHub: https://github.com/wangs311/awesome-domain-adaptation-object-detection

资源列表:换脸检测相关文献工具资源大列表
‘Awesome Deepfakes Detection - A list of tools, papers and code related to Deepfake Detection.’ by Daichi Zhang
GitHub: https://github.com/Daisy-Zhang/Awesome-Deepfakes-Detection
5.研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的6月论文合辑。
论文:LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks
论文标题:LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks
论文时间:14 Jun 2022
所属领域:自然语言处理
对应任务:Classification,Pretrained Language Models,分类,预训练语言模型
论文地址:https://arxiv.org/abs/2206.06565
代码实现:https://github.com/uw-madison-lee-lab/languageinterfacedfinetuning
论文作者:Tuan Dinh, Yuchen Zeng, Ruisu Zhang, Ziqian Lin, Michael Gira, Shashank Rajput, Jy-yong Sohn, Dimitris Papailiopoulos, Kangwook Lee
论文简介:LIFT does not make any changes to the model architecture or loss function, and it solely relies on the natural language interface, enabling “no-code machine learning with LMs.” / LIFT 不会对模型架构或损失函数进行任何更改,它仅依赖于自然语言界面,实现了“使用语言模型进行无代码机器学习”。
论文摘要:Fine-tuning pretrained language models (LMs) without making any architectural changes has become a norm for learning various language downstream tasks. However, for non-language downstream tasks, a common practice is to employ task-specific designs for input, output layers, and loss functions. For instance, it is possible to fine-tune an LM into an MNIST classifier by replacing the word embedding layer with an image patch embedding layer, the word token output layer with a 10-way output layer, and the word prediction loss with a 10-way classification loss, respectively. A natural question arises: can LM fine-tuning solve non-language downstream tasks without changing the model architecture or loss function? To answer this, we propose Language-Interfaced Fine-Tuning (LIFT) and study its efficacy and limitations by conducting an extensive empirical study on a suite of non-language classification and regression tasks. LIFT does not make any changes to the model architecture or loss function, and it solely relies on the natural language interface, enabling “no-code machine learning with LMs.” We find that LIFT performs relatively well across a wide range of low-dimensional classification and regression tasks, matching the performances of the best baselines in many cases, especially for the classification tasks. We report the experimental results on the fundamental properties of LIFT, including its inductive bias, sample efficiency, ability to extrapolate, robustness to outliers and label noise, and generalization. We also analyze a few properties/techniques specific to LIFT, e.g., context-aware learning via appropriate prompting, quantification of predictive uncertainty, and two-stage fine-tuning. Our code is available at https://github.com/UW-Madison-Lee-Lab/LanguageInterfacedFineTuning
在不进行任何架构更改的情况下微调预训练语言模型 (LM) 已成为学习各种语言下游任务的规范。然而,对于非语言的下游任务,一种常见的做法是对输入、输出层和损失函数采用特定于任务的设计。例如,可以通过将单词嵌入层替换为图像块嵌入层、将单词标记输出层替换为 10 路输出层以及将单词预测损失替换为 10 路分类损失,来将 LM 微调为 MNIST 分类器。 一个自然的问题出现了:LM 微调能否在不改变模型架构或损失函数的情况下解决非语言的下游任务?为了回答这个问题,我们提出了语言接口微调 (LIFT),并通过对一套非语言分类和回归任务进行广泛的实证研究来研究其功效和局限性。 LIFT 不会对模型架构或损失函数进行任何更改,它仅依赖于自然语言界面,实现了“使用 LM 进行无代码机器学习”。我们发现 LIFT 在广泛的低维分类和回归任务中表现相对较好,在许多情况下与最佳基线的性能相匹配,特别是对于分类任务。我们的报告显示了 LIFT 基本特性的实验结果,包括它的归纳偏差、样本效率、外推能力、对异常值和标签噪声的鲁棒性以及泛化性。我们还分析了一些特定于 LIFT 的属性/技术,例如,通过适当的提示进行上下文感知学习、预测不确定性的量化和两阶段微调。我们的代码可在 https://github.com/UW-Madison-Lee-Lab/LanguageInterfacedFineTuning 获得


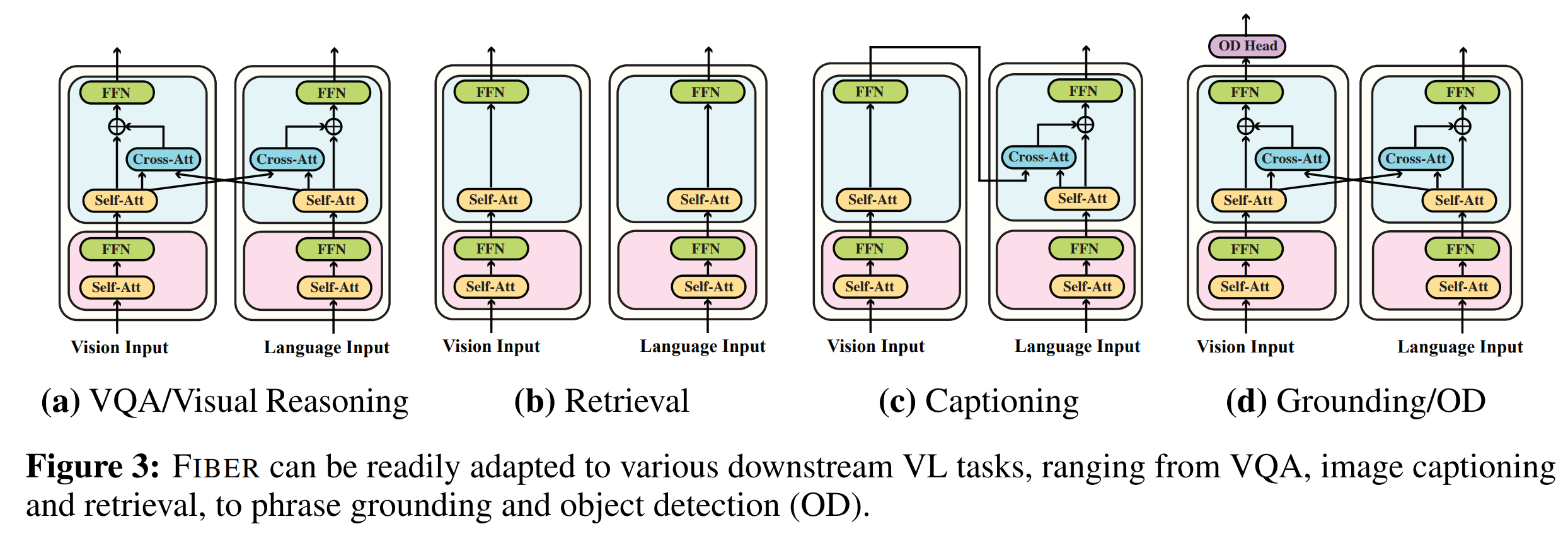
论文:Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone
论文标题:Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone
论文时间:15 Jun 2022
所属领域:自然语言处理
对应任务:Image Captioning,object-detection,Object Detection,Phrase Grounding,Question Answering,Referring Expression,Referring Expression Comprehension,Visual Question Answering,VQA,看图说话,目标检测,物体检测,问答,指称表达,指称表达理解,视觉问答
论文地址:https://arxiv.org/abs/2206.07643
代码实现:https://github.com/microsoft/fiber
论文作者:Zi-Yi Dou, Aishwarya Kamath, Zhe Gan, Pengchuan Zhang, JianFeng Wang, Linjie Li, Zicheng Liu, Ce Liu, Yann Lecun, Nanyun Peng, Jianfeng Gao, Lijuan Wang
论文简介:Vision-language (VL) pre-training has recently received considerable attention. / 视觉语言(VL)预训练模型最近受到了相当大的关注。
论文摘要:Vision-language (VL) pre-training has recently received considerable attention. However, most existing end-to-end pre-training approaches either only aim to tackle VL tasks such as image-text retrieval, visual question answering (VQA) and image captioning that test high-level understanding of images, or only target region-level understanding for tasks such as phrase grounding and object detection. We present FIBER (Fusion-In-the-Backbone-based transformER), a new VL model architecture that can seamlessly handle both these types of tasks. Instead of having dedicated transformer layers for fusion after the uni-modal backbones, FIBER pushes multimodal fusion deep into the model by inserting cross-attention into the image and text backbones, bringing gains in terms of memory and performance. In addition, unlike previous work that is either only pre-trained on image-text data or on fine-grained data with box-level annotations, we present a two-stage pre-training strategy that uses both these kinds of data efficiently: (i) coarse-grained pre-training based on image-text data; followed by (ii) fine-grained pre-training based on image-text-box data. We conduct comprehensive experiments on a wide range of VL tasks, ranging from VQA, image captioning, and retrieval, to phrase grounding, referring expression comprehension, and object detection. Using deep multimodal fusion coupled with the two-stage pre-training, FIBER provides consistent performance improvements over strong baselines across all tasks, often outperforming methods using magnitudes more data. Code is available at https://github.com/microsoft/FIBER
视觉语言(VL)预训练模型最近受到了相当多的关注。然而,大多数现有的端到端预训练方法要么仅针对 VL 任务,例如图像文本检索、视觉问答 (VQA) 和测试对图像的高级理解的“看图说话”,要么仅针对区域对诸如短语接地和对象检测等任务的理解水平。我们提出了 FIBER(基于 Fusion-In-the-Backbone 的变换器),这是一种新的 VL 模型架构,可以无缝处理这两种类型的任务。 FIBER 通过在图像和文本主干中插入交叉注意力,将多模态融合深入模型中,而不是在单模态主干之后使用专用的变压器层进行融合,从而在内存和性能方面带来收益。此外,与之前的工作要么仅对图像文本数据或带有框级注释的细粒度数据进行预训练,我们提出了一种两阶段预训练策略,可以有效地使用这两种数据:( i) 基于图文数据的粗粒度预训练;其次是(ii)基于图像文本框数据的细粒度预训练。我们对广泛的 VL 任务进行了全面的实验,从 VQA、看图说话和图像检索,到短语基础、指称表达理解和目标检测。使用深度多模式融合与两阶段预训练相结合,FIBER 在所有任务的强基线上提供了一致的性能改进,通常优于使用更多数据的方法。代码位于 https://github.com/microsoft/FIBER

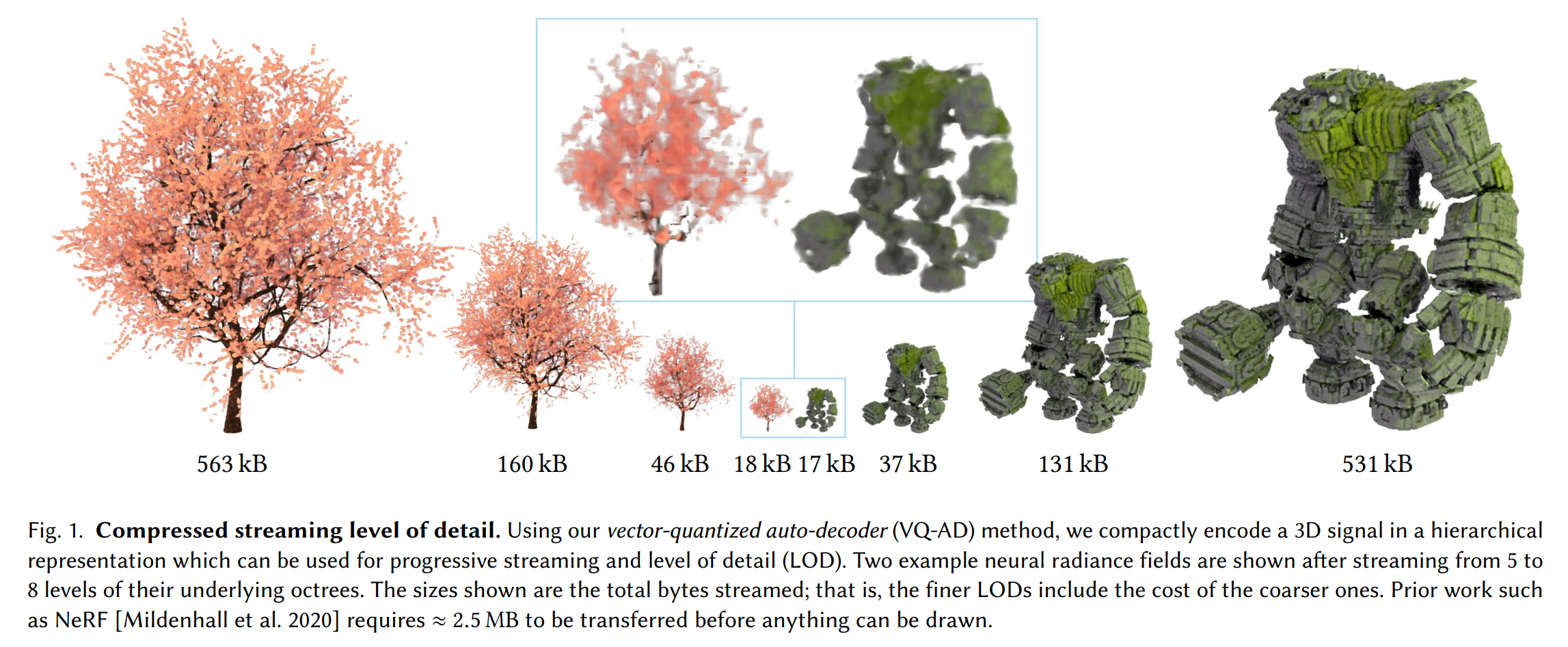
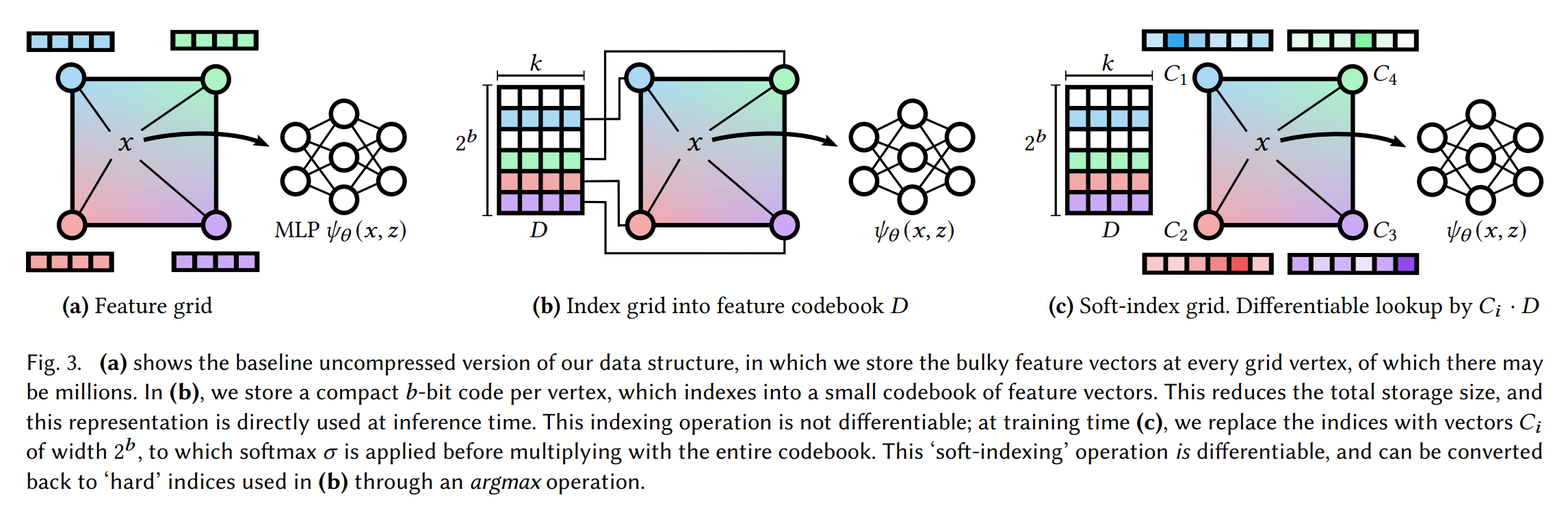
论文:Variable Bitrate Neural Fields
论文标题:Variable Bitrate Neural Fields
论文时间:15 Jun 2022
论文地址:https://arxiv.org/abs/2206.07707
代码实现:https://github.com/nv-tlabs/vqad
论文作者:Towaki Takikawa, Alex Evans, Jonathan Tremblay, Thomas Müller, Morgan McGuire, Alec Jacobson, Sanja Fidler
论文简介:Neural approximations of scalar and vector fields, such as signed distance functions and radiance fields, have emerged as accurate, high-quality representations. / 标量和矢量场的神经近似,例如有符号距离函数和辐射场,已经成为准确、高质量的表示。
论文摘要:Neural approximations of scalar and vector fields, such as signed distance functions and radiance fields, have emerged as accurate, high-quality representations. State-of-the-art results are obtained by conditioning a neural approximation with a lookup from trainable feature grids that take on part of the learning task and allow for smaller, more efficient neural networks. Unfortunately, these feature grids usually come at the cost of significantly increased memory consumption compared to stand-alone neural network models. We present a dictionary method for compressing such feature grids, reducing their memory consumption by up to 100x and permitting a multiresolution representation which can be useful for out-of-core streaming. We formulate the dictionary optimization as a vector-quantized auto-decoder problem which lets us learn end-to-end discrete neural representations in a space where no direct supervision is available and with dynamic topology and structure. Our source code will be available at https://github.com/nv-tlabs/vqad
标量和矢量场的神经近似,例如有符号距离函数和辐射场,已经成为准确、高质量的表示。最先进的结果是通过从可训练的特征网格中查找来调节神经近似来获得的,这些特征网格承担部分学习任务并允许更小、更高效的神经网络。不幸的是,与独立的神经网络模型相比,这些特征网格通常以显着增加内存消耗为代价。我们提出了一种用于压缩此类特征网格的字典方法,将它们的内存消耗减少多达 100 倍,并允许多分辨率表示,这对于核外流式传输很有用。我们将字典优化制定为向量量化的自动解码器问题,它使我们能够在没有直接监督且具有动态拓扑和结构的空间中学习端到端的离散神经表示。我们的源代码将在 https://github.com/nv-tlabs/vqad 上提供

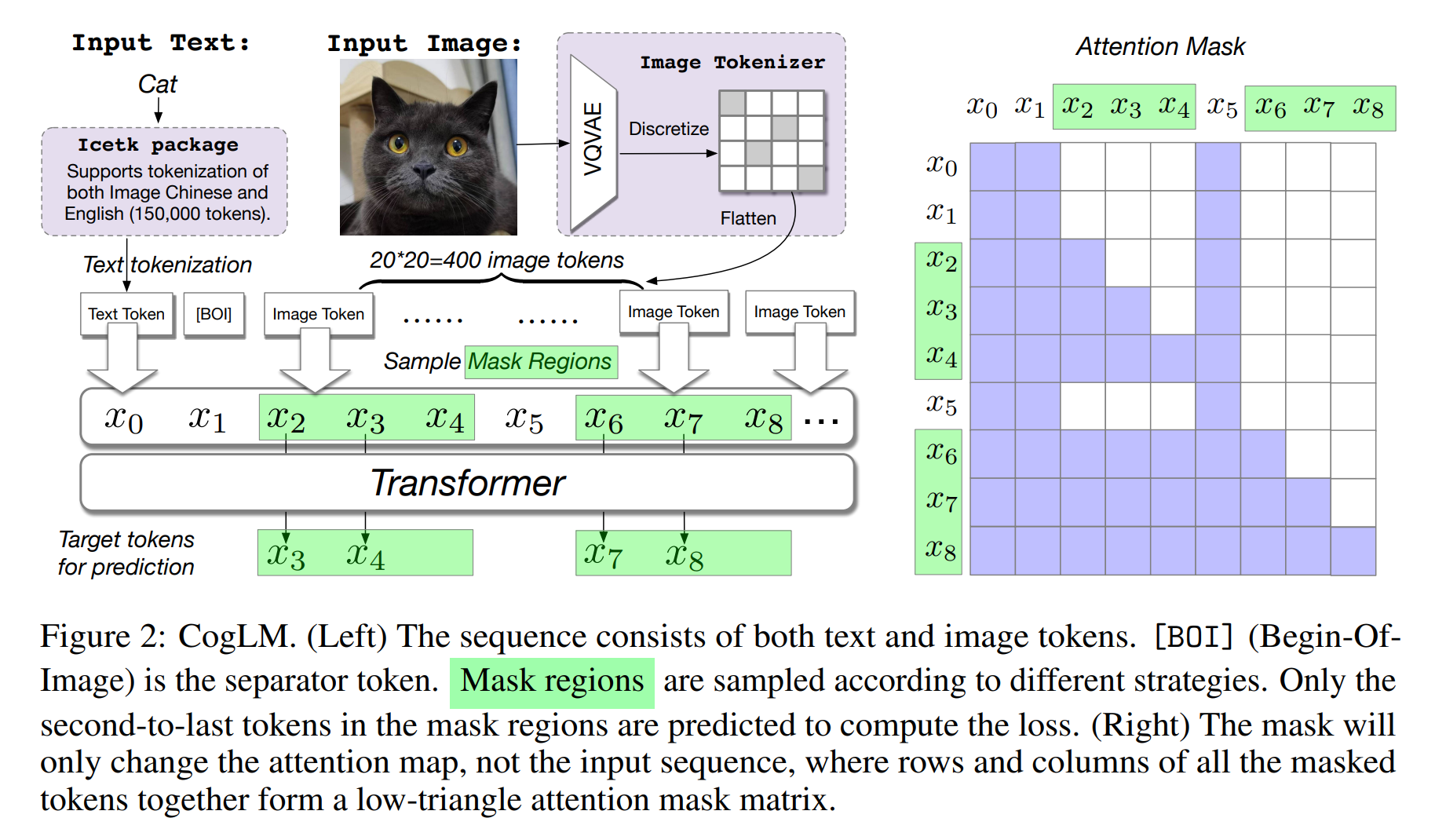
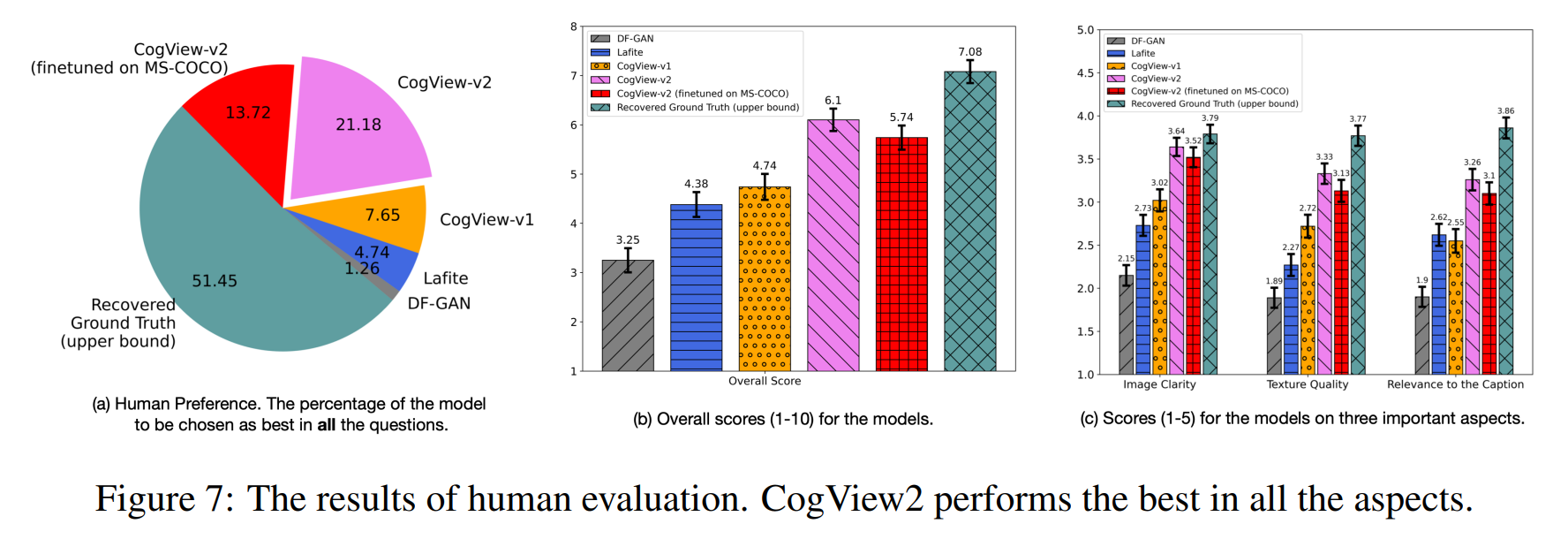
论文:CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers
论文标题:CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers
论文时间:28 Apr 2022
所属领域:计算机视觉,自然语言处理
对应任务:Image Generation,Language Modelling,Super-Resolution,Text to image generation,Text-to-Image Generation,图像生成,语言建模,超分辨率,文本到图像生成
论文地址:https://arxiv.org/abs/2204.14217
代码实现:https://github.com/thudm/cogview2
论文作者:Ming Ding, Wendi Zheng, Wenyi Hong, Jie Tang
论文简介:The development of the transformer-based text-to-image models are impeded by its slow generation and complexity for high-resolution images. / 基于transformer的文本到图像模型的发展受到其对高分辨率图像的生成缓慢度和复杂性的阻碍。
论文摘要:The development of the transformer-based text-to-image models are impeded by its slow generation and complexity for high-resolution images. In this work, we put forward a solution based on hierarchical transformers and local parallel auto-regressive generation. We pretrain a 6B-parameter transformer with a simple and flexible self-supervised task, Cross-modal general language model (CogLM), and finetune it for fast super-resolution. The new text-to-image system, CogView2, shows very competitive generation compared to concurrent state-of-the-art DALL-E-2, and naturally supports interactive text-guided editing on images.
基于Transformer的文本到图像模型的发展受到其对高分辨率图像的生成缓慢度和复杂性的阻碍。在这项工作中,我们提出了一种基于分层Transformer和局部并行自回归生成的解决方案。我们使用简单灵活的自监督任务、跨模态通用语言模型 (CogLM) 预训练 6B 参数转换器,并对其进行微调以实现快速超分辨率。与并发最先进的 DALL-E-2 相比,新的文本到图像系统 CogView2 显示出非常具有竞争力的生成结果,并且自然支持对图像进行交互式文本引导编辑。

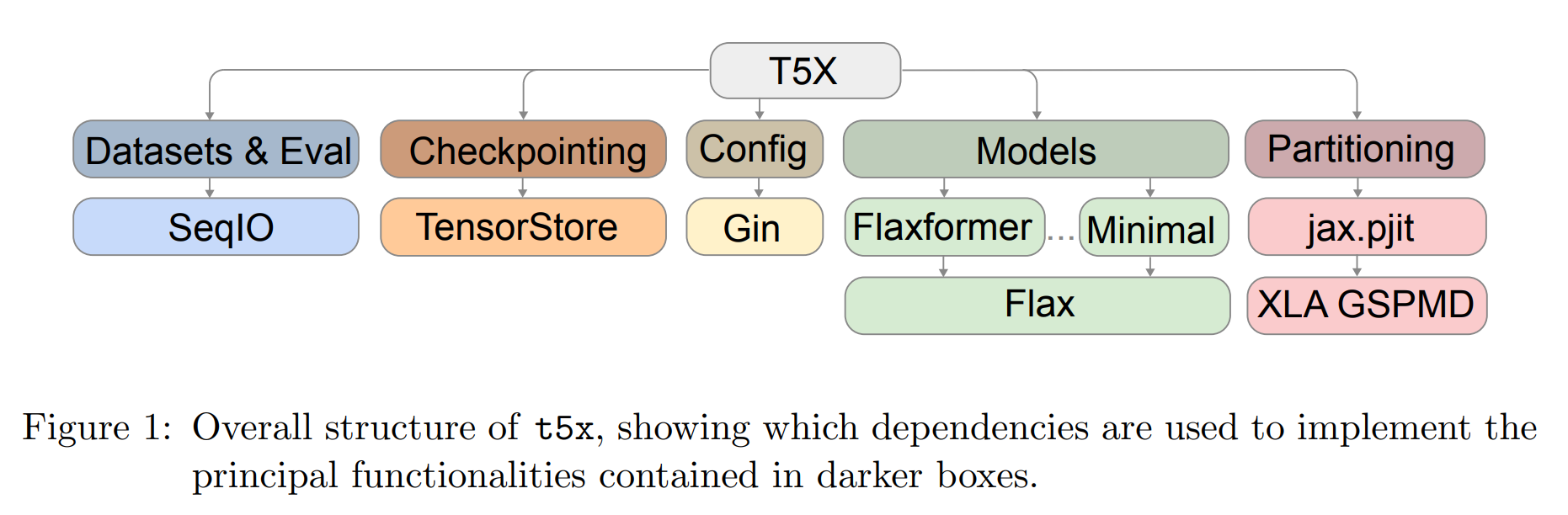
论文:Scaling Up Models and Data with t5x and seqio
论文标题:Scaling Up Models and Data with t5x and seqio
论文时间:31 Mar 2022
所属领域:自然语言处理
对应任务:语言模型
论文地址:https://arxiv.org/abs/2203.17189
代码实现:https://github.com/google-research/t5x , https://github.com/google/seqio
论文作者:Adam Roberts, Hyung Won Chung, Anselm Levskaya, Gaurav Mishra, James Bradbury, Daniel Andor, Sharan Narang, Brian Lester, Colin Gaffney, Afroz Mohiuddin, Curtis Hawthorne, Aitor Lewkowycz, Alex Salcianu, Marc van Zee, Jacob Austin, Sebastian Goodman, Livio Baldini Soares, Haitang Hu, Sasha Tsvyashchenko, Aakanksha Chowdhery, Jasmijn Bastings, Jannis Bulian, Xavier Garcia, Jianmo Ni, Andrew Chen, Kathleen Kenealy, Jonathan H. Clark, Stephan Lee, Dan Garrette, James Lee-Thorp, Colin Raffel, Noam Shazeer, Marvin Ritter, Maarten Bosma, Alexandre Passos, Jeremy Maitin-Shepard, Noah Fiedel, Mark Omernick, Brennan Saeta, Ryan Sepassi, Alexander Spiridonov, Joshua Newlan, Andrea Gesmundo
论文简介:Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. / 最近基于神经网络的语言模型从扩大训练数据集的大小和模型本身的参数数量中受益匪浅。
论文摘要:Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: t5x simplifies the process of building and training large language models at scale while maintaining ease of use, and seqio provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. t5x and seqio are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio respectively.
最近基于神经网络的语言模型从扩大训练数据集的大小和模型本身的参数数量中受益匪浅。由于各种因素,包括需要在超级计算机集群(例如 TPU)上分配计算、防止输入数据时出现瓶颈以及确保可重复的结果,扩大规模可能会很复杂。在这项工作中,我们提出了两个软件库来缓解这些问题:t5x 简化了大规模构建和训练大型语言模型的过程,同时保持易用性,seqio 提供了一个基于任务的 API,用于简单地创建快速和可重复的训练数据和评估管道。这些开源库已用于在具有数 TB 训练数据的数据集上训练具有数千亿参数的模型。除了这些库,我们还发布了类似 T5 的编码器-解码器模型以及类似 GPT 的仅解码器架构的配置和说明。 t5x 和 seqio 是开源的,可在 https://github.com/google-research/t5x 和 https://github.com/google /seqio 分别。

论文:OmniXAI: A Library for Explainable AI
论文标题:OmniXAI: A Library for Explainable AI
论文时间:1 Jun 2022
所属领域:模型可解释
对应任务:Counterfactual Explanation,Decision Making,Feature Engineering,Interpretable Machine Learning,Time Series,反事实解释,决策制定,特征工程,可解释机器学习,时间序列
论文地址:https://arxiv.org/abs/2206.01612
代码实现:https://github.com/salesforce/omnixai
论文作者:Wenzhuo Yang, Hung Le, Silvio Savarese, Steven C. H. Hoi
论文简介:We introduce OmniXAI (short for Omni eXplainable AI), an open-source Python library of eXplainable AI (XAI), which offers omni-way explainable AI capabilities and various interpretable machine learning techniques to address the pain points of understanding and interpreting the decisions made by machine learning (ML) in practice. / 我们介绍了 OmniXAI(Omni eXplainable AI 的缩写),一个可解释 AI(XAI)的开源 Python 库,它提供全方位可解释的 AI 能力和各种可解释的机器学习技术,解决机器学习 (ML) 在实践应用中做决策的理解和解释痛点。
论文摘要:We introduce OmniXAI (short for Omni eXplainable AI), an open-source Python library of eXplainable AI (XAI), which offers omni-way explainable AI capabilities and various interpretable machine learning techniques to address the pain points of understanding and interpreting the decisions made by machine learning (ML) in practice. OmniXAI aims to be a one-stop comprehensive library that makes explainable AI easy for data scientists, ML researchers and practitioners who need explanation for various types of data, models and explanation methods at different stages of ML process (data exploration, feature engineering, model development, evaluation, and decision-making, etc). In particular, our library includes a rich family of explanation methods integrated in a unified interface, which supports multiple data types (tabular data, images, texts, time-series), multiple types of ML models (traditional ML in Scikit-learn and deep learning models in PyTorch/TensorFlow), and a range of diverse explanation methods including “model-specific” and “model-agnostic” ones (such as feature-attribution explanation, counterfactual explanation, gradient-based explanation, etc). For practitioners, the library provides an easy-to-use unified interface to generate the explanations for their applications by only writing a few lines of codes, and also a GUI dashboard for visualization of different explanations for more insights about decisions. In this technical report, we present OmniXAI’s design principles, system architectures, and major functionalities, and also demonstrate several example use cases across different types of data, tasks, and models.
我们介绍了 OmniXAI(Omni eXplainable AI 的缩写),它是一个可解释 AI(XAI)的开源 Python 库,它提供了全方位可解释的 AI 功能和各种可解释的机器学习技术,以解决机器学习 (ML) 在实践应用中做决策的理解和解释痛点。 OmniXAI 旨在成为一个一站式综合库,让数据科学家、ML 研究人员和从业者在 ML 过程的不同阶段(数据探索、特征工程、模型开发、评估和决策等)。特别是,我们的库包含丰富的解释方法家族,集成在一个统一的界面中,支持多种数据类型(表格数据、图像、文本、时间序列)、多种类型的 ML 模型(Scikit-learn 中的传统 ML 和深度PyTorch/TensorFlow 中的学习模型),以及一系列不同的解释方法,包括“特定于模型”和“与模型无关”的解释方法(例如特征归因解释、反事实解释、基于梯度的解释等)。对于从业者,该库提供了一个易于使用的统一界面,只需编写几行代码即可为他们的应用程序生成解释,还提供了一个 GUI 仪表板,用于可视化不同的解释,以获得对模型决策结果的更多理解视角。在这份技术报告中,我们介绍了 OmniXAI 的设计原则、系统架构和主要功能,并展示了跨不同类型的数据、任务和模型的几个示例用例。



论文:VideoINR: Learning Video Implicit Neural Representation for Continuous Space-Time Super-Resolution
论文标题:VideoINR: Learning Video Implicit Neural Representation for Continuous Space-Time Super-Resolution
论文时间:CVPR 2022
所属领域:计算机视觉
对应任务:Space-time Video Super-resolution,Super-Resolution,Video Super-Resolution,时空视频超分辨率,超分辨率,视频超分辨率
论文地址:https://arxiv.org/abs/2206.04647
代码实现:https://github.com/picsart-ai-research/videoinr-continuous-space-time-super-resolution
论文作者:Zeyuan Chen, Yinbo Chen, Jingwen Liu, Xingqian Xu, Vidit Goel, Zhangyang Wang, Humphrey Shi, Xiaolong Wang
论文简介:The learned implicit neural representation can be decoded to videos of arbitrary spatial resolution and frame rate. / 学习到的隐式神经表示可以解码为任意空间分辨率和帧速率的视频。
论文摘要:Videos typically record the streaming and continuous visual data as discrete consecutive frames. Since the storage cost is expensive for videos of high fidelity, most of them are stored in a relatively low resolution and frame rate. Recent works of Space-Time Video Super-Resolution (STVSR) are developed to incorporate temporal interpolation and spatial super-resolution in a unified framework. However, most of them only support a fixed up-sampling scale, which limits their flexibility and applications. In this work, instead of following the discrete representations, we propose Video Implicit Neural Representation (VideoINR), and we show its applications for STVSR. The learned implicit neural representation can be decoded to videos of arbitrary spatial resolution and frame rate. We show that VideoINR achieves competitive performances with state-of-the-art STVSR methods on common up-sampling scales and significantly outperforms prior works on continuous and out-of-training-distribution scales. Our project page is at http://zeyuan-chen.com/VideoINR/
视频通常将流和连续的视觉数据记录为离散的连续帧。由于高保真视频的存储成本昂贵,因此大部分以较低的分辨率和帧率存储。最近开发了时空视频超分辨率 (STVSR) 的作品,以将时间插值和空间超分辨率结合在一个统一的框架中。然而,它们中的大多数只支持固定的上采样比例,这限制了它们的灵活性和应用。在这项工作中,我们提出了视频隐式神经表示 (VideoINR),而不是遵循离散表示,并展示了它在 STVSR 中的应用。学习到的隐式神经表示可以解码为任意空间分辨率和帧速率的视频。我们表明,VideoINR 在常见的上采样尺度上通过最先进的 STVSR 方法实现了具有竞争力的性能,并且在连续和训练外分布尺度上显着优于先前的工作。我们的项目页面在http://zeyuan-chen.com/VideoINR/




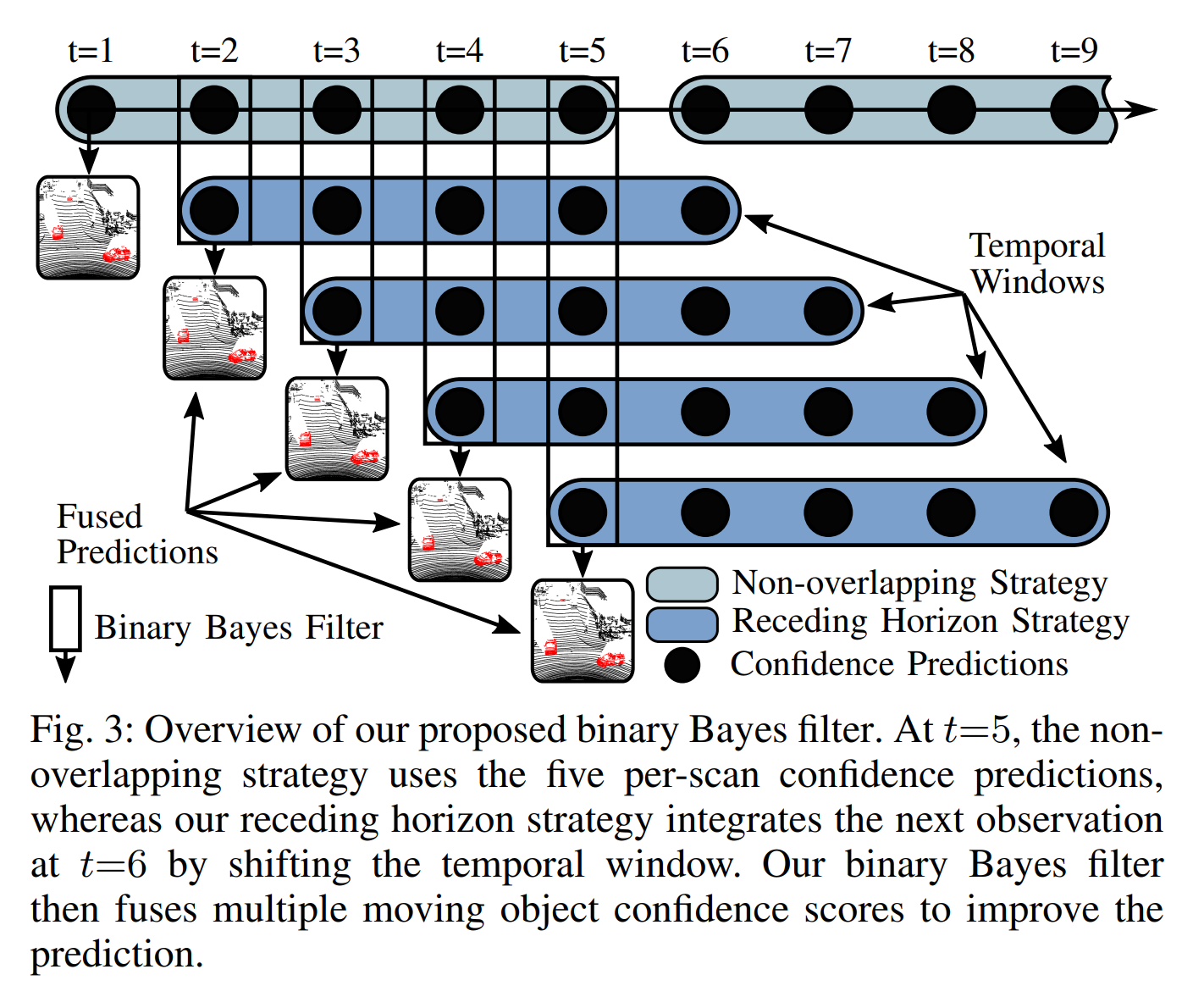
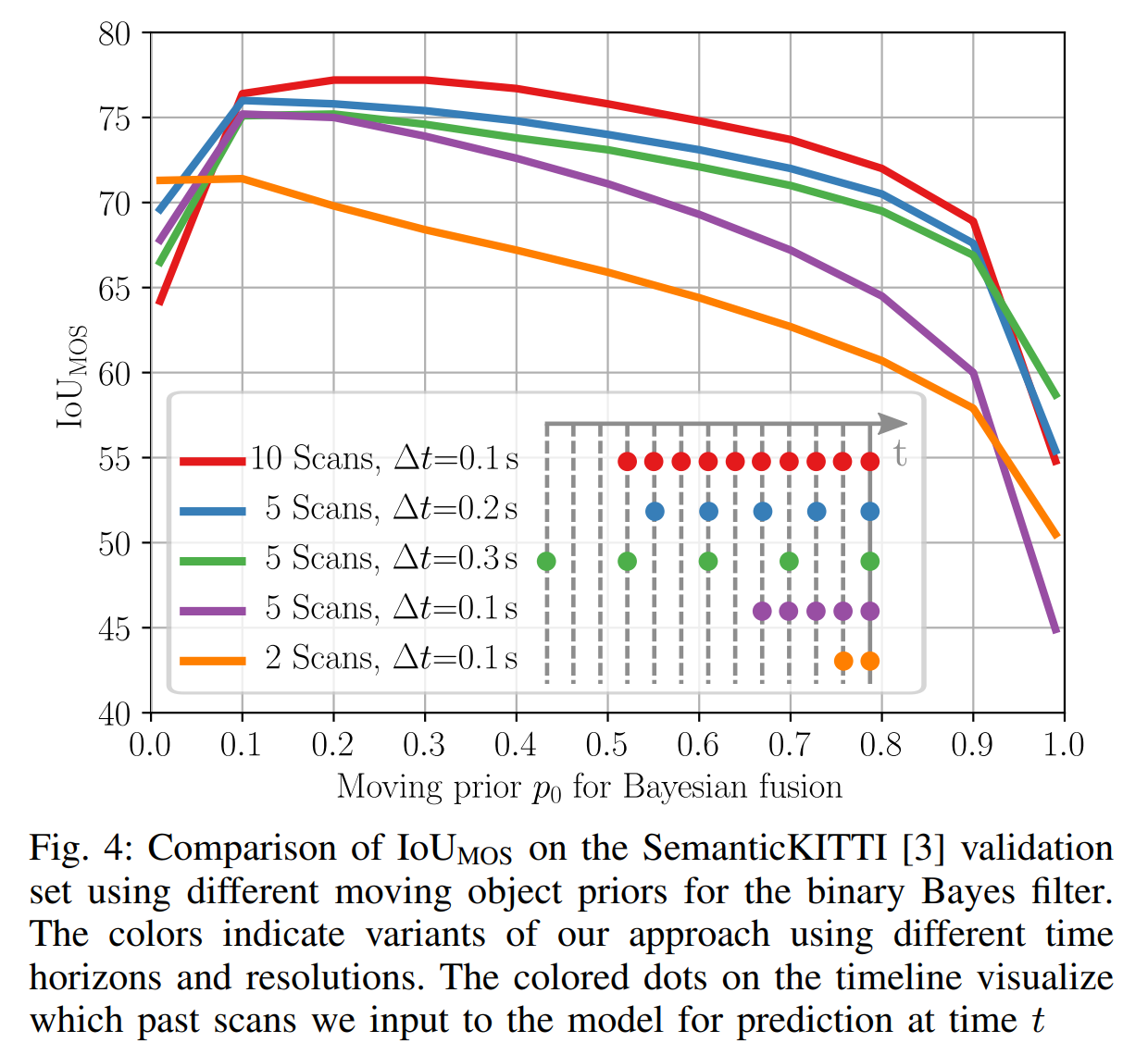
论文:Receding Moving Object Segmentation in 3D LiDAR Data Using Sparse 4D Convolutions
论文标题:Receding Moving Object Segmentation in 3D LiDAR Data Using Sparse 4D Convolutions
论文时间:8 Jun 2022
所属领域:计算机视觉
对应任务:Autonomous Vehicles,Pose Estimation,Semantic Segmentation,自动驾驶汽车,姿态估计,语义分割
论文地址:https://arxiv.org/abs/2206.04129
代码实现:https://github.com/prbonn/4dmos
论文作者:Benedikt Mersch, Xieyuanli Chen, Ignacio Vizzo, Lucas Nunes, Jens Behley, Cyrill Stachniss
论文简介:A key challenge for autonomous vehicles is to navigate in unseen dynamic environments. / 自动驾驶汽车的一个关键挑战是在看不见的动态环境中导航。
论文摘要:A key challenge for autonomous vehicles is to navigate in unseen dynamic environments. Separating moving objects from static ones is essential for navigation, pose estimation, and understanding how other traffic participants are likely to move in the near future. In this work, we tackle the problem of distinguishing 3D LiDAR points that belong to currently moving objects, like walking pedestrians or driving cars, from points that are obtained from non-moving objects, like walls but also parked cars. Our approach takes a sequence of observed LiDAR scans and turns them into a voxelized sparse 4D point cloud. We apply computationally efficient sparse 4D convolutions to jointly extract spatial and temporal features and predict moving object confidence scores for all points in the sequence. We develop a receding horizon strategy that allows us to predict moving objects online and to refine predictions on the go based on new observations. We use a binary Bayes filter to recursively integrate new predictions of a scan resulting in more robust estimation. We evaluate our approach on the SemanticKITTI moving object segmentation challenge and show more accurate predictions than existing methods. Since our approach only operates on the geometric information of point clouds over time, it generalizes well to new, unseen environments, which we evaluate on the Apollo dataset.
自动驾驶汽车的一个关键挑战是在看不见的动态环境中导航。将移动对象与静态对象分开对于导航、姿势估计和了解其他交通对象接下来将如何移动至关重要。在这项工作中,我们解决了将属于当前移动物体(如步行行人或驾驶汽车)的 3D LiDAR 点与从非移动物体(如墙壁和停放的汽车)获得的点区分开来的问题。我们的方法采用一系列观察到的 LiDAR 扫描,并将它们变成体素化的稀疏 4D 点云。我们应用计算效率高的稀疏 4D 卷积来联合提取空间和时间特征,并预测序列中所有点的移动对象置信度得分。我们研发了一种后退视野策略,使我们能够在线预测移动物体,并根据新的观察结果在行进路径中改进预测。我们使用二元贝叶斯滤波器递归地集成扫描的新预测,从而产生更稳健的估计。我们评估了我们在 SemanticKITTI 移动对象分割挑战中的方法,并展示了比现有方法更准确的预测。由于我们的方法只对点云的几何信息进行操作,因此它可以很好地推广到新的、看不见的环境,我们在 Apollo 数据集上对其进行评估。


我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。

- 作者:韩信子@ShowMeAI
- 历史文章列表
- 专题合辑&电子月刊
- 声明:版权所有,转载请联系平台与作者并注明出处
- 欢迎回复,拜托点赞,留言推荐中有价值的文章、工具或建议,我们都会尽快回复哒~