关于学术文献推荐系统的调研报告
1 引言
1.1 研究背景
随着大数据时代的到来,互联网在给人们的生活带来丰富多彩的同时,海量信息也导致了“信息过载”问题。对于信息使用者来说,如何从海量信息中找到自己需要的信息是一件越来越困难的事;对于信息生产者来说,如何让自己的商品在众多商家中脱颖而出,吸引大众的目光从而带来收益,也是一件很困难的事情[1]。个性化推荐系统的产生便很好的解决了这个问题,对用户来说降低了获取信息的成本提高了用户体验,对商家来说也提高了用户的黏度,可谓是一个双赢的技术。目前在工业界,推荐系统已经应用到了很多领域,在视频推荐领域,有Youtube,Netflix,优酷,爱奇艺等;在音乐推荐领域,有KKbox,网易云音乐等;在电商推荐领域,有亚马逊,淘宝,京东等。
经调查研究显示,目前在学术研究领域科技论文数量每年以6%~8%的速率增长,这导致了科研工作者不得不花费大量时间和精力在相关领域的论文检索上。目前在论文检索领域虽然有专业的学术搜索引擎和检索服务提供商,如 Google scholar search、Microsoft academic search、以及中国知网( CNKI) 等,但面对返回的大众化检索结果,用户往往会眼花缭乱,并不能在最短时间内找到自己需要的信息。科研人员更希望论文检索系统能根据自己的实际需求主动推荐相关领域的论文,在节省检索时间的同时获得高质量的检索结果;同时还需要向同行快速高效地推介自己的学术成果,从而提高学术声誉,提高自己在学术界的影响力,为争取更好的科研资源奠定基础。
个性化推荐技术在论文检索领域的发展和研究具有十分重要的意义。目前如 web of science、百度文库、中国期刊网等都提供了根据用户兴趣自动收集具有高相似度文献的服务,而百度学术等搜索网站的个性化推荐已经取得了相当不错的效果。
1.2 论文推荐系统研究现状
将推荐系统的思想应用在文献推荐系统中是一个较新的探索领域,但各种研究成果也在不断涌现。比如CTR技术的出现最初就是为了解决论文推荐领域的冷启动问题,利用文章文本内容,同时权衡文章打分情况来做推荐;2015年kdd里有一篇数据挖掘的论文[2]是用最简单的关系,主题思想是利用类似 random walk的思想给最简单的图跑一下,然后预测与一个点接近的其它点,可能是一度关系,也可能二度到三度关系。我觉得论文可以看作一种文本,只是相比于一般的文本来说,论文具有更加独特的一些特征。那么用在文本推荐领域的算法都可以在论文推荐领域进行应用上的探索。
1.2.1 基于内容的论文推荐技术
将基于内容的推荐算法应用在论文推荐领域的主要实现方法是提取论文的标题、摘要、关键词汇、发表刊物、引用次数、作者等特征信息,以及提取用户的年龄、研究领域、职业等特征信息。基于内容的论文推荐技术目前也出现了很多相关的研究成果。2005年,Sullivan等人[3]首次提出将激活-扩散模型应用到论文推荐领域;同年Wat anabe等人[4]开发了一个文献支持系统Papits,该系统基于用户的历史浏览记录构建用户模型,然后通过计算用户矩阵与论文矩阵之间的相似度并排序,最终将相似度最高的论文推荐给用户。2006年,Gori和Pucci提出[5] 根据论文与论文之间的引用和被引用关系,将整个论文数据库表示成图,将图矩阵进行归一化处理后,使用优化版的PageRank算法进行推荐。Goodrum[6]介绍了Citeseer系统,主要思想同样是根据论文与论文之间的引用和被引用关系,来发现从而推荐相关论文的方法。Strohman等人[7]认为,仅仅使用基于文本信息的推荐算法或者仅仅使用基于引用关系信息的推荐方法都有其局限性,于是提出了将二者进行融合的推荐算法。Yu等人提出[8]基于向量空间模型的推荐技术来表示用户偏好及论文。Sun等[9]同样是基于向量空间模型表示的思想,实现对审稿人的论文推荐,具体是将需要审稿的文献用向量空间模型表示,然后将与审稿人偏好矩阵相似度较高的论文推荐给其审阅。Chandrasekapan等[10]把Citeseer系统中有过论文发表记录的用户进行分析并针对他们设计了论文推荐系统,该系统本质上是使用的基于内容的推荐算法,但在计算用户矩阵与论文矩阵之间的相似度的时候不再采用前面提及的基于向量空间模型的思想,而是将论文及用户偏好表示为概念树,通过计算概念树之间的编辑距离来计算论文及用户偏好之间的相似度。最终的实验结果证明,该方法比基于向量空间模型推荐技术的性能要好。王冬晖等人[11]基于特征选择和softmax回归思想设计了一个基于内容的计算机论文推荐系统;Pudhiyaveetil等人提出[12]将所研究的用户范围扩大到所有有过浏览记录的用户。Ba su等[13]提出了将审稿人的多种特征信息以及论文的多种特征进行融合的推荐算法。Poh l等人提出[14]基于论文的共被查看信息向相关用户推荐论文的思想,最终的实验结果验证了也验证了该算法的优越性。
1.2.2基于协同过滤的论文推荐算法
高凯等人提出[15]用FPT树(即Frequent-Pattern-Time)发现用户的共同爱好,然后基于神经网络的bp算法进行推荐。Vellino等人[16]认为用基于PageRank的推荐算法生成user矩阵的Top-N推荐结果要比基于布尔偏好矩阵的推荐结果优异,而最终结果却表明,基于PageRank推荐算法的Top-N推荐结果要逊色于基于布尔偏好矩阵的推荐结果。段文奇[17]等人提出了传播平台模型,是借助协同过滤的思想,实现了一个推荐-传播的推荐模型;Aga rwal等人[18]提出了子空间聚类算法;Chen等人[19]使用聚类算法中的蚁群算法先对用户进行聚类,然后在聚类后的每一个簇内使用Apriori关联规则算法从而完成相关推荐。[20]与论文[19]相似,也是先聚类,不过是先根据用户的背景信息使用自适应共振理论来聚类,然后对聚类后的每个簇使用Apriori关联规则算法实现推荐。Conry等人[21]则提出了RMSE预测模型专门用于评阅会议论文。
1.2.3基于混合推荐的论文推荐技术
更多推荐系统会使用混合推荐的方式。Huang等人[22]提出了基于图模型的论文推荐系统,图的第一层是书及书之间的关联,第二层是用户及用户之间的关联,两层节点之间的链接是用户对书的打分或者预测打分,具体的推荐策略是图搜索技术。McNee等[23]通过设置离线实验和在线实验,分析了四个基于引文网络和协同过滤向一篇论文推荐相关论文的算法,离线实验结果表明基于不同的评价标准,推荐算法的比较结果会有很大的差异;在线实验结果表明大部分用户认为推荐算法对自己有帮助作用。Hess等[24]提出了将引文信息和可信度信息相融合的推荐技术。文献[25]设计了CYCLADES系统,并实现了个性化推荐,提醒功能。Naak等人[26, 27]认为仅仅基于用户评分信息的论文推荐系统存在着一个问题:没有考虑用户打分原因——两个用户对同一篇论文打分相同原因不一定相同,于是在此基础上设计了论文管理系统Papyres,首先是使用基于内容的推荐技术,然后使用协同过滤算法对基于内容的推荐结果进一步净化。李晓旭[28]提出基于用户画像建立了一个智能数字图书馆推荐系统;Gipp等[29]实现了一个论文推荐系统Scienstein,把引文分析、作者分析、源分析、隐式打分、显式打分等进行混合,实现推荐。车丰[30]设计了基于排序主体模型的论文推荐系统,不仅可以保证推荐结果的准确率,还考虑到推荐结果的多样性和新颖性,极大的提高了用户体验;张等人[31]提出了根据标签进行相似度计算的推荐系统,本质上是一个基于内容和协同过滤的混合推荐系统,首先用协同过滤算法发现相似用户,然后采用基于内容的推荐算法进行推荐。Wang等[32]提出了基于协同过滤技术和基于内容分析技术的混合论文推荐方法,使用隐因子模型实现协同过滤技术,使用概率模型实现内容分析技术,从而将对用户的推荐等同于计算隐因子的条件概率。
1.3研究目标
从系统设计上说,一个功能完善的推荐系统可以一般分为两个大的模块 :
1 离线推荐模块(准确率至上):离线推荐服务主要计算一些可以预先进行统计和计算的指标,从而为实时推荐模块和前端模块提供相应的数据支撑,由于没有实时的时间局限,更看重的是算法的准确率。离线推荐一般应用在以下场景:
非个性化推荐:统计该领域的热门论文或热门关键词对每位用户进行无 差别的推荐;
个性化推荐:比如每日推荐,猜你喜欢(其推荐结果早就离线计算好),相似论文推荐(即推荐当前浏览论文的相似论文,看似属于在线推荐,其实推荐结果也可以提前离线算好,待用的时候取出)
2 在线推荐模块(效率至上):根据用户浏览网页的实时反馈进行相关推荐。一般应用在比如当用户打了高分,或点击了“不感兴趣”,“存为书签”或者“喜欢”的按钮,系统可以根据用户反馈实时更新推荐列表。在线推荐服务一般需要用到大数据实时处理框架。
通常情况下,一个推荐系统由离线推荐和实时推荐共同构成,实现原则是能离线预先算好的,尽量离线算好。实时推荐和离线推荐最大的区别在于实时计算推荐结果是动态反映用户当下的偏好,而离线计算推荐结果则是根据用户从第一次登录至今的所有历史记录来计算用户总体的偏好,反映的是用户一个长期的偏好。因此离线推荐更注重推荐的准确性,对算法准确度的要求较高;而在线推荐更要求实时性来提高用户体验,更关心推荐结果的动态变化能力,所以算法的计算量不能太大,避免复杂、过多的计算造成用户体验的下降,因此推荐精度往往不会很高,只要更新推荐结果的理由合理即可。
以一个商品推荐系统为例,一般推荐系统可以分为以下几个模块:检索模块,离线推荐,实时推荐,热门推荐,评分模块,标签模块,相似推荐。如下图所示:

2 推荐算法概述
2.1 协同过滤推荐算法
既然要做个性化推荐系统,首先我们需要先了解每个人,听其言、观其行,在网络世界我们称之为用户行为数据分析。通常推荐系统会在以下情况下产生:
- 有些用户不是太清楚自己喜欢什么。
- 用户的兴趣不可能是一成不变的,会根据外部因素进行改变。
我们需要通过不断采集用户在网络中的行为数据以及用户与网站的交互反馈数据,不断修正推荐系统对用户的定位,从而不断修正符合用户当前状态的推荐结果。用户行为数据在网站上的存在形式就是用户日志。网站在运行过程中会产生大量的原始日志 Raw Log,将其存储在文件系统中,企业会将多种原始日志按照用户行为汇总成会话日志Session Log,会话日志就从某种程度上表示了用户的反馈。用户反馈主要分为显性反馈行为和隐形反馈行为。显性反馈行为包括用户明确表示对物品喜好的行为,比如评分、收藏;隐性反馈行为指的是那些不能明确反应用户喜好的行为,比如用户浏览页面的行为日志,浏览停留时间等。我们对表示用户喜欢的反馈叫正反馈,表示不喜欢的叫负反馈。如下表所示:
|
| 显性反馈 | 隐性反馈 |
| 视频网站 | 用户对视频的评分 | 用户观看视频,浏览页面的日志 |
| 电子商务网站 | 用户对商品的评分 | 购买日志,浏览日志 |
| 门户网站 | 用户对新闻的评分 | 阅读新闻的日志 |
| 音乐网站 | 用户对音乐/歌手/专辑的评分 | 听歌的日志 |
基于用户行为数据和反馈信息设计的推荐算法一般称为协同过滤算法。学术界对于实现协同过滤有很多方法,比如基于邻域的方法(neighborhood-based)、隐语义模型 (latent factor model)、基于图的随机游走算法(random walk on graph)等。目前使用最广泛的是基于邻域的方法,主要包括下面两个算法:
基于用户的协同过滤算法:给用户推荐的是他的相似用户喜欢的物品。
基于物品的协同过滤算法:给用户推荐的是和他之前喜欢物品相似的物品。
基于用户的推荐和基于物品的推荐都需要找相似,即需要找相似用户或者相似物品。衡量相似度的指标有皮尔逊相关系数、欧式距离、同现相似度、Cosine 相似度、Tanimoto 系数等。其局限性在于,当大型网站的用户数和物品数迅速增多时,一方面会出现数据稀疏问题,另一方面其算法复杂度会大幅度增高。
2.2 基于内容的推荐算法
基于内容的推荐算法,在推荐算法的演绎过程中,是对协同过滤算法的一个延续和扩展,它不需要依据用户对物品的评价意见,原理是用户喜欢和自己关注过的物品在内容上类似的 物品,比如你看了哈利波特I,基于内容的推荐算法发现哈利波特 II,VI,与你以前观看的哈利波特I在内容上面(共有很多关键词)有很大关联性,就把后者推荐给你。基于内容的推荐方法很多都是用的信息检索里面的技术,比如自然语言处理中的tf-idf技术和文本分类技术。
基于内容的推荐算法的缺陷在于,由于是直接基于物品的内容,很可能导致给用户推荐的物品局限在某个领域,缺乏新颖性和多样性,即推荐过度专业化。
2.3 基于模型的推荐算法
基于模型的推荐算法会尝试量化一个用户会多么的喜欢他们之前没有遇到的物品,有预测的性质。为达此目的,基于模型的方法通常使用一些机器学习算法来对物品的向量(针对一个特定的用户)来训练,然后建立模型来预测用户对于新的物品的得分。流行的基于模型的技术有贝叶斯网络模型、奇异值分解模型,基于关联规则的算法,隐含概率语义分析,以及如今大热的深度学习模型。基于模型的算法一般用于用户数远远多于物品数,且物品数的更新频率不高的场景。
如今像阿里,优酷,盒马,YouTube等大公司都在相继提出新的推荐算法模型,比如YouTube将循环神经网络应用在视频推荐中并取得了很好的效果,阿里提出了SDM模型,GAttN模型,DeepMCP模型,TDM模型,深度兴趣网络DIN模型,京东将强化学习应用在推荐系统中,都取得了很好的效果。
2.4 组合推荐
以上不管哪种算法,在实际的应用中都存在着一定的局限,常用在推荐系统中的解决方案就是将多种推荐系统结合起来,形成混合推荐算法,利用各个算法的优点,并尽量避开他们的缺点。常见的混合推荐系统会将基于协同过滤的推荐技术,基于内容的推荐技术,基于模型的推荐技术来一起进行推荐,然后将三者的推荐结果以某种方式进行组合。组合的方式一般有两种,一种是将三者的预测结果进行线形组合;另一种是将几种推荐算法以某种方式进行组合共同得出推荐结果;还有一种是基于特定的基准来测试这几种推荐算法的性能如何,最终将性能表现最好的推荐技术作为最终结果返回给用户。
3 评估方法和评估指标
一个好的文献推荐系统不仅要能够为用户推荐符合需求的学术资源,还需要保证推荐的文献的高质量。对所推荐的文献的质量评价应该从多个因素来考虑。
3.1 评估方法
获取推荐系统评测指标的主要实验方法主要分为三种:1、离线实验。2、用户调查。3、在线实验。
3.1.1离线实验
离线实验是通过对离线数据集进行训练集和测试集的划分和测试,完成对评测指标的结果的收集。
(1) 通过日志系统获得用户行为数据,并按照一定格式生成标准的数据集;
(2) 将数据集按比例划分成训练集和测试集;
(3) 在训练集上训练模型,在测试集上进行测试;
(4) 通过离线指标评测算法在测试集上的预测结果。
3.1.2用户调查
用户调查需要有真实的用户在需要测试的推荐系统上完成一些任务。在他们完成任务的同时观察和记录他们的行为,并提出问题让他们回答。最后通过分析他们的行为和答案来了解测试系统的性能。这种方法的优点是可以直接得到很多体现用户主观感受的指标,并且风险很低。缺点是实际应用中很难组织起大规模的测试用户,导致测试结果的统计意义不足。
3.1.3 在线实验
将推荐系统上线进行测试,并和旧的算法系统进行 AB 测试,使用户流量随机分配到新旧两个系统中,然后统计用户的反馈数据进而进行系统的指标统计和比对。
3.2 评估指标
3.2.1 召回率
召回率定义为最终推荐列表中实际被引用的论文在推荐的前K个论文中的比率,前K个推荐结果的召回率计算公式如下所示:
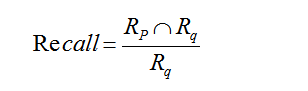
其中Rp表示测试论文中实际被引用的论文集合,Rq为推荐列表中所推荐的K个论文列表集合。
3.2.2 平均准确率
在推荐系统中,推荐的论文在论文推荐列表中的排序位置也是十分重要的。论文的平均准确率(MAP)反映的是推荐系统在全部相关推荐上性能的单值指标,推荐列表中的论文排名越靠前,其MAP值就越高。
对于一篇论文的查询q,假设推荐列表中第i篇推荐正确的论文记为Rank qi,则MAP的计算公式如下所示:
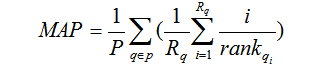
公式中,Rq表示对于查询q正确的推荐论文数量;P表示测试论文集。
3.2.3 多样性
用户的兴趣一般是比较广泛的,不会只局限于某一领域,那么推荐系统的结果应当能够覆盖用户多个兴趣领域,这便是推荐结果的多样性。推荐结果多样性的本质其实是推荐结果列表中物品两两之间的不相似度,因此,多样性和相似性是有关联的。对于某一用户u得出的推荐列表R(u)的多样性计算公式如下所示:

其中s(i,j)表示的是物品i和j之间的相似度。
3.2.4 用户满意度(在线)
只能通过用户调查或者在线实验获得,比如网站的推荐结果反馈、用户的点击率、用户停留时间和转化率指标等来衡量用户的满意度。
4 案例分析
本节以一个简易的论文推荐系统为例,包含实时推荐和离线推荐服务,综合利用了协同过滤算法,基于内容的推荐方法以及基于模型的推荐算法来提供混合推荐,提供了从前端应用、后台服务构建、算法设计实现、平台部署等多方位的闭环的业务实现。对于一个普通的网站,假设每天大概2、3000用户的访问量。处理大概2GB左右的日志数据,提供大约有6台服务器,内存大概256GB、每台磁盘2TB。在性能上也应该能够满足以下要求:
- 由于推荐系统中存着海量的用户资源和用户数据,则需要考虑到海量数据处理技术,比如数据库优化技术,并且应当具有可靠性和安全性;
- 在线用户数量巨大的情况下,应当能够应对高并发的压力;
- 系统的模块众多,并且用户量和数据量都会不断增长,因此系统应当具有良好的扩展性以及易管理性。
系统整体架构设计如图所示:

4.1 数据获取模块
要进行论文推荐,我们需要的数据如下:用户数据,论文数据,偏好值。
- 用户数据可以通过系统注册的用户及行为获取;
- 偏好值就是对用户对论文的感兴趣程度的衡量,推荐系统所做的事就是根据这些偏好数据为用户推荐他还没有浏览过的论文。而偏好值的衡量一般会有很多办法,比如用户评分、用户打标签、引用次数、保存书签、论文浏览时间等等,然后系统根据用户的这些行为流水,采取减噪、归一化、加权等方法综合给出偏好值。一般不同的业务系统给出偏好值的计算方法不一样。
- 论文数据可以从目标网站爬取,可以单独设计一个爬虫模块给整个推荐系统提供稳定可靠,可持续更新的论文数据源。
论文爬取部分基于python的Scrapy框架,设计一个分布式爬虫系统来从目标论文网站上抓取论文数据。鉴于单机的处理性能终究有限,使用分布式集群可以大大提高效率。使用Xpath解析网页,结合Scrapy-Redis做分布式,最终把数据存储在MongDB数据库中,并利用Spiderkeeper实时监控爬虫的健康状态。
该分布式爬虫的主要流程图如下所示:
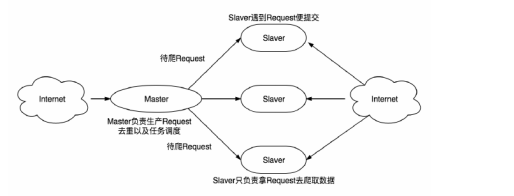
其中Master端主要负责的是生产任务以及任务去重,Slaver端则负责从Master端获取任务并执行任务解析,使用这种模式,设置一台Master服务器节点,三台Slaver服务器节点,为了不给目标爬取服务器造成压力,可以设置限制Master节点和Slaver节点的爬虫并发请求数量。在Master服务器端安装Redis数据库和Spiderkeeper监控,在Slaver端安装Scrapy和MongDB数据库。整个爬虫系统包括网页抓包模块,反反爬虫模块(为了避免目标网站的反爬措施),信息分析与提取模块(可以利用Xpath等工具进行解析,利用正则表达式将论文信息进行处理和提取,并存入数据库做准备),网页下载模块,数据存储模块以及Spiderkeeper监控模块(用户健康监控以及可视化)。
最终处理好存入数据库中数据应以表的形式存储,例如:注册用户信息表,论文信息表,用户反馈表。其中用户信息表可以包含用户id,用户名,年龄,职业,研究方向;论文信息表可包括论文作者信息(职业,研究领域,年龄,职称等),所属学科(学科名称,学科编号),刊物信息(名称,编号,级别,引用次数,关键字,摘要等);用户反馈表,可以用点击/没点击,浏览时间长短来衡量。并将这些类别型数据经过特征工程处理成字符型数据,以便于计算机识别。
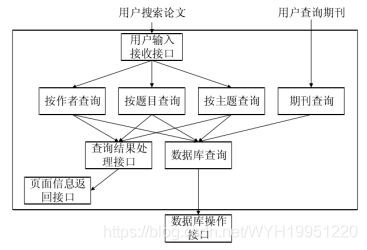
4.2 用户搜索模块
用户搜索模块是最基本的一个模块,在这个模块中,用户可以输入作者,题目,关键字主题,日期等来搜索自己想要的论文。Elastic search是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据,它本身的扩展性很好,可以扩展到上百台服务器,处理PB级别的数据,可以根据实际应用中的需求动态调整。
4.3 用户可视化模块(前端开发)
主要负责实现和用户的交互以及业务数据的展示,主体可采用AngularJS2进行实现,可部署在Apache服务上。
4.4 综合业务服务(后端开发)
主要实现JavaEE层面整体的业务逻辑,通过Spring框架进行构建,对接业务需求。可部署在Tomcat上,主要负责后台数据和前端业务的交互。可主要分为 REST 接口服务层、业务服务层、业务模型以及工具组件。
4.5 数据中心
可采用广泛应用的文档数据库MongDB作为主数据库,主要负责平台业务逻辑数据的存储。采用 Redis 作为缓存数据库,主要用来支撑实时推荐系统部分对于数据的高速获取需求。
(实际情况下可根据数据的实际情况选择关系型或者非关系型数据库)。
4.6 系统初始化模块
通过 Spark SQL将系统初始化数据加载到 MongoDB 和 ElasticSearch 中,通过 Azkaban 实现对于离线统计服务以离线推荐服务的调度,通过设定的运行时间完成对任务的触发执行。
4.7 离线推荐系统功能模块
4.7.1 用户检索功能
用户检索功能是最基本的一个检索模块,在这个模块中,用户可以通过输入作者,题目,关键字主题,日期等来搜索自己想要的论文。该系统使用Elastic search来实现高效可扩展的模糊检索。
4.7.2 热门推荐功能
热门论文推荐的目的是方便用户了解当今最为热门和前沿的研究领域,研究方向。可采用的统计方法是:
通过对系统所有用户的搜索过的关键字主题进行统计和分析,将搜索频率最高的词汇显示在搜索框里;
从 MongoDB 中加载数据,可根据论文的点击率进行排序,找出点击率top N的论文作为热门论文,并将计算结果回写到 MongoDB中,从而实现热门论文推荐。
4.7.3 相似论文推荐
当用户搜索到比较满意的结果时,可以根据搜索结果进行相似论文推荐。衡量用户是否满意可通过用户对某一篇论文的浏览时间,若浏览时间超过某个设定值,就将此论文视为用户感兴趣的论文,从而给出相似的论文推荐给用户。
计算相似论文的一个思路是使用基于内容的协同过滤算法:统计所有论文的关键词,将具有至少一个关键词的论文集合找出,对这些论文的摘要和题目进行中文分词,提取所有论文的特征矩阵,进行相似度计算,取出每个论文前n个最相似的论文,结合用户的浏览历史,将用户没有浏览过的论文推荐给用户。
4.7.4 针对用户的个性化推荐
可采用的思路有:
- 针对某个用户,统计他的历史搜索的关键词,根据搜索频率最高的关键词进行相关领域的论文匹配与推荐。
- 针对某个用户,计算该用户与其他所有用户的相似度并将相似度进行排序,取相似度最高的top N个用户看过的论文推荐给该用户。
- 基于模型的协同过滤推荐算法,分别根据 MongoDB 中存的用户反馈表(如评分值,浏览时间)和论文数据表提取用户-论文推荐矩阵,同时也可以得到论文相似度矩阵。
以ALS(交替最小二乘法)为例,算法的主要思路如下:
1. 用户特征矩阵和论文特征矩阵做笛卡尔积,产生(user,paper)的元组
2. 通过模型预测(user,paper)的元组。
3. 将预测结果通过预测分值进行排序。
4. 返回分值最大的 K篇论文,作为给当前用户的推荐。
通过 ALS 算法同时可以得出论文的相似度矩阵,该矩阵也可用于查询当前论文的相似论文并为实时推荐系统服务。
4.8 实时推荐系统功能模块
用户于论文的偏好随着时间的推移总是会改变的。比如一个用户 u 在某时刻对论文p产生了极大的兴趣(以评分为例:评了高分),那么在近期一段时候,用户u极有可能很喜欢与论文p类似的其他论文;而如果用户u在某时刻对论文q兴趣不大(打了低分),那么在短时间内,用户u 极有可能不喜欢与论文q类似的其他论文。所以对于实时推荐,当用户对一个论文实时的表达出偏好时,推荐结果应该实时的进行一定的更新,使得推荐结果匹配用户短时间的偏好,满足用户近期的口味。
所以对于实时推荐算法,主要有两点需求:
(1)用户本次打分/浏览/收藏/存为书签后、系统可以明显的更新推荐结果;
(2)计算量不大,满足响应时间上的实时要求;
算法主要思路如下:
(1)用户 u 对论文p 表达出感兴趣(比如产生了长时间浏览,存为书签,打了高分等行为,以下以评分为例),触发实时推荐的一次计算;
(2)选出与论文p最相似的K个论文作为集合S;
(3)获取用户u最近时间内的K条反馈,作为集合RK;
(4)计算论文的推荐优先级,产生集合 updated_S;将 updated_S 与上次对用户u 的推荐结果进行合并,产生新的推荐结果作为最终输出。
具体的实现可采用大数据实时处理框架[32-33]:
(1)首先 Spark 实时计算程序利用 KafkaUtils 工具获取 Kafka 集群得到的消息,生成 DStream;
(2)对于 DStream 中每个 RDD:RDD-0、对于每个 RDD-0 中的每个数据条目,进行简单的数据格式化产生每条记录为<userId,paperId,rating,timestamp>的新 RDD:RDD-1;
(3)对于 RDD-1 中每条记录:
a.根据userId,从MongoDB中获取userId最近的K次评分记录 recentRatings;
b.根据PaperId,从广播变量中获取与PaperId最相似的K个论文集合
candidatePapers;
c.对于每个论文q ∈ candidatePapers,利用公式计算出其推荐优先级,更新推荐结果;
d.将最新推荐结果与 MongoDB 中上一次的推荐结果进行合并,按照推荐优先级进行排序并更新;
5 推荐系统常见的问题与解决方案
5.1 冷启动问题
整个推荐系统更多的是依赖于用户的历史信息和偏好信息进行论文的推荐,对于老用户可以推荐出合适的论文,但这时就会存在一个问题,新注册的用户是没有任何偏好及历史信息记录的,那这个时候推荐就会出现问题,导致没有任何推荐的论文出现,这就是推荐系统中的“冷启动”问题。
处理这个问题一般是通过当用户首次登陆时,为用户提供交互式的窗口来获取用户对于物品的偏好。例如当用户第一次登陆注册的时候,系统会询问用户的职业,感兴趣的领域等。当获取用户的偏好之后,对应于需要通过用户偏好信息获取的推荐结果,则更改为通过对论文的类型的偏好的推荐。
5.2 数据稀疏问题
随着用户量急剧增大,用户-论文矩阵也会相应增大,从而产生数据稀疏问题。解决数据稀疏性问题的方法主要有以下几种:一种是人工填补数据;一种是混合推荐;还有一种就是利用神经网络来提取特征。
6 总结
如今,推荐系统在商业界的应用已经非常成熟,各种新的模型层出不穷。但是在学术领域,对于论文资源的个性化推荐可以说还只是处于一个起步和探索的阶段。
我认为,学术论文推荐模型在实际应用中还是会产生很多实际的问题:
一是版权问题,利用推荐系统传播的科研成果时可能会涉及到版权问题;
二是多语言学术论文推荐问题,目前关于学术资源推荐的论文成果已有上百篇,但是涉及到多语言论文推荐的技术,至今还没有人提出;
三是虽然已有上百篇学术资源推荐的论文成果,但是至今没有明确的结果表示这个领域的哪种算法是最好的,由此可见对于学术资源推荐还是缺乏一定的评估标准。
可以预见,随着大数据计算和人工智能新技术的发展,对学术论文的个性化推荐必将产生新的思想、模型和技术,推荐的结果也将越来越令人满意。
参考文献
[1] 项亮. 推荐系统实践[M]. 人民邮电出版社,2012.
[2] Jing Zhang , Jie Tang, et al.Panther: Fast Top-k Similarity Search in Large Networks[C]In KDD’15,2015
[3] WOODRUFF A, GOSSWEILER R, PITKOW J, et al. Enhancing a Digital Book with a Reading Recommender [C]// Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, NY, USA. ACM, 2000.
[4] WATANABE S, ITO T, OZONO T, et al. A Paper Recommendation Mechanism for the Research Support System Papits [C]// 2005 International Workshop on Data Engineering Issues in E-Commerce, Tokyo, Japan. IEEE, 2005: 71-80.
[5] GORI M, PUCCI A. Research Paper Recommender Systems: A Random-Walk based Approach [C]// Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligence, Washington, USA. IEEE Computer Society, 2006: 778-781.
[6] GOODRUMA. Scholarly Publishing in the Internet Age: a Citation Analysis of Computer Science Literature [J]. Information Processing & Management, 2001, 37(5):
661-675.
[7] STROHMAN T, CROFT W B, JENSEN D. Recommending Citations for Academic Papers [C]// Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, NY, USA. ACM, 2007, 705-706.
[8] YU Z T, ZHENG Z Y, GAO S X, et al. Personalized Information Recommendation in Digital Library Domain Based on Ontology [C]// IEEE International Symposium on Communications and Information Technology, 2005, 1249-1252.
[9] SUN Y H, NI W J, MEN R. A Personalized Paper Recommendation Approach based on Web Paper Mining and Reviewer’s Interest Modeling [C]// Proceedings of the 2009 International Conference on Research Challenges in Computer Science, Washington, DC, USA. IEEE Computer Society, 2009, 49-52.
[10] CHANDRASEKARAN K, GAUCH S S, LAKKARAJU P, et al. Concept-based Document Recommendations for Citeseer Authors [C]// Proceedings of the 5th International Conference on Adaptive Hypermedia and Adaptive Web-based Systems. Berlin, Heidelberg.Springer-Verlag, 2008, 83-92.
[11]王冬晖. 基于内容的计算机科学论文推荐系统设计与实现[D].2017.
[12] PUDHIYAVEETIL A K, GAUCH S, LUONG H, et al. Conceptual Recommender System for CiteseerX [C]// Proceedings of the Third ACM Conference on Recommender Systems, NY, USA. ACM, 2009, 241-244.
[13] BASU C, HIRSH H, COHEN W W, et al. Technical Paper Recommendation: a Study in Combining Multiple Information Sources [J]. Artificial Intelligence Research. 2001, 14(1): 231-252.
[14] POHL S, RADLINSKI F, JOACHIMS T. Recommending Related Papers Based on Digital Library Access Records [C]// Proceedings of the 7th ACM/IEEE-CS Joint Conference on Digital Libraries, ACM New York, NY, USA, 2007, 417-418.
[15] GAO K, WANG Y C, WANG Z Q. Similar Interest Clustering and Partial Back-Propagation-based Recommendation in Digital Library [J]. Library Hih Tech. 2005, 23(4): 587-597.
[16] VELLINO A. Recommending Journal Articles with PageRank Ratings [EB/OL]. Researchreport.2009.
[17] 段文奇. 基于协同过滤的论文推荐 - 传播平台模型研究.2012
[18] AGRARWAL N, HAQUE E, LIU H, et al. Research Paper Recommender Systems: A Subspace Clustering Approach [C]// International Conference on Web-Age Information Management, Springer, 2005, 3739: 475-491.
[19] CHEN C C, CHEN A P. Using Data Mining Technology to Provide a Recommendation Service in the Digital Library [J]. Electronic Library: Library and Information Studies. 2007, 25(6): 711-724.
[20] TSAI C S, CHEN M Y. Using Adaptive Resonance Theory and Data-Mining Techniques for Materials Recommendation based on the E-Library Environment[J/OL]. Electronic Library: Library and Information Studies, 2008, 26(3): 287-302.
[21] CONRY D, KOREN Y, RAMAKRISHNAN N. Recommender Systems for the Conference Paper Assignment Problem [C]// Proceedings of the third ACM Conference on Recommmender Systems, ACM New York, NY, USA, 2009, 357-360.
[22] HUANG Z, CHUNG W Y, ONG T H, et al. A Graph-based Recommender System for Digital Library [C]// Proceedings of the 2nd ACM/IEEE-CS Joint Conference on Digital Libraries, NY, USA. ACM, 2002: 65-73.
[23] MCNEE S M, ALBERT I, COSLEY D, et al. On the Recommending of Citations for Research Papers [C]// Proceedings of the 2002 ACM Conference on Computer Supported Cooperative Work, NY, USA. ACM, 2002.
[24] HESS C, STEIN K, SCHLIEDER C. Trust-Enhanced Visibility for Personalized Document Recommendations [C]// Proceedings of the 2006 ACM Symposium on Applied Computing, ACM New York, NY, USA. 2006.
[25] AVANCINI H, CANDELA L, STRACCIA U. Recommenders in a Personalized, Collaborative Digital Library Environment [J]. Journal of Intelligent Information Systems, 2007, 28(3).
[26] NAAK A, HAGE H, AIMEUR E. A Multi-criteria Collaborative Filtering Approach for Research Paper Recommendation in Papyres [C]// Proceedings of MCETECH, 2009, 26.
[27] NAAK A, HAGE H, AIMEUR E. Papyres: A Research Paper Management System [C]// Proceedings of 10th IEEE Conference on E-Commerce Technology and the Fifth IEEE Conference on Enterprise Computing, 2008.
[28] 李晓旭.基于用户画像的数字图书馆智能阅读推荐系统[D].图书馆学刊,2019
[29] GIPP B, BEEL J, HENTSCHEL C. Scienstein: a Research Paper Recommender System [C]// Proceedings of the International Conference on Emerging Trends in Computing. Virudhunagar, India. IEEE, 2009.
[30]车丰. 基于排序主题模型的论文推荐系统. 2015
[31] ZHANG M, WANG W C, LI X M.APaper Recommender for Scientific Literatures Based on Semantic Concept Similarity [C]// Proceedings of the 11th International Conference on Asian Digital Libraries: Universal and Ubiquitous Access to Information, Springer-Verlag Berlin, Heidelberg, 2008, 359-362.
[32] WANG C, BLEi D M. Collaborative Topic Modeling for Recommender Scientific Articles [C]// Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM New York, NY, USA. 2011, 448-456.
[33]科技论文推荐系统研究与实现[D]. 电子科技大学,2011.
[34]基于卷积神经网络的推荐算法研究[D]. 南昌航空大学,2019
[35]王道远. Spark快速大数据分析[M]. 人民邮电出版社,2015
[36]黄美灵. Spark MLlib机器学习算法、源码及实战讲解[M]. 电子工业出版社,2016
[37]Guolin Ke ,Qi Meng,Thomas Finley,Taifeng Wang,Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu. LightGBM: A Highly Efficient Gradient Boosting Decision Tree.2018
[38]刘建国,周涛,汪秉洪.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1) : 1-15.
[39]Robin Devooght,Hugues Bersini. Collaborative Filtering with Recurrent Neural Networks. 2017
[40]胡媛,毛宁.基于用户画像的数字图书馆知识社区用户模型构建[J]. 图书馆理论与实践,2017(4).
[41]董坤.基于协同过滤算法的高校图书馆图书推荐系统研究[J]. 现代图书情报技术,2011(11).
[42]FRANK W,STEFANO B,FRANK S.A model of a trust-based recommendation system on a social network[J].Autonomous Agents and Multi-Agent Systems,2008.
[43]崔金英.网络科技文献推荐系统的设计与实现[D].上海: 华东师范大学,2010.