一、准备工作
硬件部分:旭日X3派,USB免驱摄像头,电源适配器,烧录Ubuntu系统的SD卡,USB扬声器,显示屏(或者VNC/SSH远程连接)
软件部分:Thonny IDE集成开发环境

首先,关于Ubuntu系统镜像的烧录官方有详细的教程,这里不再赘述,我自己是选择桌面Ubuntu 20.04,大家选择最新的即可。如果是第一次进入系统,记得使用命令行更新一下软件源等,使用快捷键ctrl+alt+T打开命令行,输入以下命令:
# 更新软件源
apt-get update# 更新升级所有软件
apt-get upgrade接下来就可以开始安装Thonny IDE,作为一款轻量化的python集成开发环境,对新手十分友好,简单易上手,后续安装各种python依赖库也相当方便。安装方式Thonny官方网址提供了三种Linux的命令行下载方式,大家可以根据自己的情况进行选择。
flatpak install org.thonny.Thonny //Flatpaksudo apt install thonny //Debian,Raspbian,Ubuntu,Mintand otherssudo dnf install thonny //FedoraFedora耐心等待程序安装即可,如果中途出现异常大概率是网络不稳定导致,检查网络连接并再次运行命令行即可。由于Ubuntu系统不会自动生成快捷方式,所以安装成功后在命令行输入Thonny即可启动IDE。
重头戏来了,安装项目依赖库。启动Thonny IDE后,选择左上方工具>>管理包,根据附件中提供的程序开始安装python依赖库。过程可能会比较漫长,这取决于当前网络情况,还有部分库文件可能会出现下载失败的情况,请耐心多尝试几次。
import os
import threading
import cv2
import mediapipe as mp
import time
import torch as t
from model import HandModel
from tools.landmark_handle import landmark_handle
from tools.draw_landmarks import draw_landmarks
from tools.draw_bounding_rect import draw_bounding_rect
import numpy as np
from tools.draw_rect_text import draw_rect_txt
from PIL import Image, ImageFont, ImageDraw
import pyttsx3# 大家可以根据这个来添加项目依赖(PS.cv2是opencv-python的缩写,在import的时候采用这种缩写,但添加库的时候不能直接搜索cv2,而是要打全称opencv-python。)
二、实现原理
智能手语识别系统共包括语音播报模块,模型训练模块,手势识别模块,文字转写模块,一共可识别播报“也”、“吸引”、“美丽的”、 “相信”、“的”、“怀疑”、“梦想”、“表达”、“眼睛”、 “给”、“很难”、“有”、“许多”、“我”、“方法”、“不”, “只有”、“超过”、“请”、“放”、“说”、“微笑”、“星星”、“十分”、“看”、“你”等27个国家通用手语。
model_path = 'checkpoints/model_test1.pth'label = ["也", "吸引", "美丽的", "相信", "的", "怀疑", "梦想", "表达", "眼睛", "给", "很难","有","许多","我", "方法", "不", "只有", "结束", "请", "放", "说", "微信", "星星", "十分","看","你"]语音播报模块采用pyttsx3第三方库,它是一个用于文字转语音的第三方python库,还可实现对音量,声源,语速的调整,可脱机工作,兼容python2和python3。
def run():str_show = this_labelstar_date = open("2.txt", "w", encoding="utf-8")star_date.write(str_show)star_date.close()star_data = open("2.txt", "r", encoding="utf-8")star_read = star_data.readlines()star_data.close()file = "2.txt"res = open(file, encoding="utf-8").read()engine = pyttsx3.init()content = resengine.say(content)engine.runAndWait()time.sleep(1)模型训练模块采用torch第三方库,torch广泛运用深度学习。它能够帮助我们构建深度学习项目,强调灵活性,而且允许使用我们习惯的python表示方法来表达深度学习模型。算力高,易学习,比较容易入门。
# 模型保存地址
targetX = [0 for xx in range(label_num)]
target = []
for xx in range(label_num):target_this = copy.deepcopy(targetX)target_this[xx] = 1target.append(target_this)
# 独热码lr = 1e-3 # learning rate
model_saved = 'checkpoints/model'# 模型定义
model = HandModel()
optimizer = t.optim.Adam(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()loss_meter = meter.AverageValueMeter()epochs = 40
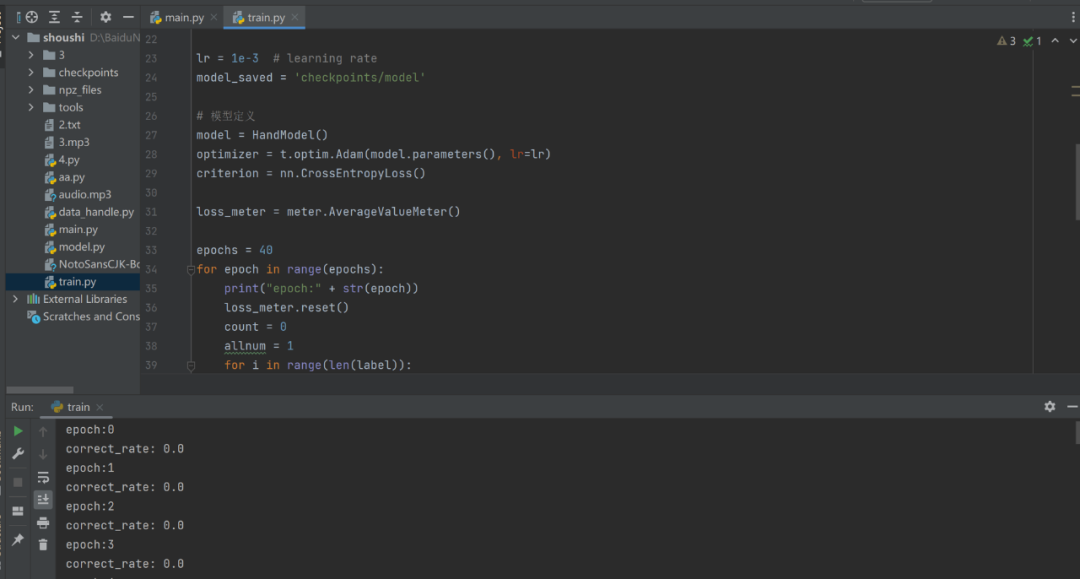
for epoch in range(epochs):print("epoch:" + str(epoch))loss_meter.reset()count = 0allnum = 1for i in range(len(label)):data = np.load('./npz_files/' + label[i] + ".npz", allow_pickle=True)data = data['data']for j in range(len(data)):xdata = t.tensor(data[j])optimizer.zero_grad()this_target = t.tensor(target[i]).float()input_, this_target = Variable(xdata), Variable(this_target)output = model(input_)outLabel = label[output.tolist().index(max(output))]targetIndex = target[i].index(1)targetLabel = label[targetIndex]if targetLabel == outLabel:count += 1allnum += 1output = t.unsqueeze(output, 0)this_target = t.unsqueeze(this_target, 0)loss = criterion(output, this_target)loss.backward()optimizer.step()loss_meter.add(loss.data)print("correct_rate:", str(count / allnum))t.save(model.state_dict(), '%s_%s.pth' % (model_saved, epoch))准备好数据集就可以开始进行模型训练,模型推荐在电脑上进行训练,我自己的电脑是win10的系统,用的pycharm IDE的集成开发环境,如果只是想体验一下的话也可以直接使用附件里训练好的模型。
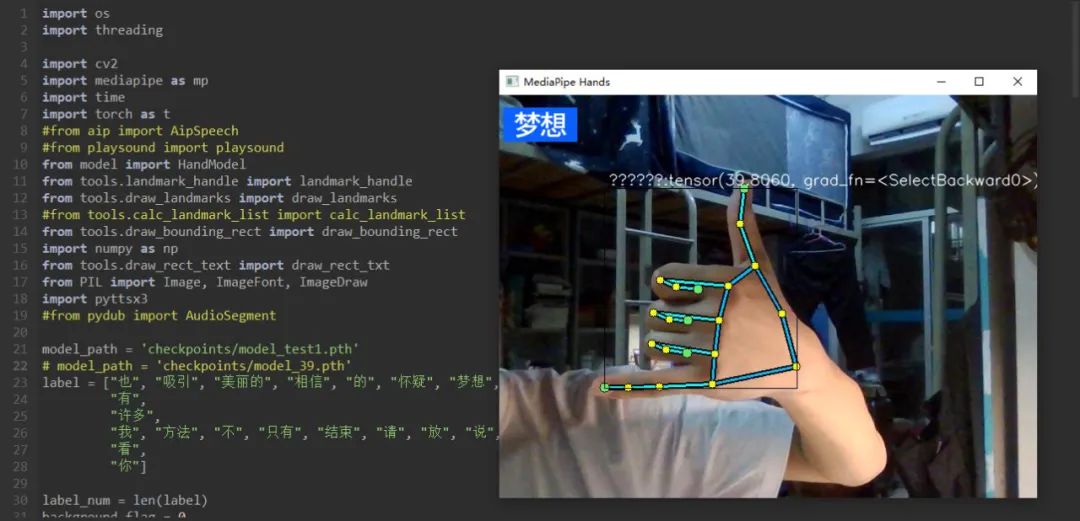
手势识别模块采用Mediapipe和OpenCV库对人手进行特征提取与骨骼绑定,旭日X3派根据摄像头捕捉的关键帧的进行特征提取,基于PyTorch模型进行推理,并将推理翻译结果显示到屏幕上,同时将翻译结果以txt文件形式进行保存和API接入后上传到百度语音开发平台,由平台进行人声的合成,然后将生成的mp3文件下载到旭日X3派终端用扬声器进行播放,实现了为语言障碍人士发声,为“碍”发声。
# 百度大脑AI开放平台API接入实现语音合成的示例def fetch_token():print("fetch token begin")params = {'grant_type': 'client_credentials','client_id': API_KEY,'client_secret': SECRET_KEY}post_data = urlencode(params)if (IS_PY3):post_data = post_data.encode('utf-8')req = Request(TOKEN_URL, post_data)try:f = urlopen(req, timeout=5)result_str = f.read()except URLError as err:print('token http response http code : ' + str(err.code))result_str = err.read()if (IS_PY3):result_str = result_str.decode()print(result_str)result = json.loads(result_str)print(result)if ('access_token' in result.keys() and 'scope' in result.keys()):if not SCOPE in result['scope'].split(' '):raise DemoError('scope is not correct')print('SUCCESS WITH TOKEN: %s ; EXPIRES IN SECONDS: %s' % (result['access_token'], result['expires_in']))return result['access_token']else:raise DemoError('MAYBE API_KEY or SECRET_KEY not correct: access_token or scope not found in token response')""" TOKEN end """if __name__ == '__main__':token = fetch_token()tex = quote_plus(TEXT) # 此处TEXT需要两次urlencodeprint(tex)params = {'tok': token, 'tex': tex, 'per': PER, 'spd': SPD, 'pit': PIT, 'vol': VOL, 'aue': AUE, 'cuid': CUID,'lan': 'zh', 'ctp': 1} # lan ctp 固定参数data = urlencode(params)print('test on Web Browser' + TTS_URL + '?' + data)req = Request(TTS_URL, data.encode('utf-8'))has_error = Falsetry:f = urlopen(req)result_str = f.read()headers = dict((name.lower(), value) for name, value in f.headers.items())has_error = ('content-type' not in headers.keys() or headers['content-type'].find('audio/') < 0)except URLError as err:print('asr http response http code : ' + str(err.code))result_str = err.read()has_error = Truesave_file = "error.txt" if has_error else 'result.' + FORMATwith open(save_file, 'wb') as of:of.write(result_str)if has_error:if (IS_PY3):result_str = str(result_str, 'utf-8')print("tts api error:" + result_str)print("result saved as :" + save_file)
# 骨架绑定的可视化draw_landmarks(frame, hand_local)
brect = draw_bounding_rect(frame, hand_local)
文字转写模块通过旭日X3派外接麦克风进行收音,API接入后将录制的mp3文件上传,通过云端语音平台实时转写为文字后显示到旭日X3派终端的屏幕上。最后利用python的多线程将手势识别,语音播报,文字转写同时运行,至此,实现了聋哑人士与普通人的双向无障碍沟通交流。
三、效果展示
得益于旭日X3派的强大算力,系统对手势的识别展示并播报十分灵敏,画面流程度也得到保障(温馨提示:长时间运行请准备小风扇给开发板降温哦)。
四、性能测试
系统测试方案:将训练好模型导入旭日X3派中,接入电源后等待初始化完成,由小组成员们随机在镜头前做出27个国家通用手语,将翻译终端识别播报的准确率记录,同时将识别的总时长记录收集。
测试数据如下:

结果分析:实验数据表明,27个国家通用手语随机检验的识别准确率均在90%以上,单次执行时间也均在1秒之内。
结论:手语翻译终端有很高的实时性,充分保障聋哑残障人士的无障碍沟通交流。
本文转自地平线开发者社区
原作者:鑫辰大海王
原链接: (完整文档及代码点击此处一键直达)








![[opcv图像处理] C/C|++将图片转换为马赛克效果](https://static.hdslb.com/mobile/img/512.png)