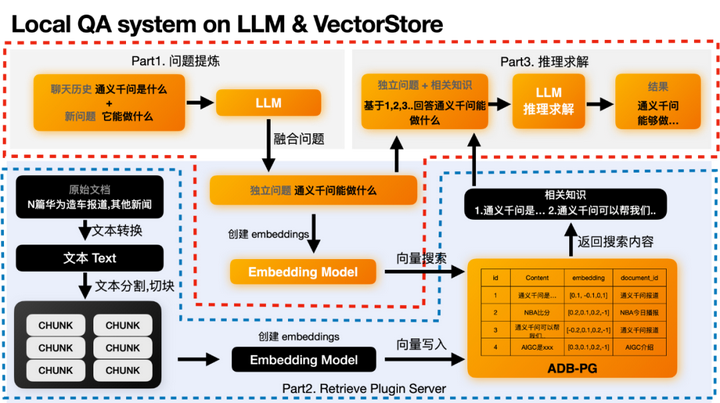
自18年谷歌BERT横空出世以来,预训练语言模型一跃成为自然语言处理领域的研究热点,海量数据与大规模模型的预训练+少量下游任务数据微调(Pre-training + Fine-tune)也成为NLP任务的新范式。从在开源数据集上进行评测到业务实践中的价值体现,预训练语言模型都被证明能够显著提高模型性能和算法效果。如果说预训练语言模型是2019年以来NLP领域的关键词,随着GPT系列模型的诞生,各大公司和研究机构的军备竞赛为其又冠上了大规模这一限定词。
4月19日,阿里巴巴达摩院发布中文社区最大规模预训练语言模型PLUG(Pre-training for Language Understanding and Generation)。该模型参数规模达270亿,集语言理解与生成能力于一身,在小说创作、诗歌生成、智能问答等长文本生成领域表现突出,其目标是通过超大模型的能力,大幅提升中文NLP各类任务的表现,取得超越人类表现的性能。发布后,PLUG刷新了中文语言理解评测基准CLUE分类榜单历史纪录。
自去年OpenAI发布超大规模预训练语言模型GPT-3引发全球热议后,中文领域同类模型的训练进程备受关注。与GPT-3类似,阿里达摩院本次发布的PLUG有望广泛应用于文本生成领域,成为“万能写作神器”。更重要的是,此类超大模型拥有极强的通用性,或将成为AI时代的新型基础设施之一。
相较于Open AI的GPT-3等其他大规模生成模型,PLUG具备如下几个独特优势:
-
PLUG是目前中文社区最大规模的纯文本预训练语言模型。
-
PLUG集语言理解与生成能力于一身,在语言理解(NLU)任务上,以80.614分刷新了Chinese GLUE分类榜单的新记录排名第一;在语言生成(NLG)任务上,在多项业务数据上较State-of-the-art平均提升8%以上。
-
PLUG可为目标任务做针对性优化,通过利用下游训练数据finetune模型使其在该特定任务上生成质量达到最优,弥补之前其它大规模生成模型few-shot inference的生成效果不足,适于应用在实际生成任务。
-
PLUG采用了大规模的高质量中文训练数据(1T以上),同时,PLUG采用encoder-decoder的双向建模方式,因此,在传统的zero-shot生成的表现上,无论是生成的多样性,领域的广泛程度,还是生成长文本的表现,较此前的模型均有明显的优势。
-
PLUG开放了体验功能供学术领域试用。

(注:4月19日,PLUG刷新CLUE分类榜单纪录,排名仅次于“人类”)
此前,达摩院机器智能实验室自研的NLU语言模型StructBERT与NLG语言模型PALM均在各自领域取得了SOTA的效果。简单来说,StructBERT模型通过加强句子级别(Sentence Structural Objective)和词级别(Word Structural Objective)两个层次的训练目标中对语言结构信息的建模,加强模型对于语法的学习能力。PALM模型则结合了Autoencoding和Autoregression两种预训练方式,引入Masked LM目标来提升encoder的表征能力,同时通过预测文本后半部分来提升decoder的生成能力。此次大规模语言模型的训练,达摩院团队汲取二者所长,提出了一个简单的框架,用来进行NLU&NLG联合训练。相比于GPT系列模型,该大规模生成模型以StructBERT作为encoder,有着很强的输入文本双向理解能力,从而可以生成和输入更相关的内容。
整个训练流程分为两个阶段。首先在第一阶段,达摩院团队训练了一个24 layers/8192 hidden size的标准StructBERT模型作为encoder。这个过程共计训练了300B tokens的训练数据,规模与GPT-3的训练规模相当。在第二阶段,达摩院团队将这个encoder用于生成模型的初始化,并外挂了一个6 layers / 8192 hidden size的decoder,在训练生成模型的过程中,在encoder端和decoder端均随机确定长度[32, 512]进行数据采样,确保适应下游广泛的生成任务。这一阶段共计训练了100B tokens的训练数据,前90%的训练中,团队保留了Masked LM任务以保持模型的NLU能力,后10%的训练中,去掉MLM任务进行微调,以使得生成的PPL降到更低,能取得更好的生成效果。

PLUG生成模型有着很强的长文本生成和建模能力,相比于GPT系列模型的单向建模,PLUG对输入的理解是双向建模的,因此能够在给定小段输入的条件下,生成和输入内容相关且信息量丰富的长文本。直接用预训练好的模型在小说续写、诗歌生成、菜谱生成等场景下测试,示例如下:
小说续写
输入:话说宝玉和凤姐回家,见过众人,宝玉便回明贾母要约秦钟上家塾之事,自己也有个伴读的朋友,正好发愤;又着实称赞秦钟人品行事,最是可人怜爱的。凤姐又在一旁帮着说:“改日秦钟还来拜见老祖宗呢。”说的贾母喜欢起来。凤姐又趁势请贾母一同过去看戏。贾母虽年高,
输出:但身上还有几分力气,便命凤姐陪她看戏。贾母一个劲儿的让出一条道来,凤姐便陪他到一边。不想戏刚刚上场,只见从人堆里,挤出两个老人来,都是身着绸衣,头上扎着两根簪儿,后面跟着两个老人。贾母一眼便认出来,这便是邢岫烟。这邢岫烟原是贾环的外孙女婿,邢夫人的外孙宝玉看了,也不觉的诧异。一时,那邢岫烟和贾环一干人等,就围着贾母、凤姐、秦钟等。一时,邢岫烟又叫:邢夫人来。贾环等不胜其扰,一时都来到邢夫人的房门口。只见邢夫人正站在窗口,向窗内张望。邢岫烟便向邢夫人笑道:邢二婶子,你看这窗户这么大,难道窗子不是贾环等听见,都来看戏。只见邢夫人也在一旁,忙向邢夫人打听起邢岫烟的来历来。邢夫人听见贾环在此,忙向邢岫烟说道:邢夫人,你也在这里看戏。邢岫烟听说,忙向邢夫人道:邢二婶子,你来的正好,正好可以问问你。邢二婶子,你可认得他么?邢夫人道:认得。邢夫人笑道:你认得他吗?
论文撰写
输入:目标检测是计算机视觉的一个重要研究方向,其目的是精确识别给定图像中特定目标物体的类别和位置。近年来,
输出:视觉技术已经成为计算机视觉领域中研究热点,视觉智能的发展将对传感方式、感知技术、图像处理技术、自然语言处理等方面产生深刻影响。视觉传感器在工业生产、军事领域中的应用已越来越广泛。但是我们在实际生产中经常遇到一些难题,例如传感器的检测难题,传感器的校准难题,传感器的应用领域不明确,传感器的性能评估不一致等等,这些都是传感器在工业生产中实际应用中遇到的难题。
生活解答
输入:孩子学习成绩差怎么办?
输出:作为家长,我们对孩子学习成绩的关注度不仅仅是指孩子学习成绩,还包括孩子的学习状态、学习方法和学习习惯,如果孩子的学习成绩不是特别理想,我们是不是首先要帮助孩子找到原因?对孩子心理学的学习成绩,很多家长都说不好,有的父母会说我的孩子怎么这么笨,我的孩子都这么笨,我这么努力就是为了他学习。其实,孩子心理的学习成绩的好坏不仅是学习的效率,还有学习的能力。孩子从小学习的是他人对他的期望,他要有更好的人生,这样他的心理就会健康和谐,家长能够给孩子更多的关注,才会有更好的发展。
古诗生成
输入:寒随穷律变,春逐鸟声开。初风飘带柳,
输出:风至一枝春。含情春草绿,带笑暮花红。春日野田行,风烟寒树迥。清明带雨过,谷雨烧畲烟。农事一年最,家家插秧忙。田间地头水,桑下屋后苗。
零样本学习
除此之外,PLUG模型在零样本fine-tune的情况下也能完成多种类型的下游任务,包括分类任务、自然语言推理任务等,示例如下(下面样本来自中文CLUE榜单的OCNLI-中文推理数据集):
输入:他以身殉职,终年59岁。他是在今年去世的。这两句话什么关系:中立。实施更大规模的减税。即将实行减税。这两句话什么关系:包含。
实施更大规模的减税,即将缩小减税规模。这两句话什么关系:对立。
州立大学,到那读博士去了。州立大学没有博士点。这两句话什么关系:
输出:对立
输入:他以身殉职,终年59岁。他是在今年去世的。这两句话什么关系:中立。
实施更大规模的减税。即将实行减税。这两句话什么关系:包含。
实施更大规模的减税,即将缩小减税规模。这两句话什么关系:对立。
州立大学,到那读博士去了。有人到州立大学读博士。这两句话什么关系:包含。
州立大学,到那读博士去了。州立大学很受欢迎。这两句话什么关系:中立。
扎实推进乡村建设。乡村需要建设。这两句话什么关系:
输出:包含
关于大规模预训练语言模型的发展趋势,达摩院深度语言模型团队负责人黄松芳表示,“一方面将从数据驱动(Data-driven)逐步发展到知识驱动(Knowledge-driven),探索数据和知识深度融合的预训练语言模型;另一方面将不仅仅追求模型参数规模扩大,而会更关注超大模型的落地应用实践,探索低碳、高效、业务可用的预训练语言模型。”
接下来,PLUG将扩大参数规模至2000亿级,并进一步提升文本生成质量。与PLUG发布同步,达摩院宣布近期将开源阿里巴巴深度语言模型体系大部分重要模型。阿里达摩院语言技术实验室负责人司罗表示,“达摩院NLP团队将进一步攻克自然语言处理领域科研难题,完善中文及跨语言人工智能基础设施,让AI没有难懂的语言,并探索通用人工智能之路。”
在超大规模预训练模型领域,除发布以中文为核心的PLUG外,阿里达摩院、阿里云计算平台团队还联合智源研究院、清华大学发布了面向认知的超大规模新型预训练模型“文汇”,以及联合清华大学发布了超大规模多模态预训练模型“M6”。
测试地址:https://nlp.aliyun.com/portal#/BigText_chinese

60+专家,13个技术领域,CSDN 《IT 人才成长路线图》重磅来袭!
直接扫码或微信搜索「CSDN」公众号,后台回复关键词「路线图」,即可获取完整路线图!