一年一度的大宋佳人活动又开始了,小姐姐们又开始了踊跃的报名,都有哪些漂亮的小姐姐呢?不放我们来爬一下看看
- 注:本文仅用于python爬虫学习,请勿滥用数据,严禁侵犯个人隐私
基础分析
大宋佳人活动主页面:https://n.163.com/2021/dasongjiaren4/#/list
-
打开页面向下翻,有三个赛道,美颜赛道,魔音赛道,萌宠赛道;今天我们主要来分析美颜和魔音赛道。萌宠赛道因为是今年新增加的,界面与美颜魔音不同,暂不分析。具体如下图所示【为保护隐私,图片适当打码】

-
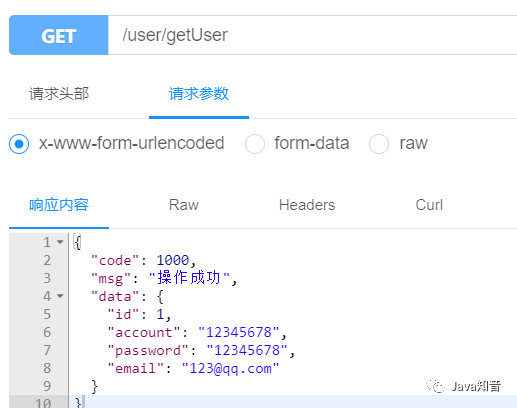
按下F12,切换到Network,刷新网页然后开始分析,很容易可以判断真正的数据请求链接为:https://nshssl.hi.163.com/file_mg/public/nsh/dasongjiaren202104/list/hot?callback=jQuery111305466870739796736_1619712866351&channel=1&page=1&_=1619712866355
-
根据既往经验,以及返回的数据内容发现jQuery111305466870739796736_1619712866351的一大堆对我们的数据抓取其实是没用的,因此这部分参数去掉后,返回的数据就是json格式了,并且更容易处理
-
channel 是赛道信息,1是美颜,2是魔音,注意3不是萌宠,萌宠是新的界面,后续有时间再去分析
-
page明显是一个页码
-
最后一个参数 _=1619712866355,这个明显是一个时间戳的毫秒形式
-
我们暂时去除jquery那个参数后看一下数据返回信息;这是一个unicode编码

-
我们继续解码后,结果为:

这是一个标准的json数据,是我们想要的结果,更换参数page=2,就是第二页的信息,没有问题 -
因此,我们已经拿到的核心的请求部分;同理修改channel,发现数据确实是是魔音赛道的,接下来开始写代码
代码模块确定
- 使用requests库,从网页获取原始数据
- 使用pandas转换并且依次合并后续数据
- 考虑到为了方便的进入对于角色的详情界面,我在结果那里增加了一个参数 href,基本组成部分为 https://n.163.com/2021/dasongjiaren4/#/detail/ + id
- 最后保存在Excel或者数据库中,本次演示保存在一个Excel文件中的两个表
准备工作
- Python环境安装 最新版Python 64位安装包
- 第三方库安装
pip install requests
pip install pandas
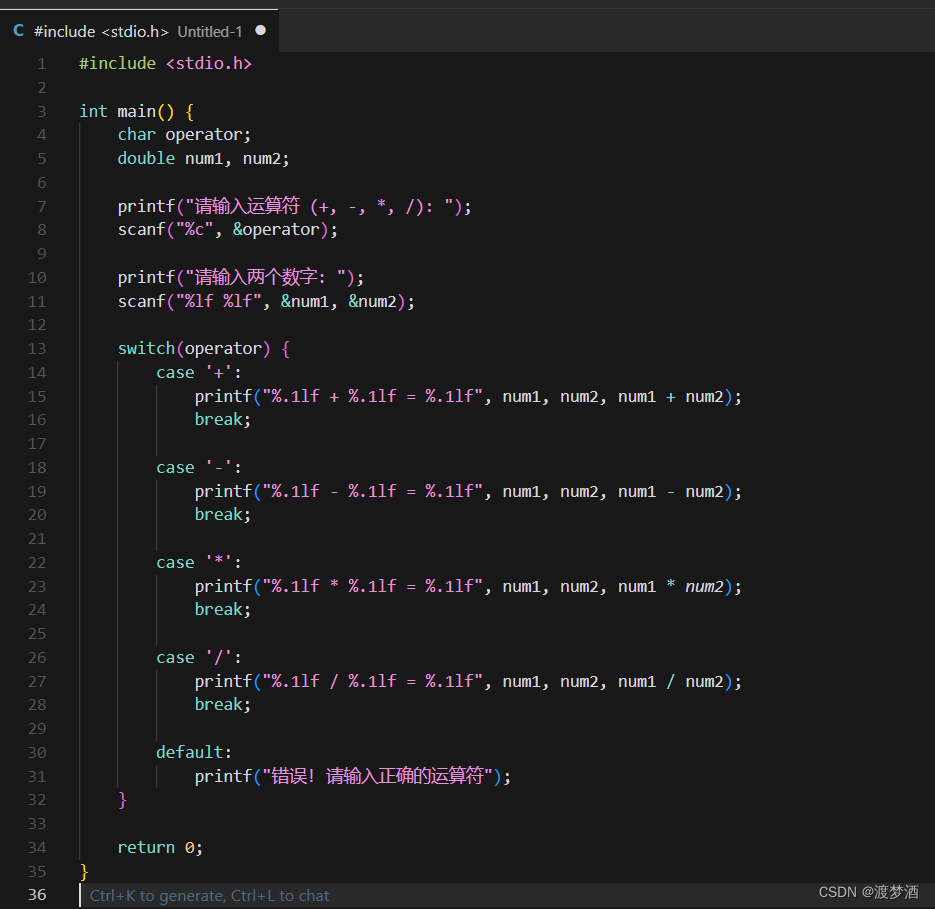
代码编写
- 代码还有很多优化的空间,如果要学习的话,请自行探索,可以与我私信交流
# !usr/bin/env python
# -*-coding:utf-8 -*-
import requests
import pandas
import timeclass DaSongJiaRen:def __init__(self):self.url = 'https://nshssl.hi.163.com/file_mg/public/nsh/dasongjiaren202104/list/hot'self.head = []self.pages = 0self.data_meiyan = pandas.DataFrame()self.data_moyin = pandas.DataFrame()def get_html(self, channel, page):"""获取源码:param channel: 频道信息,1为美颜赛道,2为魔音赛道:param page: 第几页:return:"""# 最后这个时间戳可以不要url = self.url + f'?channel={channel}&page={page}&_={int(time.time()*1000)}'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/90.0.4430.85 Safari/537.36'}r = requests.get(url, headers=headers)js = r.json()lis = js['data']['list']if not self.pages:self.pages = js['data']['pages']self.head = list(lis[0].keys()) + ['href']data = [list(each.values())for each in lis]data = [each+ [f'https://n.163.com/2021/dasongjiaren4/#/detail/{each[0]}'] for each in data]if channel == 1:if self.data_meiyan.empty:self.data_meiyan = pandas.DataFrame(data, columns=self.head)else:self.data_meiyan = pandas.concat([self.data_meiyan, pandas.DataFrame(data, columns=self.head)])else:if self.data_moyin.empty:self.data_moyin = pandas.DataFrame(data, columns=self.head)else:self.data_moyin = pandas.concat([self.data_moyin, pandas.DataFrame(data, columns=self.head)])print(f'完成{"美颜" if channel == 1 else "魔音"}赛道 第{page}页')def save_data(self):wr = pandas.io.excel.ExcelWriter('大宋佳人数据.xlsx')self.data_meiyan.to_excel(wr, index=False, sheet_name='美颜赛道')self.data_moyin.to_excel(wr, index=False, sheet_name='魔音赛道')wr.save()print('数据已保存')def main(self):page = 1while page == 1 or (self.pages and page <= self.pages):self.get_html(channel=1, page=page)page += 1print('美颜赛道信息获取完毕')page = 1self.pages = 0self.head = []while page == 1 or (self.pages and page <= self.pages):self.get_html(channel=2, page=page)page += 1print('魔音赛道信息获取完毕')self.save_data()if __name__ == '__main__':dsjr = DaSongJiaRen()dsjr.main()运行过程展示
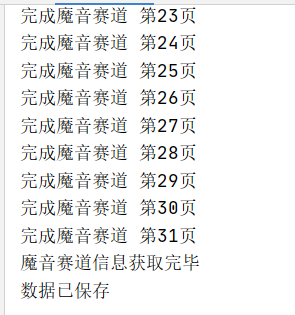
结果展示
Excel文件内容

后记
本次数据爬取仅为了练习Python网抓,请勿将数据用于非法途径,请勿侵犯个人隐私信息。数据来自网易雷火,抓取的时候,适当考虑一下延时,避免对服务器造成影响
备注
如有其他疑问,请私信我。觉得写的不错的话,来个一键三连,谢谢