使用 OpenCV 和 Python 识别信用卡号
在之前的博文中,我们学习了如何安装 Tesseract 二进制文件并将其用于 OCR。 然后我们学习了如何使用基本的图像处理技术来清理图像以提高 Tesseract OCR 的输出。
但是,不应将 Tesseract 视为能够获得高精度的光学字符识别的通用、现成的解决方案。 在某些情况下,它会工作得很好——而在其他情况下,它会失败得很惨。 这种用例的一个很好的例子是信用卡识别,给定输入图像, 我们希望:
本地化四组四位数字,与信用卡上的十六位数字有关。 应用 OCR 识别信用卡上的十六位数字。 识别信用卡类型(即 Visa、MasterCard、American Express 等)。
在这些情况下,Tesseract 库无法正确识别数字(这可能是因为 Tesseract 没有接受信用卡示例字体的培训)。 因此,我们需要为 OCR 信用卡设计我们自己的定制解决方案。 在今天的博客文章中,我将演示如何使用模板匹配作为 OCR 的一种形式来帮助我们创建一个解决方案来自动识别信用卡并从图像中提取相关的信用卡数字。
今天的博文分为三个部分。 在第一部分中,我们将讨论 OCR-A 字体,这是一种专为辅助光学字符识别算法而创建的字体。 然后我们将设计一种计算机视觉和图像处理算法,它可以:
- 本地化信用卡上的四组四位数字。
- 提取这四个分组中的每一个,然后单独分割 16 个数字中的每一个。
- 使用模板匹配和 OCR-A 字体识别 16 个信用卡数字中的每一个。
最后,我们将看一些将信用卡 OCR 算法应用于实际图像的示例。
通过与 OpenCV 模板匹配的 OCR
在本节中,我们将使用 Python + OpenCV 实现我们的模板匹配算法来自动识别信用卡数字。
为了实现这一点,我们需要应用许多图像处理操作,包括阈值、计算梯度幅度表示、形态学操作和轮廓提取。这些技术已在其他博客文章中用于检测图像中的条形码并识别护照图像中的机器可读区域。
由于将应用许多图像处理操作来帮助我们检测和提取信用卡数字,因此我在输入图像通过我们的图像处理管道时包含了许多中间屏幕截图。
这些额外的屏幕截图将让您更深入地了解我们如何能够将基本图像处理技术链接在一起以构建计算机视觉项目的解决方案。 让我们开始吧。
打开一个新文件,命名为 ocr_template_match.py ,我们将开始工作:
# import the necessary packages
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
要安装/升级 imutils ,只需使用 pip :
pip install --upgrade imutils
注意:如果您使用 Python 虚拟环境(就像我所有的 OpenCV 安装教程一样),请确保首先使用 workon 命令访问您的虚拟环境,然后安装/升级 imutils 。
现在我们已经安装并导入了包,我们可以解析我们的命令行参数:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,help="path to input image")
ap.add_argument("-r", "--reference", required=True,help="path to reference OCR-A image")
args = vars(ap.parse_args())
建立了一个参数解析器,添加两个参数,然后解析它们,将它们存储为变量 args 。 两个必需的命令行参数是:
–image :要进行 OCR 处理的图像的路径。
–reference :参考 OCR-A 图像的路径。 该图像包含 OCR-A 字体中的数字 0-9,从而允许我们稍后在管道中执行模板匹配。
接下来让我们定义信用卡类型:
# define a dictionary that maps the first digit of a credit card
# number to the credit card type
FIRST_NUMBER = {"3": "American Express","4": "Visa","5": "MasterCard","6": "Discover Card"
}
信用卡类型,例如美国运通、Visa 等,可以通过检查 16 位信用卡号中的第一位数字来识别。我们定义了一个字典 FIRST_NUMBER ,它将第一个数字映射到相应的信用卡类型。 让我们通过加载参考 OCR-A 图像来启动我们的图像处理管道:
# load the reference OCR-A image from disk, convert it to grayscale,
# and threshold it, such that the digits appear as *white* on a
# *black* background
# and invert it, such that the digits appear as *white* on a *black*
ref = cv2.imread(args["reference"])
ref = cv2.cvtColor(ref, cv2.COLOR_BGR2GRAY)
ref = cv2.threshold(ref, 10, 255, cv2.THRESH_BINARY_INV)[1]
首先,我们加载参考 OCR-A 图像,然后将其转换为灰度和阈值 + 反转。 在这些操作中的每一个中,我们存储或覆盖 ref ,我们的参考图像。

现在让我们在 OCR-A 字体图像上定位轮廓:
# find contours in the OCR-A image (i.e,. the outlines of the digits)
# sort them from left to right, and initialize a dictionary to map
# digit name to the ROI
refCnts = cv2.findContours(ref.copy(), cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
refCnts = imutils.grab_contours(refCnts)
refCnts = contours.sort_contours(refCnts, method="left-to-right")[0]
digits = {}
找到了参考图像中的轮廓。 然后,由于 OpenCV 2.4、3 和 4 版本如何不同地存储返回的轮廓信息,我们检查版本并对 refCnts 进行适当更改。 接下来,我们从左到右对轮廓进行排序,并初始化一个字典,digits,它将数字名称映射到感兴趣的区域。
此时,我们应该遍历轮廓,提取ROI并将其与其对应的数字相关联:
# loop over the OCR-A reference contours
for (i, c) in enumerate(refCnts):# compute the bounding box for the digit, extract it, and resize# it to a fixed size(x, y, w, h) = cv2.boundingRect(c)roi = ref[y:y + h, x:x + w]roi = cv2.resize(roi, (57, 88))# update the digits dictionary, mapping the digit name to the ROIdigits[i] = roi
遍历参考图像轮廓。
在循环中, i 保存数字名称/编号, c 保存轮廓。 我们围绕每个轮廓 c 计算一个边界框,用于存储矩形的 (x, y) 坐标和宽度/高度。使用边界矩形参数从 ref(参考图像)中提取 roi。 该 ROI 包含数字。
我们将每个 ROI 大小调整为 57×88 像素的固定大小。 我们需要确保每个数字都调整为固定大小,以便在本教程后面的数字识别中应用模板匹配。
我们将每个数字 0-9(字典键)与每个 roi 图像(字典值)相关联。
在这一点上,我们完成了从参考图像中提取数字并将它们与相应的数字名称相关联的工作。
我们的下一个目标是隔离输入 --image 中的 16 位信用卡号。 我们需要先找到并隔离数字,然后才能启动模板匹配以识别每个数字。 这些图像处理步骤非常有趣且有见地,特别是如果您之前从未开发过图像处理管道,请务必密切关注。
让我们继续初始化几个结构化内核:
# initialize a rectangular (wider than it is tall) and square
# structuring kernel
rectKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 3))
sqKernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
您可以将内核视为我们在图像上滑动的小矩阵,以执行(卷积)操作,例如模糊、锐化、边缘检测或其他图像处理操作。
构造了两个这样的内核——一个矩形和一个正方形。 我们将使用矩形作为 Top-hat 形态算子,使用方形作为闭运算。 我们很快就会看到这些。 现在让我们准备要进行 OCR 的图像:
# load the input image, resize it, and convert it to grayscale
image = cv2.imread(args["image"])
image = imutils.resize(image, width=300)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
加载了包含信用卡照片的命令行参数图像。 然后,我们将其调整为 width=300 ,保持纵横比,然后将其转换为灰度。 让我们看看我们的输入图像:

接下来是我们的调整大小和灰度操作:

现在我们的图像已经灰度化并且大小一致,让我们进行形态学操作:
# apply a tophat (whitehat) morphological operator to find light
# regions against a dark background (i.e., the credit card numbers)
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)
使用我们的 rectKernel 和我们的灰度图像,我们执行 Top-hat 形态学操作,将结果存储为 tophat。
Top-hat操作在深色背景(即信用卡号)下显示浅色区域,如下图所示:

给定我们的高帽图像,让我们计算沿 x 方向的梯度:
# compute the Scharr gradient of the tophat image, then scale
# the rest back into the range [0, 255]
gradX = cv2.Sobel(tophat, ddepth=cv2.CV_32F, dx=1, dy=0,ksize=-1)
gradX = np.absolute(gradX)
(minVal, maxVal) = (np.min(gradX), np.max(gradX))
gradX = (255 * ((gradX - minVal) / (maxVal - minVal)))
gradX = gradX.astype("uint8")
我们努力隔离数字的下一步是计算 x 方向上高帽图像的 Scharr 梯度。完成计算,将结果存储为 gradX 。
在计算 gradX 数组中每个元素的绝对值后,我们采取一些步骤将值缩放到 [0-255] 范围内(因为图像当前是浮点数据类型)。 为此,我们计算 gradX 的 minVal 和 maxVal,然后计算第 73 行所示的缩放方程(即最小/最大归一化)。 最后一步是将 gradX 转换为范围为 [0-255] 的 uint8。 结果如下图所示:

让我们继续改进信用卡数字查找算法:
# apply a closing operation using the rectangular kernel to help
# cloes gaps in between credit card number digits, then apply
# Otsu's thresholding method to binarize the image
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)
thresh = cv2.threshold(gradX, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# apply a second closing operation to the binary image, again
# to help close gaps between credit card number regions
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel)
为了缩小差距,我们执行了一个关闭操作。请注意,我们再次使用了 rectKernel。 随后我们对 gradX 图像执行 Otsu 和二进制阈值,然后是另一个关闭操作。 这些步骤的结果如下所示:

接下来让我们找到轮廓并初始化数字分组位置列表。
# find contours in the thresholded image, then initialize the
# list of digit locations
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
locs = []
我们找到了轮廓并将它们存储在一个列表 cnts 中 。 然后,我们初始化一个列表来保存数字组位置。
现在让我们遍历轮廓,同时根据每个轮廓的纵横比进行过滤,允许我们从信用卡的其他不相关区域中修剪数字组位置:
# loop over the contours
for (i, c) in enumerate(cnts):# compute the bounding box of the contour, then use the# bounding box coordinates to derive the aspect ratio(x, y, w, h) = cv2.boundingRect(c)ar = w / float(h)# since credit cards used a fixed size fonts with 4 groups# of 4 digits, we can prune potential contours based on the# aspect ratioif ar > 2.5 and ar < 4.0:# contours can further be pruned on minimum/maximum width# and heightif (w > 40 and w < 55) and (h > 10 and h < 20):# append the bounding box region of the digits group# to our locations listlocs.append((x, y, w, h))
我们以与参考图像相同的方式循环遍历轮廓。 在计算每个轮廓的边界矩形 c之后,我们通过将宽度除以高度来计算纵横比 ar 。 使用纵横比,我们分析每个轮廓的形状。 如果 ar 介于 2.5 和 4.0 之间(宽大于高),以及 40 到 55 像素之间的 w 和 10 到 20 像素之间的 h,我们将一个方便的元组中的边界矩形参数附加到 locs。
下图显示了我们找到的分组——出于演示目的,我让 OpenCV 在每个组周围绘制了一个边界框:

接下来,我们将从左到右对分组进行排序并初始化信用卡数字列表:
# sort the digit locations from left-to-right, then initialize the
# list of classified digits
locs = sorted(locs, key=lambda x:x[0])
output = []
我们根据 x 值对 locs 进行排序,因此它们将从左到右排序。 我们初始化一个列表 output ,它将保存图像的信用卡号。 现在我们知道每组四位数字的位置,让我们循环遍历四个排序的组并确定其中的数字。
这个循环相当长,分为三个代码块——这是第一个块:
# loop over the 4 groupings of 4 digits
for (i, (gX, gY, gW, gH)) in enumerate(locs):# initialize the list of group digitsgroupOutput = []# extract the group ROI of 4 digits from the grayscale image,# then apply thresholding to segment the digits from the# background of the credit cardgroup = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5]group = cv2.threshold(group, 0, 255,cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]# detect the contours of each individual digit in the group,# then sort the digit contours from left to rightdigitCnts = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)digitCnts = imutils.grab_contours(digitCnts)digitCnts = contours.sort_contours(digitCnts,method="left-to-right")[0]
在此循环的第一个块中,我们提取并在每侧填充组 5 个像素,应用阈值处理,并查找和排序轮廓。 详情请务必参考代码。 下面显示的是已提取的单个组:

让我们用嵌套循环继续循环以进行模板匹配和相似度得分提取:
# loop over the digit contoursfor c in digitCnts:# compute the bounding box of the individual digit, extract# the digit, and resize it to have the same fixed size as# the reference OCR-A images(x, y, w, h) = cv2.boundingRect(c)roi = group[y:y + h, x:x + w]roi = cv2.resize(roi, (57, 88))# initialize a list of template matching scores scores = []# loop over the reference digit name and digit ROIfor (digit, digitROI) in digits.items():# apply correlation-based template matching, take the# score, and update the scores listresult = cv2.matchTemplate(roi, digitROI,cv2.TM_CCOEFF)(_, score, _, _) = cv2.minMaxLoc(result)scores.append(score)# the classification for the digit ROI will be the reference# digit name with the *largest* template matching scoregroupOutput.append(str(np.argmax(scores)))
使用 cv2.boundingRect 我们获得提取包含每个数字的 ROI 所需的参数。为了使模板匹配以某种程度的精度工作,我们将 roi 的大小调整为与我们在第 144 行上的参考 OCR-A 字体数字图像(57×88 像素)相同的大小。
我们初始化了一个分数列表。将其视为我们的置信度分数——它越高,它就越有可能是正确的模板。
现在,让我们通过每个参考数字循环(第三个嵌套循环)并执行模板匹配。这是为这个脚本完成繁重工作的地方。
OpenCV 有一个名为 cv2.matchTemplate 的方便函数,您可以在其中提供两个图像:一个是模板,另一个是输入图像。将 cv2.matchTemplate 应用于这两个图像的目的是确定它们的相似程度。
在这种情况下,我们提供参考 digitROI 图像和包含候选数字的信用卡的 roi。使用这两个图像,我们调用模板匹配函数并存储结果。 接下来,我们从结果中提取分数并将其附加到我们的分数列表中。这样就完成了最内部的循环。
使用分数(每个数字 0-9 一个),我们取最大分数——最大分数应该是我们正确识别的数字。我们找到得分最高的数字,通过 np.argmax 获取特定索引。该索引的整数名称表示基于与每个模板的比较最可能的数字(再次记住,索引已经预先排序为 0-9)。
最后,让我们在每组周围画一个矩形,并以红色文本查看图像上的信用卡号:
# draw the digit classifications around the groupcv2.rectangle(image, (gX - 5, gY - 5),(gX + gW + 5, gY + gH + 5), (0, 0, 255), 2)cv2.putText(image, "".join(groupOutput), (gX, gY - 15),cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2)# update the output digits listoutput.extend(groupOutput)
对于此循环的第三个也是最后一个块,我们在组周围绘制一个 5 像素的填充矩形,然后在屏幕上绘制文本。
最后一步是将数字附加到输出列表中。 Pythonic 方法是使用扩展函数将可迭代对象(在本例中为列表)的每个元素附加到列表的末尾。
要查看脚本的执行情况,让我们将结果输出到终端并在屏幕上显示我们的图像。
# display the output credit card information to the screen
print("Credit Card Type: {}".format(FIRST_NUMBER[output[0]]))
print("Credit Card #: {}".format("".join(output)))
cv2.imshow("Image", image)
cv2.waitKey(0)
将信用卡类型打印到控制台,然后在随后的第 173 行打印信用卡号。
在最后几行,我们在屏幕上显示图像并等待任何键被按下,然后退出脚本第 174 和 175 行。
花点时间祝贺自己——你做到了。 回顾一下(在高层次上),这个脚本:
- 将信用卡类型存储在字典中。
- 获取参考图像并提取数字。
- 将数字模板存储在字典中。
- 本地化四个信用卡号码组,每个组包含四位数字(总共 16 位数字)。
- 提取要“匹配”的数字。
- 对每个数字执行模板匹配,将每个单独的 ROI 与每个数字模板 0-9 进行比较,同时存储每个尝试匹配的分数。
- 找到每个候选数字的最高分,并构建一个名为 output 的列表,其中包含信用卡号。
- 将信用卡号和信用卡类型输出到我们的终端,并将输出图像显示到我们的屏幕上。
现在是时候查看运行中的脚本并检查我们的结果了。
信用卡 OCR 结果
现在我们已经对信用卡 OCR 系统进行了编码,让我们试一试。
我们显然不能在这个例子中使用真实的信用卡号,所以我使用谷歌收集了一些信用卡示例图像。
这些信用卡显然是假的,仅用于演示目的。 但是,您可以应用此博客文章中的相同技术来识别实际信用卡上的数字。
要查看我们的信用卡 OCR 系统的运行情况,请打开一个终端并执行以下命令:
$ python ocr_template_match.py --reference ocr_a_reference.png \--image images/credit_card_05.png
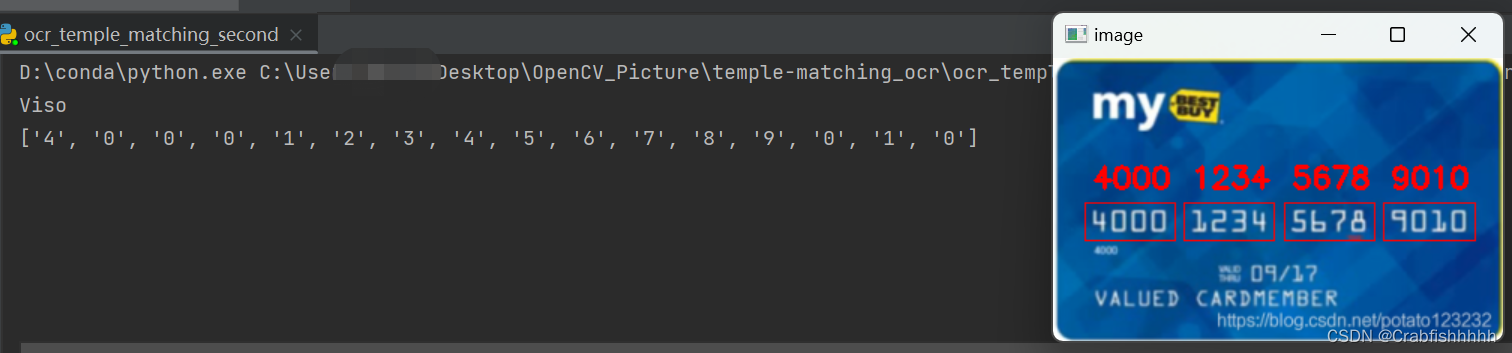
Credit Card Type: MasterCard
Credit Card #: 5476767898765432
我们的第一个结果图像,100% 正确:
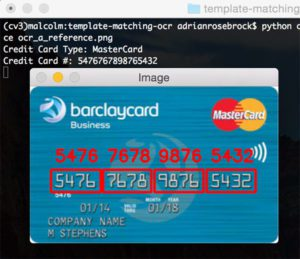
请注意我们如何能够正确地将信用卡标记为万事达卡,只需检查信用卡号中的第一位数字即可。 让我们尝试第二张图片,这次是一张签证:
$ python ocr_template_match.py --reference ocr_a_reference.png \--image images/credit_card_01.png
Credit Card Type: Visa
Credit Card #: 4000123456789010
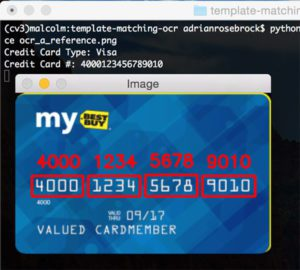
再一次,我们能够使用模板匹配正确地对信用卡进行 OCR。
$ python ocr_template_match.py --reference ocr_a_reference.png \--image images/credit_card_02.png
Credit Card Type: Visa
Credit Card #: 4020340002345678

总结
在本教程中,我们学习了如何通过 OpenCV 和 Python 使用模板匹配来执行光学字符识别 (OCR)。
具体来说,我们应用我们的模板匹配 OCR 方法来识别信用卡类型以及 16 位信用卡数字。
为了实现这一点,我们将图像处理管道分为 4 个步骤:
- 通过各种图像处理技术检测信用卡上的四组四个数字,包括形态学操作、阈值和轮廓提取。
- 从四个分组中提取每个单独的数字,导致需要分类的 16 个数字。
- 通过将每个数字与 OCR-A 字体进行比较,将模板匹配应用于每个数字以获得我们的数字分类。
- 检查信用卡号的第一位数字以确定发行公司。
在评估了我们的信用卡 OCR 系统后,我们发现它是 100% 准确的,前提是发行信用卡公司使用 OCR-A 字体作为数字。
要扩展此应用程序,您可能希望在野外收集信用卡的真实图像,并可能训练机器学习模型(通过标准特征提取或训练或卷积神经网络)以进一步提高该系统的准确性。
希望您喜欢这篇关于 OCR 的博文。
完整代码:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/47281623