为什么神经网络层数越多越好?
参考资料:https://www.zhihu.com/question/65403482、https://blog.csdn.net/weixin_44023658/article/details/106177580、https://www.bilibili.com/video/BV1bx411M7Zx
一句话回答
神经网络层数越多,对输入特征抽象的层次越深,对其理解的准确度相对来说也就越深。
神经网络关于层数的原理
人工智能的编程相比于传统编程的一个重要特点就在于,我们难以知道其内部到底是如何一步步执行,最后实现结果的?
神经网络的本质就是模仿人类大脑中的神经元组成的网络,若干神经元的激发促使另一些神经元激发。
在神经网络中,后一层神经元的输入是前一层输出的加权和,前一层的特征在后一层就被抽象出来了,学习的过程其实就是调节和优化各连接权重和阈值,并不断抽象的过程。
例如对应一个猫的识别,第一层抽象出了猫的基本特征——两只眼睛一个鼻子一个嘴巴两个耳朵,第二层抽象出了猫的耳朵应该是尖尖的,眼睛是圆圆的…而第三层我们又抽象除了更加细致的特征,以此类推…最后根据相应的算法公式,我们推出根据这些抽象,最终在输出层给出这个图片中是猫的概率是多少多少,从而得出一个结论。
浅层神经网络的特征抽象程度不高,而层次越深特征的抽象程度越高。也就是在某些特定任务上所谓的“效果越好”,这也是为什么深度神经网络可以做出很多只有人类才能做到的需要高度抽象理解能力的事情。
数字识别的例子
以一个最基础的人工智能算法来举例:手写数字识别:
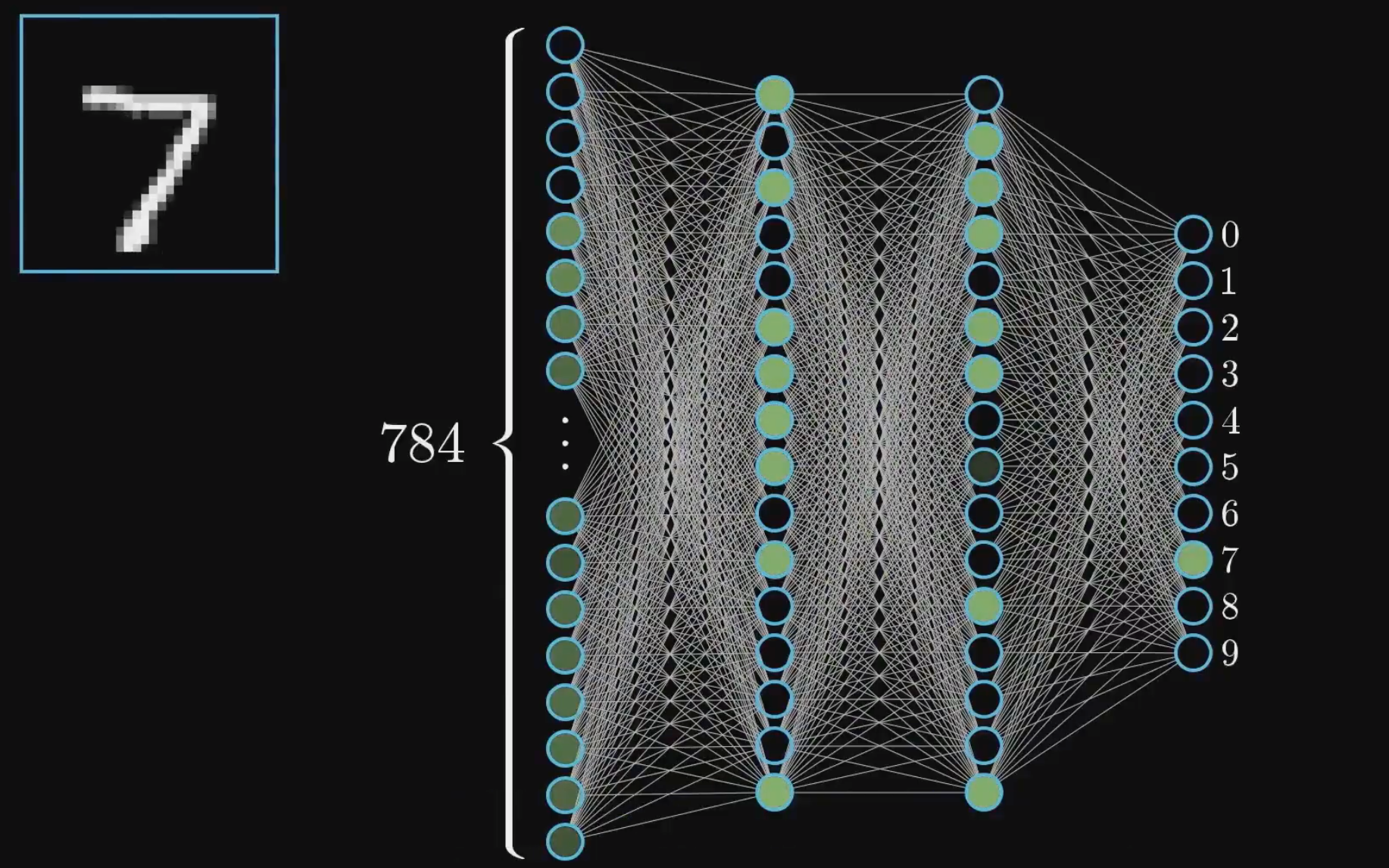
我们将一个手写数字的图片拆分成一个28*28的图片,其中每一个像素点代表该点的灰度值(0~1,越小越黑,越大越白)

而输入到输出的过程简单描述如下视频:
http://suprit-images.oss-cn-beijing.aliyuncs.com/2021-07-24-Filmage%202021-07-24_163510_MediumQuality.mp4
先来看隐含层第二层,可能各个神经元能分别对应上一个笔画部件,这就是我们前面提到的抽象。而层与层之间是有着连接的,上一层的神经元通过给定的算法公式在一定情况下才能输出到下一层,而通过诸如前向传播、反向传播、梯度下降、损失函数这些东西就可以实现神经网络的学习过程。
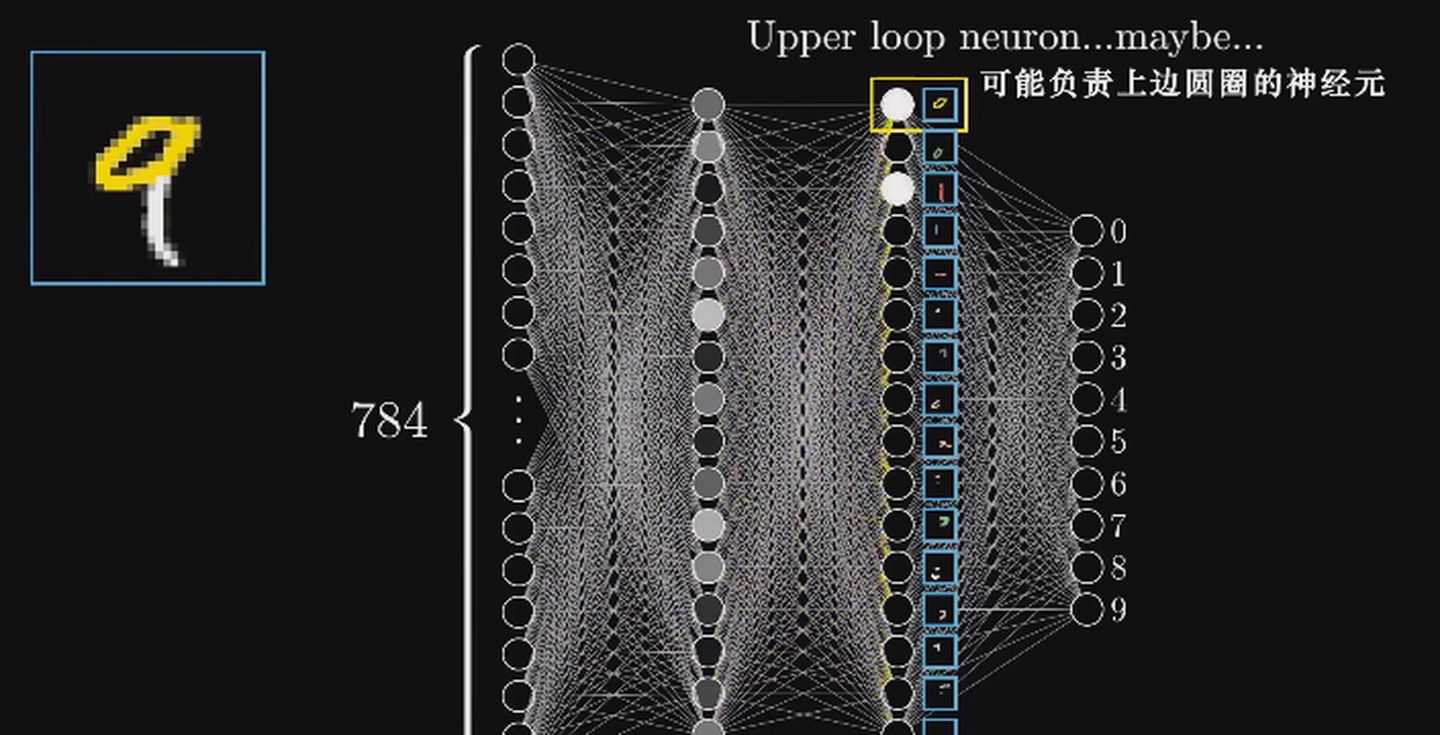

再来看隐含层第一层,识别圆圈的任务同理可以抽象成更细微的问题,也只有层数多了,才能够实现这样的抽象。
数字9的可能的特征抽象如下:

这样的原理同样可以应用到我们刚刚提到的猫的识别上,可能的特征抽象如下:

⭐️个人的一种理解
大一的C语言课上老师就告诉我,编程的逻辑无外乎只有三种:顺序、判断、循环。那么人工智能编程是一种例外吗?貌似图像识别并没有用到这三种逻辑来实现识别目标呀?
其实,从原理上来讲,这是可以实现的。以刚刚的数字识别为例,我们输入的图像为28*28个像素,每层有16个节点,分为3层,层与层的连接之间还要考虑权重和偏置,大约有784*16+16*16+16*10=13002个神经元,可以理解为有13002个情况要考虑,每一个地方的不同,都可以导致不同的结果。
我个人认为,如果你真的足够强大,使用我们大一学到的C语言,写上那么** 2 13002 2^{13002} 213002个if**,依然是可以实现图像识别这个人工智能程序的。哈哈。
从这个角度上来讲,我们在讨论机器是如何学习,其实就是想办法看看这么让电脑来妥善的处理这么一大坨参数,而使用数学公式、向量化这些东西,其实就是一个工具和桥梁,来让程序能够更好的解决问题,同时使得程序更容易编写。这就是是数学和Python的魅力所在:
增加学习次数与层数的关系和区别
有人问到,单单增加浅层神经网络的学习次数,可以提高准确率吗?
其实是可以的,但是到达一个局限值之后就再也无法提高了,甚至还会降低。而这个局限制往往会比深层神经网络要低的多。因为层数提高的是对任务的抽象程度,而学习次数仅仅是通过当前的学习方法增加熟练度。
层数真的越多越好吗?
不是说仅仅层数越多效果越好,这个还取决于你的激活函数,还有各种超参数的设置等等,关于超参数的设置属于是一个专门的领域问题。神经网络说白了就是个多层复合函数,层数越多一般会更“逼近现实”,但是也容易导致过拟合问题。
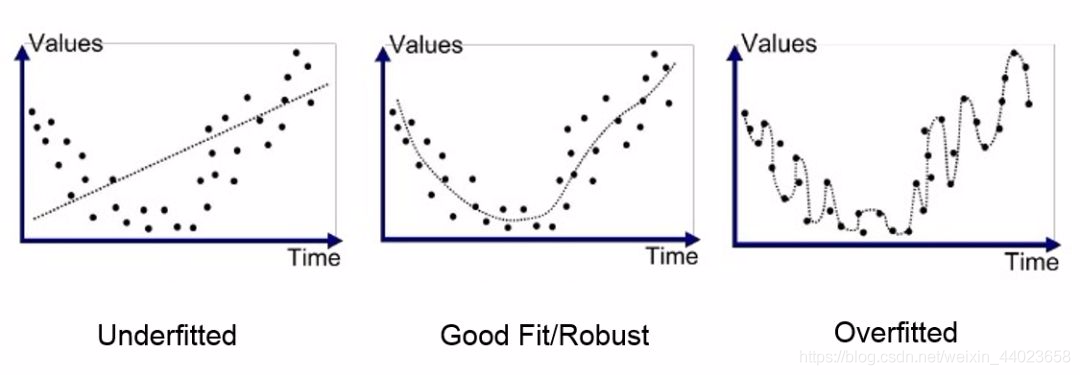
过拟合
当你的模型开始记录训练数据而不是从中学习的时候,就发生了过拟合。就好比我们在复习考试的时候一字不差背下了书中的所有内容,但知识稍微一变通,我们又不会了。
关于过拟合,依然举数字识别的例子,由于我们的层数过多,对训练数据的抽象过分到了几乎每几个像素都要抽象一下,这样就可能导致除了训练集里的图片可以百分百识别(毕竟几乎每个像素都学习好了),我们再也无法识别其他的图片。