文章目录
- 基本使用
- 管理员界面登录
- 管理用户
- 添加/删除用户及用户权限管理
- 组管理
- 任务管理
- 创建任务和上传标签
- datumaro
- anaconda安装
- datumaro安装
- datumaro基本使用
- 支持的格式
- 查看帮助文件报错
- 导入projects
- 数据增加
- 数据标注
- 标注面板使用
- 快捷键
- 左侧工具栏和右侧面板说明
- 追踪模式Track mode (视频标注使用)
- 提升标注效率
- 方式一:视频追踪,自动插帧
- 方式二:使用模型自动标记
- 参考链接:
基本使用
以下测试均建立在 github上 CVAT Release 1.0.0版本上
管理员界面登录
在上篇配置好CVAT后,可以使用类似:http://localhost:8080/admin来登录 (localhost换成自己的服务器ip)
管理用户
添加/删除用户及用户权限管理
主要是 AUTHENTICATION AND AUTHORIZATION 认证和授权 下面可以添加组和用户

大概就是常规的用户名,密码,确认密码之后就可以 成功注册了新用户了,下面其实还有继续一些权限控制的选项。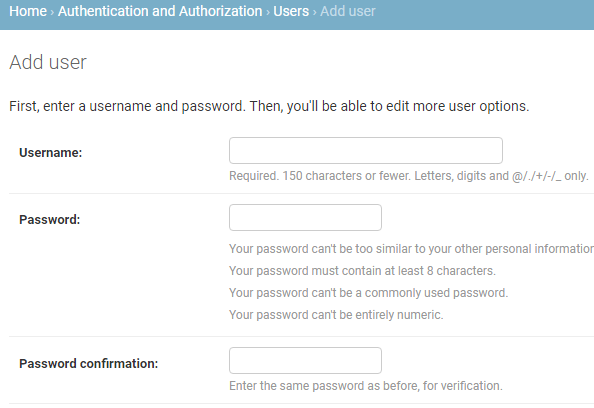
这里的三种Permissions分别表示:
- Activate(活跃用户):指定是否应将此用户视为活动用户,如果想使这个账号暂时失去权限,取消选择就可以,不需要删除。
- Staff status(员工身份):指定用户是否可以登录此管理站点。
+Superuser status( 超级用户状态):指定该用户具有所有权限,而无需显式分配它们。
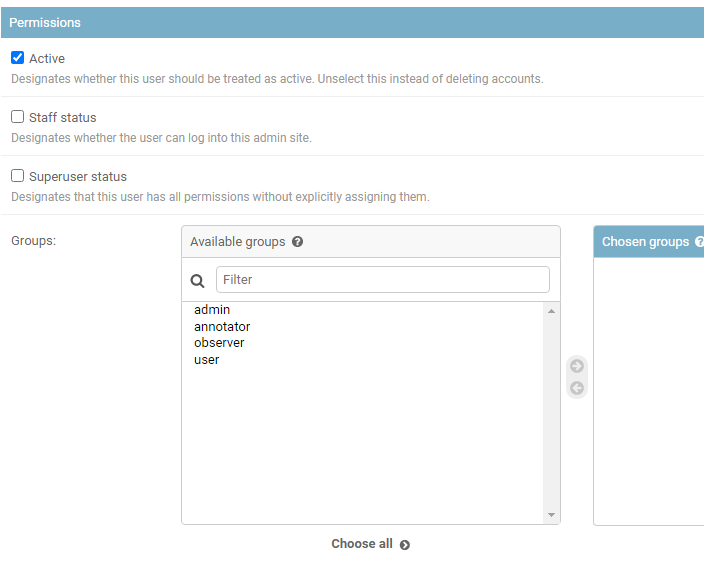
组管理
上面那四个原本就有的组,经过2020.7.27测试 (github上 CVAT
Release 1.0.0版本),组是没有权限区别的。
- 即:你不在annotator,也可以对task进行标注
- 但是在admin 就是有区别的,这里大概没设计好
- 在新建组部分,也只有 group name这一个字段,大概CVAT设计人员觉得对用户有权限控制就可以,剩下的就是管理员自行组织相同权限的用户在一个组,所以组没有权限管理
用户管理界面
任务管理

Engine->Tasks->选择具体的task名称进入,就可以看到该task的相关属性。
- 其中有一点需要注意:正常情况下,task创建后,除了标签和分配给谁可以改,其他都没法改,也没法再在Web端直接修改。
- Segment size:一个task无法分配给多个人(assignee),但是可以通过这个参数把一个task分成多个job,每个job再分给不同的人,就可以达到多人共同标注一个task的效果。 PS:虽然这里提供了这个选项,但是实际不生效,
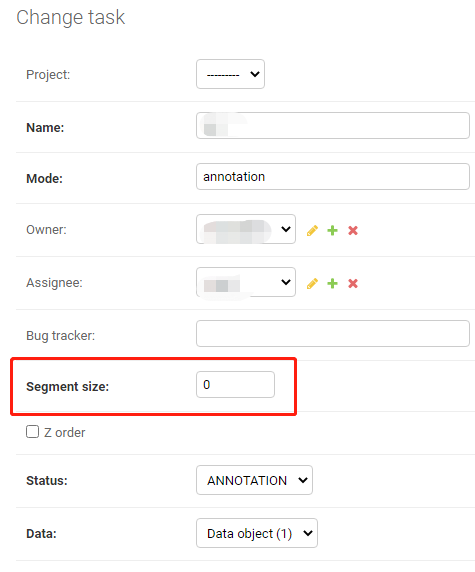
即便改了Segment size ,但是可以看到后面的Segments各种都没有反应。无效,所以如果想要把一个任务分配给多个人,只能在一开始创建任务的时候就全都考虑不好,要么就重新创建。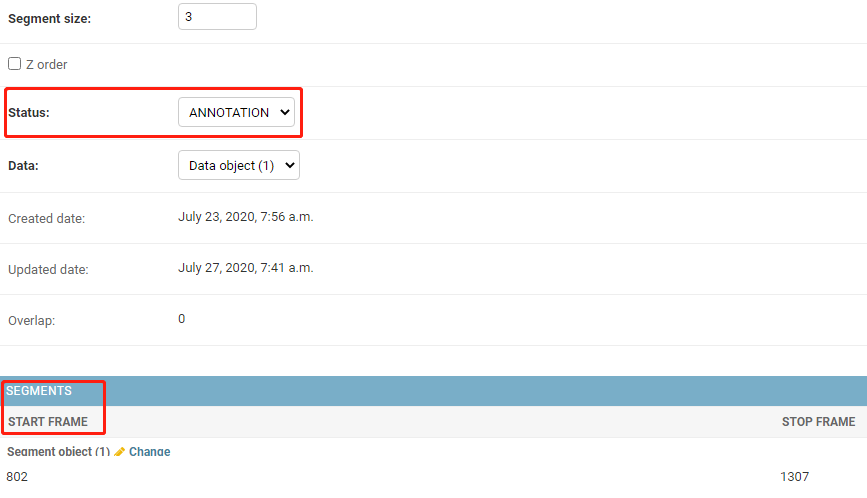
- Segment size:一个task无法分配给多个人(assignee),但是可以通过这个参数把一个task分成多个job,每个job再分给不同的人,就可以达到多人共同标注一个task的效果。 PS:虽然这里提供了这个选项,但是实际不生效,
创建任务和上传标签
进入CVAT界面后,选择新建任务(很简单,填填就好了)
- 创建任务完成后,如果还需要上传对应的标记文件,则该文件需要是zip格式的。同时,还会提示你:

即:这里上传的标记会将你在CVAT平台上标记的全都覆盖!
此外,如果上传的标记文件中标签与该task建立时的标签不一致,会报错。且已经创建好的项目的标签无法修改,可以新加,但无法修改之前已经定义的。
上传完毕后显示

然后回到任务面板,打开就可以看到已经标注好的结果了,不错
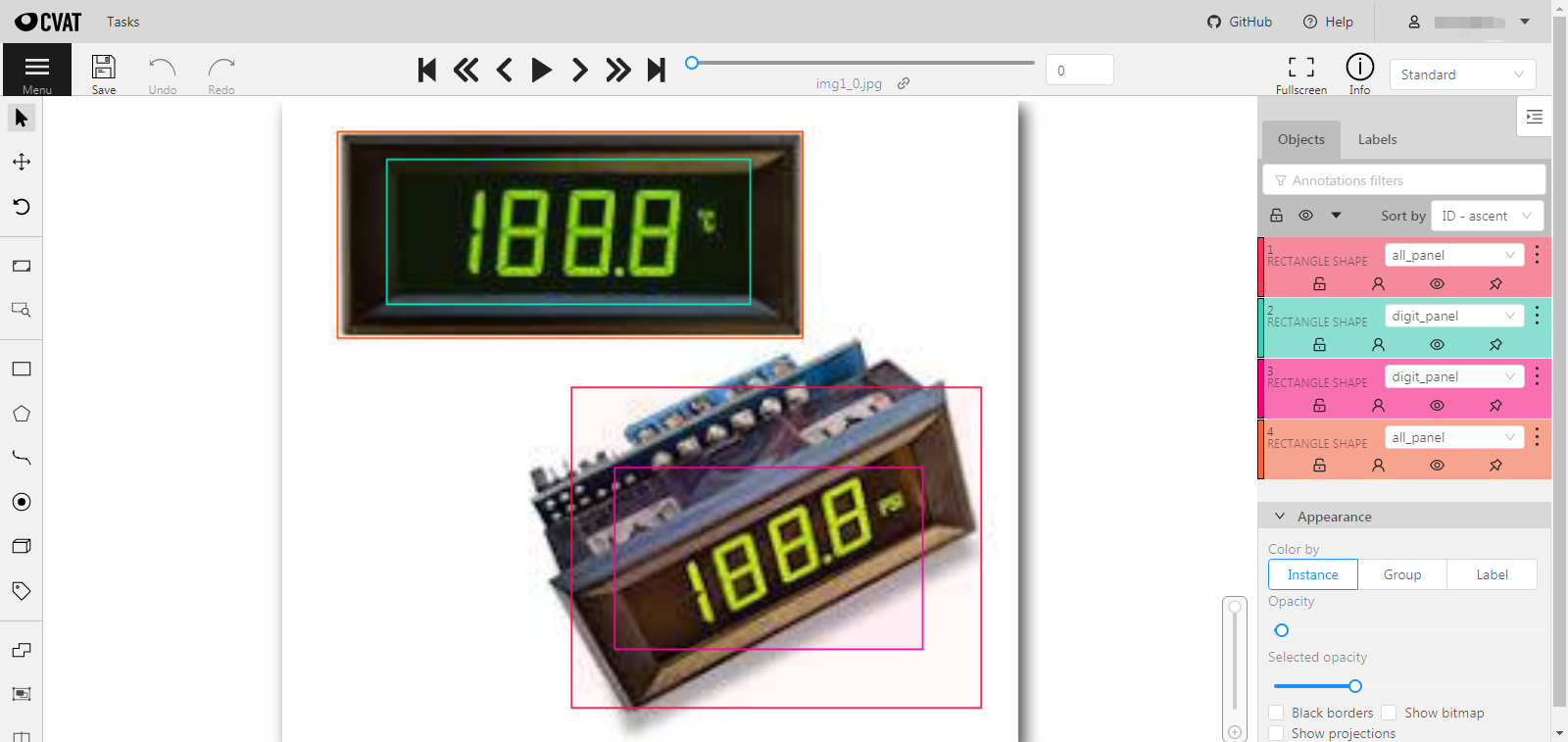
datumaro
这个是基于python的,可以在user-guide中看到 这个datumaro要求是python3.5+的环境。
为此,先查看服务器上python环境的情况
which python
//返回 /usr/bin/python
python --version
2.7.17
anaconda安装
环境不太好,所以要安装python3.5的环境,选择anaconda,直接去官网下载linux版本,右键存储链接
wget https://repo.anaconda.com/archive/Anaconda3-2020.07-Linux-x86_64.sh
(这个版本是python3.8的 所以安装结束后还要再新建一个python3.5的环境)
下载完之后再进行安装:
bash Anaconda3-2020.07-Linux-x86_64.sh
一开始会让你阅读协议,输入yes,然后会让你确定安装位置,记住这个前缀,等一会就安装好了。安装结束后,提示:
For changes to take effect, close and re-open your current shell 所以最好把这个shell连接关闭重启一下(不然无法识别conda命令),重启之后就Ok了,剩下就是anaconda里操作,新建环境安装py36,安装一些必要的包了。
- !!!!
- 不要安装py3.5 虽然datumaro写得是 python3.5+ 但是在执行pip git XXX后,当安装 pycocotools时,报错 RuntimeError: Python version >= 3.6 required。所以安装3.6最好
PREFIX=/home/XXX/anaconda3
conda create -n py36 python=3.6
conda activate py36
pip list
pip install --upgrade pip
环境配好就可以去安装datumaro了
datumaro安装
需要先安装好gcc
> sudo apt update
> sudo apt install build-essential
# 这句会安装 gcc, g++ and make
> sudo apt-get install manpages-dev
# 这个是一些手册
安装:
pip install 'git+https://github.com/opencv/cvat#egg=datumaro&subdirectory=datumaro'
安装这个的过程中会默认安装一些别的依赖包(反正等着就好了,要等挺久,可以在requirements文件中看到)。
Cython>=0.27.3 # include before pycocotools
defusedxml>=0.6.0
GitPython>=3.0.8
lxml>=4.4.1
matplotlib<3.1 # 3.1+ requires python3.6, but we have 3.5 in cvat
opencv-python-headless>=4.1.0.25
Pillow>=6.1.0
pycocotools>=2.0.0 # 这个要求python>=3.6
# 这个还要求安装有gcc 安装gcc后再进行安装就没问题了
PyYAML>=5.1.1
scikit-image>=0.15.0
tensorboardX>=1.8
datumaro基本使用
安好后,就可以开始跟着用户手册继续使用一些基本功能了。重点放在数据增加与合并上。
说明:命令调用语法可能会改变,始终遵循 --help的说明。
datumaro的关键对象是Project,一个Project是一个project自己包含的数据集,大量外部数据资源以及一个环境的组合。可以通过project create命令来创建一个空的Project,现有的数据集可以使用project import命令导入。最简单的获取任务的方式就是在CVAT的UI中导出task
所以基本可以认为,datumaro的使用需要不断跟CVAT进行导出和导入操作。
支持的格式
-f参数的取值可以有:
- COCO
- PASCAL VOC
- YOLO
- TF Detection API
- CVAT
可以在CVAT的tasks面板中看到导出的文件格式有(从名字上来看,最好使用Datumaro):

查看帮助文件报错
ImportError: libSM.so.6: cannot open shared object file: No such file or directory
解决,参考github issue:
>sudo apt-get update
>sudo apt-get install -y libsm6 libxext6 libxrender-dev
//执行完这步 就可以正常查看help文件了 ok 下面那句不用管了
>pip install opencv-python
导入projects
从现有的数据集中创建一个project,支持的就是上面的格式。Datumaro数据格式是由Extractors和Importers支持的。提取器产生对应于数据集的数据项目列表,导入器从数据源的位置创建一个项目。支持自定义提取器和导入器,但是需要将二者的实现脚本放入<project_dir>/.datumaro/extractors and <project_dir>/.datumaro/importers文件夹中
导入代码,例如 从一个coco格式的数据集中创建项目:
//先
datum project import --help
// 以help的内容为准,执行时报错,
WARNING: Failed to import module 'tf_detection_api_format.extractor.py': Traceback (most recent call last):File "<string>", line 1, in <module> ModuleNotFoundError: No module named 'tensorflow'datum project import \-f coco\-i /home/coco_dir \-o /home/project_dir \
数据增加
数据标注
标注面板使用
快捷键
- 上一张D
- 下一张F
- 新建矩形标注框 N

左侧工具栏和右侧面板说明
其实就是这个 适应图片 功能比较好。
- 滑动鼠标滚轮:标注图片缩放(不是网页缩放)
- 双击图片:图片自适应当前窗口宽度
追踪模式Track mode (视频标注使用)
为了使用这一功能,上传了一个 104.5MB的flv文件上去。
- 创建时注意:
Advanced configuration中的frame step是控制提取帧的间隔:使用此选项过滤视频帧。 例如,输入25将在视频中每隔第二十五帧或每25幅图像保留一个。 - 视频和图片要进行压缩上传,所以很慢。。上传过程无法停止,等着吧
- 14分钟 7500帧 也就是差不多 每秒8帧-10帧左右
依然打开标注面板,这里标注的时候不使用默认的shape 而是选择track。
- 标记的物体于?帧开始移动,就可以将?帧 打上星号或者点击K将其标记为关键帧。
- 如果对象开始更改其位置,则需要修改其发生的矩形。 不必更改每个帧上的矩形,只需更新几个关键帧,它们之间的帧就会自动插入。
- 例如:第0帧上画框,然后到第30帧,把之前那个框的位置进行移动(会自动帮你把这帧标记为关键帧 打上星号)
- 两帧之间就会根据一个框(一个track)的两个位置 (两个位置框的大小可以不同)来自动进行 插帧标注 效果不错
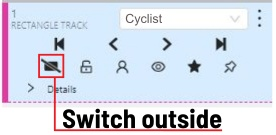
- 当标注物体变得很小或者消失的时候,需要选择
Outside Property.- 跳出之后,从那一帧开始 就不再追踪了。尤其是物体到视频边缘,物体大小持续发生变化,就需要自己慢慢标注了。
- 如果物体在某几帧消失了然后又出现,这时可以使用
Merge融合特性将不同的tracks融合成一个- 在物体可见的时候画一个矩形(使用track方式)
- 在消失但又出现的地方再画一个矩形(track)
- 点击
Merge或者按下M键,依次点击第一个track和第二个track等 - 然后点击完了,再按下
Merge或者M键 使改动生效
0帧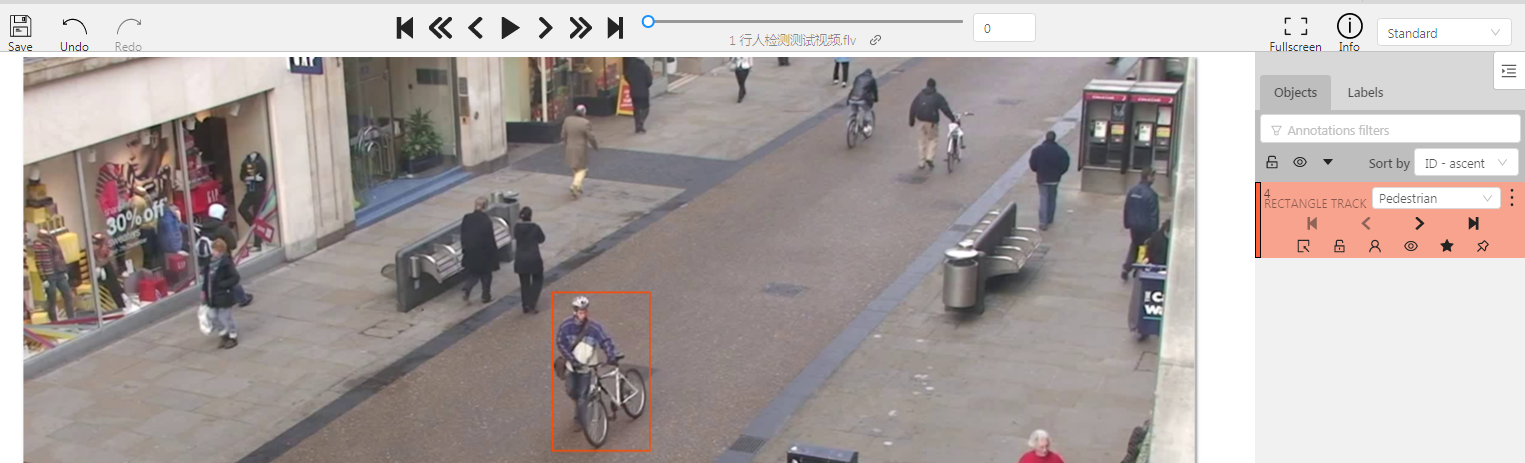
30帧
如果还想了解更多高级功能,查看 track mode (advanced)
提升标注效率
方式一:视频追踪,自动插帧
就是上面的 追踪模式 Track mode(适用于一个序列的图像,目标追踪类的任务)
方式二:使用模型自动标记
主要参考
- Auto annotation using DL models in OpenVINO toolkit format
- TF Object Detection API: auto annotation
- Analytics: management and monitoring of data annotation team
+Semi-automatic segmentation with Deep Extreme Cut - Auto segmentation: Keras+Tensorflow Mask R-CNN Segmentation
参考链接:
- wget命令
- Ubuntu18.04安装gcc