作者 | 张德兵,格灵深瞳首席科学家&算法部负责人
来源 | 转载自知乎张德兵
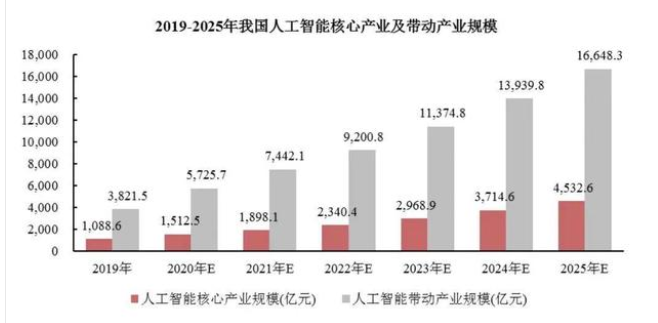
最近两个月,格灵深瞳首席科学家&算法部负责人张德兵与算法团队参加了全球人脸识别算法测试(FRVT、Face Recognition Vendor Test)。虽然是第一次参加此比赛,格灵深瞳还是取得了不错的成绩,排名世界前五,在国内领先,且具体的成绩接近世界最好水平(见表一)。
赛后,张德兵回忆了竞赛的准备过程并记录下来,希望激励团队在不久的将来能够更上一层楼,以下为参赛记录:
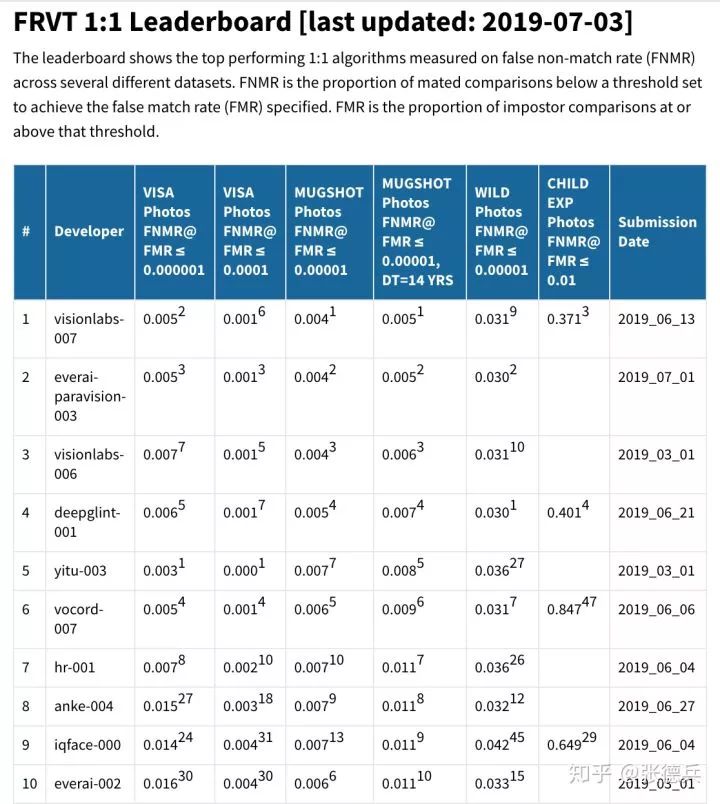
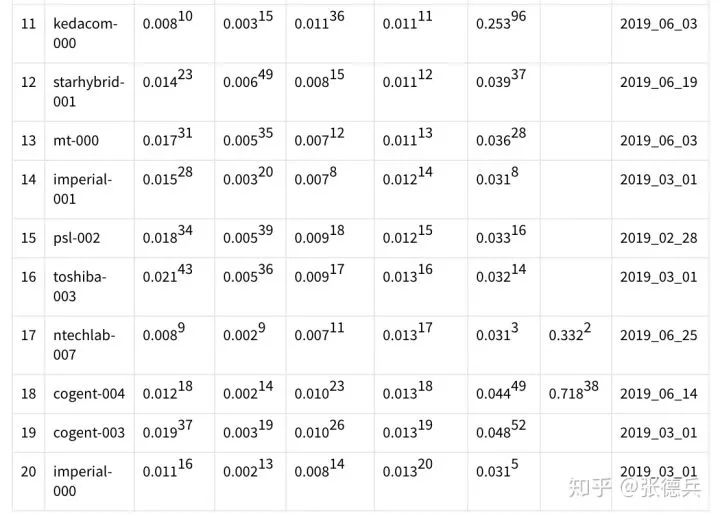
表一:FRVT 1:1 最新排名的前20名(基于第四列的跨14岁嫌疑人识别结果排序)
先介绍一下 FRVT。FRVT 由美国国家标准与技术研究院主办,号称是当今全球规模最大、标准最严、竞争最激烈、最权威的人脸识别算法竞赛,到目前为止,全球已经有近百家公司和研究机构参与了此项测试,包括VisionLabs(俄罗斯)、Ever AI(美国)、Vocord(俄罗斯)、 依图、商汤、旷视、海康、大华、腾讯等等。关于这个比赛,网上也能找到很多介绍,我大概总结一下我觉得比较重要的几个点:
独特的测试模式。在FRVT评测中,测试集是完全不公开的,只有简略的几段话描述。这意味着FRVT用的不是传统那种通过在本地跑一遍测试集,然后提交结果的评测方式(在传统评测中,大家往往不太考虑模型的计算效率,为了获得更好的成绩,经常会通过大幅提升模型容量的方法来提高效果,而且往往还会采用更加耗时的多模型甚至多尺度预测的融合策略。
所以,很多比赛中排名靠前的算法,它们的实用价值有可能并不高)。但在FRVT的测试中,官方要求每个厂商或者研究机构都要提供完整的预测代码,并且由主办方在同一个平台上来运行所有提交,得到最终各个测试集上的结果。而且,该测试对于算法的运行时间也有着很严格的限制,所有提交都只能使用不超过CPU单线程1秒的计算资源来处理一张图片从人脸检测、人脸对齐到人脸特征提取和识别的所有功能。这些特点使得FRVT非常客观且直接面向实际应用。
最严格的提交频率限制。为了避免测试厂商通过反复提交来过拟合测试集,2019年6月以前的规定是,每个厂商每次只能提交一个算法版本,且两次提交之间相隔至少要3个月,其中第一次提交的时候为了避免大家成绩太差,官方允许同时提交两个算法版本。但在2019年6月以后,规则变得更加严格了一些,每个厂商的两次提交间隔变成了4个月,而且不管是不是第一次提交,每次都只能提交一个算法版本。这也就是说我们只有一次提交机会,风险还是挺大的。
丰富多样的测试场景。FRVT主要覆盖了四种类型的测试场景照片,分别是签证照片(Visa),嫌疑人照片(Mugshot),自然场景照片(Wild)和儿童照片(Child),下面简单介绍一下:
签证照片(如图一(a))。签证照片是非常清晰、正面、无遮挡的一种受控测试场景,成像质量很高,且覆盖了多达上百个国家的人脸数据。
嫌疑人照片(如图1(b))。嫌疑人照片也是比较高清的,跟签证照片相比,嫌疑人两张照片间的年龄跨度一般会更大,有很多都超过了十年的年龄间隔。这个测试又分为两个场景,一个是混合的测试,一个是基于专门挑出来年龄跨度达14年以上的照片进行的更有挑战的评测。
自然场景照片(如图1(c))。自然场景的照片是在非限制场景下采集的,各种光照,角度,遮挡,模糊,低分辨率的情况都可能会出现,是难度非常大的一种场景,某种意义上也更接近安防场景的实际应用。
儿童照片。儿童照片也是在非限制场景下采集的,因为年龄分布跟大家的训练集可能差别比较大,所以也是非常难的一个任务。很多厂商提供的算法,完全无法支持这个场景,以至于得分都没有显示(成绩差于某个数值就不会显示了)。

图一,签证照片,嫌疑人照片和自然场景的拍摄照片
FRVT对以上每种场景都会进行单独的评测,然后给出一个最终的排名表。在早期的排名表中,是以签证照片识别结果的优劣对大家进行排名的,最近几次的评测则改成了以跨年龄嫌疑人照片的识别结果优劣进行排名。我个人认为,所有这些场景都是挺重要的,在实际应用中都会用到,都不能有短板。且随着人脸识别技术的不断提升,非配合式的自然场景识别肯定是未来需求的大趋势,只有真正做好非配合且无场景限制下的识别才能支持解锁更多的、更广泛的、更大规模的各行各业应用。
比赛前:
一直以来,我们对于刷LFW或者MegaFace之类数据集的就没有太大的兴趣,因为大家都知道,这里面的各种排名其实也都有不公平或者不合理的地方。FRVT则非常专业(看看它上百页的测试报告也能感觉到这一点)。但是对于FRVT竞赛,我个人一直下意识的认为Visa签证照片涉及到了上百个国家的人脸照片,如果没有类似的数据做训练,结果应该很难能做到非常好。而收集相关数据又挑战巨大。
首先想收集覆盖这么多国家的人脸数据已经是非常困难了;其次, 就算收集到一些数据,跟签证的场景也会差别很大;且经过一些尝试后发现,在现阶段,想大量采集签证场景的真实数据几乎是不可能的。另外,当看到以往成绩较好的一些厂商的结果后,在团队自己内部制作的中国人测试集上对比估算了一下,也发现我们在低误识率下的召回率还是明显要差一些,所以就一直没有尝试。
直到4月份的某一天,当我看到ArcFace在NIST上表现是超出预期的好(github.com/deepinsight/),我才突然意识到,FRVT对于我们的难度很可能被高估了。有了ArcFace这个baseline,感觉就踏实了很多。我个人猜测排名靠前的厂商也不一定真有多少能覆盖到众多国家的签证数据,大家可能更多的还是在用一些开源数据和自己的业务数据来训练的。
同时我们也注意到了大部分厂商其实还并不能在每个任务上都得到很好的结果,有明显的domain差异带来的识别率下降,所以也能多少猜出来一些可能用了什么样的数据之类的信息。
比赛中:
既然如此,那必须要试一下了。
首先仿照ArcFace在开源数据上做一些baseline的模型出来作为参照。这里要强调一下,丰富的测试集对于衡量模型效果是非常必要的。在平时的产品研发中,我们已经积累了大量的多场景测试集,可以测试到非常低的误识别率(我们也发布过一个人脸测试平台,支持接近万亿分之一低误识率且非常高效率的在线模型评测,trillionpairs.deepglint.com,该测试平台也支持了ICCV 2019 的人脸识别 workshop 竞赛 insightface-challenge.com)
接下来就是把长期以来产品研发中积累下来的模型结构设计经验,分布式模型训练经验,数据集融合经验和CPU平台上的高效inference经验快速移植到官方指定的测试环境下。
关于模型结构设计和压缩,在产品的持续研发和迭代中,我们已经积累了比较多的经验,可以很快的设计一批各种各样的CPU友好的模型结构。
关于分布式模型训练,可以参考我们之前的一个分布式人脸识别算法介绍(zhuanlan.zhihu.com/p/35),可以获得几乎线性的加速。
关于数据集融合,在很多场景我们可能都会发现,直接融合两个不同源的数据可能会有一些问题。我们也曾经思考了很久,最终找到了一种可以有效利率各个数据源的融合策略,使得在多个不同的产品场景中都能表现得很好。所以要做的就是把手头上所有的跟NIST比赛数据类型有关的数据都巧妙的融合起来,但是由于时间有限,全量数据做实验是不现实的,这次比赛还是只能用一部分。
关于高效的CPU inference。这里有个小插曲。我们曾经做过一个业余项目,基于强化学习的五子棋AI训练。我们仿照AlphaZero的思路,并且做了针对性的改进,使得基于几十张卡就可训练到强职业的水平,最后这个项目也参加了2019年的五子棋AI世界锦标赛(Gomocup 2019),并且拿了平衡开局的无禁手世界第四名(StarDust),是所有基于深度学习算法中最好的(gomocup.org/results/gom)。为什么只有第四呢?深度学习算法潜力巨大,如果有充分的训练资源,再加上GPU支持的走棋策略当然可以完胜传统算法,但是这个比赛为了公平性的考虑,也有一个限制就是必须要提供CPU单线程下的可执行程序,所以在这么有限的计算资源条件下(而且评测的19x19路的大棋盘),我们觉得能到第四名已经还不错了。虽然没有颠覆所有传统算法,但这次的业余项目,也使得我们对CPU单线程下的inference优化有了比较好的积累。
在这个过程中,我们根据以往的经验,在这个特定比赛任务上,不断的试验各种模型优化策略、数据集融合策略,也包括调整和尝试各种模型结构、超参数、迭代次数、损失函数等等。因为要试验验证的细节非常多,我们先以很高优先级,走通了基于fp16的训练方式,使得训练速度提升了几乎一倍。
这段时间在印象里是过得飞快,但大家都非常兴奋,因为高效率的试验使得我们几乎每隔几天就能看到新的提高。但时间总是很有限,在我们迭代了几十个模型后,就已经六月初,临近比赛结束了。虽然感觉还有很多的想法没有试验完,但是也没办法,差不多就打算选个最好的模型提交了。当时根据我们的自测,结果还凑合,按照ArcFace之前成绩的估算,应该大概率能进入前五名(按FRVT 4月份的成绩)。
之后恰好是CVPR 2019的会议时间(6.15-6.21),FRVT相关的一切基本准备就绪后(只差最后的确认提交),我就带着几个瞳学去了Long Beach,去了解最新的学术动态去了。没想到还没等到开会,就收到了小伙伴新的消息,在半精度模型训练的过程中,发现了一处隐藏的bug,在复杂Loss和数据源的情况下会造成模型训练的不稳定。于是,中美两地开始不分白天黑夜的紧急修改(倒也省得倒时差了),一阵忙活之后,又看到了非常显著的提升,那种感觉是非常不错的。
之后就按照官方要求进行了最终的邮件提交,之后就一直没有什么信息了,直到7.3号,比赛结果出来,看到三项的结果都超过了依图。如果按照4月份的排名,这个成绩基本上能跟当时的VisionLabs并列第一。不过因为VisionLabs也有了小幅提升,然后又冒出来一个成绩还挺不错的Ever AI,所以我们在7.3号最新的榜单里是世界第三名(按公司来看) 或者世界第四名(按模型提交数来看)。只看国内的话,是顺利的暂列第一了(大部分任务都超过了友商,当然在签证照片上还逊色依图,在儿童照片上比旷世差一点)。
我觉得我们有一个比较大的优势是在所有任务上表现都相对比较一致,不像大部分友商的提交,会在某些场景表现得比较差,似乎是出现了一些domain的偏向性,这在实际应用中,有可能会遇到一些问题。仔细看一下结果我们会发现,在这方面Ever AI其实做得更加优秀,非常值得我们学习。
最后再做一个总结吧,简单分三个方面:
一:感谢
感谢ArcFace的Baseline, 以及在我们比赛中提供的一些支持。
感谢靠谱的团队成员,人数不多,在产品压力下,还敢做挑战世界的事情,而且还能做得不错。
感谢友商,给我们提供了阶段性的追赶目标。
二:不足
训练数据仍没有充分使用起来
在新型网络结构的探索、模型结构搜索(NAS)和模型inference优化(如定点化, 模型压缩等)等方面还有一定的空间
在人脸识别的问题建模、损失函数的进一步优化、泛化性能的保证、优化策略的影响等方面仍然缺乏足够的清晰理解
三:未来
人脸识别在真实场景的应用效果,其实远不是一个比赛能够完全衡量的。人脸识别发展到现在,也包括基于人脸识别而衍生出来的行人ReID等以图搜图技术,其实离真正解决工业界大规模的应用都还有不小的距离,万路、十万路、乃至百万路的刚需,仍在前面等着我们去不断优化和探索。
当然,因为涉及到公司内部的很多研发细节,这里无法更加详细的介绍具体技术,但我们非常期待对相关技术有浓厚兴趣、有独特想法、有很强执行力的朋友加入我们,你将有机会了解到所有的技术细节,并与我们一起进一步推进相关研究,做更多有意义的事情。另外,本文的很多内容都是我个人的一些理解和分析,应邀匆忙整理了一下,有些疏漏或者错误也是难免的,如有发现,欢迎指出。
格灵深瞳算法团队:格灵深瞳核心团队,负责公司所有产品线的各类不同算法的支持(安防、零售、智能相机、机器人等等,检测、跟踪、识别、检索、商品推荐、数据挖掘、定位和导航等)。同时关注前沿算法研发和踏实的产品落地,拥有大规模的业务数据积累。
作者介绍:
张德兵,格灵深瞳首席科学家和算法部负责人。发表学术论文多篇,并多次担任NIPS、ICML、ICLR、CVPR、ICCV、ECCV、AAAI 和 IJCAI 等学术会议审稿人,推动了深度学习和机器学习技术落地。
原文链接:
https://zhuanlan.zhihu.com/p/72518307
(*本文为 AI科技大本营转载文章,转载请联系原作者)
◆
精彩推荐
◆
“只讲技术,拒绝空谈!”2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。
目前,大会盲订票限量发售中~扫码购票,领先一步!

推荐阅读
干货 | 20个教程,掌握时间序列的特征分析(附代码)
从发展滞后到不断突破,NLP已成为AI又一燃爆点?
长点心吧年轻人,利率不是这么算的!我用Python告诉你亏了多少!
一文看懂数据清洗:缺失值、异常值和重复值的处理
Libra 骗局来了! 受害者会是你吗?
那个裸辞的程序员,后来怎么样了?
FreeWheel是一家怎样的公司?| 人物志
Mac 被曝存在恶意漏洞:黑客可随意调动摄像头,波及四百万用户!
文末送书啦!| Device Mapper,那些你不知道的Docker核心技术
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢