### 背景介绍
近年来人工智能在自然语言处理领域取得了巨大的进展。其中一项引人注目的技术是生成模型,如OpenAI的GPT-3.5。这类模型通过学习大量的文本数据,具备了生成高质量文本的能力,从而引发了一系列关于文本生成真实性的讨论。
正因为生成模型的迅猛发展,也引发了一个新的挑战,即如何区分人类编写的文本与机器生成的文本。传统上,我们借助语法错误、逻辑不连贯等特征来辨别机器生成的文本,但随着生成模型的不断改进,这些特征变得越来越难以区分。因此,为了解决这一问题,研究人员开始探索使用NLP文本分类技术来区分人类编写的文本和机器生成的文本。
#### 任务一:报名比赛,下载比赛数据集并完成读取
- 说明:在这个任务中,你需要访问比赛地址并完成比赛报名。然后,下载比赛数据集,并使用Pandas库完成数据集的读取和加载。
- 实践步骤:
- 访问比赛地址:2023 iFLYTEK A.I.开发者大赛-讯飞开放平台
- 完成比赛报名并获取数据集下载链接。
- 使用下载链接下载比赛数据集。
- 使用Pandas库读取和加载数据集,将数据转化为可供处理的数据结构。
读取下载数据

显示部分结果
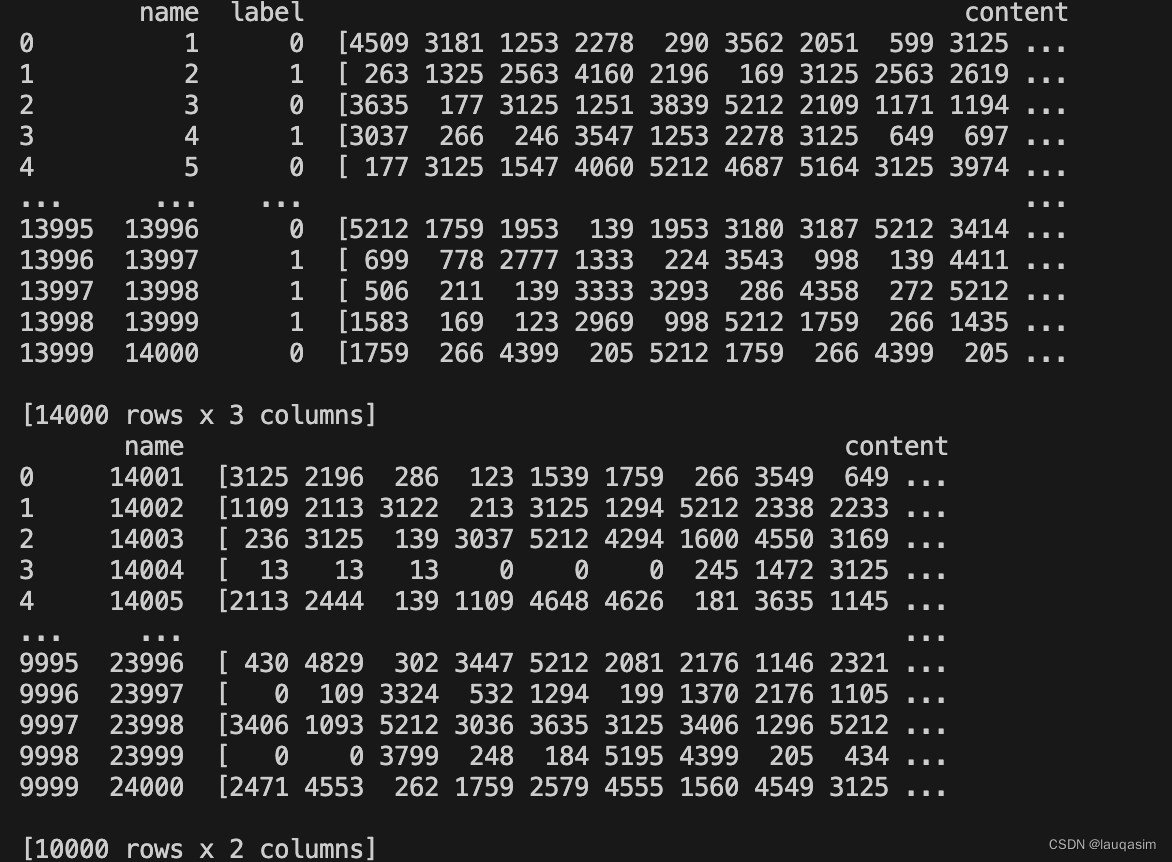
训练集一共有14000,有 name、label、content三列,content已经脱敏,转换成id。
测试集1000,有name、content两列,需要生成label进行提交。