一、概述
首先要看TCP/IP协议,涉及到四层:链路层,网络层,传输层,应用层。
其中以太网(Ethernet)的数据帧在链路层
IP包在网络层
TCP或UDP包在传输层
TCP或UDP中的数据(Data)在应用层
它们的关系是 数据帧{IP包{TCP或UDP包{Data}}}
不同的协议层对数据包有不同的称谓,在传输层叫做段(segment),在网络层叫做数据报(datagram),在链路层叫做帧(frame)。数据封装成帧后发到传输介质上,到达目的主机后每层协议再剥掉相应的首部,最后将应用层数据交给应用程序处理。
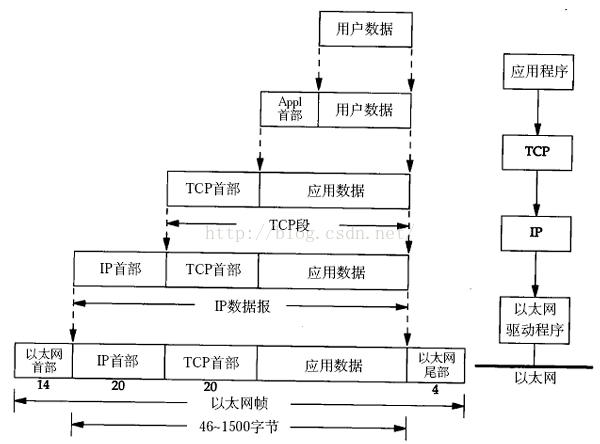
在应用程序中我们用到的Data的长度最大是多少,直接取决于底层的限制。
我们从下到上分析一下:
1.在链路层,由以太网的物理特性决定了数据帧的长度为(46+18)-(1500+18),其中的18是数据帧的头和尾,也就是说数据帧的内容最大为1500(不包括帧头和帧尾),即MTU(Maximum Transmission Unit)为1500;
2.在网络层,因为IP包的首部要占用20字节,所以这的MTU为1500-20=1480;
3.在传输层,对于UDP包的首部要占用8字节,所以这的MTU为1480-8=1472;
所以,在应用层,你的Data最大长度为1472。当我们的UDP包中的数据多于MTU(1472)时,发送方的IP层需要分片fragmentation进行传输,而在接收方IP层则需要进行数据报重组,由于UDP是不可靠的传输协议,如果分片丢失导致重组失败,将导致UDP数据包被丢弃。
从上面的分析来看,在普通的局域网环境下,UDP的数据最大为1472字节最好(避免分片重组)。
但在网络编程中,Internet中的路由器可能有设置成不同的值(小于默认值),Internet上的标准MTU值为576,所以Internet的UDP编程时数据长度最好在576-20-8=548字节以内。
二、TCP、UDP数据包最大值的确定
UDP和TCP协议利用端口号实现多项应用同时发送和接收数据。数据通过源端口发送出去,通过目标端口接收。有的网络应用只能使用预留或注册的静态端口;而另外一些网络应用则可以使用未被注册的动态端口。因为UDP和TCP报头使用两个字节存放端口号,所以端口号的有效范围是从0到65535。动态端口的范围是从1024到65535。
MTU最大传输单元,这个最大传输单元实际上和链路层协议有着密切的关系,EthernetII帧的结构DMAC+SMAC+Type+Data+CRC由于以太网传输电气方面的限制,每个以太网帧都有最小的大小64Bytes最大不能超过1518Bytes,对于小于或者大于这个限制的以太网帧我们都可以视之为错误的数据帧,一般的以太网转发设备会丢弃这些数据帧。
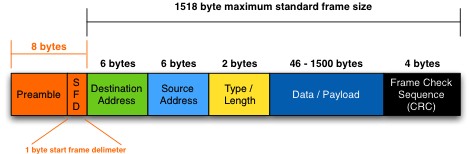
由于以太网EthernetII最大的数据帧是1518Bytes这样,刨去以太网帧的帧头(DMAC目的MAC地址48bits=6Bytes+SMAC源MAC地址48bits=6Bytes+Type域2Bytes)14Bytes和帧尾CRC校验部分4Bytes那么剩下承载上层协议的地方也就是Data域最大就只能有1500Bytes这个值我们就把它称之为MTU。
UDP 包的大小就应该是 1500 - IP头(20) - UDP头(8) = 1472(Bytes)
TCP 包的大小就应该是 1500 - IP头(20) - TCP头(20) = 1460 (Bytes)
注*PPPoE所谓PPPoE就是在以太网上面跑“PPP”。随着宽带接入(这种宽带接入一般为Cable Modem或者xDSL或者以太网的接入),因为以太网缺乏认证计费机制而传统运营商是通过PPP协议来对拨号等接入服务进行认证计费的,所以引入PPPoE。PPPoE导致MTU变小了以太网的MTU是1500,再减去PPP的包头包尾的开销(8Bytes),就变成1492。不过目前大多数的路由设备的MTU都为1500。
如果我们定义的TCP和UDP包没有超过范围,那么我们的包在IP层就不用分包了,这样传输过程中就避免了在IP层组包发生的错误;如果超过范围,既IP数据报大于1500字节,发送方IP层就需要将数据包分成若干片,而接收方IP层就需要进行数据报的重组。更严重的是,如果使用UDP协议,当IP层组包发生错误,那么包就会被丢弃。接收方无法重组数据报,将导致丢弃整个IP数据报。UDP不保证可靠传输;但是TCP发生组包错误时,该包会被重传,保证可靠传输。
UDP数据报的长度是指包括报头和数据部分在内的总字节数,其中报头长度固定,数据部分可变。数据报的最大长度根据操作环境的不同而各异。从理论上说,包含报头在内的数据报的最大长度为65535字节(64K)。
我们在用Socket编程时,UDP协议要求包小于64K。TCP没有限定,TCP包头中就没有“包长度”字段,而完全依靠IP层去处理分帧。这就是为什么TCP常常被称作一种“流协议”的原因,开发者在使用TCP服务的时候,不必去关心数据包的大小,只需讲SOCKET看作一条数据流的入口,往里面放数据就是了,TCP协议本身会进行拥塞/流量控制。
不过鉴于Internet(非局域网)上的标准MTU值为576字节,所以建议在进行Internet的UDP编程时,最好将UDP的数据长度控制在548字节 (576-8-20)以内。
三、TCP、UDP数据包最小值的确定
在用UDP局域网通信时,经常发生“Hello World”来进行测试,但是“Hello World”并不满足最小有效数据(64-46)的要求,为什么小于18个字节,对方仍然可用收到呢?因为在链路层的MAC子层中会进行数据补齐,不足18个字节的用0补齐。但当服务器在公网,客户端在内网,发生小于18个字节的数据,就会出现接收端收不到数据的情况。
以太网EthernetII规定,以太网帧数据域部分最小为46字节,也就是以太网帧最小是6+6+2+46+4=64。除去4个字节的FCS,因此,抓包时就是60字节。当数据字段的长度小于46字节时,MAC子层就会在数据字段的后面填充以满足数据帧长不小于64字节。由于填充数据是由MAC子层负责,也就是设备驱动程序。不同的抓包程序和设备驱动程序所处的优先层次可能不同,抓包程序的优先级可能比设备驱动程序更高,也就是说,我们的抓包程序可能在设备驱动程序还没有填充不到64字节的帧的时候,抓包程序已经捕获了数据。因此不同的抓包工具抓到的数据帧的大小可能不同。下列是本人分别用wireshark和sniffer抓包的结果,对于TCP 的ACK确认帧的大小一个是54字节,一个是60字节,wireshark抓取时没有填充数据段,sniffer抓取时有填充数据段。
四、实际应用
用UDP协议发送时,用sendto函数最大能发送数据的长度为:65535- IP头(20) - UDP头(8)=65507字节。用sendto函数发送数据时,如果发送数据长度大于该值,则函数会返回错误。
用TCP协议发送时,由于TCP是数据流协议,因此不存在包大小的限制(暂不考虑缓冲区的大小),这是指在用send函数时,数据长度参数不受限制。而实际上,所指定的这段数据并不一定会一次性发送出去,如果这段数据比较长,会被分段发送,如果比较短,可能会等待和下一次数据一起发送。
参考链接:http://blog.csdn.net/yaopeng_2005/article/details/6706739
参考链接:http://blog.csdn.net/naturebe/article/details/6712153
原创不易,转载请标明出处:https://blog.csdn.net/caoshangpa/article/details/51530685