Loss 函数简称与全称的对应关系
| Short Name | Full Name |
|---|---|
| adv | adversial loss |
| FM | Feature Matching |
| MSD | Multi-Scale Discriminator |
| mr-STFT | Multi-resolution STFT loss |
| fmr-STFT | full band Multi-resolution STFT loss |
| smr-STFT | sub band Multi-resolution STFT loss |
| Mel | Mel-Spectrogram Loss |
| MPD | Multi-Period Discriminator |
| FB-RAWs | Filter Bank Random Window Discriminators |
csmsc 数据集上 GAN Vocoder 整体对比如下,
测试机器:1 x Tesla V100-32G 40 core Intel® Xeon® Gold 6148 CPU @ 2.40GHz
测试环境:Python 3.7.0, paddlepaddle 2.2.0
| Model | Date | Input | Generator Loss | Discriminator Loss | Need Finetune | Training Steps | Finetune Steps | Batch Size | ips (gen only) (gen + dis) | Static Model Size (gen) | RTF (GPU) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mel GAN | 9 Dec 2019 | mel | adv FM | MSD | —— | —— | —— | —— | —— | —— | —— |
| Parallel Wave GAN | 6 Feb 2020 | mel noise | adv mr-STFT | adv | No | 40W | —— | 8 | 18 10 | 5.1MB | 0.01786 |
| HiFi GAN | 23 Oct 2020 | mel | adv FM Mel | MSD MPD | Yes | 250W | no need | 16 | —— 31 | 50MB | 0.00825 |
| Multi-Band Mel GAN | 17 Nov 2020 | mel | adv fmr-STFT smr-STFT | MSD | Yes | 100W | 100W (not good enough, need to adjust parameters) | 64 | 305 148 | 8.2MB | 0.00457 |
| Style Mel GAN | 12 Feb 2021 | mel noise | adv mr-STFT | FB-RAWs | No | 150W | —— | 32 | 58 24 | —— | 0.01343 |
网络结构
Mel GAN
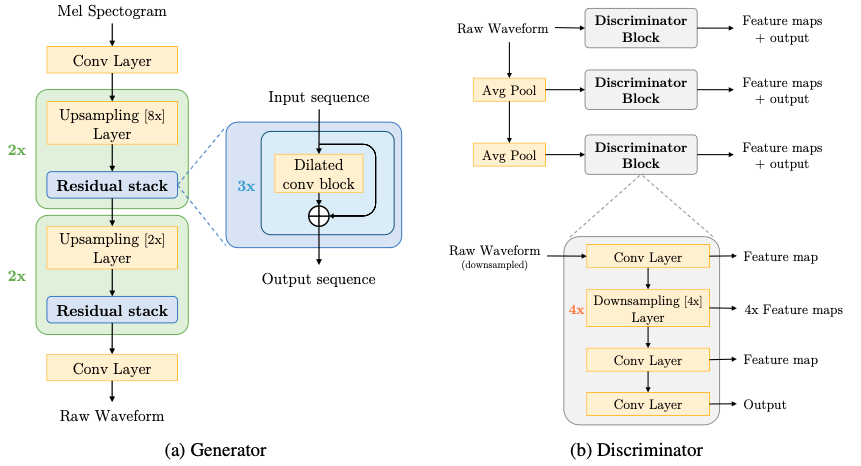
Parallel Wave GAN
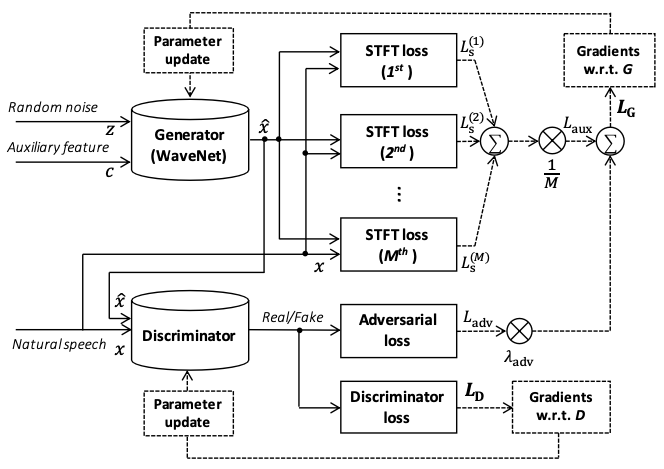
HiFi GAN
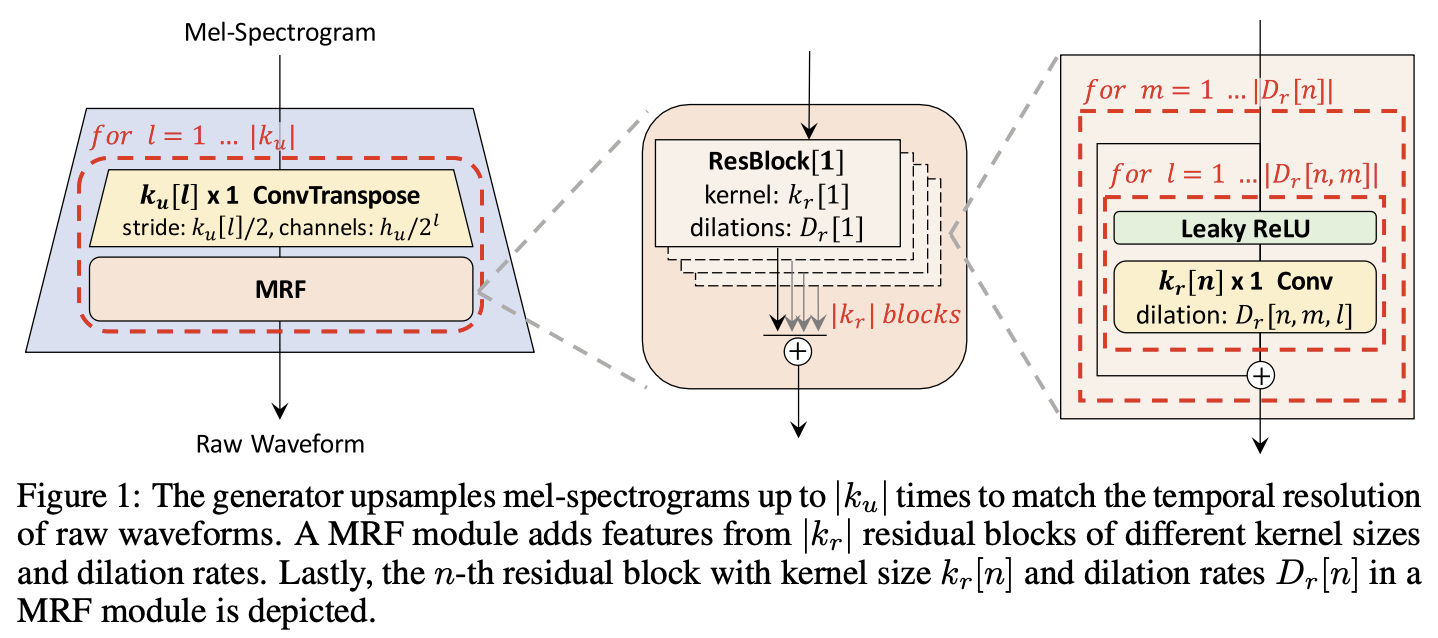
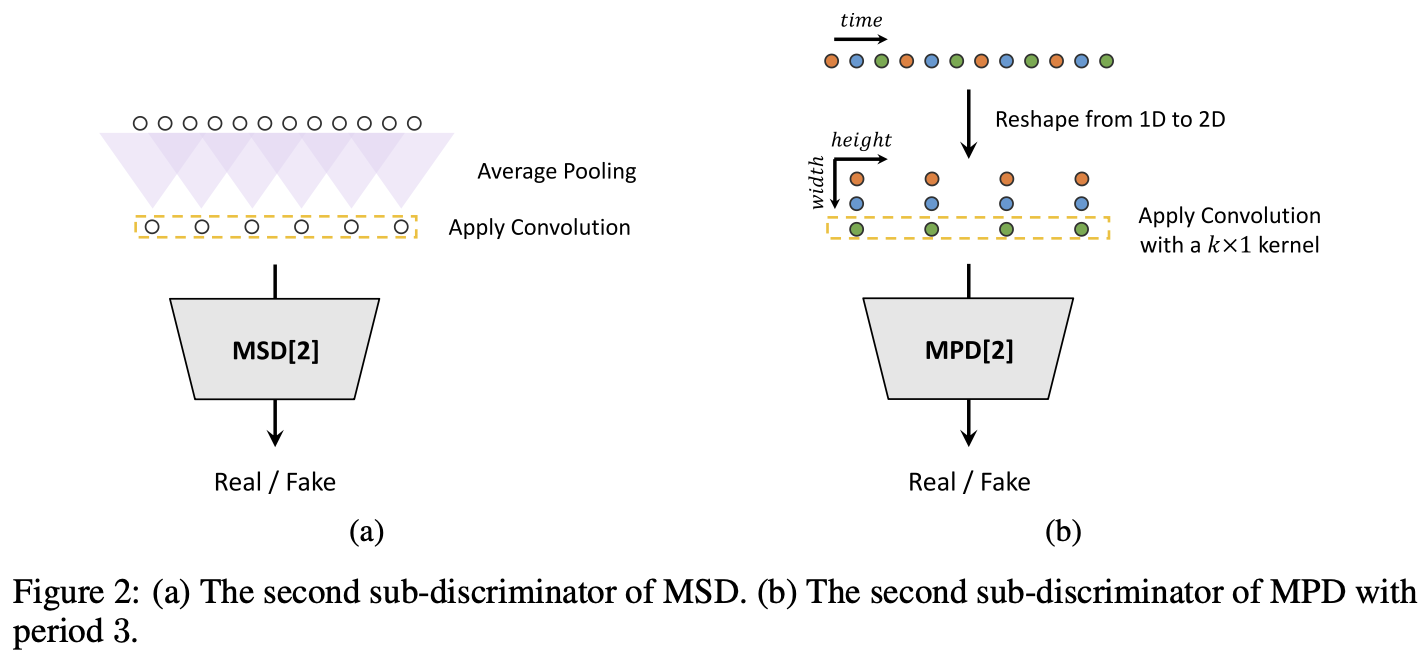
Multi-Band Mel GAN
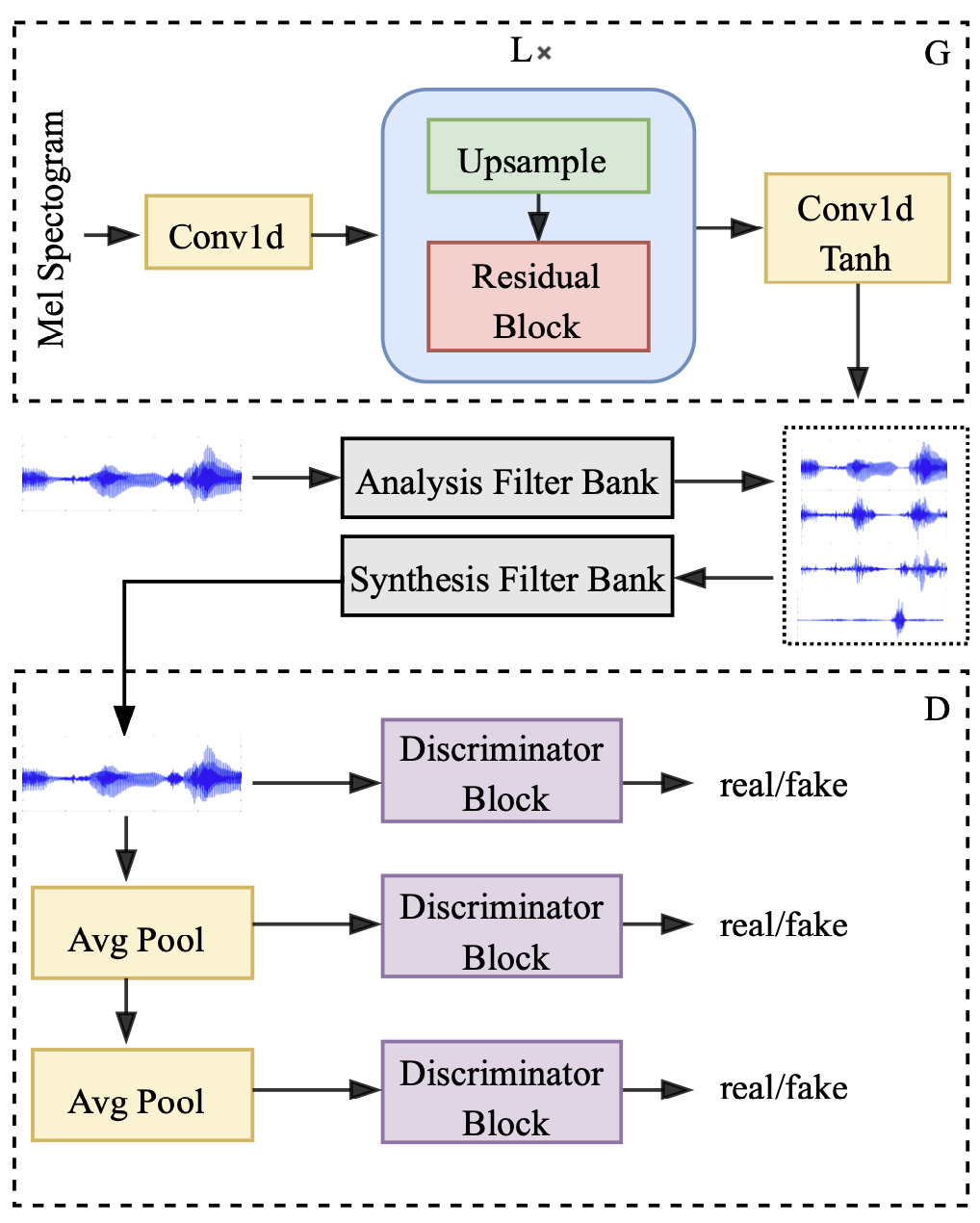
Style Mel GAN
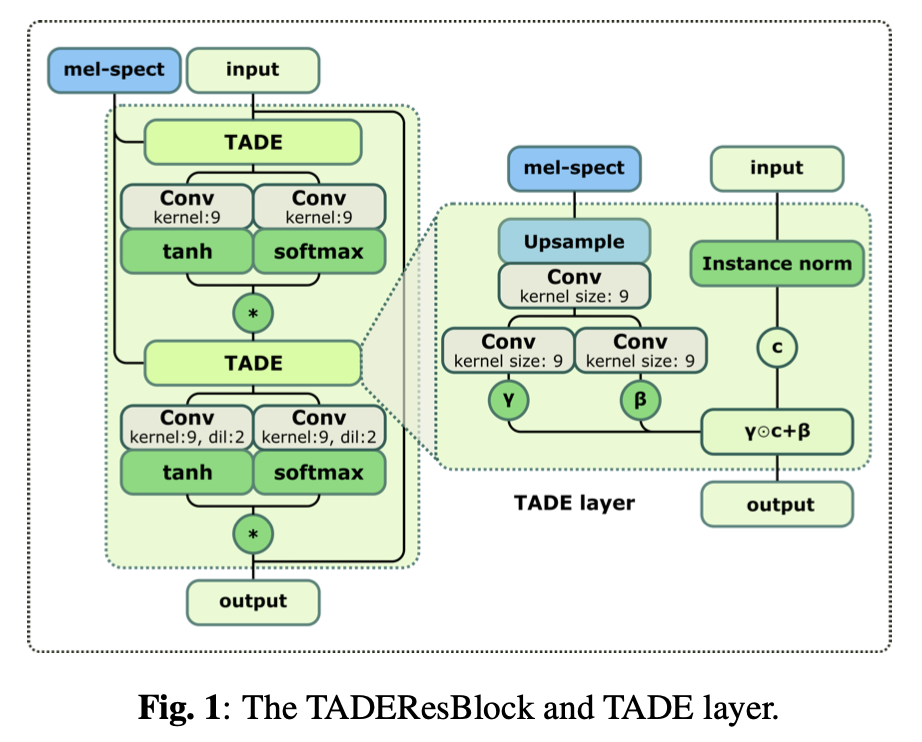
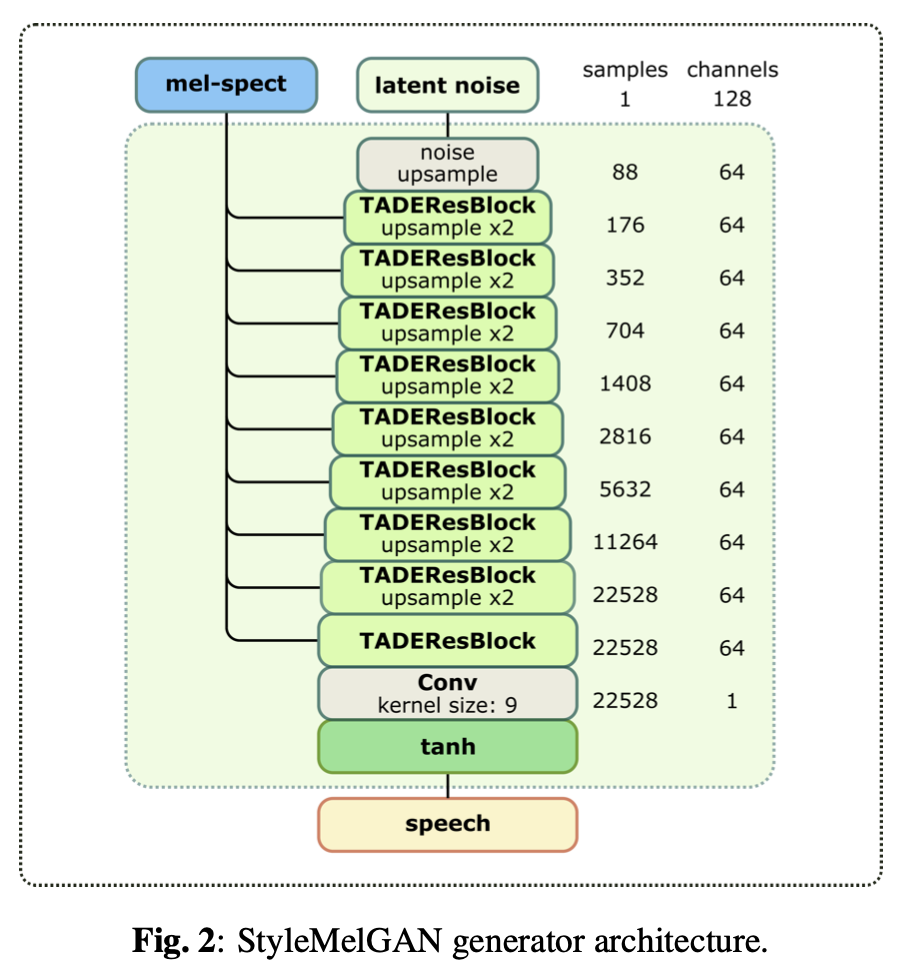
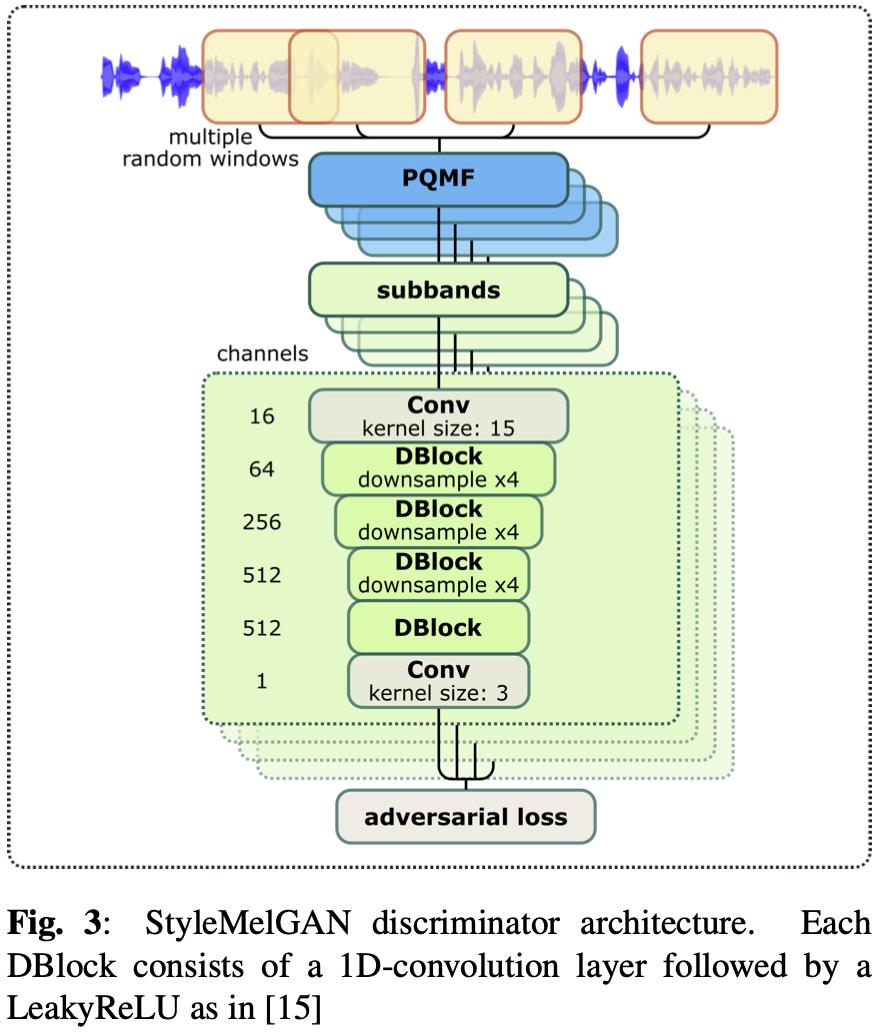
需要注意的点
输入
- 一般情况下,若训练时输入中没有
noise,容易过拟合,需要 finetune- 参考 espent issue
- 若输入中有
noise, 在预测时需要自己在inference代码中生成noise, 而不能作为参数输入给inference, 否则动转静可能走不通- 参考 pwgan 动转静修复 pr
生成器
hop_size和n_shift的含义一样upsample_scales的乘积一定等于hop_size采样点 = hop_size * 帧数librosa 帧数 = 采样点 // hop_size + 1, 具体要不要+1看不同的库,看center这个参数Mel GAN和Multi-Band Mel GAN生成器的代码是一样的,只是参数不一样,通道数不一样Parallel Wave GAN的生成器是WaveNetlike- 用非因果卷积替换了因果卷积
- 输入是满足高斯分布的随机噪声
- 训练和预测时都是非自回归的
Style MelGAN的 noise 的上采样需要额外注意,输入的长度是固定的batch_max_steps(24000) == prod(noise_upsample_scales)(80) * prod(upsample_scales)(300, n_shift)
判别器
- HiFi GAN 判别器的能力很强
速度
- 为什么
Multi-Band Mel GAN的预测会更快?因为上采样的倍数变为了原来的1/4
FFT 在语音合成声码器上的应用
语音合成是一种将任意文本转换成语音的技术,目前在深度学习领域,语音合成主要分为 3 个模块:
- 文本前端
- 声学模型
- 声码器
其中,文本前端模块将输入文本转换为音素序列或语言学特征;声学模型将音素序列或语言学特征转换为声学特征,在语音合成领域,常用的声学特征是 mel 频谱;声码器将声学特征转换为语音波形。
声码器的输入是频域特征 mel 频谱图,输出是对应的语音波形。
STFT 全称 Short-Time Fourier Transform,短时傅里叶变换,它是用滑动帧 FFT 生成频率与时间的 2D 矩阵,通常被称为频谱图(Spectrogram), 而人耳对于频率的敏感程度是非线性的,可以通过 mel 三角滤波器对频谱图处理,生成 mel 频谱图。
生成 mel 频谱图的计算离不开 fft 系列的算子,若模型的输入是 mel 频谱图,可以使用 librosa 等科学计算库进行计算再输入模型。然而,现有的大多数基于 GAN 的声码器模型,在计算 loss 时需要将生成器合成的音频及原始音频转换到频率域再做计算,这时需要用到短时傅里叶变换算子 stft,且由于 stft 算子出现在了模型图中,其需要参与到模型的前向和反向计算过程中,此时,则需要深度学习框架提供 stft 算子。
最新的 PaddleSpeech 语音合成模块的声码器,用到了 paddle 2.2.0 提供的 fft 系列算子 paddle.signal.stft。
PaddleSpeech 模型库目前已经实现的基于 GAN 的声码器包括 Parallel WaveGAN、Multi Band MelGAN、HiFiGAN 和 Style MelGAN,这些模型的 loss 中都包含基于 stft 算子的 loss,其中主要包含 Multi-resolution STFT loss 和 Mel-Spectrogram Loss。
Multi-resolution STFT loss 公式如下所示:
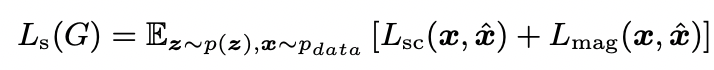
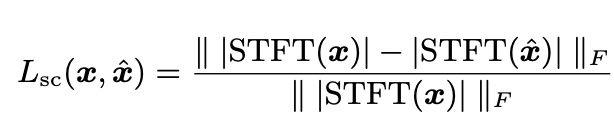
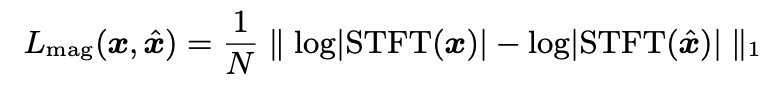
Mel-Spectrogram Loss 公式如下所示:
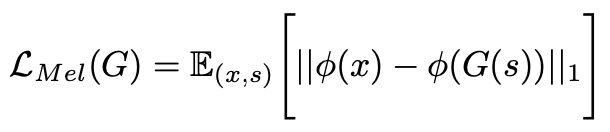
其中 Φ 表示将音频转换为对应 mel 频谱的函数。
如上述公式所示,现在主流的基于 GAN 的声码器的 loss 设计需要用到 stft,在 Paddle 中尚未实现 fft 系列算子时,PaddleSpeech 模型库使用基于 Conv1D 算子的函数来模拟 stft 算子,然而经过计算,该模拟函数前向结果正确,反向梯度计算结果不正确,这导致了模型收敛效果不佳,听感略差于竞品。
Paddle 主框架中加入 fft 系列算子后,我们将语音合成声码器 loss 模块中的基于 Conv1D 的 stft 均替换为 paddle.signal.stft,在模型收敛效果和合成音频听感上,paddle.signal.stft 的效果明显优于基于 Conv1D 的 stft 实现。
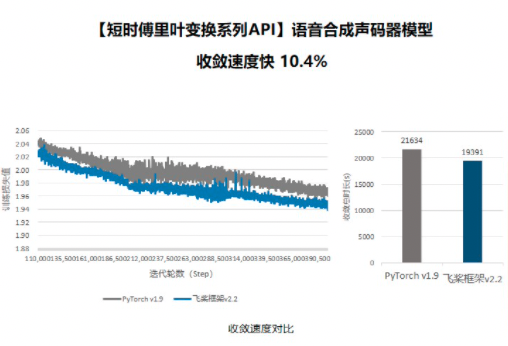
以 Parallel WaveGAN 模型为例,我们复现了基于 Pytorch 和基于 Paddle 的 Parallel WaveGAN,并保持模型结构完全一致,在相同的实验环境下,基于 Paddle 的模型收敛速度比基于 Pytorch 的模型快 10.4%, 而基于 Conv1D 的 stft 实现的 Paddle 模型的收敛速度和收敛效果和收敛速度差于基于 Pytorch 的模型,更明显差于基于 Paddle 的模型,所以可以认为 paddle.signal.stft 算子大幅度提升了 Parallel WaveGAN 模型的效果。
P.S. 欢迎关注我们的 github repo PaddleSpeech, 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。











![[opcv图像处理] C/C|++将图片转换为马赛克效果](https://static.hdslb.com/mobile/img/512.png)
