转自知乎 https://www.zhihu.com/question/22178202/answer/223017546
本科学的时候是院长教的,当时他说这个东西很有用,也仔细听了没懂什么意思,现在回过头来看,还真有用。
信息熵的定义与上述这个热力学的熵,虽然不是一个东西,但是有一定的联系。熵在信息论中代表随机变量不确定度的度量。一个离散型随机变量 的熵
定义为:
这个定义的特点是,有明确定义的科学名词且与内容无关,而且不随信息的具体表达式的变化而变化。是独立于形式,反映了信息表达式中统计方面的性质。是统计学上的抽象概念。
所以这个定义如题主提到的可能有点抽象和晦涩,不易理解。那么下面让我们从直觉出发,以生活中的一些例子来阐述信息熵是什么,以及有什么用处。
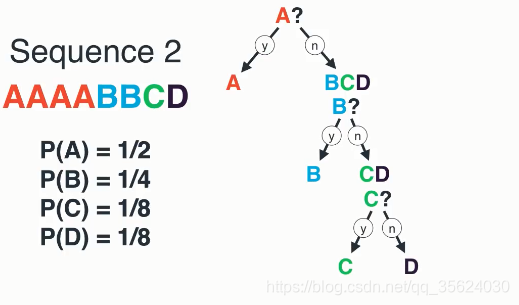
直觉上,信息量等于传输该信息所用的代价,这个也是通信中考虑最多的问题。比如说:赌马比赛里,有4匹马 ,获胜概率分别为
。
接下来,让我们将哪一匹马获胜视为一个随机变量 。假定我们需要用尽可能少的二元问题来确定随机变量
的取值。
例如:问题1:A获胜了吗?问题2:B获胜了吗?问题3:C获胜了吗?最后我们可以通过最多3个二元问题,来确定 的取值,即哪一匹马赢了比赛。
如果 ,那么需要问1次(问题1:是不是A?),概率为
;
如果 ,那么需要问2次(问题1:是不是A?问题2:是不是B?),概率为
;
如果 ,那么需要问3次(问题1,问题2,问题3),概率为
;
如果 ,那么同样需要问3次(问题1,问题2,问题3),概率为
;
那么很容易计算,在这种问法下,为确定 取值的二元问题数量为:
那么我们回到信息熵的定义,会发现通过之前的信息熵公式,神奇地得到了:
在二进制计算机中,一个比特为0或1,其实就代表了一个二元问题的回答。也就是说,在计算机中,我们给哪一匹马夺冠这个事件进行编码,所需要的平均码长为1.75个比特。
平均码长的定义为:
很显然,为了尽可能减少码长,我们要给发生概率 较大的事件,分配较短的码长
。这个问题深入讨论,可以得出霍夫曼编码的概念。
那么 四个实践,可以分别由
表示,那么很显然,我们要把最短的码
分配给发生概率最高的事件
,以此类推。而且得到的平均码长为1.75比特。如果我们硬要反其道而行之,给事件
分配最长的码
,那么平均码长就会变成2.625比特。