目录
一个学习工具
面向ChatGPT编程
bool类型(布尔类型)
内联函数inline
C宏定义
内联函数实现
函数重载
给函数重载加点bug
如何规范重载函数?
参数缺省
函数赋值顺序
默认值赋值顺序
给缺省函数加点bug
引用
命名空间namespace
可嵌套性
空间污染&另外命名
cin、cout、endl
new和delete
类
如何定义类
例子描述
类的构造函数
给成员初始化值
类的析构函数
类的拷贝构造函数
string类
this指针
对于C语言,只要掌握数据类型、逻辑语句、结构体、指针就可以完成很多东西了(一般很多人认为:C是面向过程编程)。但是C++不一样,它主要侧重类这一方面(C里面好像也没有“类”这一个东西),因此我觉得C++是C的扩展包。看这篇的人,默认你已经把C玩明白了。
一个学习工具
我现在用一台平板来写博客、工作学习的。平板性能一般不太好,那么那些IDE的就不想了。所以用一些网页版的在线工具用来学习。我现在用的是:
![]()
后面这一些都是基于这个东西来把代码敲出来验证的。
只要在页面选中你要测试的语言,然后手撸代码就可以验证了。
![]()
面向ChatGPT编程
总所周知,C++是一门面向对象的语言。那么这里需要有一个对象,在这里建议可选择面向ChatGPT编程,但是要看着来用(不建议偷懒)。
bool类型(布尔类型)
在C语言里面,没有true和false。如果你说有,是你没看到别人在其他地方把true宏定义成1,把false宏定义成0。如下面伪代码,如果a(它的数据类型被我定义成8bit的类型:uint8_t)为真,则打印出"true!"。当前的a,类型是short,如果我乐意,我把它定义成int都可以。但是有意义吗?
#include <stdio.h>#define true 1
#define false 0int main()
{short a = 1;if(a == true){printf("true!\r\n");}return 0;
}打印结果如下:
true!
下面是把a定义成不同类型的区别(分别为:uint8_t一共8bit,uint16_t一共16bit,别问为什么PC上面不行会报错,那个肯定会报错,单片机、arm板子里面的系统数据定义。这里不定义int或者short是因为页面限制大小,表格塞不进去我也没办法),并且赋值为1:
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
最终要表示的数就0和1两个,再划分更多的存储空间给这一个变量是毫无意义。因为只要1个bit就可以满足这个变量的使用要求了。你如果是搞嵌入式开发,这样浪费系统资源是要不允许的。但是,也没见过定义一个bit的都是最小定义成uint8_t的,所以在C语言里面一般把这种变量定义成uint8_t。
C++里面的布尔类型,和你所理解的一样就是两个值,1或者0,表示成是或非。既然是C++里面的,那么只要在代码里面把C++的库包含进来把它声明就可以使用了。bool类型定义出来,它就是长度为一个字节(uint8_t)的变量。
正常来说bool应该只有1和0两个数值,但是bool是由8个bit的,所以它可以放进去256的区间以内的数(-127~127)。但是!!!最神奇的出现了,系统只认为只要你这个bool变量里面不是0,无论里面是什么数,都会看成1。你在代码里面给bool类型赋值:13、111、4.67等,只会给警告,当不会给报错。
#include <iostream>
#include <stdio.h>int main()
{bool a;a = 111;printf("length:%d\r\n",sizeof(a));printf("a = %d\r\n",a);return 0;
}在里面只会打印出来:length:1, a=1,然后是编译不报错,但是报警告。
length:1
a = 1内联函数inline
一个用空间换取代码执行时间的函数,具体实现是在编译器里面完成的。首先,内联函数是一个函数。其次,这一个函数减少了代码运行时间。最后,这个函数增加了代码的运行空间开销。然后,内联函数需要在函数名字前面加上一个inline,下面是一个例子:
#include <iostream>
#include <stdio.h>#define ADD(x) ((x)+(x))inline int add1(int x)
{return x + x;
}int main()
{int a;int b;a = ADD(5);b = add1(5);printf("a = %d \r\n",a);printf("b = %d \r\n",b);return 0;
}得到结果:
a = 10
b = 10
C宏定义
在上面的例子中,ADD(x)是“x+x”的宏定义,那么ADD(5),就会在编译器里面生成一个“10”去替代代码中ADD(5)的地方。所以:
int a = ADD(5); // 相当于int a = 10;
这一个功能怎么说,有点鸡肋。(为什么要讲,帮助后面理解)
内联函数实现
终点来了!!!
在“ b = add1(5); ”里面,因为add1这个函数是内联函数,所以编译器会把它变成:
b = add1(5);
/*
编译器会把它改成这样:
b = x+x;
因为x=5,所以代码在执行的时候,又把它变成:
b = 5+5;
*/
如果add1这一个函数不是内联函数,那么,它会在“ b = add1(5); ”里面先调用add1(int x)这一个函数。而加上内联函数表示inline之后,经过编译器之后就会把add1(int x)替换成:“x+x”。这样做有什么好处呢?就是不用调用add1(int x)这一个函数了,这样不就少了几步汇编代码了吗?时间节省就是这么来的。下图是使用inline和不适用inline之后的(伪汇编代码):

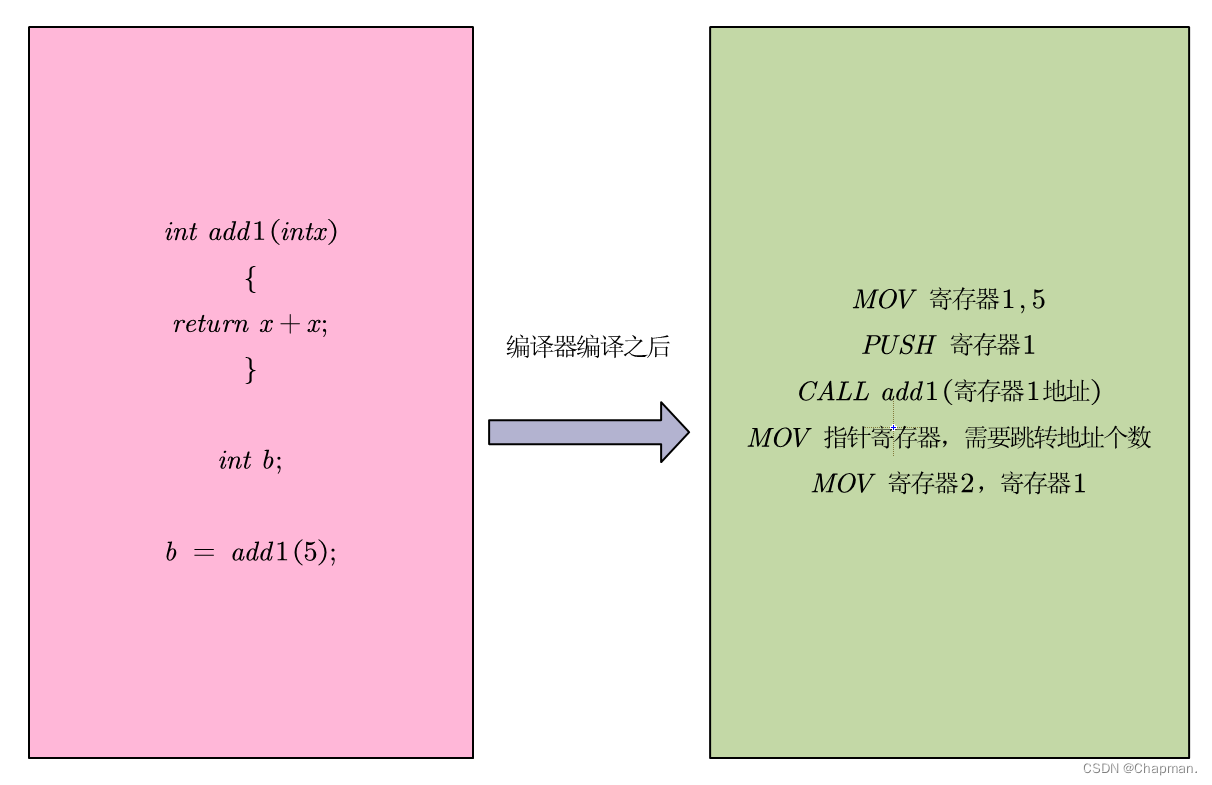
明显地,不使用inline的函数多了压栈和跳转的指令,这样增加了代码运行时间。但是,用inline之后,用函数体把调用处替换掉,这样就相当于拷贝了很多份代码(增加了空间开销,看第一张图,都多了好几行代码,然后只要这个函数被调用多次,就会拷贝很多份,用去更多的空间,如下图)。

上图所示,只要这个内联函数被使用次数多,生成的指令数量就会成正比增加。如果不适用内联函数,子函数的指令只生成一次,其他函数通过跳转指令实现多次执行。
函数重载
在C++里面,一个项目中函数名字可以被重复使用。如果有两个以上满足以下条件:
1、函数名相同。
2、参数不同(参数个数不相同,或者参数类型不冲突,返回值类型不参与本条件讨论)。
则满足了函数重载条件,实现了函数重载。例子如下:
#include <iostream>
#include <stdio.h>int func()
{printf("func1 run! \r\n");return 0;
}int func(int i)
{printf("func2 run! and i is %d\r\n",i);return 0;
}int main()
{func();func(10);return 0;
}结果为:
func1 run!
func2 run! and i is 10在例子里面,虽然有两个同名字的func函数,而且返回值数据类型都是一样的。不过一个输入参数为空,一个输入常数为int类型。然后在main里面执行代码,一个func函数不带参数,一个func函数带参数,所以编译器就可以区分出这个函数究竟是对应哪一个函,这个就是函数重载。
给函数重载加点bug
这种情况一般是函数的输入参数不明确导致的,例子如下:
#include <iostream>
#include <stdio.h>int func(int n)
{printf("func1 run! n is %d \r\n",n);return 0;
}float func(float i)
{printf("func2 run! and i is %0.1f \r\n",i);return 0;
}int main()
{func(12.31);return 0;
}在main里面,func输入参数为double类型。你猜编译会执行哪一个函数?
main.cpp: In function ‘int main()’:
main.cpp:18:12: error: call of overloaded ‘func(double)’ is ambiguous18 | func(12.31);| ^
main.cpp:4:5: note: candidate: ‘int func(int)’4 | int func(int n)| ^~~~
main.cpp:10:7: note: candidate: ‘float func(float)’10 | float func(float i)| ^~~~编译器决定不背锅!!这种情况下,因为你输入的参数取整满足int,约去一位得到float,类型不明确,编译器会直接报错,所以不要写这种东西出来!!!要么你就把12.31强制转换成int或者float。
#include <iostream>
#include <stdio.h>int func(int n)
{printf("func1 run! n is %d \r\n",n);return 0;
}float func(float i)
{printf("func2 run! and i is %0.1f \r\n",i);return 0;
}int main()
{func((int)12.31);return 0;
}如何规范重载函数?
首先,你要保证你输入的参数类型不能模糊不清,就好像上一部分所讲的情况。其次,你要保证你的输入参数类型,不能起冲突。编译器是不会帮你解决问题的,只会告诉你有问题。例如下面:
#include <iostream>
#include <stdio.h>int func(int n)
{printf("func1 run! n is %d \r\n",n);return 0;
}float func(int i)
{printf("func2 run! and i is %d \r\n",i);return 0;
}int main()
{func(2);return 0;
}你猜编译器给你跑哪个?
main.cpp:10:7: error: ambiguating new declaration of ‘float func(int)’10 | float func(int i)| ^~~~
main.cpp:4:5: note: old declaration ‘int func(int)’4 | int func(int n)| ^~~~避免上述这一些情况最好的解决办法是什么?你当你没看过这一部分,你不知道,你没学就可以了。总之你写什么代码都好,函数名字永远最好不能重复!!!
参数缺省
在C++里面,你写的一个函数里面的参数,提前赋上一个默认值。如果你在后面调用的话,可以不输入参数,那么这个函数就会默认使用默认值。如下面例子:
#include <iostream>
#include <stdio.h>void func(int n,float a = 0)
{printf("n = %d \r\n",n);printf("a = %0.1f \r\n",a);
}int main()
{func(2); return 0;
}结果为:
n = 2
a = 0.0 函数赋值顺序
在C和C++里面,函数的参数赋值顺序是从左到右的。就好像下图,2赋值给你n,1.3赋值给a。不会是1.3赋值给n,2赋值给a的。这个请注意!!!!

默认值赋值顺序
我们知道函数的赋值顺序是按照输入参数从左到右顺序赋值的。那么缺省默认值就需要反着来赋值,也就是从右到左,否者就会出现下面的bug。例子如下:
#include <iostream>
#include <stdio.h>void func(int n = 0,float a)
{printf("n = %d \r\n",n);printf("a = %0.1f \r\n",a);
}int main()
{func(1.3); return 0;
}结果是:
main.cpp:4:27: error: default argument missing for parameter 2 of ‘void func(int, float)’4 | void func(int n = 0,float a)| ~~~~~~^
main.cpp:4:15: note: ...following parameter 1 which has a default argument4 | void func(int n = 0,float a)| ~~~~^~~~~上面我给第一个参数n赋了一个默认值0,没有给a赋默认值。然后我把n的参数给缺省了,然后编译器直接报错。要么你就两个都赋默认值,因为编译器是不允许你这么干的。
#include <iostream>
#include <stdio.h>void func(int n = 0,float a = 0.2)
{printf("n = %d \r\n",n);printf("a = %0.1f \r\n",a);
}int main()
{func(); return 0;
}结果是:
n = 0
a = 0.2 给缺省函数加点bug
前面学了重载函数,如果我是这么玩的话:
#include <iostream>
#include <stdio.h>void func(int n = 0,float a = 0.2)
{printf("n = %d \r\n",n);printf("a = %0.1f \r\n",a);
}
int func()
{printf("func run \r\n",n);return 0;
}int main()
{func(); return 0;
}你猜编译器给你跑哪个函数?
main.cpp: In function ‘int func()’:
main.cpp:11:25: error: ‘n’ was not declared in this scope11 | printf("func run \r\n",n);| ^
main.cpp: In function ‘int main()’:
main.cpp:17:7: error: call of overloaded ‘func()’ is ambiguous17 | func();| ^
main.cpp:4:6: note: candidate: ‘void func(int, float)’4 | void func(int n = 0,float a = 0.2)| ^~~~
main.cpp:9:5: note: candidate: ‘int func()’9 | int func()| ^~~~以后别写这些东西了!
还有一点需要注意!在文件开头声明但是没定义函数(函数的参数里面已经赋了默认值),后面在定义函数大的时候就不用假如默认值了,否者会报错。例子如下:
#include <iostream>
#include <stdio.h>void func(int n = 0,float a = 0.2);int main()
{func(); return 0;
}void func(int n = 0,float a = 0.2)
{printf("n = %d \r\n",n);printf("a = %0.1f \r\n",a);
}结果是:
main.cpp:12:6: error: default argument given for parameter 1 of ‘void func(int, float)’ [-fpermissive]12 | void func(int n = 0,float a = 0.2)| ^~~~
main.cpp:4:6: note: previous specification in ‘void func(int, float)’ here4 | void func(int n = 0,float a = 0.2);| ^~~~
main.cpp:12:6: error: default argument given for parameter 2 of ‘void func(int, float)’ [-fpermissive]12 | void func(int n = 0,float a = 0.2)| ^~~~
main.cpp:4:6: note: previous specification in ‘void func(int, float)’ here4 | void func(int n = 0,float a = 0.2);| ^~~~
那么,应该改成这样:
#include <iostream>
#include <stdio.h>void func(int n = 0,float a = 0.2);int main()
{func(); return 0;
}void func(int n,float a)
{printf("n = %d \r\n",n);printf("a = %0.1f \r\n",a);
}结果是这样:
n = 0
a = 0.2
引用
在C里面,有一个叫解引用的东西,例如:“ p = &i; ”,意思为,把i变量的地址放到p里面。把这个“ p = &i; ”放到以下例子里面看:
int i = 1; //定义一个int类型的i并且赋值1
int *p; //定义一个int指针类型p
int Result; //定义一个int类型Result
p = &i; //把i的解引用值(i的地址)赋值给p
Result = *p; //把指针p所指的空间里面数据赋值给Result既然C里面有“ int *p ”这样的东西,作为C的拓展包C++怎么能没有“ int &p ”的东西呢?这个还真有,就是这里说的引用,下面是个例子:
#include <iostream>
#include <stdio.h>int main()
{int i = 1;int &ii = i;printf("i = %d \r\n",i);ii = 10;printf("i = %d \r\n",i);return 0;
}结果是:
i = 1
i = 10 在代码里面,“ int &ii = i; ”表示为,用ii给i取了个别名。那么,实际上i和ii都会指向同一块存储空间。所以我们在修改i的变量时,ii的变量也会跟着变,在修改ii的变量时,i也会跟政变,而且i和ii的值一直相同。这个,就是引用。
命名空间namespace
命名空间有点像C里面的结构体,是用来组织、重复使用代码的编译单元,可以通过命名空间解决函数名字重复的问题。另外,可以给命名空间取一个别名。看下面一个例子:
#include <iostream>
#include <stdio.h>namespace SPACE1
{int num = 10;namespace SPACE2{int i = 5;}void func1();void func2(){printf("func2 run \r\n");}namespace SPACE2{int i2 = 30;} namespace S2 = SPACE2;
}namespace SPACE1
{int num2 = 20;
}namespace S1 = SPACE1;void SPACE1::func1()
{printf("func1 run \r\n");
}int main()
{int num = 1;printf("num = %d \r\n",num);printf("num = %d \r\n",SPACE1::num);printf("num = %d \r\n",S1::num2);printf("i = %d \r\n",SPACE1::S2::i);printf("i = %d \r\n",SPACE1::SPACE2::i2);SPACE1::func1();SPACE1::func2(); return 0;
}结果是:
num = 1
num = 10
num = 20
i = 5
i = 30
func1 run
func2 run 首先看命名空间:namespace SPACE1,在这个空间里面有一个变量num,和在mian里面的num虽然同名,但是由于SPACE1是被划分出来的区域,和main里面的区域不一样的。所以就算两个变量重名,也不会相互影响。而在printf函数里面,调用SPACE1里面的num也需要添加标识为"SPACE1::num",这样彻底区分出两个num的不同。
其次可以看到,在SPACE1里面声明了函数void func1()之后,我在SPACE1外边定义void func1()时候,需要改成void SPACE1::func1(),以便编译器区分,这是在空间里面声明,在空间外定义。
到这里,应该差不多明白名字空间是什么意思。还需要了解的是,“::”这一个东西相当于电脑上打开文件夹显示位置的“/”,例如:
SPACE1::func1(); //标识为执行SPACE1里面的func1()
可嵌套性
在名字空间里面,可以嵌套另外一个名字空间。例如下面的,在SPACE1里面嵌套一个SPACE2的名字空间。
namespace SPACE1
{namespace SPACE2{int i = 5;}
}如果在其他函数调用SPACE2里面的i时候,则需要告诉编译器,i是在SPACE1里面的SPACE2里面的i。
printf("i = %d \r\n",SPACE1::S2::i);空间污染&另外命名
空间污染和另外命名都有一个前提——必须在同一空间下进行。例如前面的代码所示,在SPACE1空间里面,有两个SPACE2的空间同时存在——这样就造成了空间污染。另外,在这一个SPACE1的空间里面,对SPACE2起了另外的一个别名S2。
namespace SPACE1
{int num = 10;namespace SPACE2{int i = 5;}void func1();void func2(){printf("func2 run \r\n");}namespace SPACE2{int i2 = 30;} namespace S2 = SPACE2;
}在编译的时候,产生空间污染的命名空间,无论有多少个,都会把所有空间里面的内容归一到一个里面,也就是看成是同一块空间。而另外起名字,也是让编译器知道,你调用这个空间的别名实际也是调用这一个空间。
cin、cout、endl
在C++的库里面有一个头文件:#include <iostream>。里面有一对输入和输出:cin和cout,可以代替printf和scanf使用,而且用法更简单。例子如下:
#include <iostream>
using namespace std;/*
或者这样定义
using std::cin;
using std::cout;
using std::endl;
*/int main()
{int num;cin>>num;cout << "Hello World"<<endl<<num<<endl;return 0;
}输出结果:
Hello World
0因为cout和cin是在头文件iostream里面的库里面的一个叫“std”的命名空间里面,需要声明使用里面才可以在当前项目调用出来(使用 using namespace std;)。其实可以看成cin相当于scanf,cout相当于printf,endl相当于换行输出。当需要输入参数时候,就是用左移运算符,将数据送入cin这个容器里面。但需要打印出数据的时候,将数据送入cout这一个容器里面。
new和delete
这是两个关键字,字面意思:新的、删除,那就是一个新建,一个删除。但是新建什么,删除什么呢?具体可以参考下面的表格:
| 语言 | 新建空间 | 释放空间 |
| C | malloc() | free() |
| C++ | new | delete |
可以看出关键new和delete的用法,就是用于申请和释放空间的。如果了解过C语言的数据结构,可能会明白这个申请内存和释放内存是什么意思。可以看一下这个:C链表笔记。有下面一个例子:
#include <iostream>
#include <stdio.h>
using namespace std;int main()
{int i;/*申请单个int类型空间,但不初始化,并且把申请到的空间地址赋值给int类型指针p。*/int *p1 = new int;cout << "back address(p1) = "<< p1 <<endl;cout << "put a data to address(p1) 0"<<endl; *p1 = 0;cout << "back data in address(p1) = "<< *p1 <<endl; cout <<endl;/*申请单个int类型空间,初始化为11,并且把申请到的空间地址赋值给int类型指针p。*/int *p2 = new int(11);cout << "back address(p2) = "<< p2 <<endl; cout << "back data in address(p2) = "<< *p2 <<endl; cout <<endl;/*批量申请连续的int类型空间,并且把申请到的空间地址赋值给int类型数组指针p。*/int *p3 = new int[5];//申请了10个连续的int类型空间//循环给空间赋值:0~9for(i=0;i<5;i++){p3[i]=i;cout << "p3["<< i << "]=" << p3[i] <<endl; }cout <<endl;for(i=0;i<5;i++){cout << "address p3["<< i << "]=" << &p3[i] <<endl; } delete p1;delete p2;delete[] p3;cout <<endl;cout << "&p1 =" << &p1 <<endl;cout << "&p2 =" << &p2 <<endl;cout <<endl;cout << "p3[0] =" << p3[0] <<endl;cout << "p3[1] =" << p3[1] <<endl;cout << "p3[2] =" << p3[2] <<endl;cout << "p3[3] =" << p3[3] <<endl;cout << "p3[4] =" << p3[4] <<endl;cout <<endl; cout << "&p3[0] =" << &p3[0] <<endl;cout << "&p3[1] =" << &p3[1] <<endl;cout << "&p3[2] =" << &p3[2] <<endl;cout << "&p3[3] =" << &p3[3] <<endl;cout << "&p3[4] =" << &p3[4] <<endl; return 0;
}结果是:
back address(p1) = 0x1defe70
put a data to address(p1) 0
back data in address(p1) = 0back address(p2) = 0x1df0ea0
back data in address(p2) = 11p3[0]=0
p3[1]=1
p3[2]=2
p3[3]=3
p3[4]=4address p3[0]=0x1df0ec0
address p3[1]=0x1df0ec4
address p3[2]=0x1df0ec8
address p3[3]=0x1df0ecc
address p3[4]=0x1df0ed0&p1 =0x7ffccdddf6f8
&p2 =0x7ffccdddf6f0p3[0] =31395488
p3[1] =0
p3[2] =31318032
p3[3] =0
p3[4] =4&p3[0] =0x1df0ec0
&p3[1] =0x1df0ec4
&p3[2] =0x1df0ec8
&p3[3] =0x1df0ecc
&p3[4] =0x1df0ed0可以看到p1和p2两个空间在被释放后,他们原来的指针就不知道指向哪里(释放之前p1是: 0x1defe70,p2是:0x1df0ea0)。但是连续空间p3被释放后,里面数据几乎被串改了,但是指向地址没有改变。
类
在C++里面,类是用户自己定义的一种数据类型,关键字:class。类和C里面的结构体很相似,可以参考C结构体。类和结构体的最明显区别是,类里面可以有函数,但是结构体里面不可以有函数。类是一个属性(参数)和行为(可执行函数)的集合。
如何定义类
一个类里面,需要有类的名字,公有成员(public),私有成员(private),被保护成员(protected)。结构简图如下:
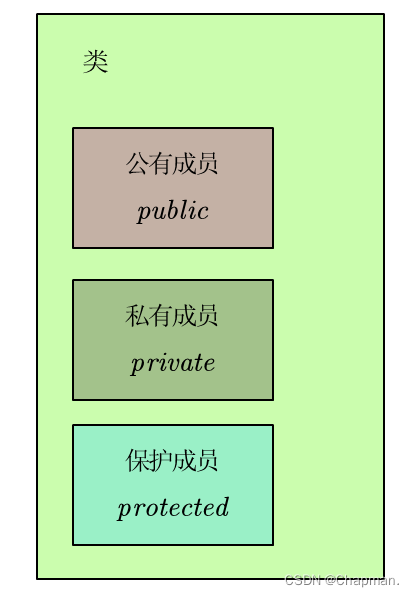
在一个类里面,如果没有被定义的成员,默认为公有成员。在类里面,成员可以是数据变量、也可以是函数。其中,公有成员可以被项目中所有函数调用或者操作,但是私有成员只能被同一个类里面的函数调用或者操作,保护成员暂时不讲。
例子描述
#include <iostream>
using namespace std;class object
{public:int name = 0;void input_yourage(int i){age = i;}void ShowYourinformation(){cout << "I am " << name << "."<<endl;printf_age();}private:int age = 1;void printf_age(){cout << "I am" << age << "years old."<<endl;}protected:};int main()
{object obj1;obj1.name = 2;obj1.input_yourage(10);obj1.ShowYourinformation();return 0;
}在main里面,和结构体一样,要先对使用的类先进行定义后使用。在obj1这一个类里面,对于公有成员:变量name,函数input_yourage(int i),函数ShowYourinformation(),是可以被类以及类外面的函数所调用。但是私有成员:变量age,函数printf_age()需要通过将同一个类里面的公有函数(或者变量)做为媒介,实现类外面对这个类的操作。
类的构造函数
在创建一个类之后,每次定义一个类,里面都会生成一个叫构造函数的函数(属于类里面的公有成员,不要放到私有和保护里面)。构造函数可以在类被创建的时候,用于初始化这一个类里面的成员。此外,构造函数没有返回值(所以也没有返回类型),并且构造函数名字和类的名字相同,构造函数也可以重载。
#include <iostream>
using namespace std;class object
{public:object(){cout << "object set " <<endl; }int name = 0;void input_yourage(int i){age = i;}void ShowYourinformation(){cout << "I am " << name << "."<<endl;printf_age();}private:int age = 1;void printf_age(){cout << "I am" << age << "years old."<<endl;}protected:};int main()
{object obj1;
/*obj1.name = 2;obj1.input_yourage(10);obj1.ShowYourinformation();
*/ return 0;
}输出结果:
object set 上面的代码里面,我只是把objecct这一个类定义了一个,构造函数object()就自己执行了。
给成员初始化值
假如,类的成员里面有const类型数值,假如在同一种类不同定义下要求这一个参数不同,则可以在构造函数里面给对应的const类型数值赋予初值。当然,在构造函数里面也可以使用缺省函数。
#include <iostream>
using namespace std;class object
{public:object(int i):name(i) //name是const类型,创建类的时候在这里向里面赋予初值{cout << "object set " <<endl; }void input_yourage(int i){age = i;}void ShowYourinformation(){cout << "I am " << name << "."<<endl;printf_age();}private:const int name = 0;int age = 1;void printf_age(){cout << "I am" << age << "years old."<<endl;}protected:};int main()
{object obj1(0);obj1.input_yourage(10);obj1.ShowYourinformation();return 0;
}输出结果是:
object set
I am 0.
I am10years old.类的析构函数
首先按照名字知道,析构函数是一个函数,它和构造函数很类似,是一对的存在(就是有构造就会有析构)。它和析构函数的区别是,构造函数是初始化这一个类,而析构函数则是在这个类被使用后对它进行释放消去(类被创建时所占用空间)。析构函数名和类命一样,只不过在前面加上一个“~”。如下例子,析构函数为:“~object()”,注意,析构函数没有返回值,所以没有返回类型,没有输入常数,但是有参数表,为空。
#include <iostream>
using namespace std;class object
{public:object(int i):name(i) //name是const类型,创建类的时候在这里向里面赋予初值{cout << "object set " <<endl; }~object() //析构,释放类{cout << "object close " <<endl; }void input_yourage(int i){age = i;}void ShowYourinformation(){cout << "I am " << name << "."<<endl;printf_age();}private:const int name = 0;int age = 1;void printf_age(){cout << "I am" << age << "years old."<<endl;}protected:};int main()
{/*创建类*/object obj1(0);/*操作类*/obj1.input_yourage(10);obj1.ShowYourinformation();return 0;
}输出结果:
object set
I am 0.
I am10years old.
object close 类的拷贝构造函数
类的构造函数属于类里面的公有成员,这一个函数用于拷贝一个已经建立了的类。同时,可以使用这一个拷贝构造函数对拷贝出来的类赋予初值。组成结构简图如下:
| 类的名字 | ( | const 类命 &obj | int n | ) |
拷贝构造函数第一个参数必须是当前类对象的引用。以下是一个例子:
#include <iostream>
#include <string>
using namespace std;class object
{public:string name;int num1;float num2;object();object(char *name1,int n1,float n2);~object();object(object &obj);object(object &obj,int v1,float v2);private:protected:};object::object()
{name = "默认名字";num1 = 0;num2 = 1;cout<<"无参构造"<<" 名字 :"<<" 名字 :"<< name << " " << num1 << " " << num2<<endl;
}object::object(char *name1,int n1,float n2)
{name = name1;num1 = n1;num2 = n2;cout<<"带参构造"<<" 名字 :"<<" 名字 :"<< name << " " << num1 << " " << num2<<endl;}object::~object()
{cout<<"析构 :"<< name << " " << num1 << " " << num2<<endl;
}object::object(object &obj)
{name = obj.name;num1 = obj.num1;num2 = obj.num2;cout<<"拷贝构造(原版) "<<" 名字 :"<< name << " " << num1 << " " << num2<<endl;}object::object(object &obj,int v1,float v2)
{name = obj.name;num1 = v1;num2 = v2;cout<<"拷贝构造(改参) "<<" 名字 :"<< name << " " << num1 << " " << num2<<endl;
}int main()
{object p0;object p1("b",1,1);object p2 = p0;object p3(p0);object p4(p0,3,4);/*已经释放,所以无析构*/object *a = new object;delete a;a = NULL;return 0;
}结果:
无参构造 名字 : 名字 :默认名字 0 1
带参构造 名字 : 名字 :b 1 1
拷贝构造(原版) 名字 :默认名字 0 1
拷贝构造(原版) 名字 :默认名字 0 1
拷贝构造(改参) 名字 :默认名字 3 4
无参构造 名字 : 名字 :默认名字 0 1
析构 :默认名字 0 1
析构 :默认名字 3 4
析构 :默认名字 0 1
析构 :默认名字 0 1
析构 :b 1 1
析构 :默认名字 0 1拷贝构造函数的功能如上,有以下一些需要注意的:但对象使用完之后,先构造的对象后析构。另外,如果使用new创建出来的对象空间,使用完之后,需要把指针指向NULL。(原因如下:一般情况下,用new建立的一块空间,其指针指向此区域。此时,系统是不允许其他指针指向这个区域的。但是,但使用了delete之后,就允许其他指针指向此区域。但是原来的指针还是指向这一个区域的,所以需要给此指针指向NULL,这样才能算完整的释放此区域。当然,换成C里面的free和malloc也是一样的。)
string类
这个和前面的cin、cout、endl类似,需要额外包含std。例子如下:
#include <iostream>
#include <string>
using namespace std;int main()
{int l;bool a;char ch;string str; //定义一个string类的strstr = "123aaa"; //将 123aaa 放到str里面ch = str.at(2); //将str.at(2)是将str里面的第三位字符放到ch里面cout<<"ch is "<< ch <<" ."<<endl; l = str.length(); //将str的长度放到l里面cout<<"Length is "<<l<<" ."<<endl;str.clear(); //清理stra = str.empty(); //str是否为空cout<<"clear? "<<a<<" ."<<endl;return 0;
}先定义一个string类的str,然后把“123aaa”放到str里面。
str.at()字符读取函数
用str.at(2)读取str里面的第三位字符,放到ch里面。
str.length()长度读取函数
用str.length()读取str传唱度,放到l里面。
str.clear()字符清理函数
使用str.clear(),清理str里面的内容。
str.empty()字符空判断函数
使用str.empty()返回一个bool类型变量。
this指针
this指针是系统自己生成的,并且是隐藏的。 在一个对象里面,this并不是对象里面的一个成员,但是作用在类里面。类的普通函数访问类的普通成员时候,this总是指向调用者对象。下面是一个例子:
#include <iostream>
#include <string>
using namespace std;class object
{public: void input_num(int num){this->num = num;}int return_num(){return num;}private:int num;protected:};int main()
{object obj;obj.input_num(10);cout << "num = " << obj.return_num() <<endl;return 0;
}结果是:
num = 10在上面的例子里面,在类object里面的函数input_num(int num),它的参数和私有成员num的名字重名,用这个this指针就可以区分出两个num从而不会报错。这一个this并不是object的成员,但是可以作用在object类里面的。
其实在void input_num(int num)里面,隐藏了一个this参数:void input_num(object *this,int num)。这一个this参数指向的是object这一个类。所以在上面代码里面:this - >num指向object里面的num,而不是函数里面num参数。