随着 ChatGPT 的出现,「AI 幻觉」一词被频繁提及。那么,什么是 AI 幻觉?简单来说,就是大模型在一本正经地胡说八道。
不止 ChatGPT,其他大语言模型也经常如此,究其根本是大语言模型在训练的过程中存在数据偏差。为此,当问题不在射程范围内,它们或开始模糊答案,或编造一些看似正确的错误答案。在此情况下,如何阻止「AI 幻觉」成为开发者亟待解决的事情。
本文将从应对思路讲起,由原理、工具、操作实例展开,手把手教你如何阻止「AI 幻觉」!
阻止大模型“胡说八道”的三种思路
总体而言有三种思路:微调大语言模型、调整 prompt、用知识库进行限制。
提起阻止「AI 幻觉」,大家首先会想到用自己的数据对大语言模型进行微调。不过,这种思路是不切实际的,因为微调这件事情本身就与大语言模型的特点——零样本迁移。再者,微调需要准备大量的数据用于训练,这就对数据提出了更高的要求,例如数据必须有用,要进行数据清洗、数据要与训练适配等。此外,训练大模型对于资源的消耗堪称巨大,一般开发者很难承受背后的高昂费用。不止如此,经过微调的模型也不足以通用,甚至失去了大语言模型零样本迁移的优势,其成本和收益根本不成比例。
第二种思路是调整 prompt,即修改提示,例如,可以跟 ChatGPT 说"当你不知道答案的时候,不要编造答案,直接回答不知道。"但是,如果大家尝试过就会发现,ChatGPT 并不能很好地遵循此类指令,仍旧会出现编造答案的情况。另外,prompt 的长度是有限制的,众所周知 OpenAI 的调用按照长度单位 token 收费。超长且不甚有用的 prompt 只会弊大于利,只调整 prompt 的方式都谈不上是最优解。
第三种思路是通过建立知识库(Knowledge Base)的方式限制 「AI 幻觉」的“自由发挥”。知识库,顾名思义是给 ChatGPT 灌输一些额外的知识,为它提供更多的参考。前面提到了 token 的限制,因此如果把知识一股脑地“喂”给 ChatGPT 绝对属于得不偿失,且知识库中的知识未必都对问题有帮助。在此情况下,需要对这些知识进行语义搜索或者说是初步筛选,以找出真正有用的知识。不过,传统的知识检索的方式与之并不适配。如果只进行关键词搜索,答案很可能对回答问题毫无帮助或者遗漏重要的消息, CVP Stack 能够有效地解决这一问题。
什么是 CVP Stack?C 是以 ChatGPT 为代表的大模型,它在 AI 程序中充当中央处理器的角色;V 代表 Vector Database,即以 Zilliz Cloud 和 Milvus 为代表的向量数据库,为大模型提供知识存储;P 代表 Prompt Engineering,各环节通过 prompt 的方式进行交互。CVP 是我们的工程师在做问答机器人 OSSChat 时提出来的一种技术栈,对该项目感兴趣的同学可以点击详情了解(https://osschat.io/chat)。
CVP Stack 实操:用 Zilliz Cloud 和 LangChain 进行知识增强
如何借助 CVP Stack 模式对大模型进行知识增强?接下来的这个实例或许可以帮助大家了解一二。
不过,在正式进入实操环节前,需要先准备好 Zilliz Cloud。Zilliz Cloud 是用于全托管 Milvus 的云服务,有了 Zilliz Cloud 后,用户无需本地部署或维护向量数据库 Milvus,可以更加简单、快速地上手操作。目前,Zilliz Cloud 已经支持 AWS、GCP 的服务,今年 6 月底即将登陆阿里云,其他几朵云的服务也已提上日程。
回到 Zilliz Cloud 的准备环节:
-
用户首先可以在 Zilliz 官网注册账号及登陆(https://cloud.zilliz.com/signup),现在注册即可获赠价值 400 的 credits;
-
登陆后可以创建 Database,在此环节可以选择对应的云服务及所属项目;
-
选择过后,页面右边会给出计费方式;
-
随后便可在底部使用你所创建的 database;
-
完成该步骤后,在 database details 中找到连接数据库的地址。有了连接地址后,用户就可以根据自己的计算机语言偏好选择用何种 SDK 进行操作。
准备完成后便可进入实操环节,用 Python 代码基于 Langchain 搭建一个带有知识增强的智能聊天机器人。其中 Vectorstore,也就是向量存储部分,会用到 Zilliz Cloud。该系统的架构主要分为问答和知识录入两条链路:
-
知识录入:把文档转成向量,将其存储在 Zilliz Cloud 之中。由 Zilliz Cloud 提供向量存储和语义搜索的能力,在提问环节为 ChatGPT 提供额外的知识以增强其问答能力。
-
问答:向大模型提问并得到最后的答案。不过如果在这个过程中使用知识增强,首先会将问题转换成向量,随后在知识库也就是向量数据库中进行语义搜索,并筛选出其中有用的信息,最终连同问题一起交给 ChatGPT。此时,ChatGPT 会综合问题及接收到的有用信息给出一个更靠谱的回答。
具体操作如下:
首先导入需要的 Langchain 模块(根据环境安装相关 python 依赖,比如 LangChain、pymilvus)。
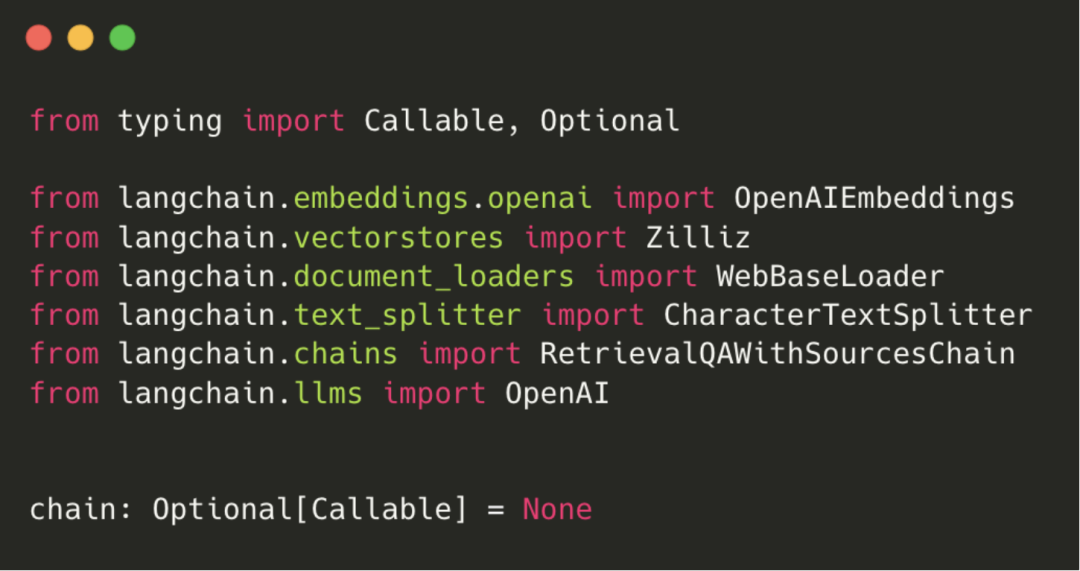
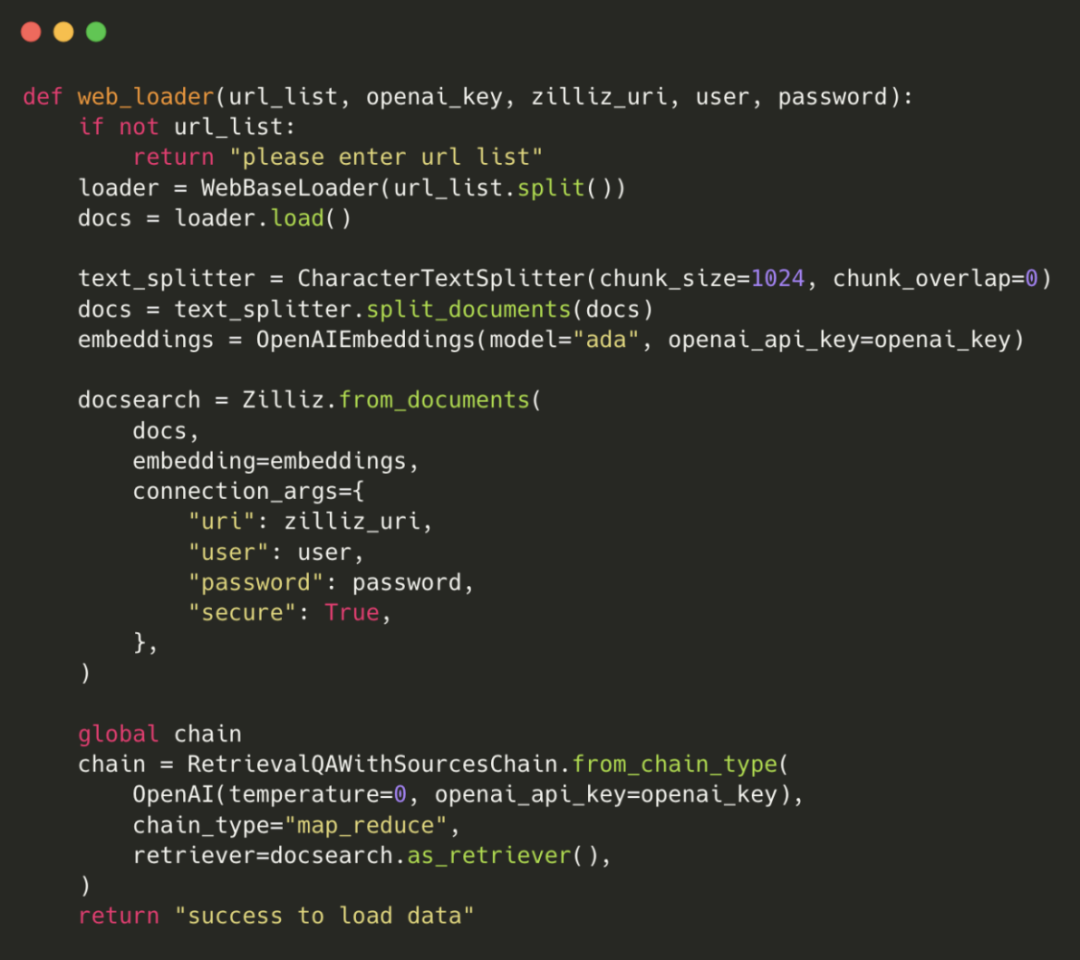
其中文档的加载和处理部分会用到 LangChain 提供的网页加载、文本拆分工具,具体代码如下:
此处有一个在线的 demo 供大家参考,目前已公开在 Hugging Face 中,链接为 https://huggingface.co/spaces/SimFG/LangChain-Zilliz-Cloud
 |demo 图片
|demo 图片
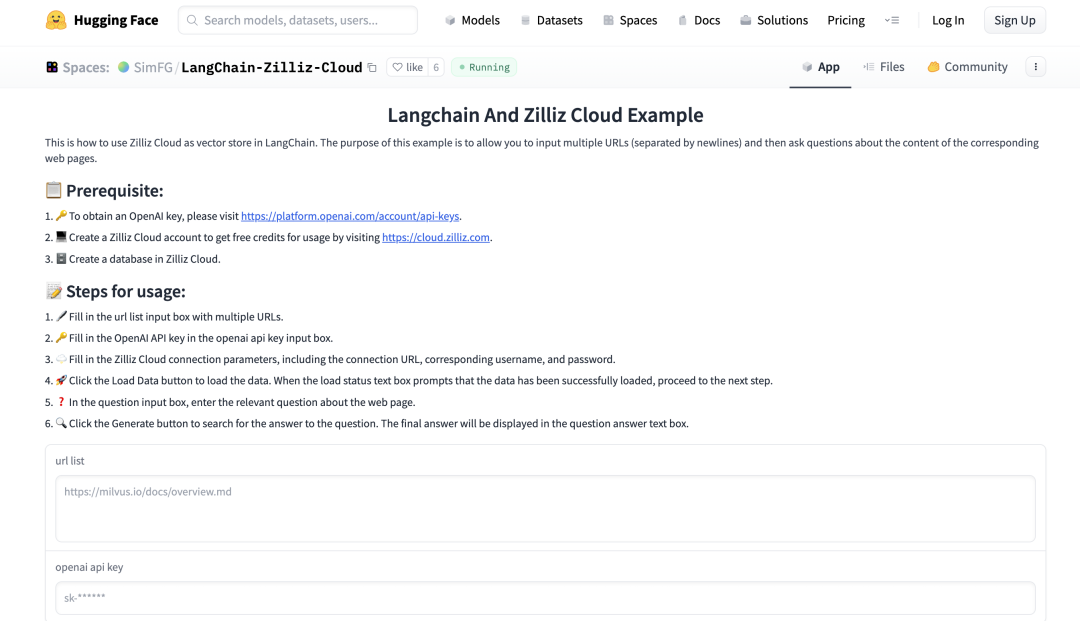
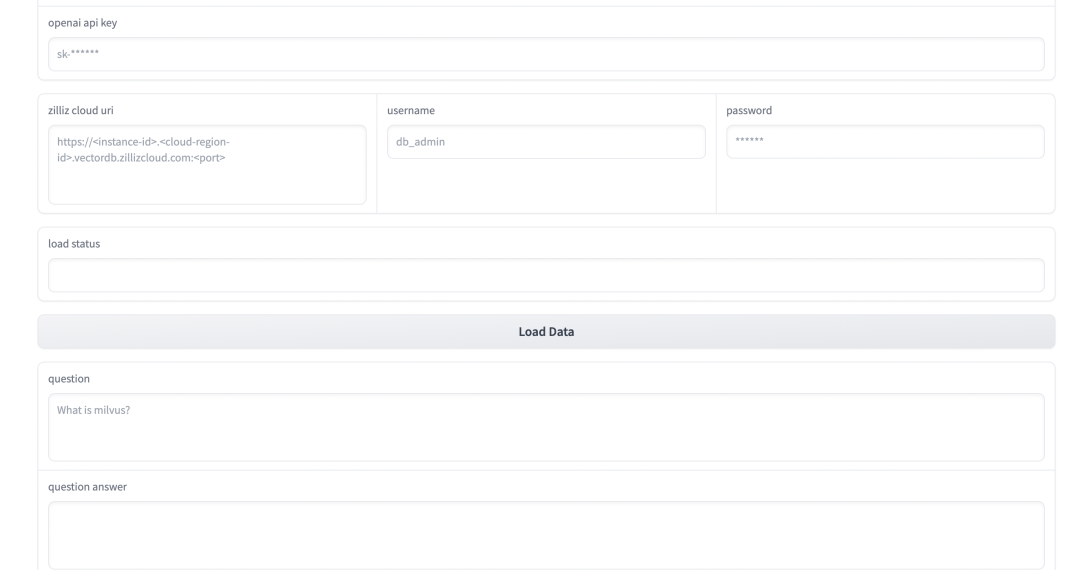 |打开 demo 后会看到该页面
|打开 demo 后会看到该页面
-
输入 URL 地址,该网页的内容将会被拆分并转成向量,存入数据库;
-
从 OpenAI 获取 key,用于连接 OpenAI 服务;
-
填写 Zilliz Cloud 数据库的连接信息,包括前文中提到的连接地址、用户名和密码;
-
点击 Load Data 创建知识底库,创建时间取决于文档长度;
-
加载完毕便可进行提问。
以上便是借助 Zilliz Cloud 和 LangChain 实现问答机器人(大模型)知识增强的全过程,具体讲解视频和 PPT 可点击获取。 (本文作者顾梦佳系 Zilliz 算法工程师)
-
如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。 -
欢迎关注微信公众号“Zilliz”,了解最新资讯。 
本文由 mdnice 多平台发布