特征
🌍 中文支持普通话并测试了多个数据集:aidatatang_200zh、magicdata、aishell3、data_aishell等。
🤩 PyTorch为 pytorch 工作,在 1.9.0 版本中测试(最新于 2021 年 8 月),GPU Tesla T4 和 GTX 2060
🌍 Windows + Linux在 Windows 操作系统和 linux 操作系统中运行(甚至在 M1 MACOS 中)
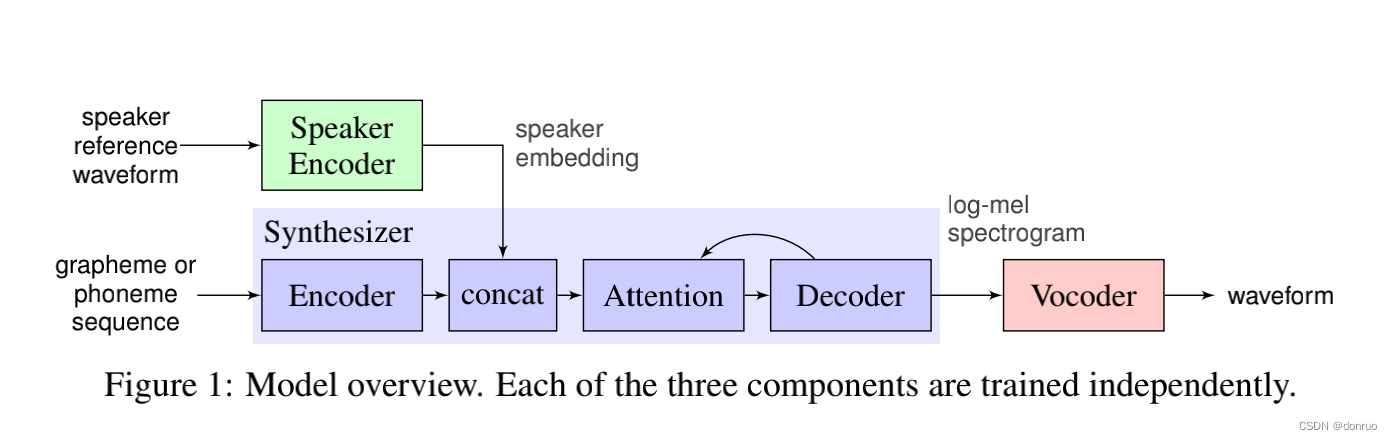
🤩 通过重用预训练的编码器/声码器,只需新训练的合成器即可获得简单而令人敬畏的效果
🌍 网络服务器准备好通过远程调用为您提供结果
进行中的工作
- GUI/客户端大升级与合并 [X] 初始化框架
./mkgui(基于streamlit + fastapi)和 技术设计 [X] 增加 Voice Cloning and Conversion的演示页面 [X] 增加Voice Conversion的预处理preprocessing 和训练 training 页面 [ ] 增加其他的的预处理preprocessing 和训练 training 页面 - 模型后端基于ESPnet2升级
1. 安装要求
按照原始存储库测试您是否已准备好所有环境。 运行工具箱(demo_toolbox.py)需要 Python 3.7 或更高版本 。
- 安装 PyTorch。
如果在用 pip 方式安装的时候出现
ERROR: Could not find a version that satisfies the requirement torch==1.9.0+cu102 (from versions: 0.1.2, 0.1.2.post1, 0.1.2.post2)这个错误可能是 python 版本过低,3.9 可以安装成功
- 安装 ffmpeg。
- 运行
pip install -r requirements.txt来安装剩余的必要包。 - 安装 webrtcvad
pip install webrtcvad-wheels。
2. 准备预训练模型
考虑训练您自己专属的模型或者下载社区他人训练好的模型:
2.1 使用数据集自己训练encoder模型 (可选)
- 进行音频和梅尔频谱图预处理:
python encoder_preprocess.py <datasets_root>使用-d {dataset}指定数据集,支持 librispeech_other,voxceleb1,aidatatang_200zh,使用逗号分割处理多数据集。 - 训练encoder:
python encoder_train.py my_run <datasets_root>/SV2TTS/encoder
训练encoder使用了visdom。你可以加上
-no_visdom禁用visdom,但是有可视化会更好。在单独的命令行/进程中运行"visdom"来启动visdom服务器。
2.2 使用数据集自己训练合成器模型(与2.3二选一)
- 下载 数据集并解压:确保您可以访问 train 文件夹中的所有音频文件(如.wav)
- 进行音频和梅尔频谱图预处理:
python pre.py <datasets_root> -d {dataset} -n {number}可传入参数: -d {dataset}指定数据集,支持 aidatatang_200zh, magicdata, aishell3, data_aishell, 不传默认为aidatatang_200zh-n {number}指定并行数,CPU 11770k + 32GB实测10没有问题
假如你下载的
aidatatang_200zh文件放在D盘,train文件路径为D:\data\aidatatang_200zh\corpus\train, 你的datasets_root就是D:\data\
-
训练合成器:
python synthesizer_train.py mandarin <datasets_root>/SV2TTS/synthesizer -
当您在训练文件夹 synthesizer/saved_models/ 中看到注意线显示和损失满足您的需要时,请转到
启动程序一步。
2.3使用社区预先训练好的合成器(与2.2二选一)
当实在没有设备或者不想慢慢调试,可以使用社区贡献的模型(欢迎持续分享):
| 作者 | 下载链接 | 效果预览 | 信息 |
|---|---|---|---|
| 作者 | 百度网盘 请输入提取码 百度盘链接 4j5d | 75k steps 用3个开源数据集混合训练 | |
| 作者 | 百度网盘 请输入提取码 百度盘链接 提取码:om7f | 25k steps 用3个开源数据集混合训练, 切换到tag v0.0.1使用 | |
| @FawenYo | https://drive.google.com/file/d/1H-YGOUHpmqKxJ9FRc6vAjPuqQki24UbC/view?usp=sharing 百度盘链接 提取码:1024 | 输入 输出 | 200k steps 台湾口音需切换到tag v0.0.1使用 |
| @miven | 百度网盘 请输入提取码 提取码:2021 | AI声音模仿,5秒钟克隆你的语音_哔哩哔哩_bilibili | 150k steps 注意:根据issue修复 并切换到tag v0.0.1使用 |
2.4训练声码器 (可选)
对效果影响不大,已经预置3款,如果希望自己训练可以参考以下命令。
- 预处理数据:
python vocoder_preprocess.py <datasets_root> -m <synthesizer_model_path>
<datasets_root>替换为你的数据集目录,<synthesizer_model_path>替换为一个你最好的synthesizer模型目录,例如 sythensizer\saved_models\xxx
- 训练wavernn声码器:
python vocoder_train.py <trainid> <datasets_root>
<trainid>替换为你想要的标识,同一标识再次训练时会延续原模型
- 训练hifigan声码器:
python vocoder_train.py <trainid> <datasets_root> hifigan
<trainid>替换为你想要的标识,同一标识再次训练时会延续原模型
- 训练fregan声码器:
python vocoder_train.py <trainid> <datasets_root> --config config.json fregan
<trainid>替换为你想要的标识,同一标识再次训练时会延续原模型
- 将GAN声码器的训练切换为多GPU模式:修改GAN文件夹下.json文件中的"num_gpus"参数
3. 启动程序或工具箱
您可以尝试使用以下命令:
3.1 启动Web程序(v2):
python web.py 运行成功后在浏览器打开地址, 默认为 http://localhost:8080
- 仅支持手动新录音(16khz), 不支持超过4MB的录音,最佳长度在5~15秒
3.2 启动工具箱:
python demo_toolbox.py -d <datasets_root>
请指定一个可用的数据集文件路径,如果有支持的数据集则会自动加载供调试,也同时会作为手动录制音频的存储目录。
4. 番外:语音转换Voice Conversion(PPG based)
想像柯南拿着变声器然后发出毛利小五郎的声音吗?本项目现基于PPG-VC,引入额外两个模块(PPG extractor + PPG2Mel), 可以实现变声功能。(文档不全,尤其是训练部分,正在努力补充中)
4.0 准备环境
- 确保项目以上环境已经安装ok,运行
pip install espnet来安装剩余的必要包。 - 下载以下模型 链接:百度网盘 请输入提取码 提取码:gh41
- 24K采样率专用的vocoder(hifigan)到 vocoder\saved_models\xxx
- 预训练的ppg特征encoder(ppg_extractor)到 ppg_extractor\saved_models\xxx
- 预训练的PPG2Mel到 ppg2mel\saved_models\xxx
4.1 使用数据集自己训练PPG2Mel模型 (可选)
- 下载aidatatang_200zh数据集并解压:确保您可以访问 train 文件夹中的所有音频文件(如.wav)
- 进行音频和梅尔频谱图预处理:
python pre4ppg.py <datasets_root> -d {dataset} -n {number}可传入参数: -d {dataset}指定数据集,支持 aidatatang_200zh, 不传默认为aidatatang_200zh-n {number}指定并行数,CPU 11700k在8的情况下,需要运行12到18小时!待优化
假如你下载的
aidatatang_200zh文件放在D盘,train文件路径为D:\data\aidatatang_200zh\corpus\train, 你的datasets_root就是D:\data\
- 训练合成器, 注意在上一步先下载好
ppg2mel.yaml, 修改里面的地址指向预训练好的文件夹:python ppg2mel_train.py --config .\ppg2mel\saved_models\ppg2mel.yaml --oneshotvc - 如果想要继续上一次的训练,可以通过
--load .\ppg2mel\saved_models\<old_pt_file>参数指定一个预训练模型文件。
4.2 启动工具箱VC模式
您可以尝试使用以下命令: python demo_toolbox.py -vc -d <datasets_root>
请指定一个可用的数据集文件路径,如果有支持的数据集则会自动加载供调试,也同时会作为手动录制音频的存储目录。
引用及论文
该库一开始从仅支持英语的Real-Time-Voice-Cloning 分叉出来的,鸣谢作者。
| 网址 | 指定 | 标题 | 实现源码 |
|---|---|---|---|
| 1803.09017 | GlobalStyleToken(合成器) | 风格令牌:端到端语音合成中的无监督风格建模、控制和转移 | 本代码库 |
| 2010.05646 | HiFi-GAN(声码器) | 用于高效和高保真语音合成的生成对抗网络 | 本代码库 |
| 2106.02297 | Fre-GAN(声码器) | Fre-GAN:对抗频率一致的音频合成 | 本代码库 |
| 1806.04558 | SV2TTS | 将学习从说话人验证转移到多说话人文本到语音合成 | 本代码库 |
| 1802.08435 | WaveRNN(声码器) | 高效的神经音频合成 | fatchord/WaveRNN |
| 1703.10135 | Tacotron(合成器) | Tacotron:走向端到端语音合成 | fatchord/WaveRNN |
| 1710.10467 | GE2E(编码器) | 说话人验证的广义端到端损失 | 本代码库 |
常见问题(FQ&A)
1.数据集在哪里下载?
| 数据集 | OpenSLR地址 | 其他源 (Google Drive, Baidu网盘等) |
|---|---|---|
| helptang_200zh | 开放式单反 | 谷歌云端硬盘 |
| 魔术数据 | 开放式单反 | 谷歌云端硬盘(开发集) |
| 爱壳3 | 开放式单反 | 谷歌云端硬盘 |
| data_aishell | 开放式单反 |
解压 aidatatang_200zh 后,还需将
aidatatang_200zh\corpus\train下的文件全选解压缩
2.<datasets_root>是什麼意思?
假如数据集路径为 D:\data\aidatatang_200zh,那么 <datasets_root>就是 D:\data
3.训练模型显存不足
训练合成器时:将 synthesizer/hparams.py中的batch_size参数调小
//调整前
tts_schedule = [(2, 1e-3, 20_000, 12), # Progressive training schedule(2, 5e-4, 40_000, 12), # (r, lr, step, batch_size)(2, 2e-4, 80_000, 12), #(2, 1e-4, 160_000, 12), # r = reduction factor (# of mel frames(2, 3e-5, 320_000, 12), # synthesized for each decoder iteration)(2, 1e-5, 640_000, 12)], # lr = learning rate
//调整后
tts_schedule = [(2, 1e-3, 20_000, 8), # Progressive training schedule(2, 5e-4, 40_000, 8), # (r, lr, step, batch_size)(2, 2e-4, 80_000, 8), #(2, 1e-4, 160_000, 8), # r = reduction factor (# of mel frames(2, 3e-5, 320_000, 8), # synthesized for each decoder iteration)(2, 1e-5, 640_000, 8)], # lr = learning rate
声码器-预处理数据集时:将 synthesizer/hparams.py中的batch_size参数调小
//调整前
### Data Preprocessingmax_mel_frames = 900,rescale = True,rescaling_max = 0.9,synthesis_batch_size = 16, # For vocoder preprocessing and inference.
//调整后
### Data Preprocessingmax_mel_frames = 900,rescale = True,rescaling_max = 0.9,synthesis_batch_size = 8, # For vocoder preprocessing and inference.
声码器-训练声码器时:将 vocoder/wavernn/hparams.py中的batch_size参数调小
//调整前
# Training
voc_batch_size = 100
voc_lr = 1e-4
voc_gen_at_checkpoint = 5
voc_pad = 2//调整后
# Training
voc_batch_size = 6
voc_lr = 1e-4
voc_gen_at_checkpoint = 5
voc_pad =2
4.碰到RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]).
请参照 issue #37
5.如何改善CPU、GPU占用率?
视情况调整batch_size参数来改善
6.发生 页面文件太小,无法完成操作
请参考这篇文章,将虚拟内存更改为100G(102400),例如:文件放置D盘就更改D盘的虚拟内存
7.什么时候算训练完成?
首先一定要出现注意力模型,其次是loss足够低,取决于硬件设备和数据集。拿本人的供参考,我的注意力是在 18k 步之后出现的,并且在 50k 步之后损失变得低于 0.4 
快速入门(新手)
快速开始 (新手友好版)
本快速开始教程是以Windows为例的,假设不做任何训练(节省几小时甚至几天时间),假设你对python等开发环境也不熟悉,也可能没有支持CUDA的GPU
安装
如果已经确认安装过,请忽略该步骤
-
拉取本代码库
-
安装Anacodna, Python 3.8 或更高,参考中文教程,在Anaconda中创建并切换到独立虚拟环境后,进行以下步骤。
-
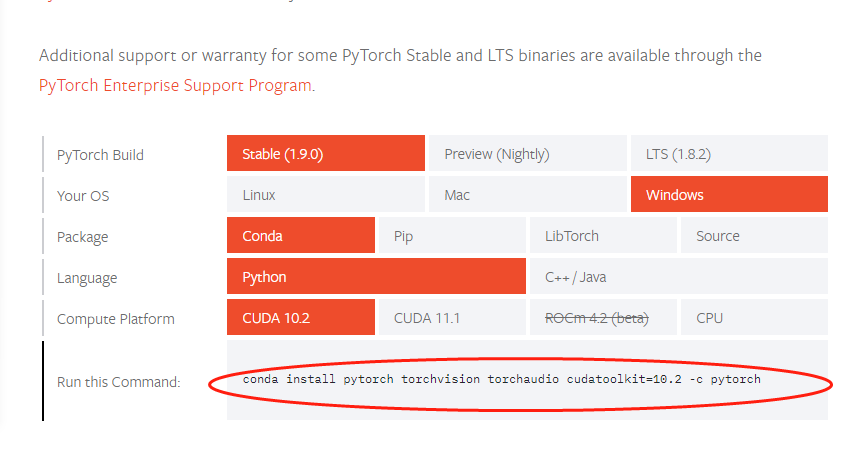
安装 PyTorch, 直接官网下载。如果GPU不支持CUDA,请默认选择。
验证本步骤是否成功:在系统任意路径下运行python,进入交互式编程界面后输入
import torch;, 回车,torch.cuda.is_available(), 回车。如果都是成功的话,可以进行下一步。
-
安装 ffmpeg。 1)下载 选择点击打开链接Windows对应的版本下载 2)解压 ffmpeg-xxxx.zip 文件到指定目录; 3)将解压后的文件目录中 bin 目录(包含 ffmpeg.exe )添加进 path 环境变量中; 4)进入 cmd,输入 ffmpeg -version,可验证当前系统是否识别 ffmpeg 以及查看 ffmpeg 的版本
-
运行pip install -r requirements.txt 来安装剩余的必要包。
确保本步骤不报错
- 安装 webrtcvad 用 pip install webrtcvad-wheels。
确保本步骤不报错
下载社区训练好的模型
在以下选择中下载模型
| 作者 | 下载链接 | 效果预览 |
|---|---|---|
| @miven | 百度网盘 请输入提取码 提取码:2021 | AI声音模仿,5秒钟克隆你的语音_哔哩哔哩_bilibili |
该模型与最新代码有兼容性问题 请查阅 用这里的模型跑出现这个RuntimeError: Error(s) in loading state_dict for Tacotron: size mismatch for encoder.embedding.weight: copying a param with shape torch.Size([70, 512]) from checkpoint, the shape in current model is torch.Size([75, 512]). · Issue #37 · babysor/MockingBird · GitHub 解决
下载完成后,确保 xxx.pt 格式的文件放在代码库的 synthesizer\saved_models文件夹下,saved_models如不存在请新建
运行demo_toolbox
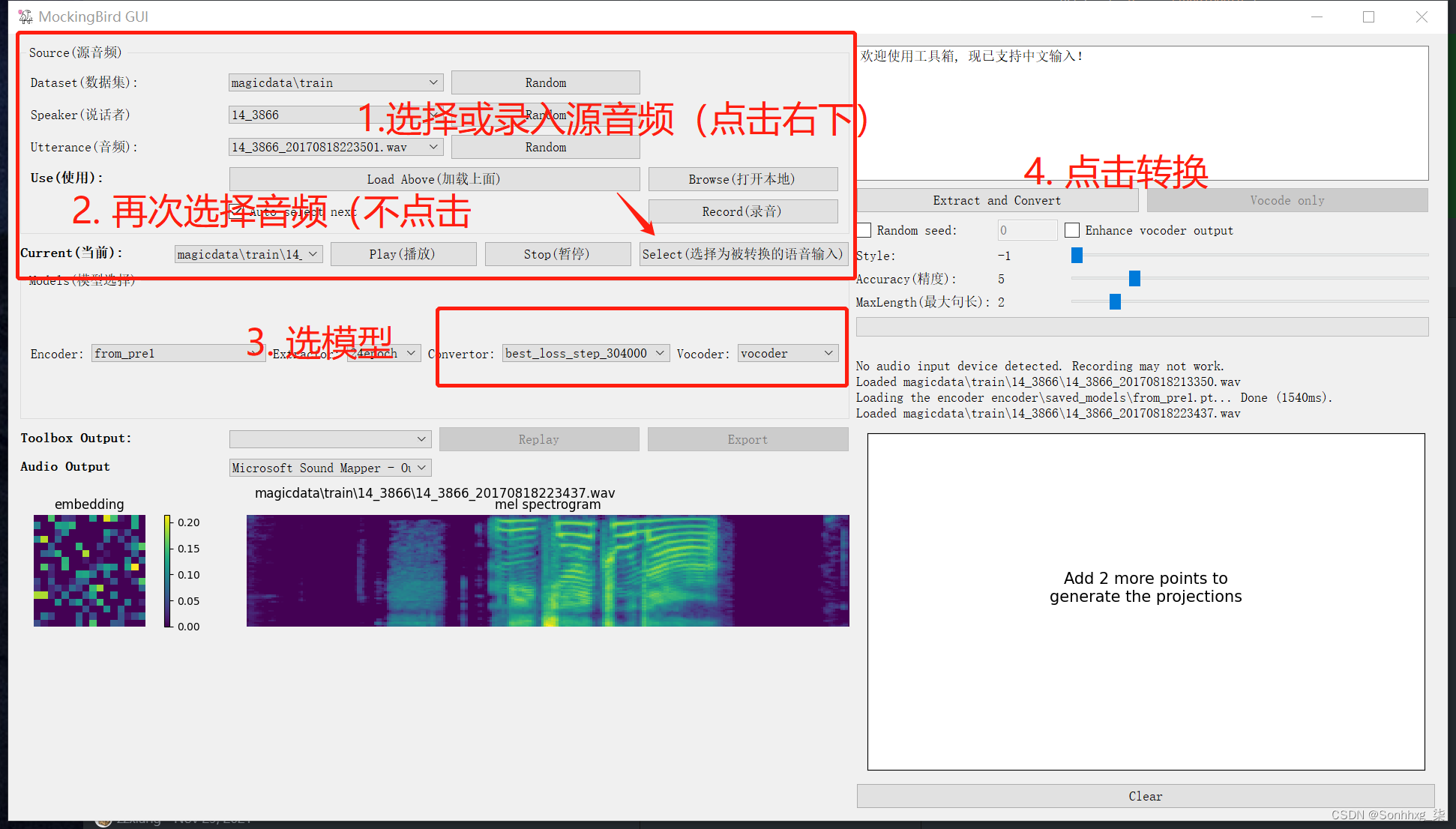
在代码库路径下,运行 python demo_toolbox.py -d .\samples 尝试使用工具箱, 由于没有下载任何数据集,这里的功能比较简单:
- 确保界面左边中间的
synthesizer选择了上一步中xxx.pt文件对应的模型。 - 点击
Record录入你的5秒语音 - 输入任意文字
- 点击
Synthesizer and vocode等待效果输出