目录
1、批归一化(Batch Normalization)的含义以及如何理解
2、批归一化(BN)算法流程
3、什么时候使用Batch Normalization
总结
1、批归一化(Batch Normalization)的含义以及如何理解
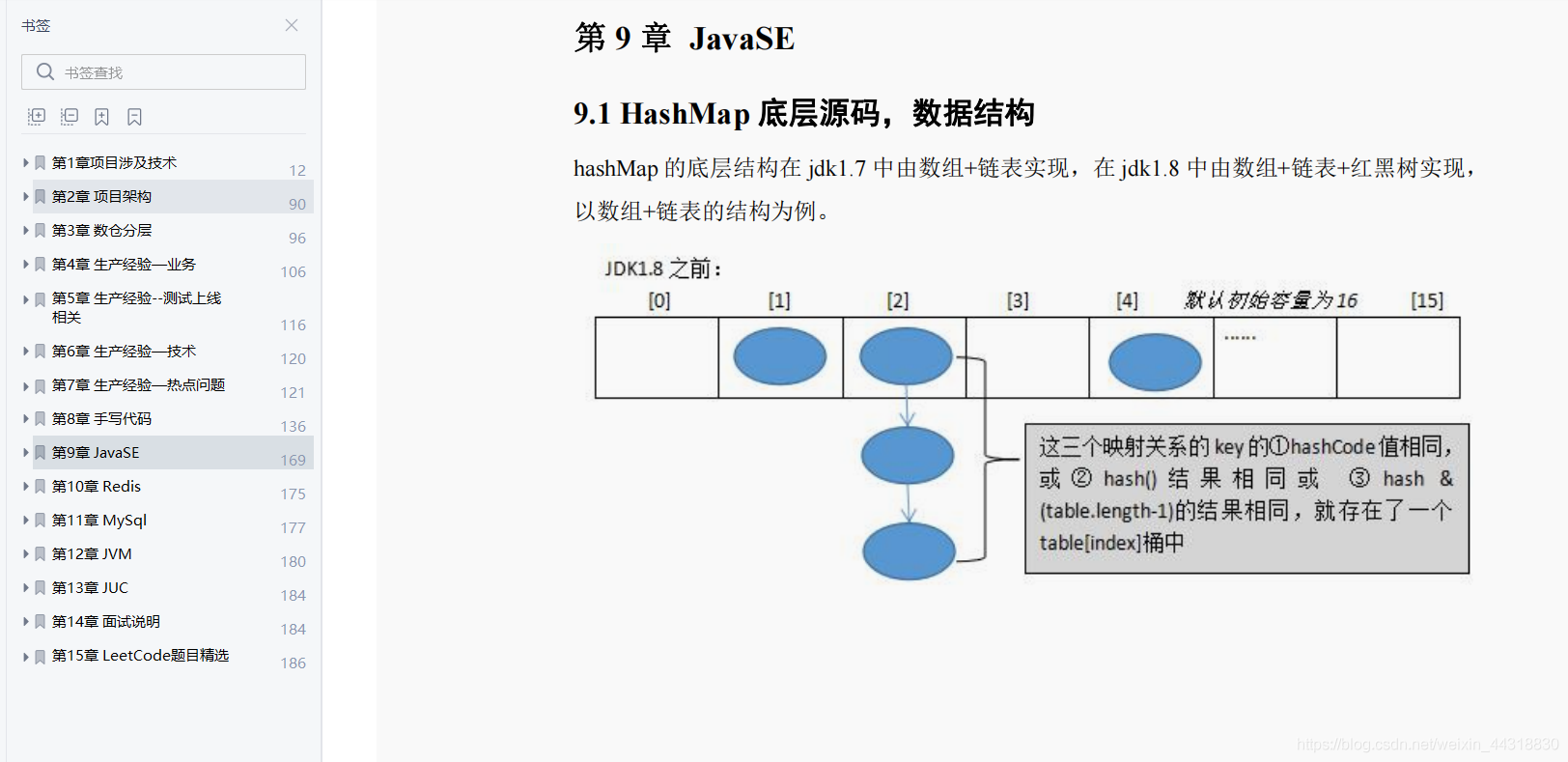
Batch Normalization,简称BatchNorm或BN,翻译为“批归一化”,是神经网络中一种特殊的层,如今已是各种流行网络的标配(目前最流行的结构:卷积+BN+激活函数)。
深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
下面,举tanh激活函数的例子作进一步说明。

上者没有进行 normalization,下者进行了 normalization,这样当然是下者能够更有效地利用 tanh 进行非线性化的过程。没有 normalize 的数据 使用 tanh 激活以后, 激活值大部分都分布到了饱和阶段, 也就是大部分的激活值不是-1, 就是1, 而 normalize 以后, 大部分的激活值在每个分布区间都还有存在. 再将这个激活后的分布传递到下一层神经网络进行后续计算, 每个区间都有分布的这一种对于神经网络就会更加有价值。
如果还不明白,我再举个放羊的例子。
最开始羊群聚在一起吃草,过了一段时间羊群慢慢散开了,这时候羊群的主人把羊群往一块赶一赶,防止个别的羊走散了。羊群就是输入数据,BN就是羊群的主人。
2、批归一化(BN)算法流程
下面给出 BN 算法在训练时的过程
输入:上一层输出结果 X = {x_1, x_2, ..., x_m} ,学习参数 ,
算法流程:
第一步 计算上一层输出数据的均值
其中,m 是此次训练样本 batch 的大小。
第二步 计算上一层输出数据的标准差
第三步 归一化处理,得到
其中 是为了避免分母为 0 而加进去的接近于 0 的很小值
第四步 重构,对经过上面归一化处理得到的数据进行重构,得到
其中, 为可学习参数。
注:上述是 BN 训练时的过程,但是当在投入使用时,往往只是输入一个样本,没有所谓的均值 和标准差
。此时,均值
是计算所有 batch
值的平均值得到,标准差
采用每个batch
的无偏估计得到。
3、什么时候使用Batch Normalization
在CNN中,BN应作用在非线性映射前。在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
BN比较适用的场景是:每个mini-batch比较大,数据分布比较接近。在进行训练之前,要做好充分
的shuffle,否则效果会差很多。另外,由于BN需要在运行过程中统计每个mini-batch的一阶统计量和二阶统计量,因此不适用于动态的网络结构和RNN网络。
总结
BN的作用就是把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。因为梯度一直都能保持比较大的状态,所以很明显对神经网络的参数调整效率比较高,就是变动大,就是说向损失函数最优值迈动的步子大,也就是说收敛地快。