整理 | 梦依丹 责编 | XXXXX
出品 | CSDN(ID:CSDNnews)
在马斯克反复承诺表示要开源 Twitter 推荐算法之后,3 月 31 日,Twitter 部分推荐算法源码正式在 GitHub 上开放,采用 GNU Affero General Public License v3.0 许可证。

Twitter 开放推荐算法源码
https://github.com/twitter/the-algorithm
Twitter 在 GitHub 上发布了两个代码库,包括用于控制用户在 For You 时间线上看到推文的机制。Twitter 将此举描述为“更透明的第一步”,同时还可以“防止风险”,既可以保护 Twitter 本身,也可以保护平台上的人。
此次开源不包括驱动 Twitter 广告推荐的代码或用于训练 Twitter 推荐算法的数据。Twitter 表示:“[我们排除了]任何可能危及用户安全和隐私或破坏我们打击儿童性侵犯和操纵等恶意行为的能力的代码。”
马斯克在 Twitter Spaces 上提到:
“算法的初始版本会比较尴尬,人们会发现许多错误,但我们会很快修复。即使你不同意某些内容,但至少你会知道它为什么在那里,而且你不会被秘密操纵...这里的类比是我们所追求的 Linux 作为开源操作系统的伟大范例...在理论上,人们可以发现许多 Linux 的漏洞。事实上,发生的是社区识别和修复这些漏洞。”
后续 Twitter 将开源所有显示展示推文相关的代码。

在 Twitter 源码公布后,新浪微博新技术研发负责人张俊林在朋友圈中提到:
Twitter 开源了推荐系统源代码,发现排序模型用的是我们两年前发布的 MaskNet 模型,Twitter 的研发人员也在开源当天给我们发了一封邮件,他们和其他排序模型做过效果对比,发现 MaskNet 是效果最好的,所以最终 Twitter 排序采用了这个模型。我们自己内部评估,这个模型也是我们自己过去几年摸索的几个模型里(FiBiNet、GateNet、MaskNet、ContextNet)综合效果最好的一个。
要说搜广推模型,卷得最狠的应该还是国内互联网公司,不过,随着 GPT 4 的降临,很可能这个赛道未来用什么模型已经不那么重要了。

如何从 5 亿条推文中精选内容给用户?
一条推文从发布到展示,期间都经历了哪些奇妙的旅程呢?Twitter 官博重点介绍了“For You”列表下的算法相关推荐机制和排名,每天从 5亿条推文中展示部分精选内容的背后,正式揭晓。
Twitter 算法推荐的基础是一组核心模型和特征,从推文、用户和互动数据中提取潜在信息。推荐流水线由三个主要阶段组成,这些阶段使用这些特征:
1、从不同的推荐来源中获取最佳推文,这个过程称为获取候选推文;
2、使用机器学习模型对每个推文进行排名;
3、应用启发式和过滤器,例如过滤用已屏蔽用户的推文、NSFW 内容和已经看过的推文等。
负责构建和提供 For You 时间线的服务称为 Home Mixer。Home Mixer 基于 Product Mixer 构建,Product Mixer 是 Twitter 自定义的 Scala 框架,可以帮助构建内容流。该服务充当软件骨干,连接不同的候选源、评分函数、启发式和过滤器。
下面的图表说明了构建时间线所使用的主要组件:
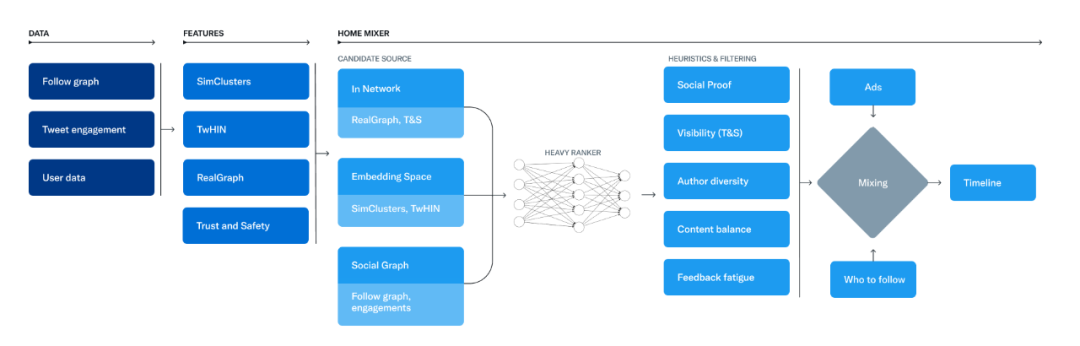
作为该系统的核心部分,大致按照单个时间线请求期间被调用的顺序,从检索候选推文开始。
候选推文来源
Twitter 有几个候选推文作为来源,它们为用户检索最近和相关的推文。对于每个请求,推荐算法会尝试通过这些来源从数亿条推文中提取最佳的 1500 条。会从用户关注的(内部网络)和不关注的人中(外部网络)找到候选者。目前, For You 时间线平均由 50% 的内部网络推文和 50% 的外部网络推文组成,也存在因用户而异的情况。
内部网络资源
内部网络资源是最大的候选推文来源,旨在提供你关注的用户最相关、最新的推文。它使用逻辑回归模型高效地对你关注对象的推文进行排名。然后将排名靠前的推文发送到下一个阶段。
这里最重要的组件是真实图(Real Graph)模型,用于预测两个用户之间的互动可能性。用户和推文作者之间的真实图得分越高,For You 下面即会展示更多两者之间的推文。
内部网络资源目前已停用 Fanout Service,这是一个 12 年前的服务,用于为每个用户提供缓存的内部网络推文。目前 Twitter 还在重新设计逻辑回归排名模型,该模型最近几年已经更新和训练过!
外部网络资源
相较于内部网络资源,在用户关注之外找到相关的推文是一个更加棘手的问题, Twitter 采取了两种方法来解决这个问题。
1、社交图谱,首先通过分析你所关注用户或兴趣相似的用户互动来推出你可能会感兴趣的内容;其次会通过一些问题来遍历互动和关注的图形来对结果进行逻辑回归模型排名,如 Twitter 开发的 GrapJet 图形处理引擎,可以维护用户和推文之间的实时互动图形。
2、嵌入空间,旨在回答关于内容相似性的更一般的问题:哪些推文和用户与我的兴趣相似?Twitter 最有用的嵌入空间之一是 SimClusters。SimClusters 使用自定义矩阵分解算法发现由一群有影响力的用户锚定的社区。有 145k 个社区,每三周更新一次。
排名
内容源确定好,那如何来确定内容的时间线呢?排名是通过一个约 48M 个参数的神经网络实现的,该神经网络持续根据推文互动进行训练,以优化积极的参与度(例如,点赞、转发和回复)。这种排名机制考虑了数千个特征,并输出十个标签,以给每个推文打分,其中每个标签表示参与的概率。Twitter 根据这些分数对推文进行排名。
启发式、过滤器和产品特性
在排名阶段之后,Twitter 会应用启发式和过滤器来实现各种产品特性。这些特性共同工作,创建一个平衡和多样化的信息流。其中包括:
可见性过滤:根据内容和用户偏好过滤推文。例如,删除用户屏蔽或静音的帐户的推文;
作者多样性:避免连续太多来自单个作者的推文;
内容平衡:确保提供公平的网络内资源和网络外推文平衡;
基于反馈的打分机制:如果查看者在某些推文周围提供了负面反馈,则降低该推文的分数;
社交证明:该机制通过排除没有与推文具有二度连接的网络外推文来实现这一点。这意味着,为了被推荐给用户,推文必须与用户的关注者或关注者的关注者有一定的连接;
对话:通过将回复与原始推文串在一起,为回复提供更多上下文;
编辑的推文:确定设备上当前的推文是否过时,并发送指令以用编辑版本替换它们。
混合和推送
作为推文展示到用户面前的最后一步,系统将推文与其他非推文内容(如广告、关注建议和入门提示)混合在一起,返回用户的设备上显示。
上述管道每天运行约 50 亿次,并平均在 1.5 秒内完成。单个管道执行需要 220 秒的 CPU 时间,几乎用户在应用程序上感知到的延迟的 150 倍。

被特殊照顾的马斯克
Twitter 算法开源引起了用户的强烈兴趣,用户很快发现 Twitter CEO 马斯克(Elon Musk)得到了特别对待。上个月马斯克的推文曾一度展示给几乎所有 Twitter 用户。相关算法代码特别提到了 author_is_elon、author_is_power_user、author_is_democrat、author_is_republican...
("author_is_elon",candidate =>candidate.getOrElse(AuthorIdFeature, None).contains(candidate.getOrElse(DDGStatsElonFeature, 0L))),("author_is_power_user",candidate =>candidate.getOrElse(AuthorIdFeature, None).exists(candidate.getOrElse(DDGStatsVitsFeature, Set.empty[Long]).contains)),("author_is_democrat",candidate =>candidate.getOrElse(AuthorIdFeature, None).exists(candidate.getOrElse(DDGStatsDemocratsFeature, Set.empty[Long]).contains)),("author_is_republican",candidate =>candidate.getOrElse(AuthorIdFeature, None).exists(candidate.getOrElse(DDGStatsRepublicansFeature, Set.empty[Long]).contains)),)这段代码地址:https://github.com/twitter/the-algorithm/blob/7f90d0ca342b928b479b512ec51ac2c3821f5922/home-mixer/server/src/main/scala/com/twitter/home_mixer/functional_component/decorator/HomeTweetTypePredicates.scala#L224-L246
随后,一位 Twitter 工程师表示,这些标签仅用于指标。但马斯克表示,他不知道这些标签之前没有出现过,并表示它们不应该存在。
参考链接:
https://blog.twitter.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm
https://techcrunch.com/2023/03/31/twitter-reveals-some-of-its-source-code-including-its-recommendation-algorithm/

☞ChatGPT 大规模封号亚洲节点,并停止注册;Google 否认 Bard 窃取 ChatGPT 数据进行训练|极客头条
☞ChatGPT 类大语言模型为什么会带来“神奇”的涌现能力?
☞让模型理解和推断代码背后的意图是预训练模型的核心挑战 | NPCon演讲实录