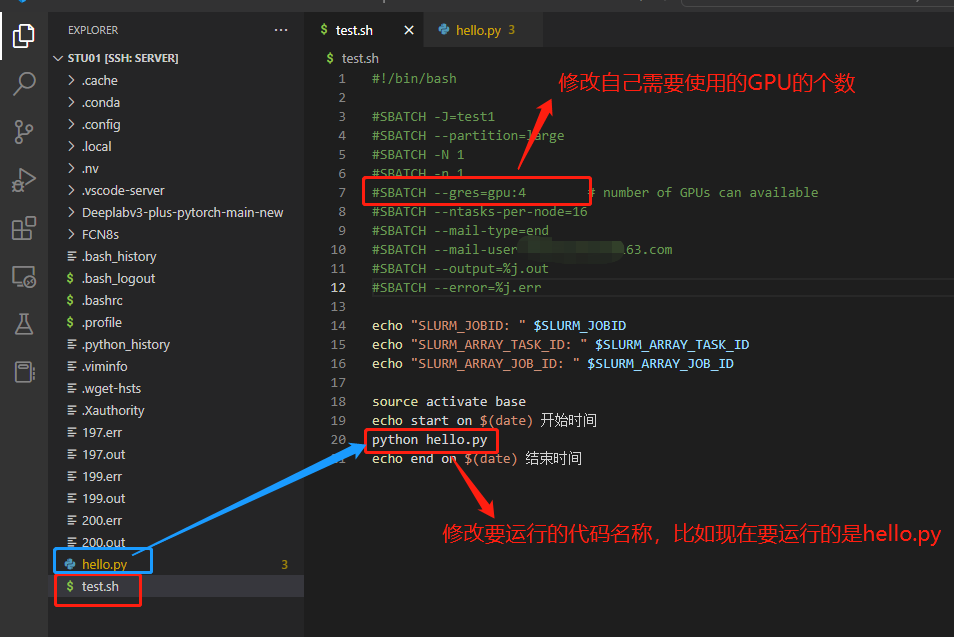
| 文章来源于:“鹅厂技术派”公众号
大模型要成功,算力是关键。
这是腾讯云面向大模型训练场景,发布的全新一代的HCC高性能计算集群性能参数:
“算力性能和上一代相比提升3倍,服务器接入带宽从1.6T提升到3.2T。”
采用最新一代腾讯云星星海自研服务器,并搭载NVIDIA H800 Tensor Core GPU的这代HCC高性能集群,单GPU卡支持输出最高1979 TFlops的算力。
具体强在哪里?
去年10月,腾讯完成首个万亿参数的AI大模型——混元NLP大模型训练。在同等数据集下,将训练时间由50天缩短到11天。如果基于新一代集群,训练时间将进一步缩短至4天。
单纯堆卡,算力并不能线性增长
大模型热度持续高涨,但要训练一个成功的大模型,算力,算法、数据三者缺一不可。
越强的大模型,越需要更强的算力来完成训练。拥有强大的算力是AI大模型成功的关键。
在单体服务器计算能力有限的情况下,需要将上千台服务器相连,打造大规模、分布式的高性能计算集群。业界标杆的大模型,对训练算力需求普遍非常高,使用成千上万张GPU卡。
如此庞大的参数规模,单独一块GPU运算卡甚至都完成不了最基本的装载,这也使得我们要用网络联接成千上万的服务器组建大规模算力集群,为大模型提供所需的算力。
HCC高性能计算集群就是在这样的需求下诞生,但是,要把这么多的卡“串联“起来,背后需要很强的技术能力。
因为根据木桶效应,单纯堆卡并不能带来算力的线性增长。它需要的是计算、存储、网络以及上层的框架等各个环节全面协调配合,才能输出一个高性能、高带宽、低延迟的智算能力平台。

最强算力背后是底层自研技术的突破
为了提供极致的算力输出,腾讯云HCC高性能集群,从底层基础设施到上层的训练框架,做了多方面的技术创新。
计算:业界领先的超高密度,将单点算力性能提升至更高
服务器的单机性能是集群算力的基础。在非稀疏规格情况下,新一代集群单GPU卡支持输出最高 495 TFlops(TF32)、989 TFlops (FP16/BF16)、1979 TFlops(FP8)的算力。
针对大模型训练场景,腾讯云星星海服务器采用6U超高密度设计,相较行业可支持的上架密度提高30%;利用并行计算理念,通过CPU和GPU节点的一体化设计,将单点算力性能提升至更高;
全面升级第四代英特尔至强扩展处理器,服务器PCIe带宽、内存带宽最高提升100%。
网络:自研星脉高性能计算网络,将集群算力再提升20%
我们知道,模型参数量越大,对带宽的需求就越高。成千上万的GPU卡协同工作数周甚至更久,GPU 与 GPU 间、服务器与服务器节点之间存在海量的内部数据交互需求。
传统的中小模型训练,往往只需要少量 GPU 服务器参与,跨服务器的通信需求相对少,可以沿用通用的 100Gbps 带宽。而万亿参数大模型训练,是一种带宽敏感的计算业务,往往是All-to-All的通信模式。
在大模型场景下,相比单点GPU故障只影响集群算力的千分之几,一条链路的负载不均导致网络堵塞,就会成为木桶短板,影响到数十个甚至更多GPU的连通性。
同时,集群训练也会引入额外的通信开销,导致 N 个 GPU 算力达不到单个GPU 算力的N 倍。业界开源的GPU集合通信库(比如NCCL),也不能将网络的通信性能发挥到极致。
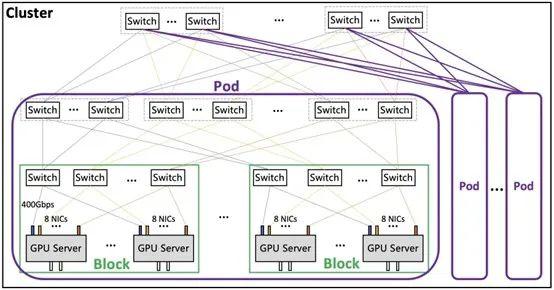
如果说业界最新代次的GPU是跑车,那么我们需要一条专业赛道,才能让N个GPU组成的大模型训练集群最大限度地发挥潜力。
腾讯自研的星脉高性能计算网络,就是这条专业赛道。这条赛道对GPU集群网络做了深度定制。增加了网络节点带宽,为计算节点提供3.2T ETH RDMA高性能网络,大幅降低了通信耗时的占比。
这相当于同样的GPU卡,用超带宽网络将集群算力提至更高。实测结果显示,搭载同样的GPU,最新的3.2T星脉网络相较1.6T网络,让集群整体算力提升20%。
这条赛道,对“交通规则”也做了优化。在大规模的训练集群中,GPU之间的通信实际上由多种形式的网络承载,有机间网络,也有机内网络。
传统上的通信方案,存在大量的机间网络通信,导致集群的通信开销很大。星脉高性能计算网络将两种网络同时利用起来,将小流聚合为大流,通过减少流量的数目,从而提升整网的传输性能。实测显示,在大规模All-to-All场景下,星脉高性能计算网络能帮助通信的传输性提升30%。

基于多轨道聚合的无阻塞网络架构、主动拥塞控制和定制加速通信库,目前,新一代集群能提供业界领先的集群构建能力,支持单集群高达十万卡级别的组网规模。
在超大集群场景下,仍然能保持优秀的通信开销比和吞吐性能,满足大模型训练以及推理业务的横向扩展。
存储:TB级吞吐能力和千万级IOPS,减少计算节点等待
近5年,模型参数量增长十万倍,而GPU显存只增长了 4 倍。理论上,云上的池化资源能解决这一问题。
但训练场景下,几千台计算节点会同时读取一批数据集,存储桶还面临着高并发的问题。大模型的数据集主要是GB级的大文件,从加载模型到启动完成需要数分钟,如果GPU资源闲置,也会拖慢整体训练效率。
如果说大模型算力中的网络,是为GPU修了一条专业赛道。那么高性能存储,则是一个“秒换轮胎”的维修站,提前备好数据,尽量减少计算节点的等待,让集群性能进一步逼近最优。
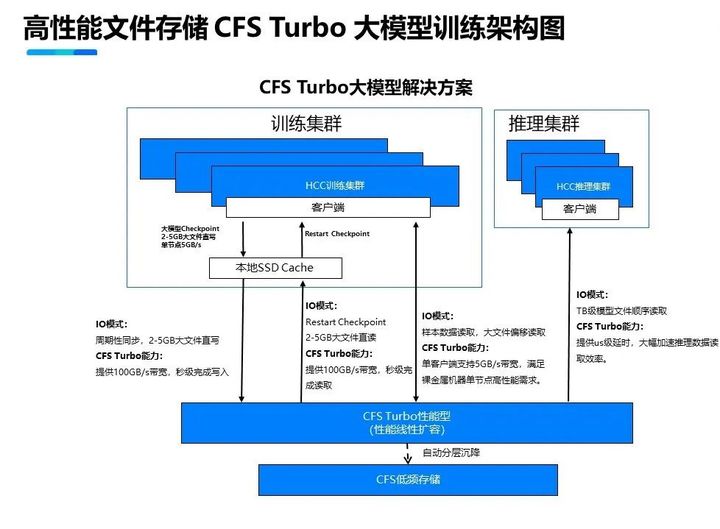
新一代集群,引入了腾讯云最新自研存储架构,具备TB级吞吐能力和千万级IOPS,支持不同场景下对存储的需求。
COS+GooseFS方案,提供基于对象存储的多层缓存加速,大幅提升端到端的数据读取性能,为大模型场景提供海量、极速、高性价比的存储方案;将公开数据集、训练数据、模型结果统一存储到对象存储COS中,实现数据统一存储和高效流转。GooseFS按需将热数据缓存到GPU内存和本地盘中,为大模型训练提供低延时的本地化访问能力,加速训练过程、提升训练效率。

CFS Turbo高性能并行文件存储,采取多级缓存加速的方案。基于全分布式架构,提供100GB/s带宽、1000万IOPS的极致性能。并通过持久化客户端缓存技术,将裸金属服务器本地NVMe SSD和Turbo文件系统构成统一命名空间,实现微秒级延时,解決大模型场景大数据量、高带宽、低延时的诉求。同时,通过智能分层技术,自动对冷热数据分层,节省80%的存储成本,提供极致的性价比。
在底层架构之上,针对大模型训练场景,新一代集群集成了腾讯云自研的TACO Train训练加速引擎,对网络协议、通信策略、AI框架、模型编译进行大量系统级优化,大幅节约训练调优和算力成本。
腾讯太极机器学习平台自研的训练框架AngelPTM,也已通过腾讯云对外提供服务,帮助企业加速大模型落地。在腾讯云上,企业基于大模型能力和工具箱,可结合产业场景数据进行精调训练,提升生产效率,快速创建和部署 AI 应用。
多层接入,算力更易获取
由于大模型的体量单集群的节点数非常大,初创公司通常会面临问题:单集群节点需要开多大,才能够适应AI算力的规模?
面对这一需求,在算力层面,腾讯云针对训练、推理、测试及优化场景,提供匹配方案和产品。
其中,新一代HCC高性能计算集群,面向大规模AI训练。以专用集群方式对外提供服务,腾讯云将裸金属云服务器作为节点,满配最新代次的GPU,并结合自研存储架构、节点之间通过自研星脉RDMA网络互联,给大模型训练业务提供高性能、高带宽和低延迟的一体化高性能计算。
后续,针对自动驾驶训练、自然语言处理、AIGC大模型训练、科研计算等场景下客户的高算需求,通过腾讯云裸金属、云服务器、容器、云函数等多形态多层级接入能力,都可以快速获取。
更大规模的大模型,正在逼近算力的边界。以新一代集群为标志,腾讯云正在基于自研芯片、星星海自研服务器和分布式云操作系统遨驰,通过软硬一体的方式,打造面向AIGC的高性能智算网络,持续加速全社会云上创新。
点击“新一代高性能计算集群HCC”申请内测
——完——
记得关注我们,及时接收精彩内容哦~
公众号/视频号:腾讯太极机器学习平台
腾讯太极机器学习平台,致力于让用户更加聚焦业务AI问题解决和应用,一站式解决算法工程师在应用过程中特征处理、模型训练、模型服务等工程问题。