文章目录
- 问题简述
- 问题背景
- 问题描述与目标
- 评估指标
- 以往工作
- PowerNet: Transferable Dynamic IR Drop Estimation via Maximum Convolutional Neural Network
- Thermal and IR Drop Analysis Using Convolutional Encoder-Decoder Networks(EDGe)
- BeGAN: Power Grid Benchmark Generation Using a Process-portable GAN-based Methodology
- 总结
这篇博客是针对ICCAD 2023 的peoblemC(用机器学习模型预测电路的IR Drop)的理解。
问题简述
问题背景
电力供应网络(Power delivery network, PDN) 是芯片设计中一个关键网络,它需要把电压给到每一个需要电的元器件。但由于供应网络中可能会有某些寄生效应导致元件实际收到的电压低于供应值,如果某个元件实际收到的电压比供应值低太多,可能就不能正常工作,所以当一个电路设计好之后,需要进行分析看看设计是否合理,即需要检查是否会存在电压降的太多的区域。
如图是一个电力供应网络的例子,它可以抽象为一些电流源、电压源、导线和电阻组成的网络。
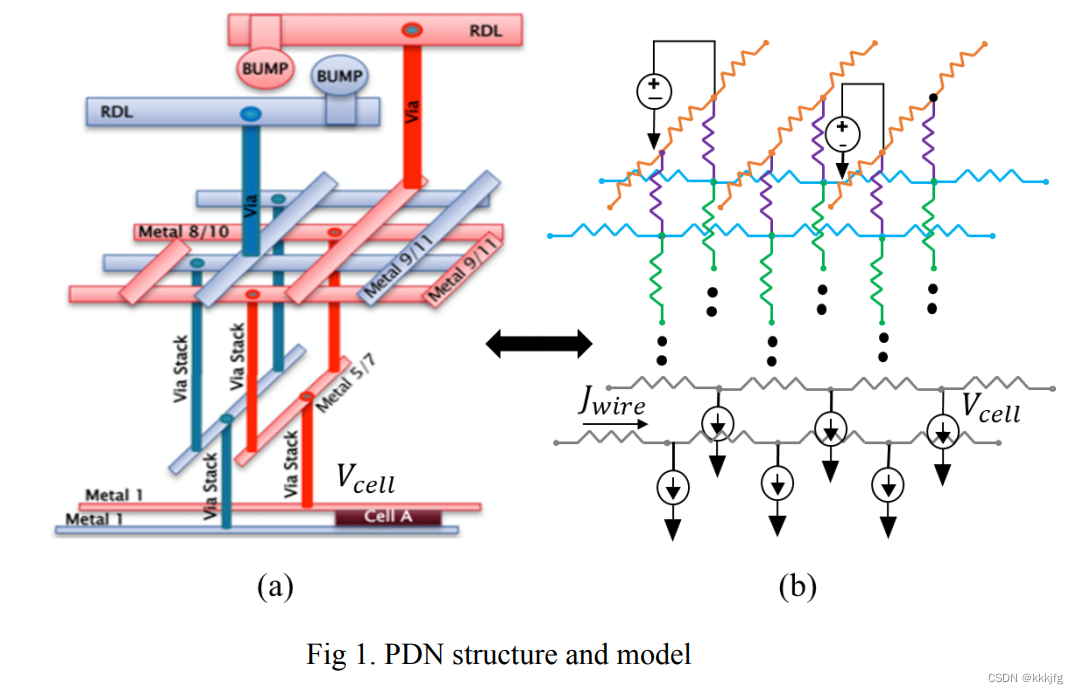
问题描述与目标
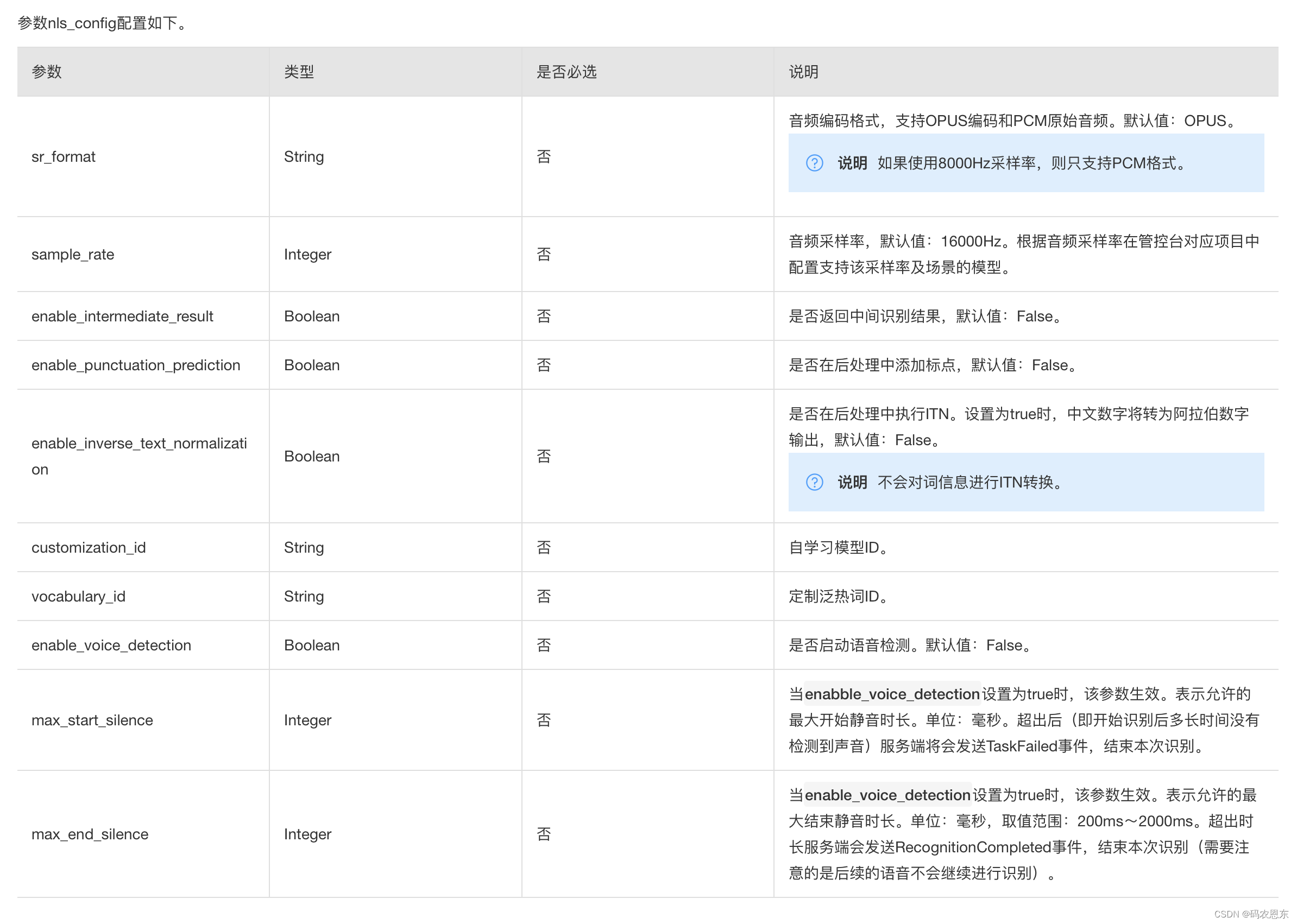
从这个比赛的赛题就知道,这个题目是希望参赛者使用机器学习的方法对压降进行预测。输入输出的格式也给好了:
(1)第一种是准备给计算机视觉模型的图片版输入输出,数据格式是csv,
输入是三张图,即一张电流图,一张PDN密度图和一张电压源有效距离图,大小都是80X80。
输出是一个压降图,大小也是80X80
所以赛题目标就是根据三张输入图预测一张压降图。
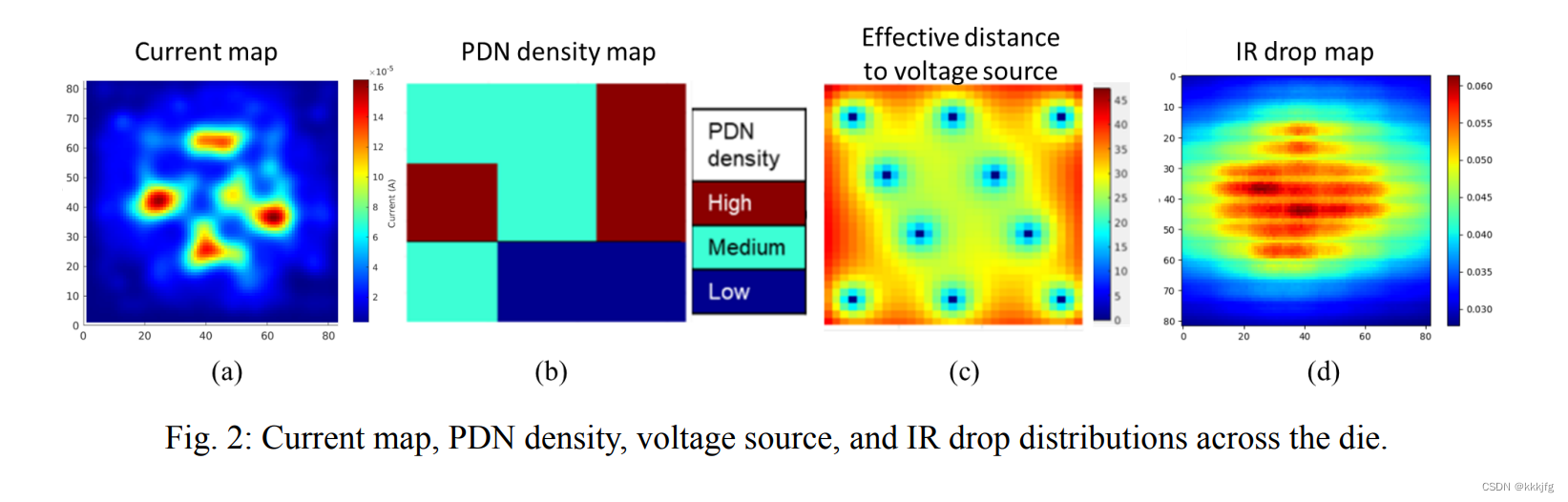
以上是一组输入输出的可视化。看上去是规模很小的预测,比很多cv任务的1080*1920之类的大小要小多了。
第二种输出是给图神经网络模型的, 基于SPICE的数据
这种数据是如图1(b)所示的PDN模型的SPICE电网表。
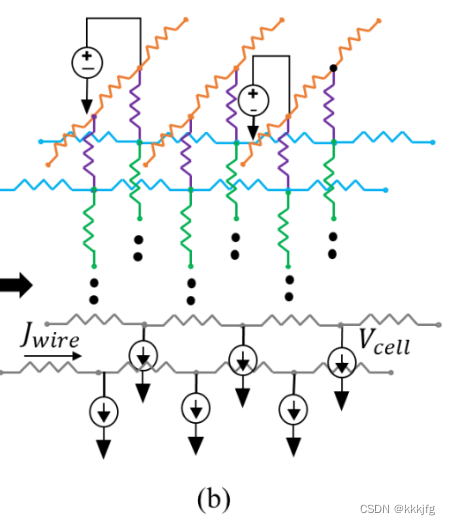
SPICE网络列表把PDN网络描述成了一些电阻,电压源,电流源的组合,以下是一个例子:
R645 n1_108000_179200_1 n1_102600_179200_1 0.14
R646 n1_113400_179200_1 n1_113400_179200_3 4.23
I7 n1_113400_179200_1 0 4.24901e-08
V0 n1_81000_106230_7 0 1.1
格式是 <电气元件> <节点1> <节点2> <值>。
其中“电气元件”可以是电阻,电压源或者电流源
每个节点引用的时候会带上它的隶属网络名称,坐标,层编号四个数字,用下划线隔开,形如:
<网络名称>_<x坐标>_<y坐标>_<层编号>
R646 n1_113400_179200_1 n1_113400_179200_3 4.23就是一个值为4.23的电阻,是位于n1网络中的,电阻连接113400,179200和113400,179200两个点。
在上面的例子中,R646所连接的两个节点的x和y坐标相同,但层数不同,所以是通孔(via)。I7是连接到位置(113400,179200)处的节点的电流源,V0是位于节点(81000, 106230)处的电压源。 SPICE中的位置以纳米为单位表示。
赛题上说“SPICE网络列表格式的输入具有之前所说的图片版本的三个输入图的所有信息”,应该是有道理的,因为这里直接就给的是原始网络信息,应该是可以推导过去的,之前图片版本的三个输入图看上去也只是取了电路的 一部分特征出来罢了。
讲道理这第二种输入格式的信息应该是更丰富的更能推导出更好的预测,但可惜我不太会直接跑图神经网络,也一下子没想到除了那三个特征(电流图,供应网密度,有效电压源距离)之外还能怎么抽取更多的特征。
压降的标签和之前图片版的一样,是80X80的图。
评估指标
评估指标有4个:
- 平均绝对误差(MAE)
- F1 score = 2 * Precision * Recall / (Precision + Recall)
- 运行时间
- 模型大小
最终的得分是“这四个指标的函数”
以往工作
对于压降预测,最准确的应该是直接利用电路的电阻,电压源,电流源算,而且对于压降的计算,这三个是充分必要条件,直接拿这些条件计算看起来是最好的。
基于这种思想可以直接拿“Modified Nodal Analysis(MNA)”的方程来解。
(此处可以参考博客https://blog.csdn.net/weixin_44381276/article/details/112505698, https://zhuanlan.zhihu.com/p/464409274)
G V = J GV=J GV=J
通过连通性矩阵 G G G和各边电压 J J J能直接解出压降 V V V。
这个方法说实话看得不是很懂,不过还好这个赛题不是考这个的,因为直接解算比较慢,这个赛题希望直接用机器学习模型进行预测。
此前已经有许多基于机器学习模型进行预测的工作了,以下介绍几个比较相关的。
PowerNet: Transferable Dynamic IR Drop Estimation via Maximum Convolutional Neural Network
概括地说,这个网络是把电源供应网络划块作为最小讨论单位(比如划成80X80的分区),然后手工抽取了很多特征,对于某一个小区域,尝试截取这个区域周围的一个窗口的特征图,送进卷积网络,预测这个区域的单值。
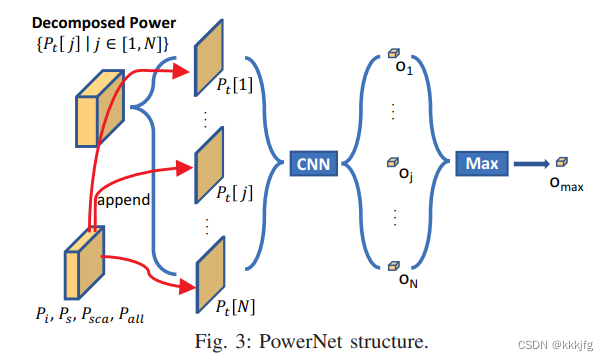
对应题目的“Maximum Convolutional Neural Network”的Maximum,这篇工作借用了时间轴信息,即什么时候什么元件会工作。然后根据时间轴进行划片,弄一个特征数组 P t P_t Pt(如上所示),对各时间段都进行预测,然后取一个最大值作为输出。上图的“CNN”对应一个卷积神经网络,如下图。
看上去就是正常的一个小卷积网络。
总结一下,就是对网络进行划块,并抽取了一些特征,如 P i , P s , P s c a , P a l l P_i,P_s,P_{sca},P_{all} Pi,Ps,Psca,Pall,然后又根据这些特征,加上不同器件在不同时间的使用情况建立了 P t P_t Pt数组(P_t的shape应该是T×K×K),最后输入一个处理K×K大小的卷积网络。在T维上取最大值,得到压降预测。
训练流程如下:

可以看到,这个算法每次只取一个位于(x,y)周围的区域(第9行),遍历取出 P t P_t Pt中的值(第11-12行),每次对这个位置预测一个压降并算loss,这篇文章使用了L1loss,即绝对值误差作为与标签的loss。
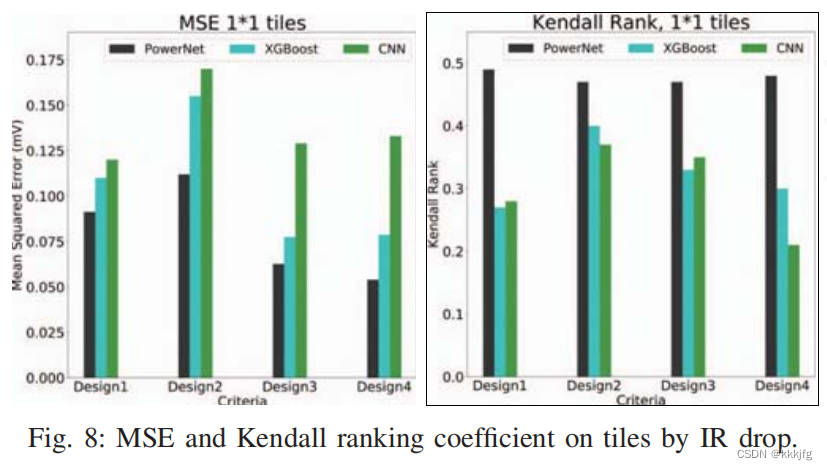

精度上比以往的方法要更准了,但这篇工作推理并不快,作者说是因为这篇文章使用了时间的信息,每个区域都产生了t个解。
Thermal and IR Drop Analysis Using Convolutional Encoder-Decoder Networks(EDGe)
这篇工作是和这个题目最相关的,输入格式和这个题目提供的第一种输入格式一致,效果也不错。
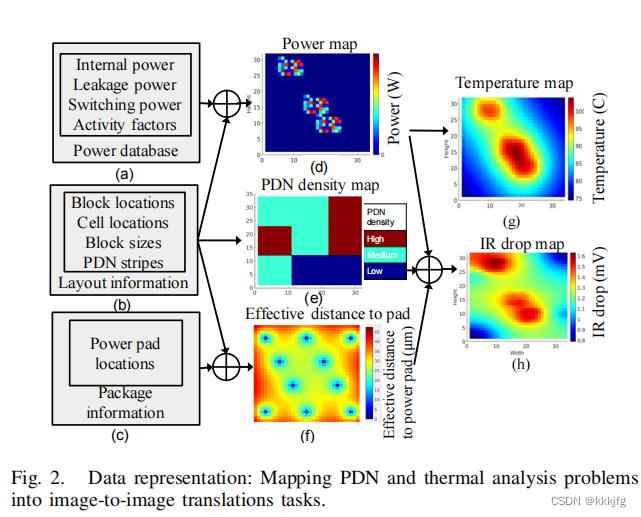
整体框架如下,把Power map,PDN density map, Effective distance to pad三张图拼起来送进网络直接预测就可以了。
这篇文章提出的网络模型是比较泛的“encoder-decoder”模型,即编码解码器结构,是经典的生成模型结构。文章给了两个具体的模型,即UNet和ConvLSTM。如下,是一个UNet结构:
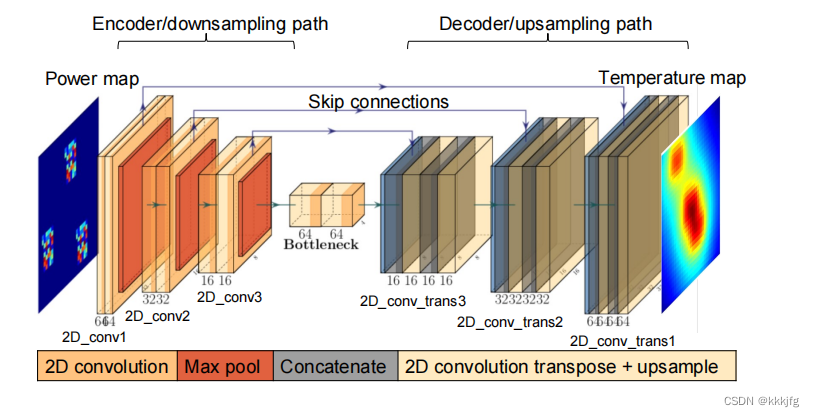
(这个图里画的是“Temperature map”, 但IREDGe和ThermEDGe好像是共用的同一个模型。)
以下是ConvLSTM版的,使用ConvLSTM版的好处在于可以加点时序信息,喂进去不同时间点的power maps进去,预测不同时间点下的温度、压降图。
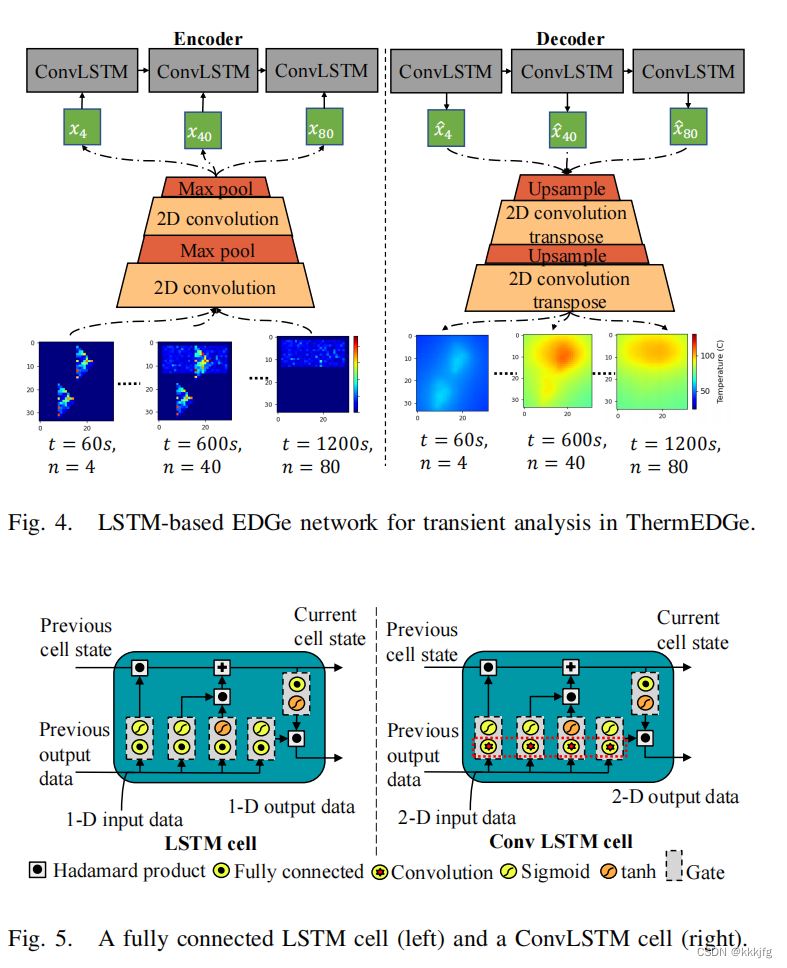
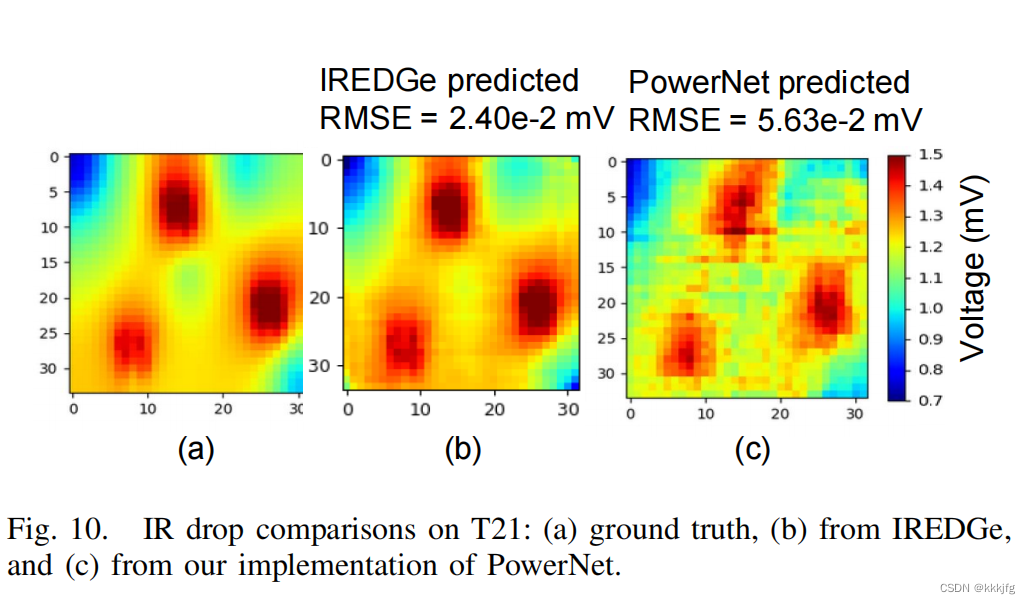
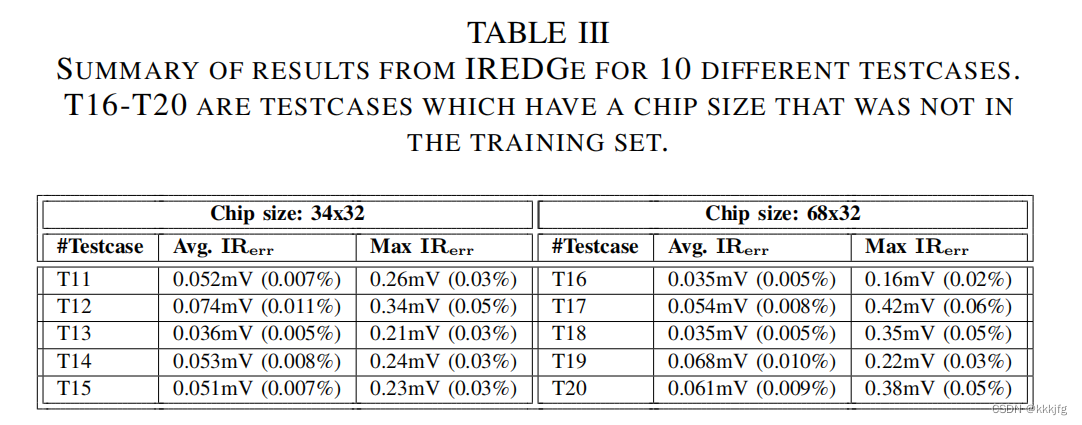
从效果图看,这篇文章的方法生成的IR Drop预测要准确一些且平滑一些。平滑是因为这篇文章用的模型是直接对全局进行的预测,而不是逐个区域地进行预测。直接喂入全图还有一个好处,就是可以不用像PowerNet那样手动设置window size这个超参,且从结果来看,EDGe这个模型对于不同大小的输入有一定的泛化能力:
BeGAN: Power Grid Benchmark Generation Using a Process-portable GAN-based Methodology
从前面介绍的两篇工作可以看出,预测压降这个任务的数据是很少的,这严重地制约了训练一个好模型。所以这个赛题提供了一个混合数据集,有GAN生成的数据和真实数据。赛题建议选手使用生成数据进行训练,再在真实数据上进行微调以最大化利用数据。
BeGAN是赛题所列的参考文献中的一个,它可以生成一些数据,以下是大致介绍。
生成什么数据呢?主要是电流图。为什么要生成电流图呢?主要是因为电流图可能会暴露一些芯片下面的模块,有泄露知识产权的风险,所以目前只有非常有限的真实芯片的电流图可供机器学习模型学习。所以很多PDN网络基准测试是基于很不真实的不连续的“格子电流图”产生的。如下左侧是经过处理的电流图,对应右侧的真实电流图,可以看到左侧的格子深浅和右侧基本一致,但很粗糙不如右边的精细。
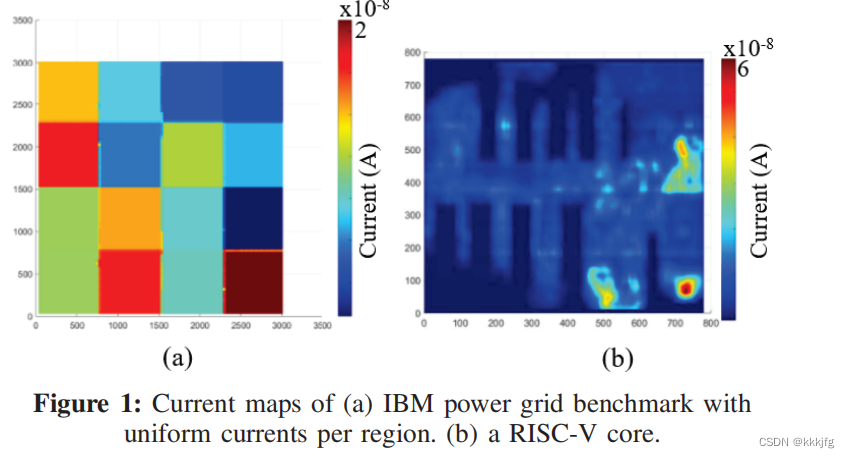
所以获得更多逼真的电流图就变得尤为关键。
讲生成方法之前我先插播一个问题:产生电流图,和这个赛题的预测IR Drop有什么联系?这个我大致看了全文也没理解,我问了问chatgpt IR Drop是怎么生成的,是模型预测的吗,以下是chatgpt的回答:
“BeGAN基准测试中的IR降是通过工具生成的。具体来说,BeGAN生成器使用GAN技术合成了一个符合要求的CM(电流图,current map)图案,并使用OpeNPDN工具合成了一个与该CM图案相对应的PDN网络。随后,基于OpeNPDN和SPICE仿真器,可以计算PDN网络中节点的电压和相应的R降,这些R降即为BeGAN基准测试中使用的R降数据。总之,BeGAN基准测试中的R降不是横型预测得出的,而是通过工具自动生成的。”
有点道理,就是说,我们是有工具能轻易做出一个符合电流图的电路的,然后有了电路就可以直接解算IR Drop。
以下是BeGAN的整个框架。注意看中间下面的“Current maps”,GAN的作用止步于此。这个maps后续会丢到“Power grid synthsis”工具里,生成完整的基准测试。这篇文章所提出的模型是专注于生成逼真电流图的。
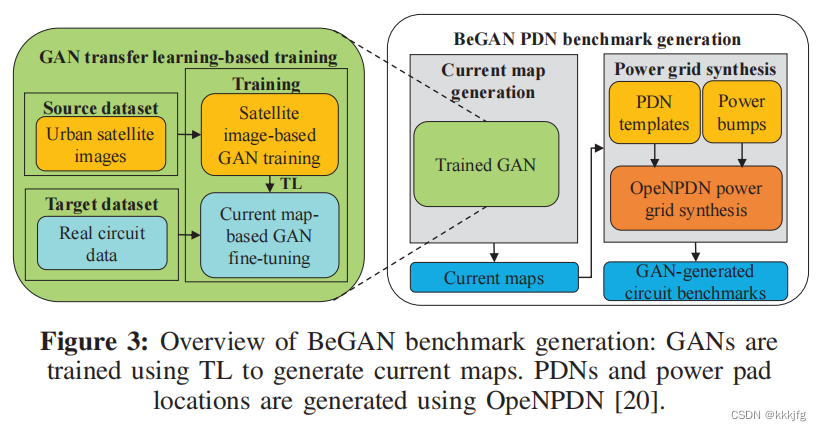
至于GAN的训练过程,作者很巧妙地使用了迁移学习。因为即使是使用GAN网络生成,目前已有的真实电流图也远达不到需要的数据量。这里作者很巧妙地使用了另外一种图像进行预训练——卫星拍摄的街道图像。

以上就是一个例子。我在看到文字之前单看这个图我还以为是一个真实的芯片图。确实很像,那个树木跟引脚似的,这些房子看起来很像宏单元。右边的图是经过颜色变换从左边变过去的,刚好在芯片电流图中“hot spot”热点区域是全图存在,但面积不大的,卫星图经过变换后也刚好符合这个特征。
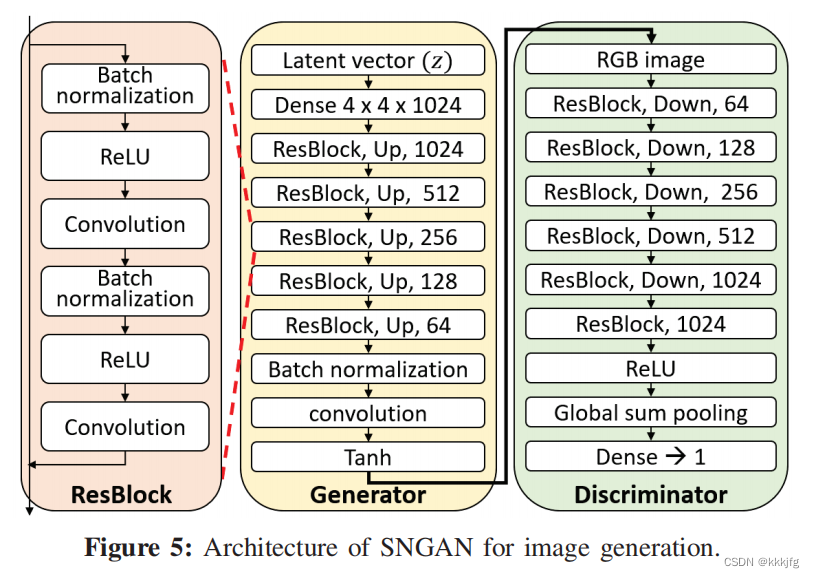
这上面就是这篇文章采用的模型SNGAN的结构,作者先把这个模型在卫星图上进行预训练使其具有生成卫星图的能力。
然后进行迁移学习,在真实数据上微调。
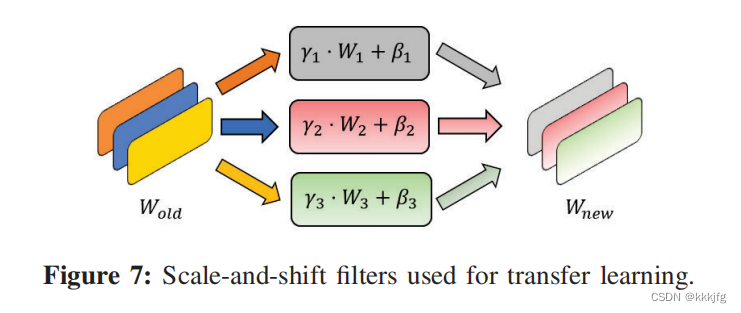
微调阶段,作者锁死卷积神经网络的权重矩阵,模型中仅学习两组参数,即权重矩阵的缩放和偏移 γ \gamma γ和 β \beta β。
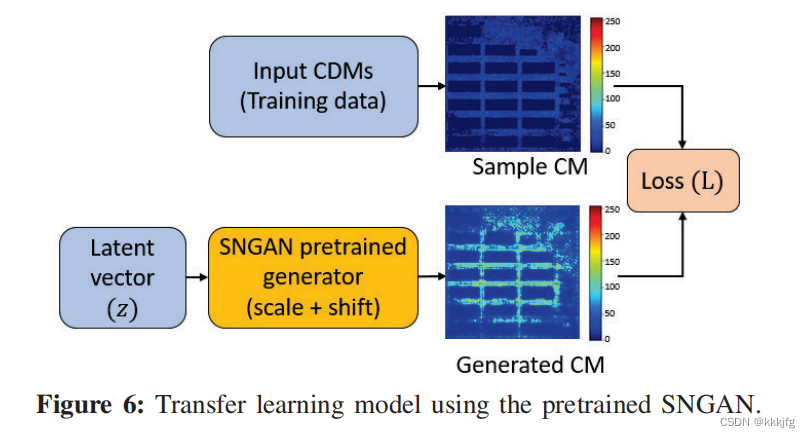
而迁移学习过程中,采用了一种和GLO(Optimizing the latent space of generative net works)一样的策略,去除了GAN中的判别器,直接让生成的图片和真实图片做loss。loss表达式如下。
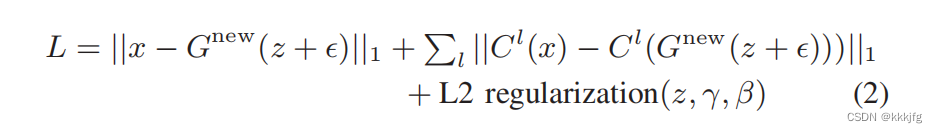
第一项是生成图和原图的L1 loss, C l ( x ) C^l(x) Cl(x)是perceptual loss, 用的是过了vgg网络之后的几层特征的L1 loss, 用这个loss是希望从高层语义特征上希望生成图和原图“看上去是一个东西”。
当然这里有个疑问,为什么随机的lantent vector生成的图能直接和原图做loss呢?其实这里latent vector是可学习的,所以模型能在可能的生成结果中找一个和真实图片最接近的结果与真实图片进行对齐。文中的说法是"learns to map learnable latent vectors to samples in a target dataset by minimizing reconstruction loss"。
总而言之根据我的理解,GLO这种方法就是在训练时同时学习latent vecter和网络参数,具体到这个任务而言,“可学习latent vecter”这个设定使得生成结果可以最大程度和真实数据对齐,并使得网络参数能进行学习,让生成的“卫星图”能更进行一些变化以更接近真实的电流图。
总体而言,这篇文章还是比较巧妙的, 运用了卫星街道图片进行预训练, 又用了GLO进行迁移学习,使得能用很小的真实电流图训练,就能生成许多逼真的电流图,进而可以使用工具制作PDN benchmarks。
总结
看下来的感觉有一些感觉:
1,ML在EDA领域,至少是IR Drop上的应用还在比较初步的阶段。用的模型都比较简单。
2,这个问题包含很多手工特征信息,比如赛题这种PDN density map, PowerNet中的 P i , P s , P s c a P_i,P_s,P_{sca} Pi,Ps,Psca等。所以是一个依赖知识与建模的问题。
3,这个问题的输入输出,从计算机视觉的角度看,都是比较简单的EDGe那篇的输入甚至是32*32,不到一百个数据的数据量,或许关键点在于数据量小且需要防止过拟合?
4,这个问题的loss看上去比较奇怪,直接是用F1,F2 loss这种回归一个范围不定的值,感觉应该还有更合适的,比如IOU之类。
5,看了几篇EDA的论文,发现和cv领域真的太不一样了,行文比较随意一些,即使是ICCAD这类的顶会,感觉语言通顺度和好理解程度上都不如CVPR,ICCV这些会议的文章,且论文用图居然是很糊的,即使是简单图也没有做成矢量图,感觉没有很认真在作图,用糊图都是表达与交流课老师再三强调不要犯的。指标对比也用的是柱状图,没有大部分cv论文写的清楚明白。可能这个领域还没有很卷。