本实验为生物信息课程专题实验的一个小项目。数据集为私有的EEG脑电信号。实现基于机器学习的脑电信号抑郁症病人的识别分类。
目录
1 加载需要的库函数
2 加载需要的数据
3 数据特征预处理和文本特征转换
4 数据编码
5 数据集分割
6 使用KNN进行数据分类
7 对训练模型进行评价
1 加载需要的库函数
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import seaborn as sb
2 加载需要的数据
data = pd.read_csv('/eeg-psychiatric-disorders-dataset/EEG.machinelearing_data_BRMH.csv')
data.head()3 数据特征预处理和文本特征转换
print("Data Shape:",data.shape)print("Data Description: \n")
data.describe()data.isnull().sum()data.education.isnulldata.education.isnull().sum()data.IQdata.IQ.isnull()data.IQ.isnull().sum()data.drop(["no.", "age", "eeg.date","education", "IQ"], axis=1, inplace =True)
data.head()data.drop(["sex"], axis=1,inplace= True)
data.head()data.rename(columns={"main.disorder":"main_disorder"}, inplace = True)
data.rename(columns={"specific.disorder":"specific_disorder"}, inplace = True)
data.head()features_with_null=list(data.columns[data.isna().any()])
len(features_with_null)features_with_null=list(data.columns[data.isna().any()])
len(features_with_null)main_disorders = list(data.main_disorder.unique())
main_disordersspecific_disoders = list(data.specific_disorder.unique())
specific_disodersmood_data = data.loc[data['main_disorder'] == 'Mood disorder']
mood_data.head()main_disorderstest = list(mood_data.main_disorder.unique())
main_disorderstestspecific_mood_disoders = list(mood_data.specific_disorder.unique())
specific_mood_disoders
4 数据编码
from sklearn import preprocessing
pre_processing=preprocessing.LabelEncoder()
specific_disoders_encoding = pre_processing.fit_transform(mood_data["specific_disorder"])features=["main_disorder" , "specific_disorder"]
mood_data.drop(features, axis=1, inplace=True)mood_data.head()features=mood_data.to_numpy()
features# Target:
y = specific_disoders_encoding
#specify:
X = preprocessing.StandardScaler().fit_transform(features)delta_cols = [col for col in mood_data.columns if 'delta' in col]
beta_cols = [col for col in mood_data.columns if 'beta' in col]
theta_cols = [col for col in mood_data.columns if 'theta' in col]
alpha_cols = [col for col in mood_data.columns if 'alpha' in col]print(f"Number of Delta Columns : {len(delta_cols)}")
print(f"Number of Beta Columns : {len(beta_cols)}")
print(f"Number of Theta Columns : {len(theta_cols)}")
print(f"Number of Alpha Columns : {len(alpha_cols)}")
temp_features = delta_cols + beta_cols +theta_cols + alpha_cols
print(f"Number of items in temp_features : {len(temp_features)}")
req_features = mood_data[temp_features].to_numpy()
# the target
y = specific_disoders_encoding
#the features
X = preprocessing.StandardScaler().fit_transform(req_features)5 数据集分割
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 0.3)6 使用KNN进行数据分类
from sklearn.neighbors import KNeighborsClassifier
knn_model = KNeighborsClassifier(n_neighbors = 5)
knn_model.fit(X_train,y_train)
y_pred = knn_model.predict(X_test)
y_pred7 对训练模型进行评价
from sklearn import metrics
print("Accuracy is",metrics.accuracy_score(y_test,y_pred)," when k = 3")
print("Accuracy is",metrics.accuracy_score(y_test,y_pred)," when k = 5")
print("Accuracy is",metrics.accuracy_score(y_test,y_pred)," when k = 7")
from sklearn.metrics import classification_report
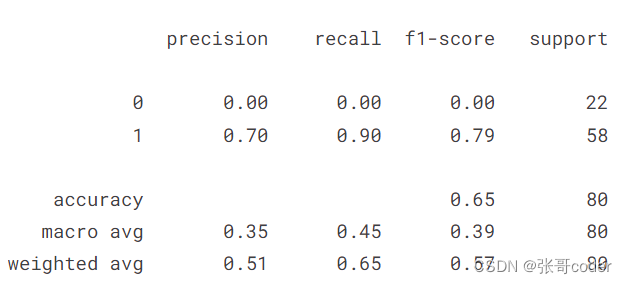
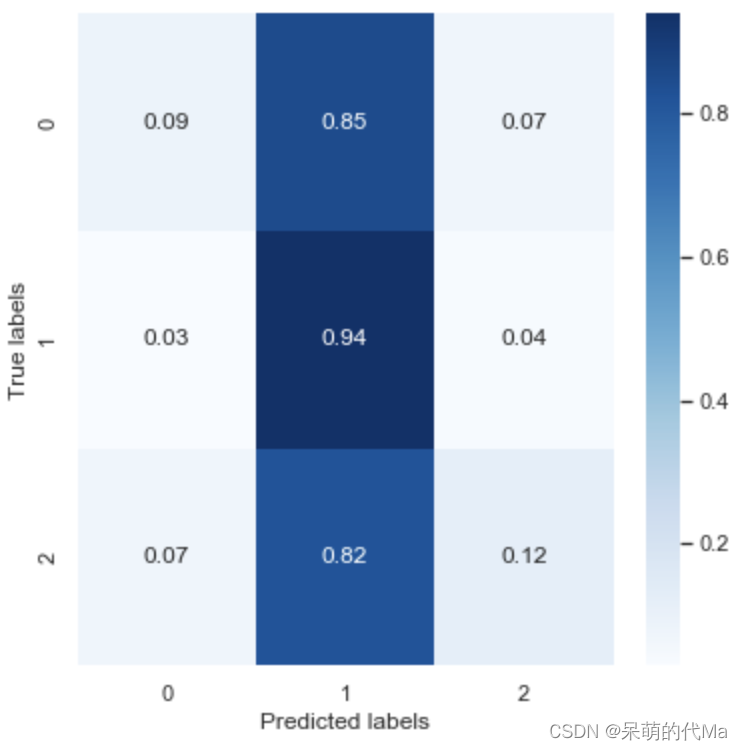
print(classification_report(y_test,y_pred))