相信大家在开发一些程序会有识别图片上文字(即所谓的OCR)的需求,比如识别车牌、识别图片格式的商品价格、识别图片格式的邮箱地址等等,当然需求最多的还是识别验证码。如果要完成这些OCR的工作,需要你掌握图像处理、图像识别的知识,需要用到图形形态学、傅里叶变换、矩阵变换、贝叶斯决策等很多复杂的理论,这让绝大部分人都会望而却步。
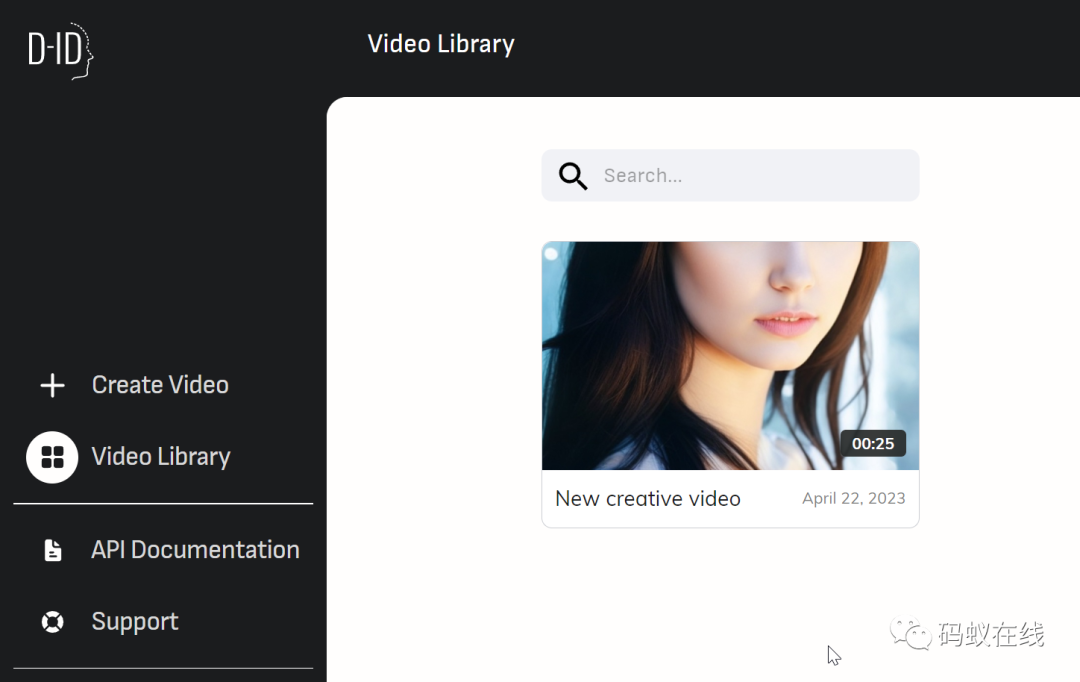
Tesseract这个开源项目的出现让我们普通人也可以涉足OCR的开发。Tesseract可以从图片中识别出文字内容,但不要以为Tesseract可以智能的识别出各种奇形怪状、复杂的图片文字,Tesseract默认只能识别非常标准字体、清晰无干扰的图片文字,刚接触Tesseract的人很多都会发出这样的评价“Tesseract吹的挺厉害,但是识别率很低呀,不好用”。其实我们要识别的内容千奇百怪,Tesseract是需要去训练才能比较高准确率的识别的,我们需要把一批样本图片让Tesseract去尝试识别,然后对他识别出的错误结果进行校正,告诉他“这个图片你识别错了,应该识别为某某某”,这样Tesseract慢慢的就“学会了”怎么样进行识别。也就是如下一个训练过程:
看到上图有一个“预处理”,这是什么意思呢?我们知道,很多验证码都是加了一些干扰处理的,比如说有的验证码加了噪音点、有的验证码加了干扰线、有的验证码加了干扰背景、有的验证码做了文字扭曲。如下图:

这些图片如果直接交给Tesseract去处理,识别的难度会非常大。开发人员应该在把图片交给Tesseract之前对图片进行比较的预处理操作,比如去掉干扰线、去掉背景噪点、字符矫正等等,有些复杂的预处理操作可能会涉及到图形形态学中比较深入的理论,这不是一篇文章能够介绍的,下面只列出比较简单的图片预处理的基本知识,深入学习请参考图形学相关资料。
1、.Net中图片对象类是Image类,使用Image.FromFile(file)来加载一张图片,一般的图片都是位图,Bitmap类是Image类的子类,所以我们一般把Image. FromFile()返回值转换为Bitmap类型使用Bitmap bitmap = (Bitmap)Image.FromFile(file)
2、Bitmap. Save()用来把内存中的图片对象保存到输出中去。第二个参数为图片格式。
3、由于Bitmap关联到GDI的非托管资源,实现了IDisposable接口,所以需要使用using进行对象的资源管理,以避免程序内存泄露的问题。关于using、IDisposable这些C#/.Net基础知识这里不再介绍,不清楚的请参考传智播客.Net培训学院公布的免费.Net视频教程,下载地址如下:http://net.itcast.cn/
4、如果要进行高效的图片操作,需要配合指针对Bitmap进行操作,当然为了避免对C#指针操作不熟悉的读者,这篇文章中我将会使用效率略低但是比较易懂的GetPixel、 SetPixel方法来进行图片操作。GetPixel、 SetPixel是Bitmap提供的两个方法,分别可以用来对图片进行指定坐标像素点颜色的读取和设置指定坐标像素点的颜色。
接下来开始讲解Tesseract的使用:
一、 首先我们要采集多张有代表性的验证码样本图片,因为比较复杂的验证码的训练过程会比较长,而这次传智播客.Net学院举办的验证码识别免费公开课时间有限,因此我挑选了相对比较简单的验证码进行识别。复杂验证码的识别过程也是大同小异的。我测试用的100张验证码图片在文章最后的“公开课软件、图片库和代码.zip”压缩包中。

string[] files = Directory.GetFiles(@"D:\KuaiPan\传智资料\班级资料\公开课\2013年4月份验证码识别\haijia","*.gif");for (int i = 0; i < files.Length; i++){string file = files[i];using(Bitmap bitmap = (Bitmap)Image.FromFile(file))using (Bitmap newBitmap = Process(bitmap)){newBitmap.Save(@"F:\aa\"+i+".tif",ImageFormat.Tiff);}}private static Bitmap Process(Bitmap bitmap){Bitmap newBitmap = new Bitmap(bitmap.Width, bitmap.Height);for (int x = 0; x < bitmap.Width; x++){for (int y = 0; y < bitmap.Height; y++){//去掉边框if (x == 0 || y == 0 || x == bitmap.Width - 1 || y == bitmap.Height - 1){newBitmap.SetPixel(x, y, Color.White);}else{Color color = bitmap.GetPixel(x, y);//如果点的颜色是背景干扰色,则变为白色if (color.Equals(Color.FromArgb(204, 204, 51)) ||color.Equals(Color.FromArgb(153, 204, 51)) ||color.Equals(Color.FromArgb(204, 255, 102)) ||color.Equals(Color.FromArgb(204, 204, 204)) ||color.Equals(Color.FromArgb(204, 255, 51))){newBitmap.SetPixel(x, y, Color.White);}else{newBitmap.SetPixel(x, y, color);}}}}return newBitmap;}F:\aa\文件夹下就会有100张图片转换后的图片,转换后效果如下:
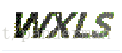
可以看到背景颜色和干扰线全部被去掉了。
三、 接下来运行jTessBoxEditor(jTessBoxEditor是使用java编写的,因此先需要安装配置java运行环境,对java运行环境安装配置不熟悉的朋友请自行寻找资料),双击jTessBoxEditor.jar即可启动运行。将第二步处理后的tiff使用主菜单 “Tool→Merge Tiff”图片合并为一张图片,比如保存到F:\aa\下haijia.tif文件中。
四、 下载安装tesseract-ocr-setup-3.01-1.exe(我使用3.02有问题,不知道是我的问题还是我不会用,总之还是推荐大家这里先使用3.01版本),这个setup版本会自动把安装目录添加到Path环境变量中,推荐使用。如果下载portable版本则需要自己编辑环境把tesseract解压路径添加到Path环境变量中。
五、 在下一步操作之前需要先给训练结果取一个名字,比如我这里就取haijia这个名字。如果你取了别的名字,只要把后面所有操作中的“haijia”改成你取的名字即可。
六、 启动windows命令行窗口,并且进入haijia.tif文件所在的目录,然后执行tesseract.exe haijia.tif haijia batch.nochop makebox。其中haijia.tif就是第三步生成的合并tiff文件的文件名,haijia则是咱们取的训练名。这样就会生成初始识别结果的haijia.box文件
七、 保证haijia.box文件和haijia.tif文件文件名完全一样并且放在同一个文件夹下。使用jTessBoxEditor打开haijia.tif文件,逐个校正文字,后保存。注意在jTessBoxEditor中每次修改完了字符都要回车,注意及时保存。如果发现多识别了、两个字母被识别为一个字母、一个字母被识别为两个字母等错误,需要使用Merge、split、delete之类的功能进行微调,还要通过修改X、Y、W、H修改自动识别的区域 。
八、 所有的自动识别结果矫正完毕后命令行执行tesseract.exe haijia.tif haijia nobatch box.train
九、 命令行执行unicharset_extractor.exe haijia.box
十、 在目录下新建一个名字为“font_properties”的文件,并且输入文本(其中haijia就是训练的名字,保存的时候使用EditPlus等高级文本编辑器去掉BOM头或者保存为ANSI格式): haijia 1 0 0 1 0
十一、 命令行执行cntraining.exe haijia.tr
十二、 命令行执行 mftraining.exe -F font_properties -U unicharset haijia.tr
十三、 第12步完成后,目录下应该生成若干个文件了,把unicharset, inttemp, normproto, pfftable这四个文件加上训练名字前缀“haijia.”。
十四、 命令行执行“combine_tessdata haijia.” 来合并生成的haijia.traineddata训练文件。执行完这步后,文件夹下就应该生成一个haijia.traineddata文件了,这个文件就是识别用的训练数据文件,只需要这一个haijia.traineddata文件即可,之前用的tif图片文件以及其他的中间文件都不需要了。
十五、 接下来调用Tesseract的API就可以在程序中进行验证码识别了。Tesseract支持很多语言,C/C++、Java、.Net、PHP、Python都有相应的API封装,只要寻找你使用语言的API库即可。下面还是以.Net为例。
a) 使用tesseractdotnet_v301_r590.zip中的tesseract.dll添加到相应的引用。注意tesseractdotnet默认只支持.Net 2.0,所以需要把项目的Target修改为.Net 2.0,如果你需要在2.0以上的版本中使用,则需要自己下载tesseractdotnet的源代码进行编译。
b) 采用第二步同样的方法对待识别的图片进行预处理,然后执行下面的代码对预处理过后的图片对象进行识别:
using (Bitmap bitmap = (Bitmap)Image.FromFile(file))using (Bitmap newBitmap = Process(bitmap))//图片预处理{TesseractProcessor processor = new TesseractProcessor();processor.SetPageSegMode(ePageSegMode.PSM_SINGLE_LINE);//F:\aa\是haijia.traineddata文件所在的文件夹。注意路径必须以\结尾,并且路径要用\分割,而不是/分割,否则会报错AccessViolation异常processor.Init(@"F:\aa \","haijia", (int)eOcrEngineMode.OEM_DEFAULT);string result = processor.Recognize(newBitmap);//返回值就是识别结果MessageBox.Show(result);}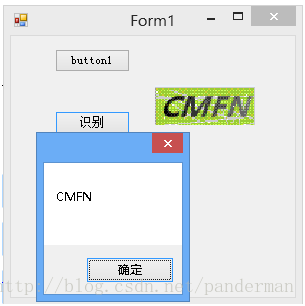
酷!帅!
文字的表现能力毕竟有限,因此我把这次传智播客公开课我讲的课堂录像免费发布出来,大家对照视频教程来进行学习的话会更方便,视频教程中也讲了一些我这篇文章中没有讲的东西,视频教程下载地址:http://dl.vmall.com/c0kvta13ex