一个朋友很喜欢周杰伦。
所以,前两天我跟别人去KTV,就唱的是“七里香”。
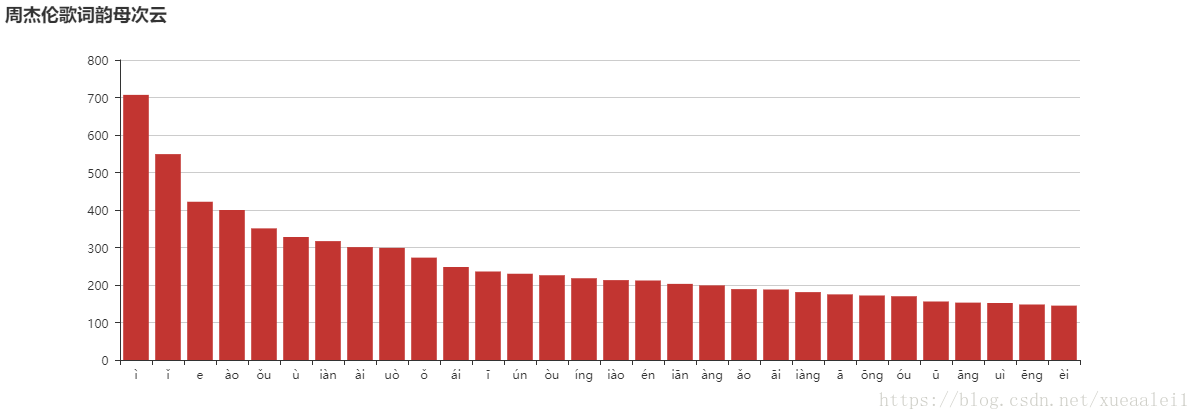
唱着唱歌,突然就好奇了起来。周杰伦的歌里,是不是还有很多的麻雀
后来发现,270首歌,140786个字,千言万语,说来说去,都是“我”,“的”,“你”

路人:咦,怎么没有你我他中的他
我:你我之间,没有他。
路人:不对啊,不是每首歌都是你呀我呀的吗这跟是不是周杰伦也没啥关系吧?
我:......我不听我不听。
还有去除所有单字的,只考虑词的。

等等,为毛......双节棍......三个字,出现的频率如此之高....

啥......阳光宅男里也有双截棍吗......宅男也用双截棍打人吗

本文完
--------------------------------源代码
url ='https://music.163.com/#/search/m/?id = 6452&limit = 100&offset = 100&s =%E5%91%A8%E6%9D%B0%E4%BC%A6&type = 1'
这个是网易云音乐里的关键词“周杰伦”的搜索结果。利用硒大法,可以强行弄出歌名歌手名歌曲编号。
http://music.163.com/api/song/media?id=186001 这个链接,不断替换后面的ID,可直接看到歌词JSON。
from selenium import webdriver
import re,time,requests,json
from bs4 import BeautifulSoup
import pandas as pd
driver = webdriver.Chrome()
url = 'https://music.163.com/#/search/m/?id=6452&limit=100&offset=100&s=%E5%91%A8%E6%9D%B0%E4%BC%A6&type=1'
driver.get(url)#自动爬取周杰伦歌曲的 歌曲代号/歌名/歌星
#反爬也不做了.什么时候停了,就是弄好了.
while True:driver.switch_to.default_content()driver.switch_to.frame("contentFrame") # 2.用id来定位pattern=re.compile('/artist\?id=[0-9]+"><span class="s-fc7">(.*?)<.*?title="《(.*?)》">')html = driver.page_source soup= BeautifulSoup(html,'html.parser')list_song=[]for row in soup.find("div",{"class":"srchsongst"}):list_song.append([re.search('data-res-id="([0-9]+)"',str(row)).group(1), #歌曲代号re.search('b title="(.*?)"',str(row)).group(1), #歌名re.search(pattern,str(row)).group(1)]) #歌星print('Done')Data=pd.DataFrame(list_song)Data.to_csv(r"C:\Users\Jack\Desktop\OutData.csv",encoding = "utf-8",mode="a+",index=0,header=0)#翻页button = driver.find_element_by_xpath('//*[@id="auto-id-Uf7JxlNgQEttTgGT"]')button.click()time.sleep(1)#清洗出一个没有重复歌名的名单. (一首歌会有各种版本)
data=pd.read_csv("C:\\Users\\Jack\\Desktop\\outData.csv")
songData=data.values.tolist()newlist=[]
for i in songData :if re.sub(u"\\(.*?\\)|\\{.*?}|\\[.*?]|\s?\-", "",i[1]) not in [ i[1] for i in newlist]:
#正则是为了洗出没有符号,尽可能简洁的歌曲名. 并且not in newlist 是为了保证不会重复newlist.append([i[0],re.sub(u"\\(.*?\\)|\\{.*?}|\\[.*?]|\s?\-", "",i[1]),i[2]])def load(songid): #获取歌词信息url= 'http://music.163.com/api/song/media?id=' +str(row[0])r = requests.get(url,headers=headers)return json.loads(r.text)['lyric']list_new = []
for row in newlist:try:lyric = load(row[0])list_new.append([row[0],row[1],row[2],lyric])except:print('---')print(row[0])time.sleep(1)print('|',end='')time.sleep(0.2)
print('爬取歌词完成')#stopwords是为了防止进来奇怪的东西. 因为有些歌词里面是会夹杂歌手名的...
#这样可去除异常的高词频的词,防止wordcloud异常.(人为控制啊你)
#用空格作间隔符,加快输入速度. 之前我可是输了两三行...
stopWords='周杰伦 录音师 录音室'
import jieba
list=[]
for i in jieba.cut_for_search(''.join([i[3] for i in list_new])):
#用jieba.cut_for_search,俗称 搜索引擎模式. 是为了尽可能保证一句话多拆成 词,而不是 字.word= (re.sub('[0-9.:\/\(\)\[\]\s:]+|\\r|\\n|[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b]','',i))if word != '' and word not in stopWords.split(' ') :list.append(word)from pandas import DataFrame
df = DataFrame({"word":[i for i in list ],"count":1})df2 = df.groupby('word').count().sort_values(by = 'count',axis = 0,ascending = False)
df2.insert(0,"index",[i for i in df2.index])df2.columns=['word','count']wordlist=df2.values.tolist()from pyecharts import WordCloud
wordcloud = WordCloud('周杰伦歌词次云','Made By Jack',width=800, height=620)
wordcloud.add("",[i[0] for i in wordlist], [i[1] for i in wordlist], word_size_range=[10, 70],shape='pentagon')
wordcloud这样子就能弄出歌词WordCloud啦〜
后来寻思着,唱歌是不是要讲究押韵来着?但是不知道啥叫必然的规律..
所以尝试了一下
yunmulist=[]
from pypinyin import lazy_pinyin
for row in [i[3].split('\n') for i in list_new]:for row2 in row:row3=re.sub('[\[\],.:\(\)\s)]|[0-9]','',row2)try:lastword = (row3[-1])word_pinyin =pinyin(lastword)if word_pinyin!=[]:yunmulist.append(lazy_pinyin(lastword,style=Style.FINALS_TONE, strict=False,errors='ignore'))except:passdf = DataFrame({"word":[i[0] for i in yunmulist if i !=[]],"count":1})
df.groupby('word').count().sort_values(by = 'count',axis = 0,ascending = False)
df2 = df.groupby('word').count().sort_values(by = 'count',axis = 0,ascending = False)
df2.insert(0,"index",[i for i in df2.index])df2.columns=['word','count']wordlist=df2.values.tolist()from pyecharts import Bar
wordcloud = Bar('周杰伦歌词韵母次云',width=1200, height=420)
wordcloud.add("",[i[0] for i in wordlist][0:30], [i[1] for i in wordlist][0:30], word_size_range=[20, 60],shape='pentagon')
wordcloud只截取了前20的。前后差异太大了。