ChatGPT原理剖析
ChatGPT原理剖析2_2
ChatGPT分为三个部分
1.Generative,Pre-trained,Transformer

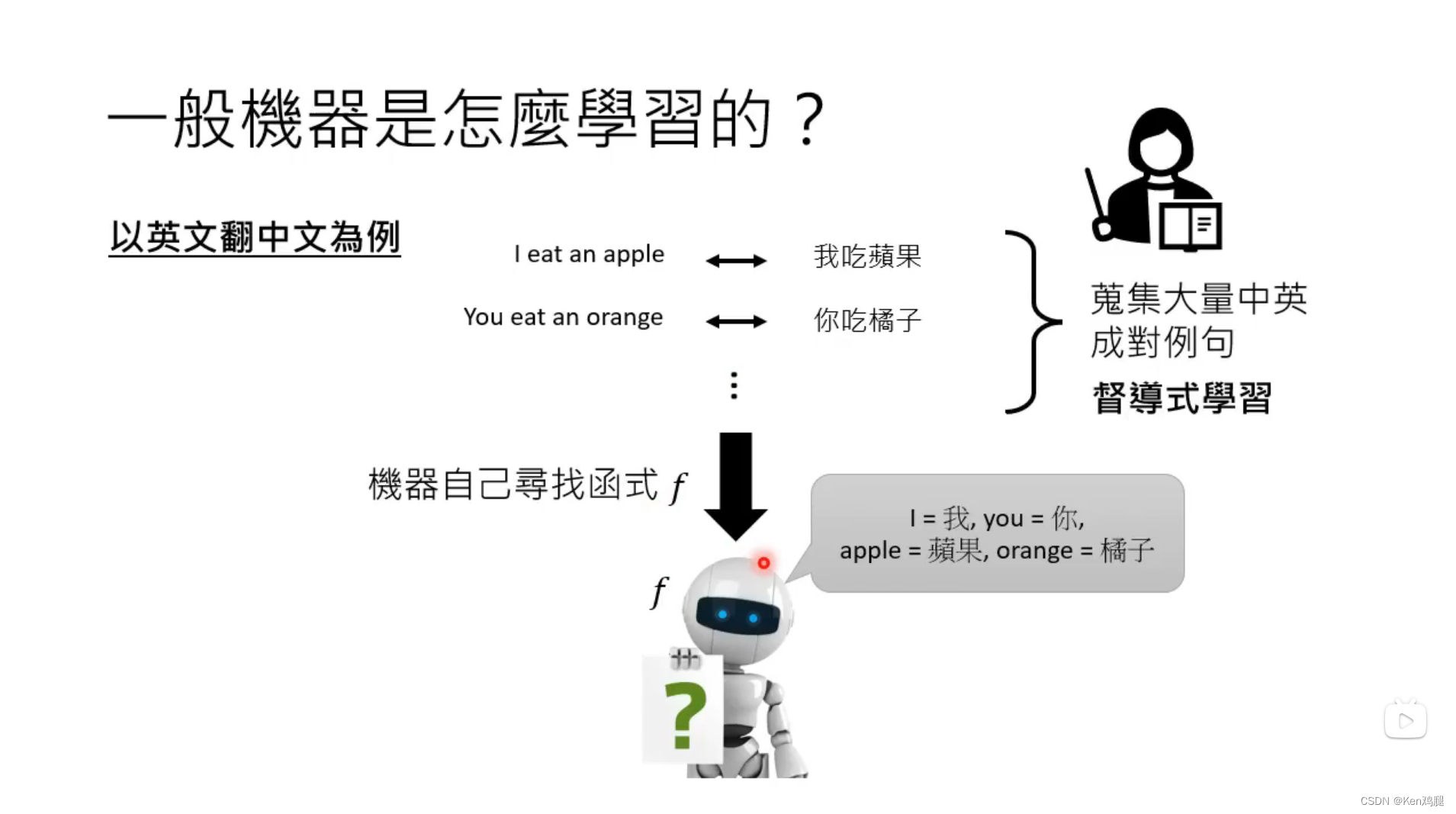
2.以往的机器学习是根据成对的例句,通过大量成对的例句找出规律,可以理解为找出了某个函数
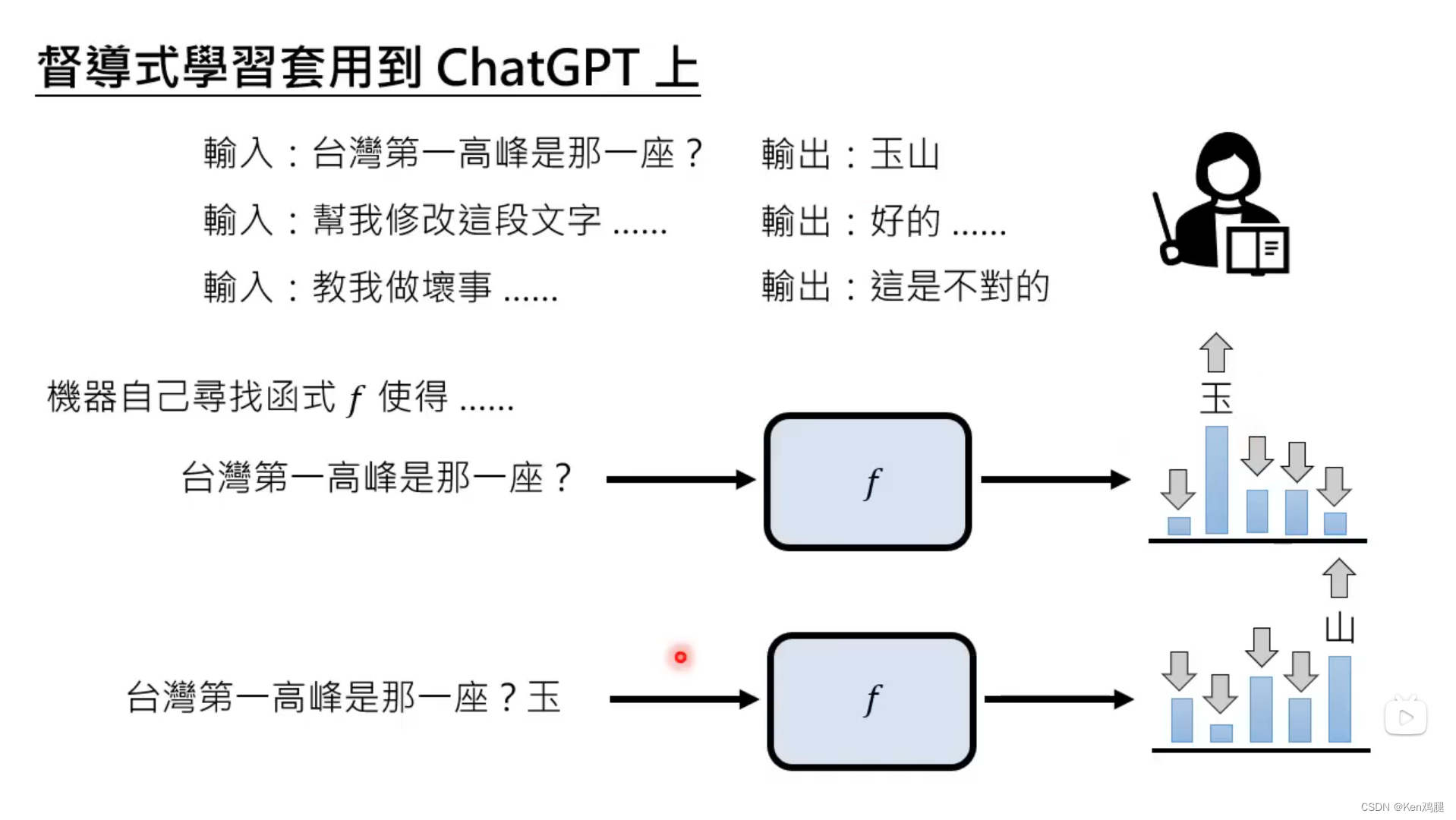
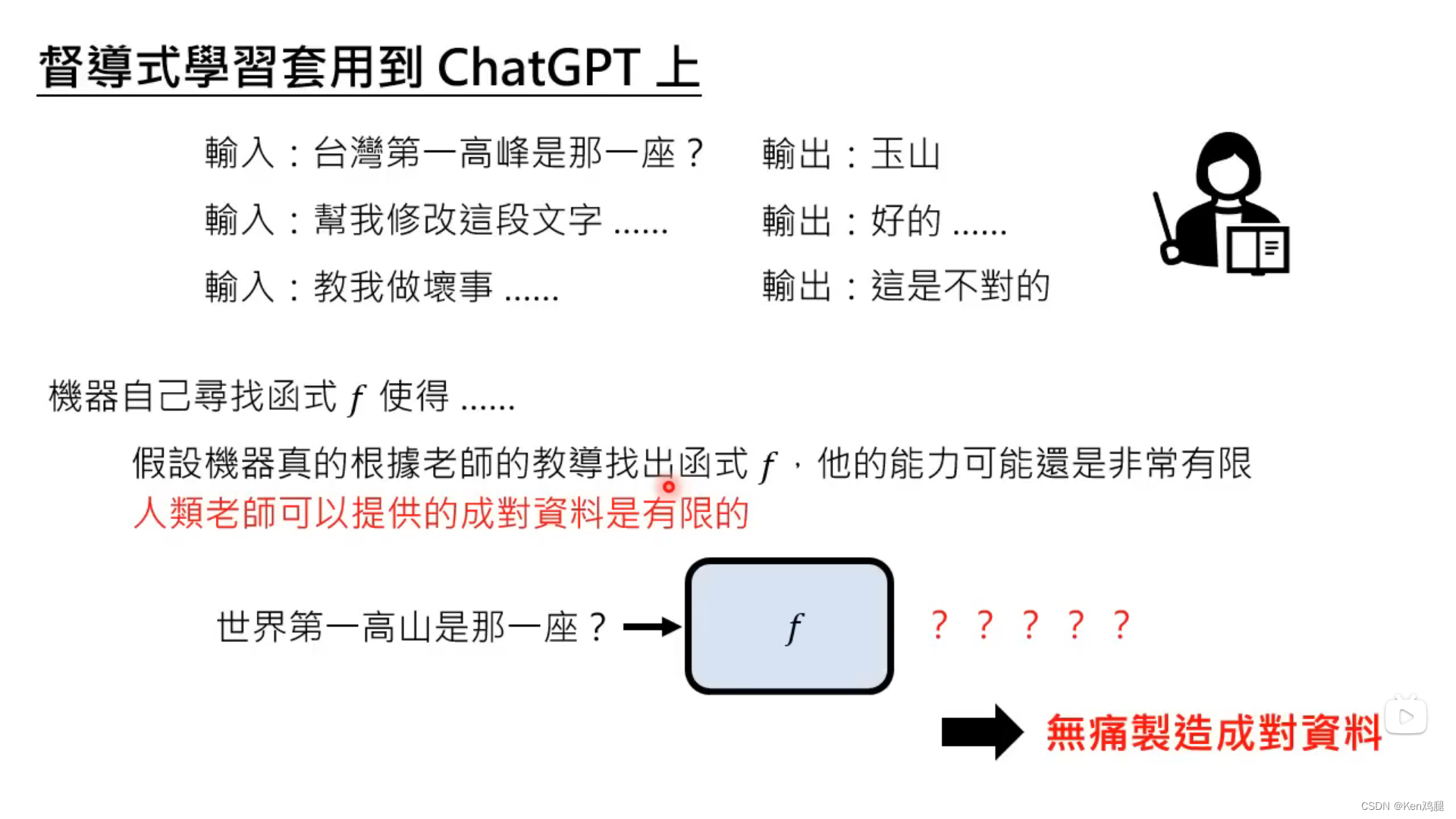
3.如果让人类来制造例句的话,效率会比较低,并且成本会很高,因此这里开始使用互联网的数据进行监督学习,并根据互联网上的讯息总结为某个函数
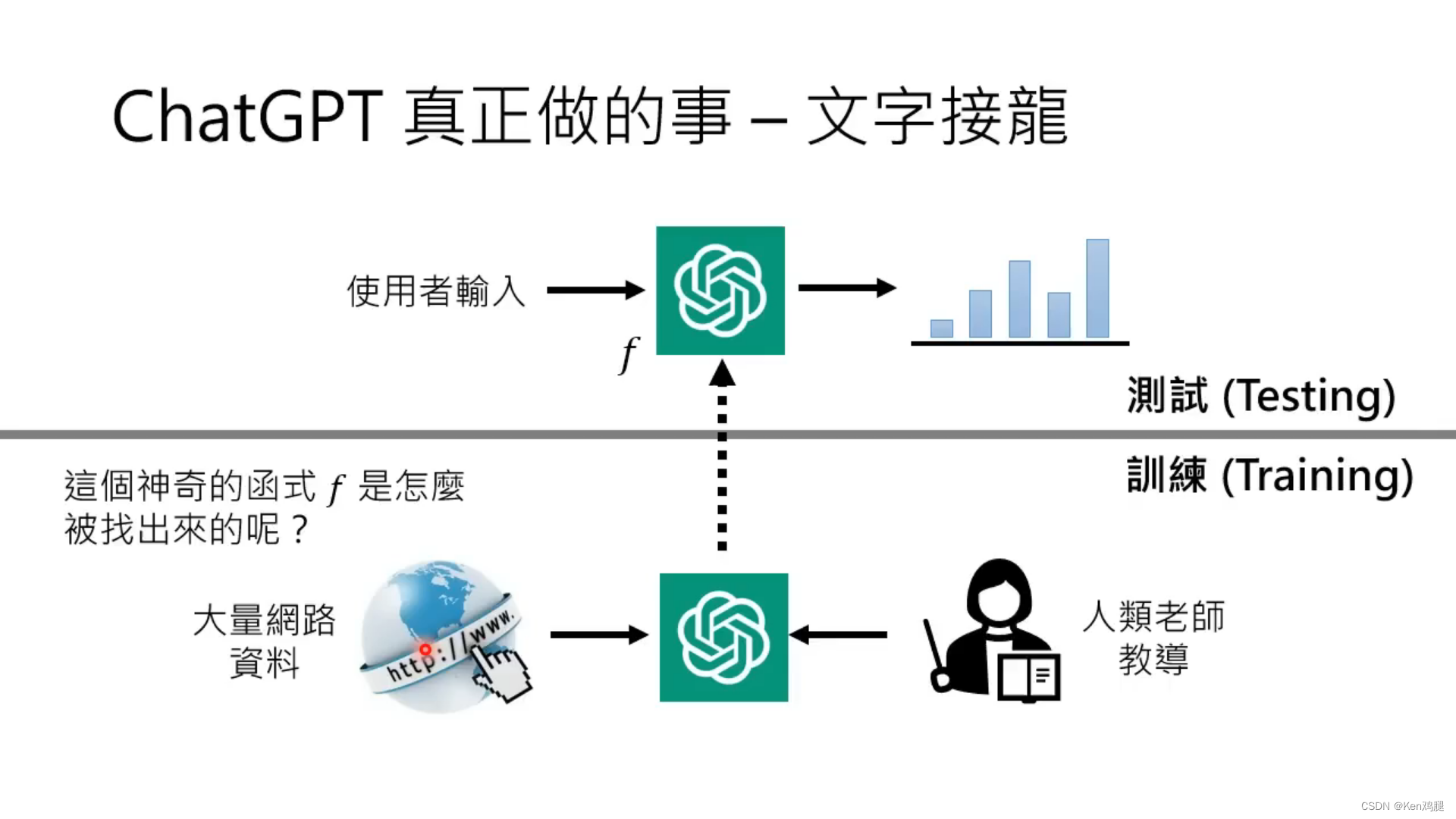
4.在收集了足够多的数据后,就可以基于这些数据来回答问题,基于算法来做文字接龙了
GPT的参数以及规模
1.GPT-3的参数量是175Billion,数据集是570GB这个数据量相当于是将哈利波特全集读了30万遍,一套哈利波特的文字量大约是150万字。可见GPT使用的数据有多大,并且570GB还只是GPT从所有数据45T中选取的一部分

完整的流程

这里解释了整个流程预训练->监督学习->强化学习,我们需要前期给到足够多的例句让GPT有基本的文字接龙的能力,在通过人类老师的监督学习,这里GPT->ChatGPT这里就是Finetune(微调)使其能达到更好的效果,在最后一步就是强化学习(Reinforcement Learning),通过打分机制来告诉ChatGPT回答的好不好,以提升ChatGPT的效果。
1.这里为什么要进行预训练呢,这里对其进行了解释,在多种语言上进行预训练后,只要教某一种语言的一种任务,就能达到比较好的效果。
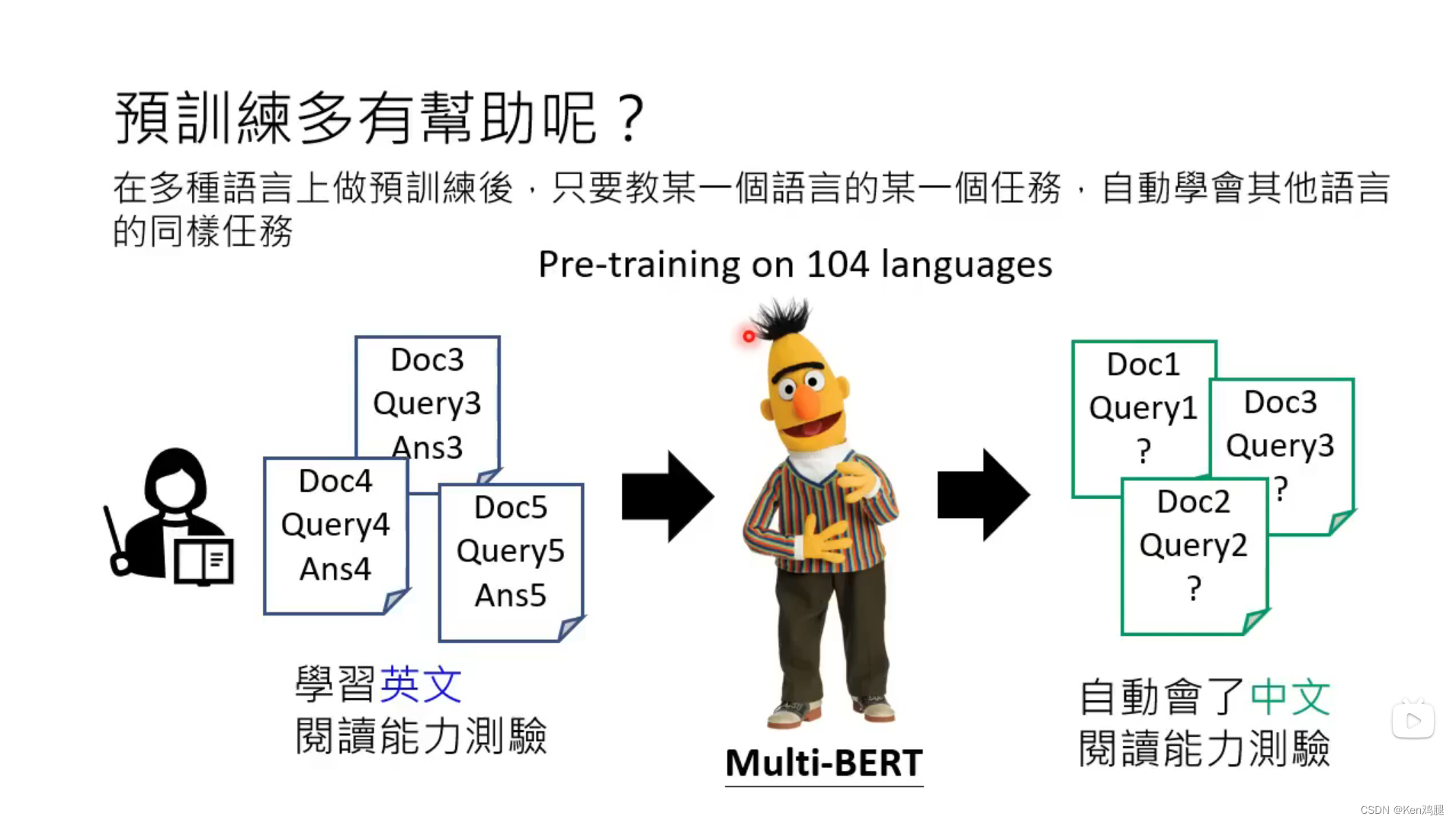
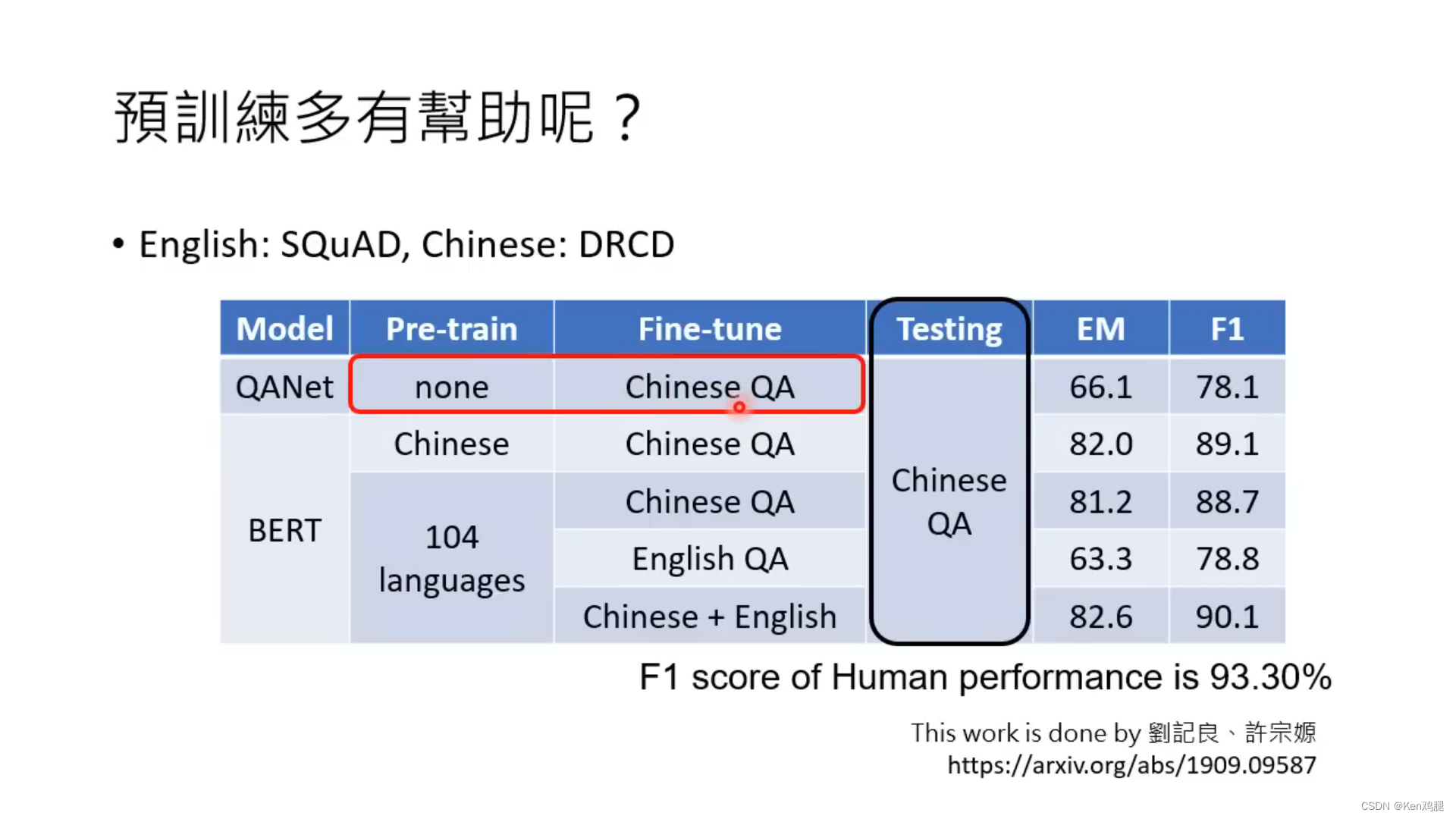
2.这里举了一个例子在是否做了预训练后,通过中文进行微调,做中文的测试,效果会比没有做预训练的模型效果要好。
ChatGPT原理剖析2_3
ChatGPT带来的研究问题
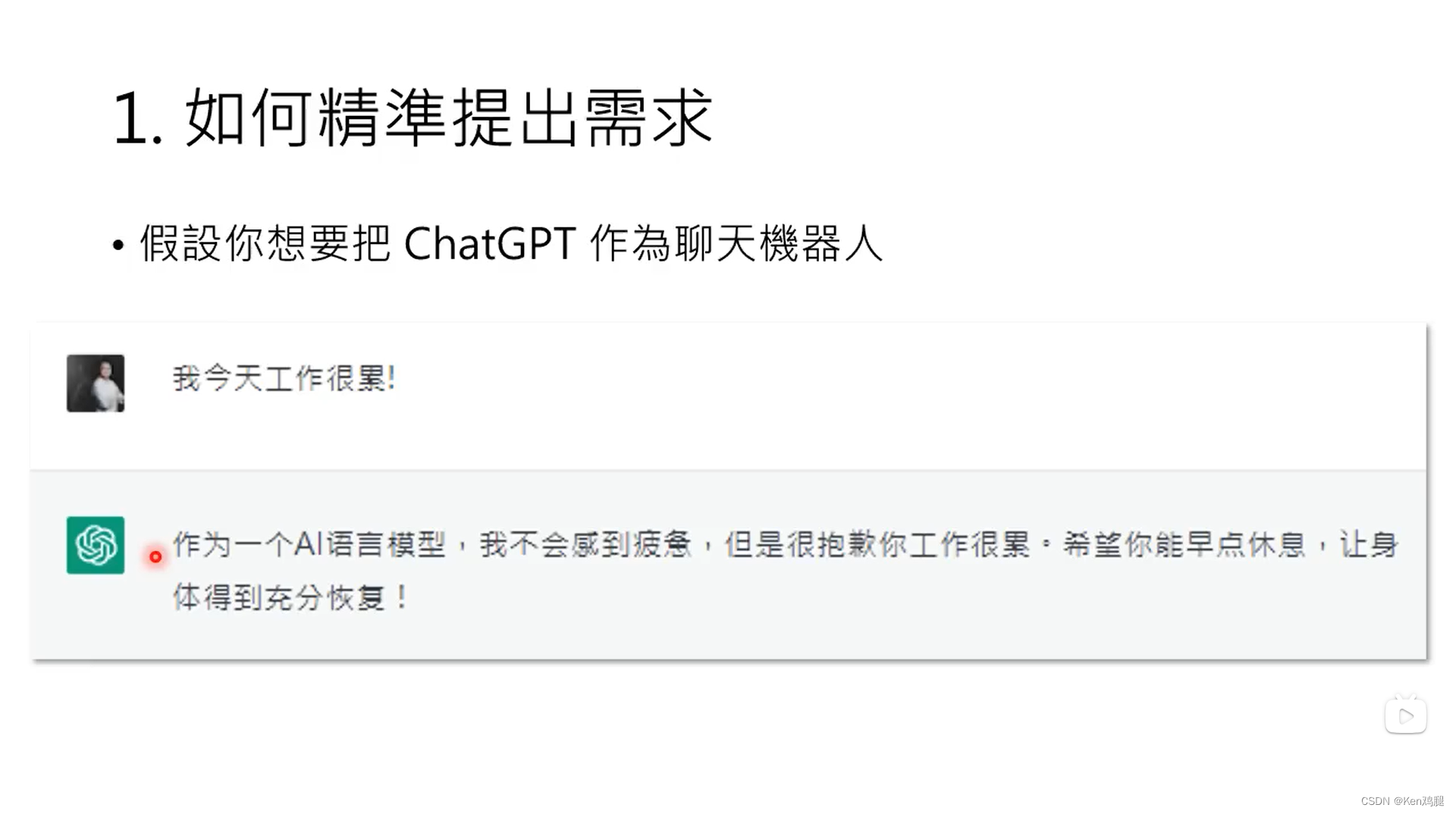
1.如何精准提出需求
和人一样,如果没有精准的表达内容,聆听者是没有办法知道你所想表达的意思的,ChatGPT也是一样,我们需要表达让它听的懂得内容,这样它才能较好的 给到我们反馈,而这个过程称为Prompting
2.如何更正错误
ChatGPT数据只更新到2021年,所以它对之后的事情并不知情(当然现在有很多可以联网的插件可以用),这里李宏毅老师在得到不准确的数据后,告诉ChatgGPT 最近的世界杯足球赛冠军是阿根廷。但我们可以想象,如果告诉ChatGPT错误的答案会不会影响ChatGPT的反馈结果,这里就有一个研究方向是Neural Editing。


3.侦测AI的物件
这里举了一个例子通过人写的内容和AI生成的内容对照,寻找两者之间的区别。但这似乎没这么简单。最近有听说Sam Altman也是在寻求找到区分人类和AI内容的方法。

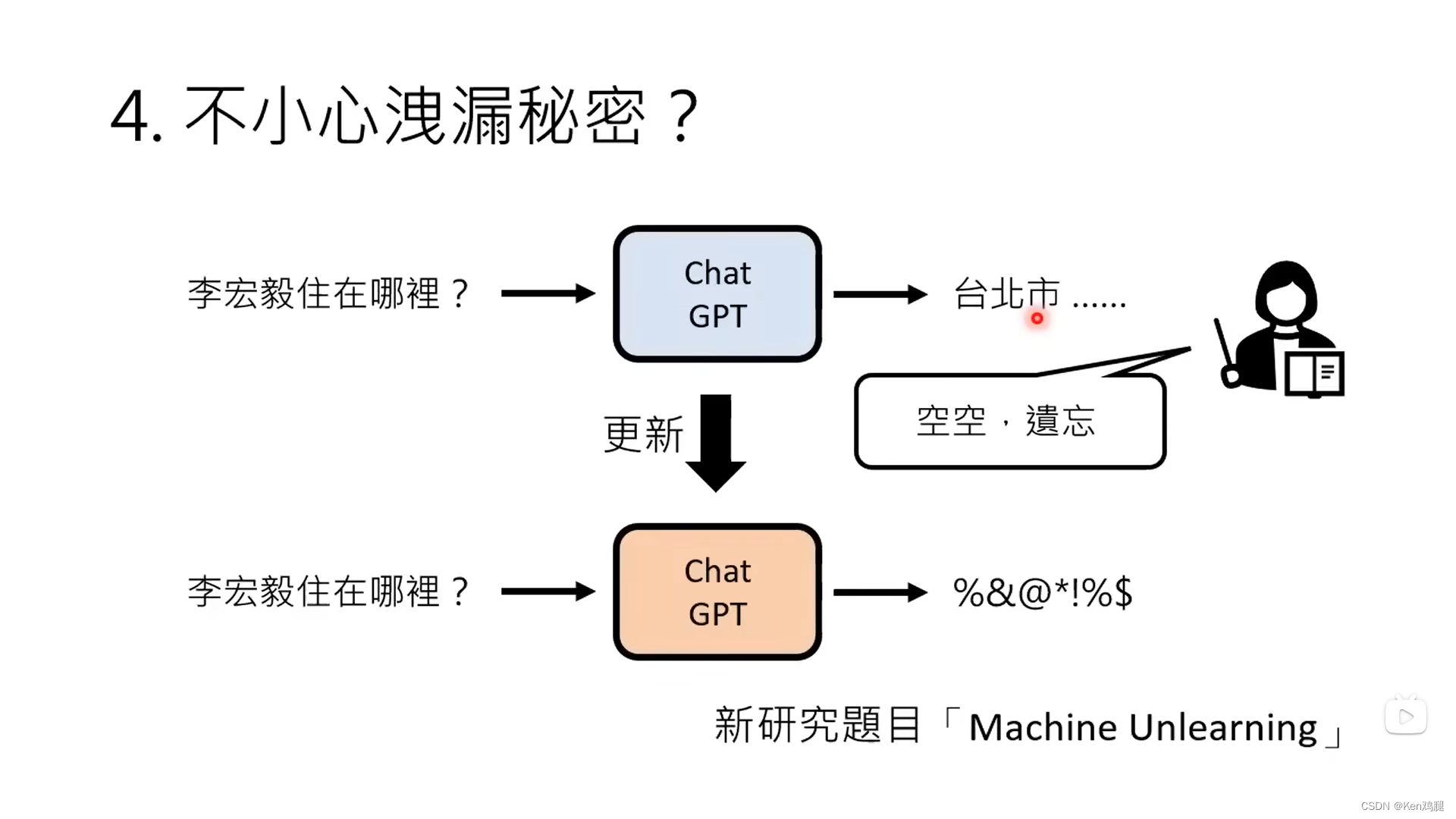
4.如何保护不想上传到互联网的内容
在李宏毅老师搜寻自己住哪里的时候,开始ChatGPT是直接回答不知道的,但是当绕着弯让其扮演自己一定知道李宏毅住在台湾某个地方的时候,AI还是提供了一个地址,这里就对于隐私保护就蛮重要的,因此也诞生了一项新的研究Machine Unlearning。
ChatGPT是怎样炼成的-GPT社会化的过程
ChatGPT和instructGPT非常像,区别仅仅在于ChatGPT是在GPT3.5的基础上fine-tune,而instructGPT是在GPT3.0基础上fine-tune


1.由于每个文字出现的概率不同,所以GPT每次抽取出的文字是不同的,因此最终输出的内容也是不同的。
2.通过对InstructGPT的论文,可以看出不用给到GPT所有的数据,它具备泛化的能力,不过我们需要给到GPT一些范例,让其知道人类的喜好,以便其能按照需求回答人类的问题

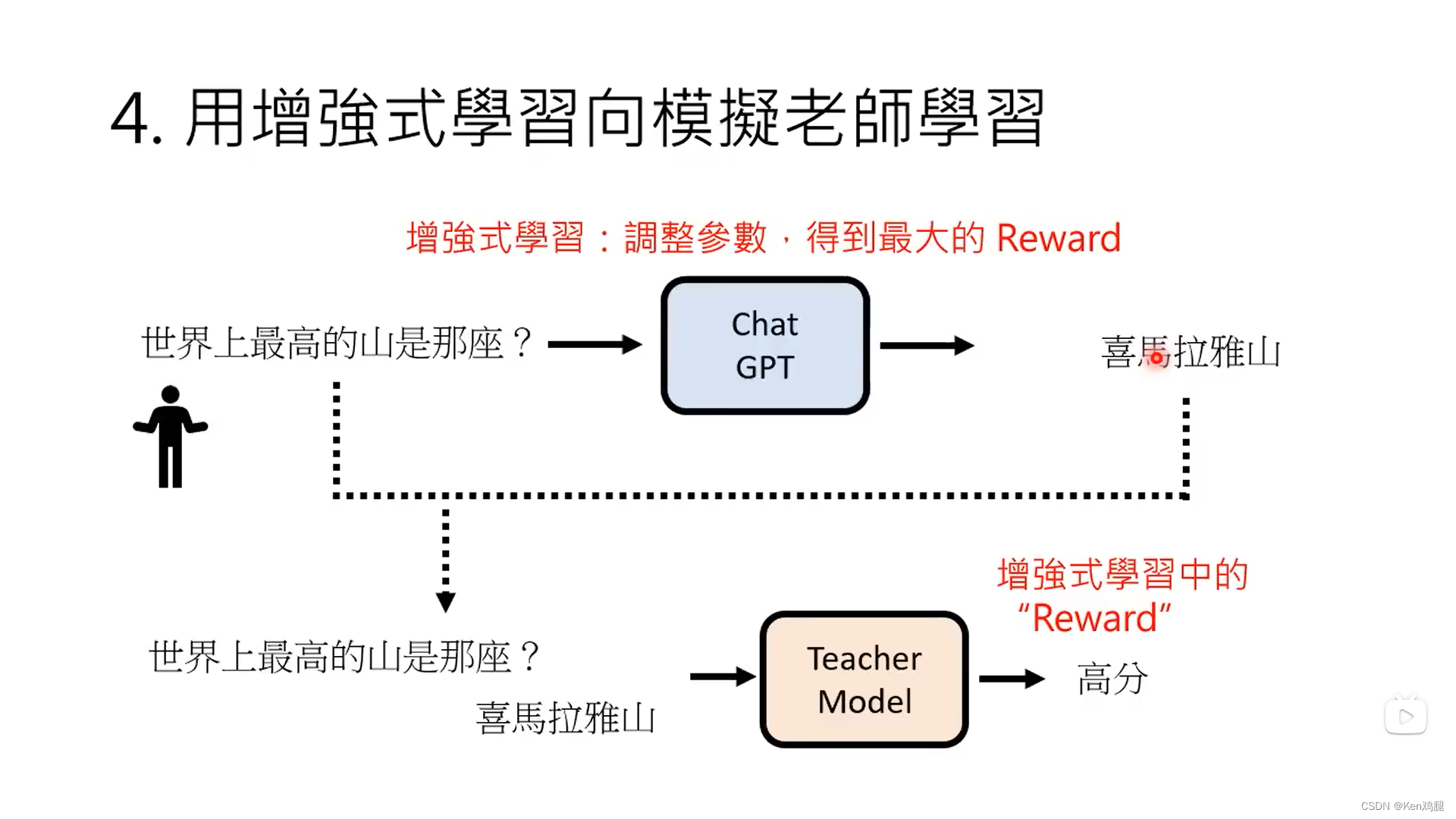
3.需要训练一个老师模型(老师模型知道人类的偏好),来告诉GPT,回答的哪些答案是比较好的答案,打出一个分数,以便于它能有更高的概率回答出更好的答案

4.这里将问题和答案给到teacher model,她会有打分,经过reinforce learning 再给到GPT,这样就有了ChatGPT.