本篇论文实际上是对上一篇论文的优化(seq2BF),使用关键词作为软约束,即关键词不一定出现在生成文本中。
一、模型框架
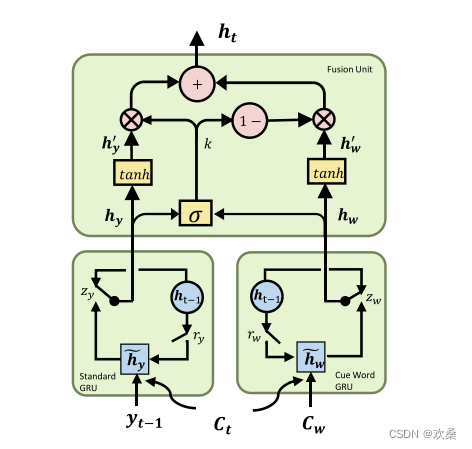
本框架有三个部分组成:标准GRU;提示词GRU和融合单元。(标准GRU和提示词GRU不共享信息,标准GRU操作一个一般的解码过程,提示词GRU模仿这个过程,但将预测的提示词作为当前输入。 对于融合单元,它结合标准GRU和提示字GRU的隐藏状态以生成当前输出字。 实验结果证明了该方法的有效性。)
GRU(Gate Recurrent Unit)和LSTM(Long-Short Term Memory)一样,是循环神经网络(Recurrent Neural Network, RNN)的一种。目的为了解决长期记忆和反向传播中的梯度等问题而提出来的。
实际上GRU和LSTM的效果差别不大,但是GRU更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
本篇论文引入线索词作为生成过程中的附加信息。 关键点在于如何纳入此类信息。 目前常用的方法之一是通过多种门控机制对神经细胞进行修饰。 然而,这些方法都是专门为特定的场景设计的,当它们被用于其他任务时,效果并不像预期的那样好。 为了解决这个问题,我们提出了另一个独立的神经细胞–线索词GRU来处理辅助信息。 由于这种神经细胞可以很容易地被其他单元替换,因此极大地提高了灵活性和可重用性
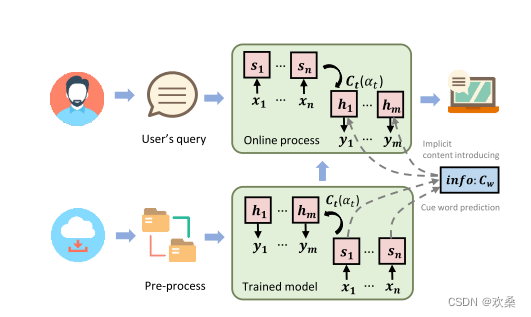
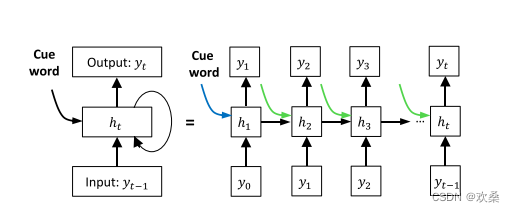
本地信息初始化由蓝色表示,全局信息初始化包括蓝色箭头和绿色箭头。
第一步预测关键字;第二步将提示词纳入解码过程,各自生成响应。
该模型设计了cue word gru单元,将关键词信息加入到每一步的状态更新。利用设计的fusion unit结构融合普通的GRU和cue word gru单元。关键词的选取与Seq2BF一样都是用PMI来计算。
注意此模型与Seq2BF的区别,该模型是把cue word的信息融合进了每次的循环,而不是像Seq2BF一样使用将cue word插入到forward阶段保证了cue word一定出现。
rGRU和SCGRU通过门控机制整合额外的信息,而SLGD和FGRU直接将信息融合到神经网络的的各个门中。(rGRU和SCGRU都是专门设计的门,对标准神经网络进行扩充来控制提示词但是结果相差很大,)
新知
作者在最后提到了矩形脉冲,矩形脉冲也是相关性的一个重要表现,表示融合单元的K门是如何平衡了Hy和Hw的影响的。信号是一种离散信号,形状多种多样,与普通模拟信号(如正弦波)相比,波形之间在时间轴不连续(波形与波形之间有明显的间隔)但具有一定的周期性是它的特点。最常见的脉冲波是矩形波(也就是方波)。脉冲信号可以用来表示信息,也可以用来作为载波,比如脉冲调制中的脉冲编码调制(PCM),脉冲宽度调制(PWM)等等,还可以作为各种数字电路、高性能芯片的时钟信号。
总结
**优点:**将cue word加入到了每一步的循环,有利于信息的充分利用
**缺点:**软约束导致cue word并不一定出现了生成文本,导致漏翻;仍然只适用于短文本;cue word选择不好,结果也可能不流畅