Data Augmentation for Deep Neural Networks Model in EEG Classification Task: A Review
脑电图(EEG)的分类是测量神经活动节奏振荡的关键方法,是脑机接口系统(BCI)的核心技术之一。然而,从非线性和非平稳的EEG信号中提取特征,在目前的算法中仍然是一项具有挑战性的任务。随着人工智能的发展,近年来已经提出了各种先进的算法用于信号分类。其中,深度神经网络(DNN)由于其端到端的结构和强大的自动特征提取能力,已经成为最具吸引力的一类方法。然而,在BCI的实际应用中很难收集大规模的数据集,这可能会导致分类器的过拟合或弱泛化。为了解决这些问题,人们提出了一种有希望的技术,以提高基于数据增强(DA)的解码模型的性能。在这篇文章中,我们调查了最近对基于DNN的EEG分类的各种DA策略的研究和发展。审查包括三部分:使用何种基于BCI的EEG范式,采用何种类型的DA方法来改进DNN模型,以及可获得何种准确性。我们的调查总结了当前的实践和性能结果,旨在促进或指导未来研究和开发中DA对EEG分类的部署。
1 Introduction
作为捕捉大脑活动意向的重要工具,脑电图(EEG)可以用来测量大脑的节律性振荡,反映大量神经元群体的同步活动(Atagün,2016)。节奏振荡与神经中枢的状态变化密切相关,直接反映了大脑的心理活动(Pfurtscheller,2000;Villena-González等人,2018)。脑机接口(BCI)是作为用户和计算机之间通信协议的典型应用之一,不依赖于大脑和肌肉的正常神经通路(Nicolas-Alonso和Gomez-Gil,2012)。根据EEG的生成类型,BCI可分为三种类型:非侵入性BCI、侵入性BCI和部分侵入性BCI(Rao,2013;Levitskaya和Lebedev,2016)。由于风险低、成本低和方便,基于EEG的非侵入性BCI是最受欢迎的BCI类型,也是本文讨论的主要类型。
在执行互动期间,EEG的自动分类是使BCI在应用中更加实用的重要步骤(Lotte等,2007)。然而,一些限制给分类算法带来了挑战(Boernama等,2021)。首先,EEG信号的振幅很弱,并且总是伴随着不相关的成分,其信噪比很低。其次,EEG的本质是神经元集群活动的潜在变化,是一种非稳态信号。在目前的研究中,机器学习和非线性理论的技术被广泛用于EEG分类(Lotte等人,2018)。然而,较长的校准时间和较弱的泛化能力限制了它们在实践中的应用。
在过去的几年里,深度神经网络(DNN)在图像、语音和自然文本处理领域取得了优异的成绩(Hinton等人,2012;Bengio等人,2013)。通过基于分层表示和映射的连续非线性转换,可以从输入数据中自动提取特征。由于其能够最大限度地减少冗余信息的干扰和非线性特征提取,基于DNN的EEG解码已经吸引了越来越多的关注。然而,获得预期结果的先决条件之一是支持大规模的数据集,以确保DNNs的鲁棒性和泛化能力(Nguyen等人,2015)。脑电图收集仍有一些挑战。首先,由于对实验环境和受试者有严格的要求,可能会导致过度拟合,增加模型的结构风险,所以很难收集大规模的数据(Zhang D. et al.)不仅如此,脑电信号极易受到心理和生理条件变化的影响,导致不同受试者/会话的特征分布具有高度的变异性(Zhang D. et al.) 它不仅降低了解码模型的准确性,而且还限制了模型在独立测试集中的泛化。
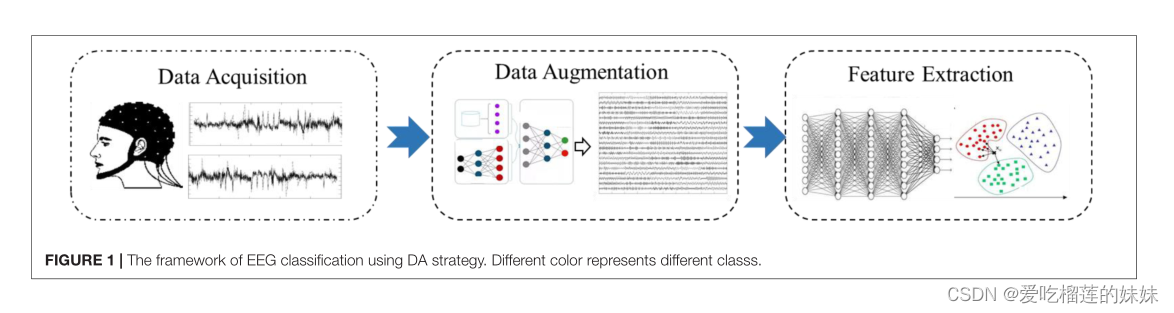
一个有前途的方法是正则化(Yu等人,2008;Xie等人,2015),它可以有效提高DNN的泛化能力和鲁棒性。有三种方法可以实现正则化,包括在损失函数中加入项(如L2正则化),直接在模型中加入项(如dropout、批量正则化、核最大规范约束),以及数据增强(DA)。与前两种方法相比,DA通过使用更全面的数据集以最小化训练和测试数据集之间的距离来解决过拟合问题。这对脑电信号特别有用,因为小规模的数据集的限制极大地影响了分类器的性能。因此,研究人员越来越关注在EEG分类任务中使用DA的深度学习(DL)模型的优化问题。该方法的框架显示在图一。
本文其余部分的组织如下。识别相关研究的检索方法在“方法”一节中详细描述。在“结果”部分,介绍了基于dnn的脑电分类中DA的基本概念和具体方法。“讨论”部分讨论了目前的研究现状和面临的挑战。最后,在“结论”部分得出结论。
方法
通过Web of Science、PubMed和IEEE Xplore进行了2016 - 2021年的广泛文献检索。用于搜索的关键词包括DA、EEG、深度学习、dnn。表1列出了包含或排除的收集标准。

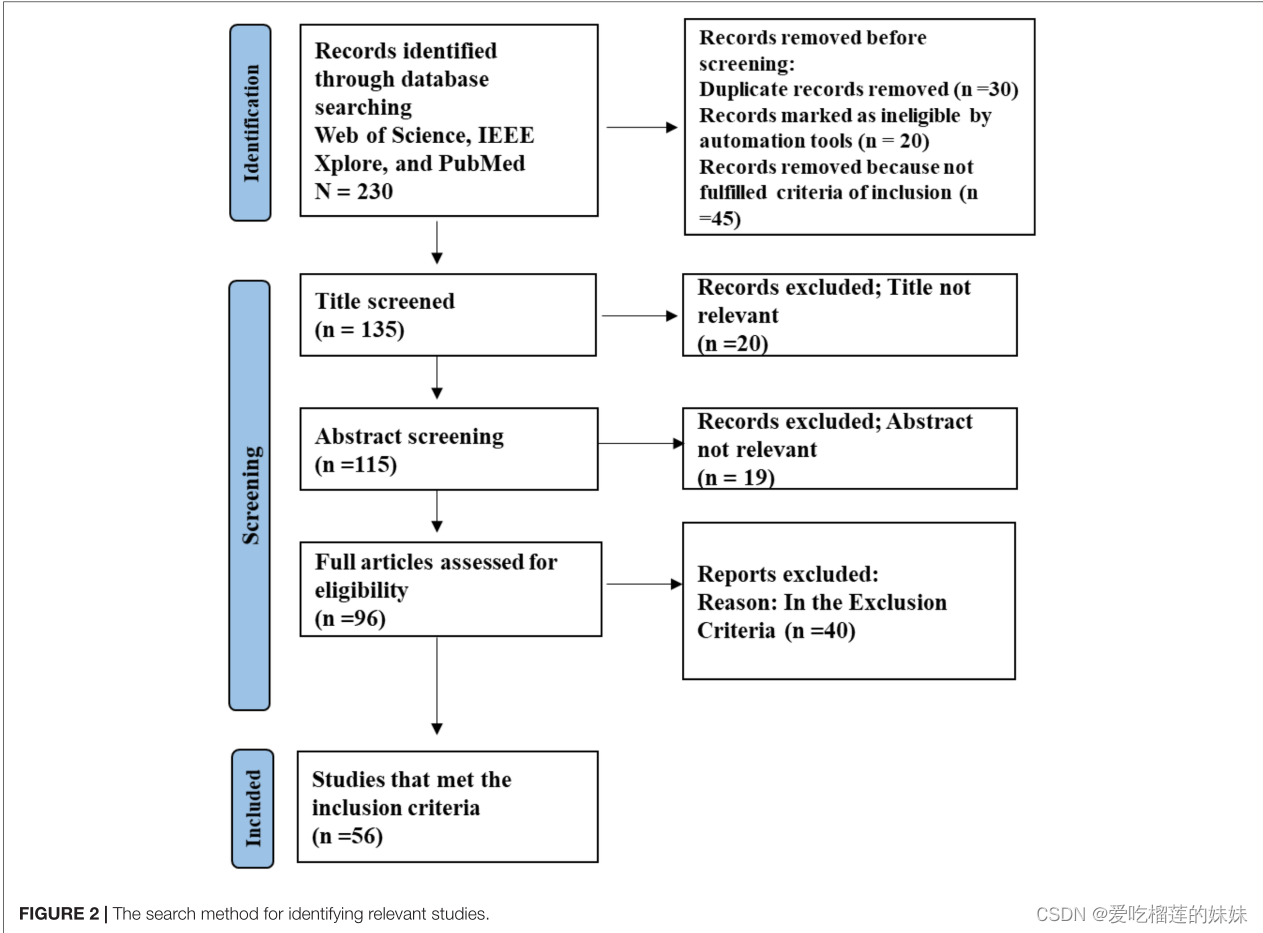
本综述遵循PRISMA指南(Liberati et al., 2009)。图2中的流程图总结了结果。流程图识别并缩小了相关研究的集合。符合排除标准的所有数据集和研究之间的重复被排除。最终纳入符合纳入标准的论文56篇。
结果
数据增强的概念和方法
数据增强的目的是防止DNN模型的过拟合,方法是根据现有的训练数据人为地生成新的数据(Shorten and Khoshgoftaar, 2019)。该技术主要有三种策略:基本图像处理、深度学习和特征转换。第一种方法直接在输入空间中进行增强,而后两种方法基于数据集的特征空间实现DA。
在这里,我们将在以下部分简要介绍这些方法。
基于图像操作的数据增强
基于图像操作的数据增强以直观和低成本的方式使用几何特征进行简单的转换。典型的方法可以分为以下几类。
几何转换:图像的几何特征通常是包含方向和轮廓元素的物理信息的视觉表示(Cui et al., 2015;Paschali等人,2019)。常用操作包括:
翻转:这种方法是在矩阵大小一致的前提下,沿水平轴或垂直轴旋转图像来实现的。
裁剪:可以通过对图像的中心区域进行随机裁剪,然后将其余部分混合来实现裁剪操作。
旋转:数据增强旋转是通过将图像沿某一坐标轴旋转来实现的。如何选择旋转参数是影响增强效果的重要因素。
光度和颜色转换:
在颜色通道的空间中执行增强是另一种实际实现的方法(Heyne et al., 2009)。在操作过程中,原始数据被转换为功率谱,应力图,等等。它们代表了空间特征的分布。
颜色变换:通过调整RGB矩阵来实现新数据的生成。
噪声注入:另一种增加数据多样性的方法是在原始数据中注入随机矩阵,这些矩阵通常来自高斯分布(Okafor等人,2017)。
基于深度学习的数据增强
图像处理增强方法是在数据的输入空间中进行变换。然而,这些方法不能利用数据的底层特征来执行增强(Arslan等人,2019)。最近,一种新的DA方法引起了研究者的注意。利用dnn将数据空间从高维映射到低维,并实现特征提取来重构人工数据(Cui et al., 2014)。DA有两种典型的深度学习策略:自动编码器(AE)和生成对抗网络(GAN)。
自动编码器及其改进版本
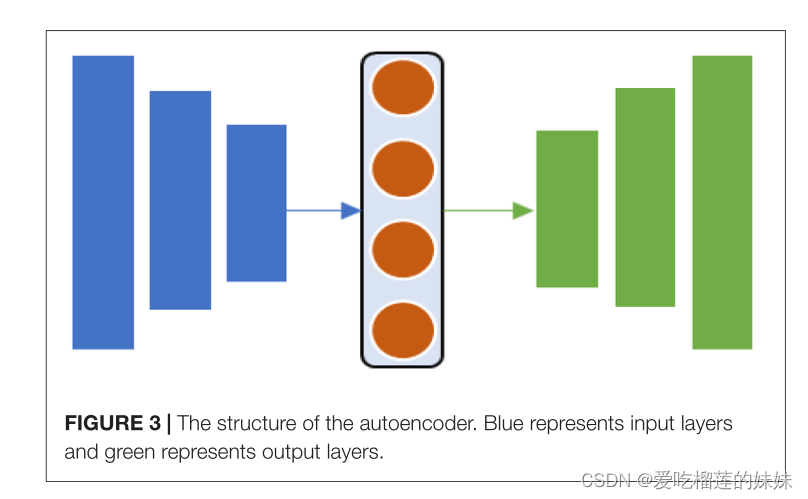 如图3所示,AE是一种前馈神经网络,用于用一半网络将原始数据编码为低维向量表示,并使用另一半网络将这些向量重建回人工数据(Yun et al., 2019)。
如图3所示,AE是一种前馈神经网络,用于用一半网络将原始数据编码为低维向量表示,并使用另一半网络将这些向量重建回人工数据(Yun et al., 2019)。
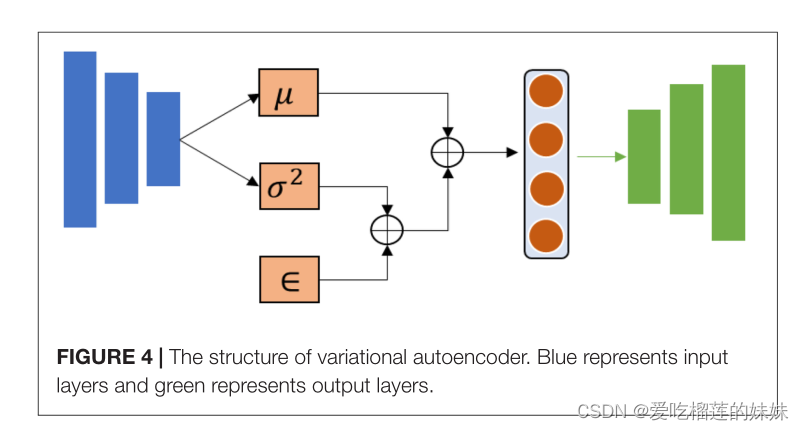
为了获得预期的生成数据,提出了一种变分自编码器(V AE)来提高自编码器的性能。与AE相比,V AE通过在结构中添加约束,确保生成的数据服从特定的概率分布(图4)。其中,µ为概率分布的均值,σ2为方差,∈为偏差。
生成式对抗网络及其改进版本
生成式对抗网络是指基于对抗学习原理的人工生成数据。
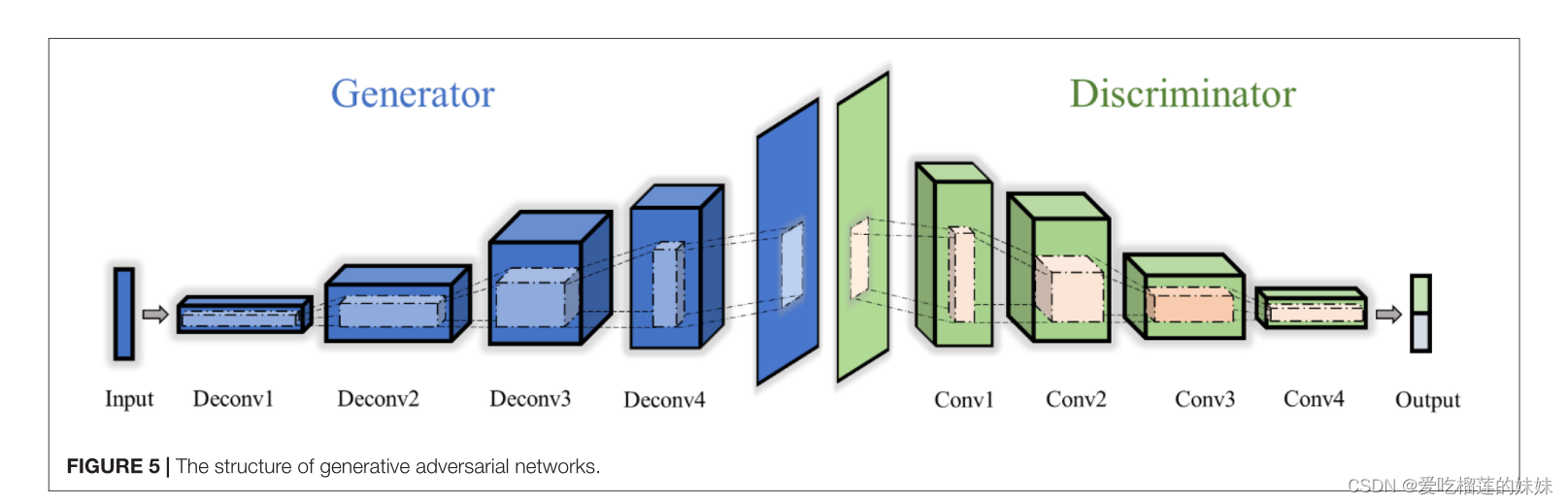
如图5所示,它在双边网络之间进行竞争,以达到学习目标数据统计分布的动态平衡(Deng et al., 2014)。GAN的优化问题可以定义为:
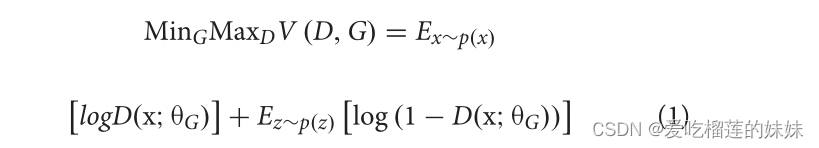
式中,p(x)为训练数据的分布,D(x;θG)是用于估计实际数据x的生成数据z之间概率分布p(•)的判别模型。V为值函数,E为期望值。在训练阶段的过程中,GAN的目标是找到具有高维参数的非凸博弈的纳什均衡。但是,模型的优化过程没有对损失函数进行约束,在训练阶段容易产生无意义的输出。为了解决这一问题并扩大其应用范围,研究人员提出了改进的结构,如深度卷积GAN、条件GANs、循环GANs等(Goodfellow et al., 2014)。在这些DA的新架构中,DCGAN使用cnn来构建生成器和鉴别器网络,而不是比GAN在内部复杂性上扩展更多的多层感知器(Radford et al., 2015)。为了提高训练过程的稳定性,提出了一个额外的循环一致性损失函数来优化GAN的结构,将其定义为循环GANs (Kaneko et al., 2019)。条件GANs通过向生成器和鉴别器添加条件向量,有效地缓解了模式崩溃的限制(Regmi和Borji, 2018)。另一种感兴趣的架构是Wasserstein GAN (WGAN)。该架构使用Wasserstein距离来测量生成数据与真实数据之间的距离,而不是Jensen-Shannon或Kullback-Leibler散度来提高训练性能(Y ang et al., 2018)。
基于特征变换的数据增强
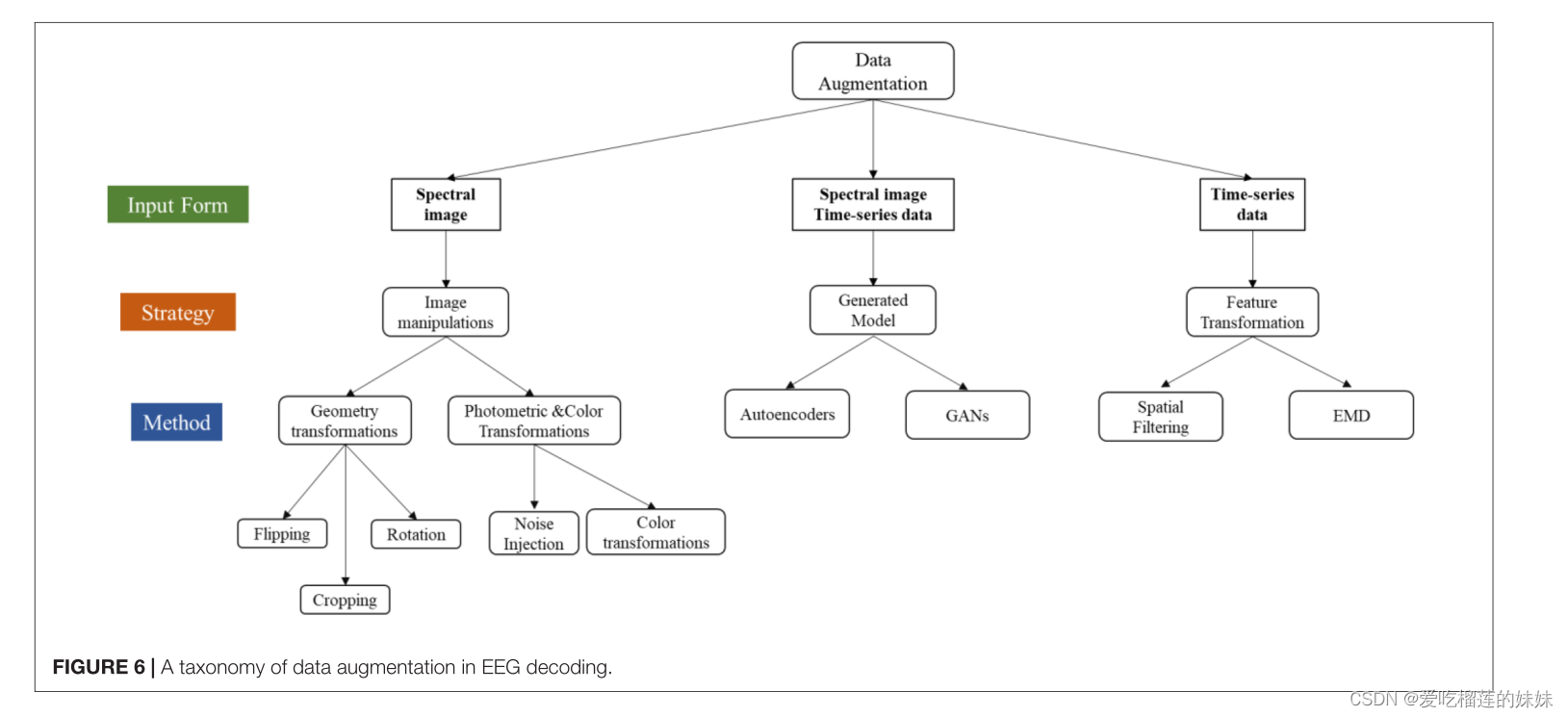
与图像处理和深度学习方法相比,特征变换利用低维特征的空间变换进行DA,生成分布多样的人工数据。但也有少数研究报道了相关方法。提出了一种新的空间滤波方法,该方法通过将时延策略与常见的频谱空间模式(CSSP;Blankertz和BCI竞争,2005)。另一项研究应用经验模态分解将脑电图划分为DA的多个模态(Freer和Y ang, 2019)。为了清楚地显示DA的分类,图6简要地集成了本文中收集的所有DA方法。
典型脑电图范例
根据交互形式的不同,BCIs可分为主动型和被动型两种。其中,主动脑机接口被定义为对特定外部刺激的神经活动,包含三种典型范式:运动意象(MI)、视觉诱发电位(VEP)和事件相关电位(ERP)。MI是一种没有真正输出的模仿运动意图的心理过程。不同的意象任务可以激活大脑的相应区域,而这种激活可以通过脑电图的各种特征表示来反映(Bonassi et al., 2017)。视觉诱发电位是当人类接受闪烁的视觉刺激时,视觉区域产生的连续反应(Tobimatsu和Celesia, 2006)。当外部刺激以固定频率形式呈现时,视觉区域被调制以产生与该频率相关的连续响应,即稳态视觉诱发电位(SSVEP;Wu等人,2008)。事件相关电位是指在接受视觉、音频或触觉刺激等特定刺激时的潜在反应(Luck, 2005)。与主动脑机接口相比,被动脑机接口旨在从被试的任意大脑活动中输出EEG信号,这是一种不依赖于自愿任务的脑机接口形式(Roy et al., 2013;Arico等人,2017)。在本节中,我们回顾了最近关于DA在基于dnn的脑电图分类中的报道。
脑电图分类的数据增强策略
近年来,DA在脑电分类中的应用得到了越来越多的关注。Abdelfattah等人(2018)使用循环GANs (RGAN)来提高MI-BCI任务中分类模型的性能。与GAN的结构不同,他们使用循环神经网络来替代发电机组件。由于RGAN能够捕获信号的时间依赖性,在时间序列数据生成中显示出很大的优势。通过对三种模型的验证,DA后的分类精度明显提高。
Zhang等人(2020)使用深度卷积GAN (DCGAN)进行了图像增强的研究,该深度卷积GAN在生成器中用分数跨卷积代替池化层,在鉴别器中用跨卷积代替池化层。他们考虑到特征分布的规律,将时间序列信号转换为频谱图形式,并应用卷积运算的对抗训练来生成数据。同时,他们讨论了不同DA模型的性能,并验证了DCGAN生成的数据具有最佳的相似性和多样性。
Freer和Y ang(2019)提出了一种卷积长短期记忆网络(CLSTM)对MI脑电图进行二进制分类。为了增强分类器的鲁棒性,他们分别应用噪声注入、乘法、翻转和频移来增强数据。结果表明,DA后平均分类正确率提高14.0%。
Zhang Z.等人(2019)在MIBCI任务中创建了一种新的DA方法,他们应用经验模态分解(EMD)将原始EEG帧划分为多个模态。分解过程定义为:
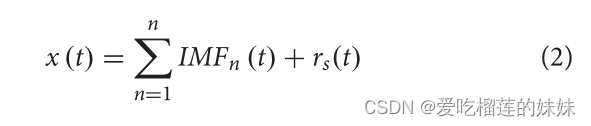
其中x (t)为EMD恢复信号,IMF为本征模态函数,s为IMF个数,rs(t)为最终残差值。在训练阶段,他们将IMFs混合到本征模态函数中以生成新的数据,然后使用复Morlet小波将其转换为张量,最后输入卷积神经网络(CNN)。实验结果表明,该人工脑电框架能够提高分类器的性能,并获得较高的准确率。
Panwar等人(2020)提出了一种带有梯度惩罚的WGAN (Eq. 3),用于合成快速串行视觉呈现(RSVP)任务的脑电图数据。值得注意的是,WGAN应用Wasserstein距离来衡量真实数据与生成数据之间的距离
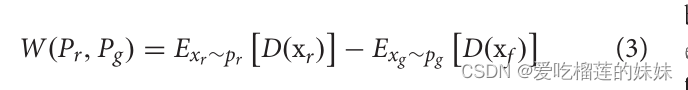
其中Pr和Pg是真实数据xr和生成数据xg的分布。W表示两个分布的距离,E为均值。为了提高训练的稳定性和收敛性,他们使用梯度惩罚来优化训练过程。
同时,该方法解决了DA训练过程中存在的频率伪影和不稳定性问题。为了评估DA的有效性,他们提出了两个评估指标(视觉检查和来自高斯混合模型的对数似然分数)来评估生成数据的质量。实验表明,在生成的数据中可以清楚地看到与EEG呈现相关的模式,并且在RSVP任务中,基于DA后的EEGNet模型获得了显著的改善(lawhenn et al., 2018)。Aznan等人(2019)也采用了类似的方法。
Aznan等人(2019)应用WGAN生成合成脑电图数据,优化SSVEP任务中的交互效率。之后,在离线阶段对预训练的分类器执行生成的EEG,并通过realcollection EEG对分类器进行微调。采用该方法对机器人进行控制,实现实时导航。结果表明,该方法显著提高了跨多主题实时导航任务的准确性。
Y ang等(2020)认为GT和NI的典型DA方法忽略了试验中信噪比(SNR)的影响。因此,他们提出了一种新的随机平均脑电图数据的DA方法,人工生成具有不同信噪比模式的脑电图数据。DA是通过从同一类别中随机取n (1 < n < n)个例子来计算每次迭代的平均电位来实现的,其中n代表所有试验的数量。采用RNN和CNN对视觉诱发电位(VEP)任务中的不同特定频率进行分类,DA后得到明显改善。
Li等人(2019)分别讨论了MI-BCI任务中噪声添加对时间序列形式和频谱信号的影响。他们利用CNN结合信道投影和混合尺度对4类MI信号进行分类,得出噪声可以破坏时间序列信号的幅值和相位信息,但不能改变频谱的特征分布。因此,他们使用STFT将时间序列脑电图信号转换为频谱图像,定义为振幅摄动DA。结果表明,对于两个公共数据集中的几乎所有主题,使用DA的性能都有所提高。
Lee等人(2020)研究了一种新的DA方法,称为边缘性合成少数群体过度采样技术(Borderline -SMOTE)。它利用少数类实例的m个最近邻生成少数类的合成数据,然后通过加权计算将这些实例加到实际数据中。通过从P300任务中收集的EEG数据来评估DA的有效性。结果表明,所提方法能够增强决策边界的鲁棒性,提高基于脑机接口的P300分类精度。
基于脑电图的被动脑机接口在研究中逐渐变得更加突出(Zander et al., 2009;Cotrina等人,2014;Aricò等人,2018),并用于检测和监测人类的情感状态。在这一部分中,我们介绍了数据分析在被动脑机接口中的应用案例。
Kalaganis et al.(2020)提出了一种基于图经验模态分解(EMD)的DA方法来生成EEG数据,该方法结合了多路网络模型的优点和经典经验模态分解的图变体。他们设计了一个虚拟现实环境下的持续注意力驱动任务,同时利用图CNN实现了对人体状态的自动检测。实验结果表明,对脑电信号图结构的探索能够反映信号的空间特征,图CNN与DA相结合的方法获得了更稳定的性能。
Wang等人(2018)讨论了脑电DA的局限性并在情感识别任务中指出了其特征脑电图在情绪检测任务中的作用与时间序列有较高的相关性。然而,直接的几何变换和噪声注入可能会破坏特征在时域内,这可能会导致负的DA效应。基于这些考虑,他们在原始数据的每个特征矩阵中加入高斯噪声,以获得新的训练样本。计算可以定义为:
其中,µ为均值,σ为标准差,P为概率密度函数,z为高斯随机变量。Xg为注入噪声后生成的数据。有三种分类模型,即LeNet, ResNet和SVM用于评估性能。结果表明,生成的数据可以显著提高基于LeNet和ResNet的分类器的性能。但是,它对支持向量机模型的影响很小。
Luo et al.(2020)应用条件Wasserstein GAN (cWGAN)和选择性V AE (sV AE)来增强分类器在情感识别任务中的性能。sVAE的损失函数定义如下:
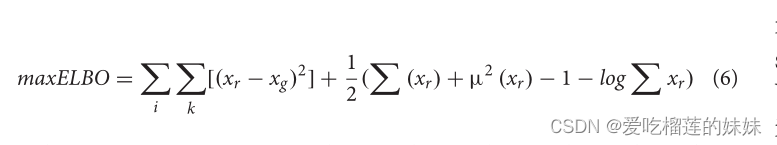
其中ELBO为证据下界,xr为真实数据,xg为生成数据。优化的目标是最大化ELBO, ELBO等于最小化真实数据与生成数据之间的KL发散。在GAN损失函数的基础上,增加一个额外的惩罚项:
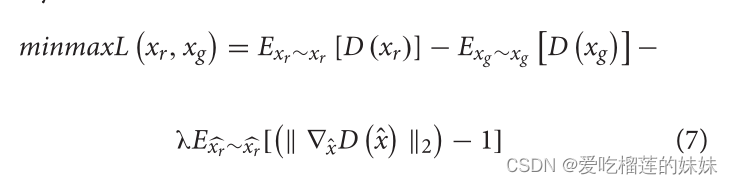
其中λ为原始目标与梯度惩罚之间权衡的权重系数,而x表示从真实分布与生成分布之间的直线上采样的数据点。K·k2是2范数。在他们的工作中,将DA模型的训练样本转化为功率谱密度或微分熵的形式,并比较了DA后不同分类器的性能。实验表明,脑电信号的两种表示形式都能满足人工数据集的要求,提高了分类器的性能。
Bashivan等人(2015)强调,从脑电图中建模认知信号的挑战是提取跨受试者/会话的信号表示,并提出DNN具有出色的特征提取能力。因此,他们将原始脑电图信号转换为拓扑保留的多光谱图像,作为心理负荷分类任务的训练集。为了解决过拟合和泛化能力较弱的问题,他们在光谱图像中随机添加噪声来生成训练集。
然而,这种DA方法并没有显著提高分类性能,只是加强了模型的稳定性。为了更全面地展示实现,我们在表2中总结了DA在脑电图解码中的应用细节。
讨论
小规模数据集的局限性阻碍了深度学习在脑电分类中的应用。近年来,DA策略得到了广泛的关注,并被用于提高dnn的性能。然而,仍有几个问题值得讨论。
综合以上讨论,我们发现DA模型的输入形式可以分为三类:时间序列数据、光谱图像和特征矩阵。
我们还发现,在MI任务中,研究者更倾向于将EEG信号转换为图像信号进行后续处理。一个可能的原因可能是MI的特征通常伴随着频带能量的变化,即事件相关去同步(ERD)/事件相关同步(ERS;Phothisonothai和Nakagawa, 2008;阳台和马扎,2009)。这一现象表明,MI-EEG在时频空间表现出更显著的特征表征,而不是在时域。而基于VEP范式的脑电图更倾向于采用时间序列信号作为输入,对时间锁定有严格的要求,且时间序列特征更明显(Basar et al., 1995;Kolev和Schurmann, 2009;孟等人,2014)。另一种形式的输入是可以通过小波、熵、STFT、功率谱密度等提取的特征矩阵(Subasi, 2007;Filippo等人,2009;Seitsonen等人,2010;卢等人,2017;Lashgari等人,2020)。
从实现角度的不同,数据分析可分为输入空间增强和特征空间增强。事实上,前者具有可解释性和计算成本较低的优点。但是,根据表2所示的分类性能结果,我们发现在特征空间中的操作比在输入空间中的操作可以获得更显著的改进。一种解释是,由于不可思议的非线性映射和自动特征提取能力,这种类型的DA模型可以提取数据的内在表示。
近年来,生成对抗网络在生成脑电图信号方面已经变得流行(Hung和Gan, 2021),尽管它仍然没有被清楚地证明是跨不同脑电图任务的最有效策略。由于研究数量有限,目前尚不清楚哪种方法更受欢迎。因此,研究人员应根据脑电的范式类型和特征表征选择合适的DA方法。
以往的研究表明,在不同的EEG任务中,DA可以不同程度地提高EEG的解码精度。
然而,这种改善在不同的数据集和预处理模式下有很大差异。有几种可能的解释有待讨论。首先,大多数研究没有讨论DA在训练分类器阶段是否会产生负面影响,如上所述,脑电图信号伴随着强噪声和多尺度伪影。但现有的DA方法是全局操作,无法有效区分这些不相关的组件。同时,从特定BCI任务(SSVEP, P300)采集的脑电图信号执行的特征是锁定时间和锁定相位的,这可能会导致使用GT生成人工数据的特征表示错误。而由于GT信号对特征锁定没有严格的要求,因此在MI和ER任务中表现良好。因此,在应用GT之前,应该先分析脑电信号的特征表示。其次,虽然生成数据的特征分布的边界条件是数据有效性的重要保证之一,但目前也有少数研究讨论生成数据的特征分布的边界条件。
另一个值得讨论的重要问题是生成多少数据可以最有效地提高分类器的性能。研究人员探索了真实数据(RD)和生成数据(GD)不同比例对分类性能的影响,并证明增强效果不随GD的大小而增加(Zhang et al., 2020)。
使用人工数据研究不同训练数据量对分类性能的影响表明,性能的提高至少需要GD的两倍大小(Zhang and Liu, 2018)。因此,GD的大小应通过不同配合比的多组试验来确定。
基于以上分析,我们认为以下研究值得在进一步研究中进行探索。首先,可以结合不同的DA方法对数据集进行扩展,并在输入空间和特征空间进行增强。例如,基于GT生成的数据可以放入GANs中进行二次增强,可以提高生成数据的多样性。其次,将元学习与数据增强相结合可能会揭示DA影响分类任务的原因,这可能会提高生成数据的可解释性。
同时,基于GAN的DA是目前的主流方法,但如何提高生成数据的质量仍然是一个有价值的点。
结论
由于可用对象、实验时间和操作复杂性的限制,收集大规模EEG数据集是一项艰巨的任务。数据增强已被证明是一种有前途的方法,以避免过拟合和提高dnn的性能。因此,本文讨论了基于dnn的脑电解码DA的研究现状。本文对近5年来的最新研究进行了讨论和分析。
基于他们的结果分析,我们可以得出结论,DA能够有效地提高EEG解码任务的性能。本文介绍了当前的实际建议和性能结果。它可以为脑电图研究提供指导和帮助,帮助该领域产生高质量、可重复的结果。