契源
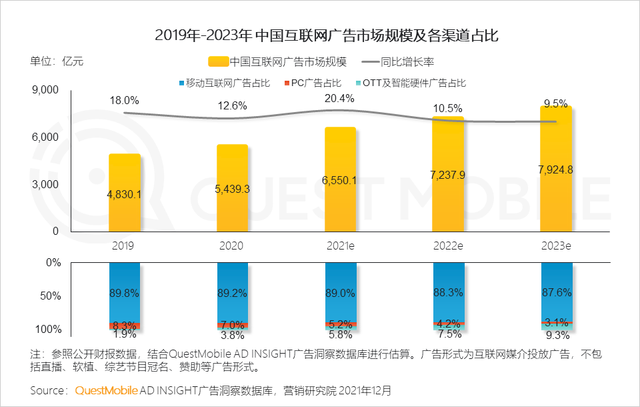
想必每个自媒体行业从业者都面临过这样一种情况:从网络上找到一张素材做封面,然而素材图片往往太模糊。那么,有没有办法对其进行高清修复呢?这就是计算机视觉领域的子领域图像超分所研究的主要问题。
在我的专业课上,曾使用复现过图像超分领域的两个经典算法SRCNN和FSRCNN,但是效果一般。具体内容可以参见我之前写的博文:https://zstar.blog.csdn.net/article/details/125613142
最近我在2021ICCV上看到图像超分的Real-ESRGAN这篇论文。
论文标题:Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
论文链接:https://arxiv.org/abs/2107.10833
该论文是腾讯ARC实验室的研究成果,作者同时开源了该算法的代码。
仓库地址:https://github.com/xinntao/Real-ESRGAN
下面是论文里的一张效果对比图,可以看出和同类算法相比,Real-ESRGAN的效果还是挺惊艳的。

理论简介
首先声明,图像超分不是我的主要研究方向,下面我就以一个“外行人”的视角简单理解一下Real-ESRGAN这个算法的原理。
如果读者对理论不感兴趣,可以跳到下一节的实践部分。
大致原理
Real-ESRGAN并不是一个凭空开创的算法,从名字上也可以看出,它是对ESRGAN算法的改进。图像超分中这条发展脉络可以这样追溯:SRCNN->SRGAN->ESRGAN->Real-ESRGAN。
看到GAN,就知道Real-ESRGAN采用的也是GAN的架构。首先是将高清图片作为数据集,然后通过下面这些步骤(涂污(blur)、下采样(Downsampling)、添加噪声(Noise)、JPEG压缩(Compression))来生成低分辨率的模糊图片。
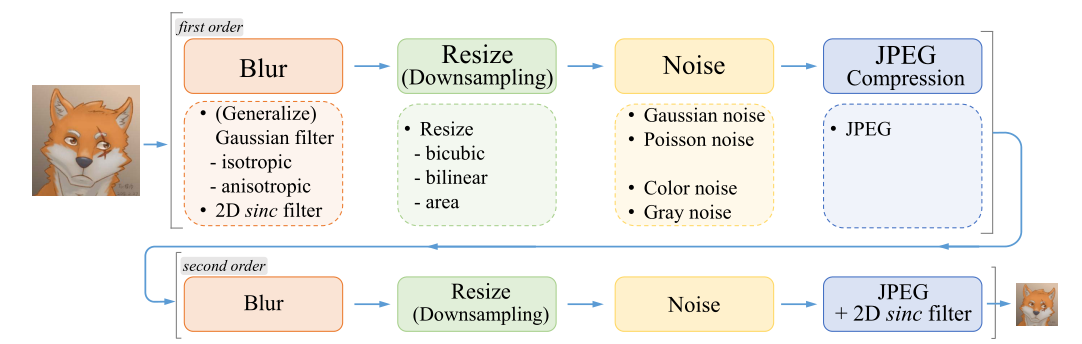
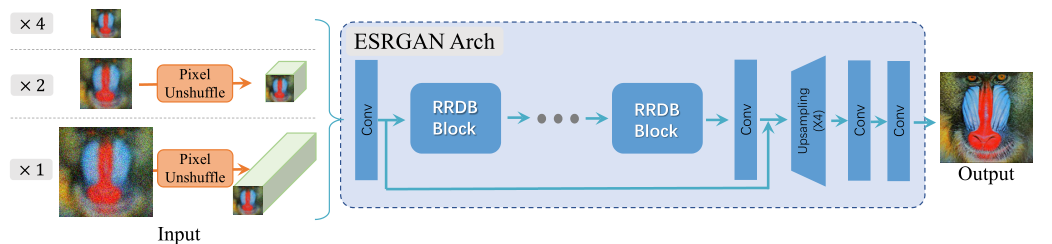
然后,将这些处理后的图片输入到生成器(Generator)之中,生成1倍、2倍和4倍高清放大的图片。
最后,将生成的图片和真实的高清图片混杂在一起,输入到判别器(Discriminator)中进行判别,如果能够“骗过”判别器,就说明生成的图片质量不错。
论文创新
相较于ESRGAN,Real-ESRGAN主要有下面三点创新:
- 提出了一个高阶降解过程来模拟实际降解过程,并利用sinc滤波器来模拟常见的振铃和超调伪象。
- 采用了一些必要的修改(例如,光谱归一化的U-Net鉴别器)来增加鉴别器的能力和稳定训练动态。
- 用纯合成数据训练的Real-ESRGAN能够还原大多数真实世界的图像,获得比以往作品更好的视觉性能,在真实世界的应用中更加实用。
论文局限
论文最后提到该算法有下面三点局限:
- 一些恢复的图像(尤其是建筑和室内场景)由于混叠问题,容易出现扭曲的线条。
- GAN训练在一些样本上引入了一些伪影。
- 它无法消除现实世界中分布外退化。
更多详细的模型构建,算法处理细节请阅读原论文。
实践上手
光说不练假把式,下面就到了快乐的实践环节了。
超便捷方式
作者为了方便别人快速使用它的成果,直接打包好了一个exe程序,以至于不需要配环境也能直接使用。
我下载的是Windows版本,顺便分享在此https://pan.baidu.com/s/18n71xRPZL7uRcnlwSnWrdQ?pwd=iznh
作者提供了五种模型:
- realesr-animevideov3-x2:2倍分辨率视频
- realesr-animevideov3-x3:3倍分辨率视频
- realesr-animevideov3-x4:4倍分辨率视频
- realesrgan-x4plus:4倍分辨率照片
- realesrgan-x4plus-anime:4倍分辨率动画图片

使用时,只需要在命令行中根据所需选择下面的命令输入:
转换图片:
1. ./realesrgan-ncnn-vulkan.exe -i input.jpg -o output.png
2. ./realesrgan-ncnn-vulkan.exe -i input.jpg -o output.png -n realesr-animevideov3
3. ./realesrgan-ncnn-vulkan.exe -i input_folder -o outputfolder -n realesr-animevideov3 -s 2 -f jpg
4. ./realesrgan-ncnn-vulkan.exe -i input_folder -o outputfolder -n realesr-animevideov3 -s 4 -f jpg
转换视频:
1. Use ffmpeg to extract frames from a video (Remember to create the folder `tmp_frames` ahead)ffmpeg -i onepiece_demo.mp4 -qscale:v 1 -qmin 1 -qmax 1 -vsync 0 tmp_frames/frame%08d.jpg2. Inference with Real-ESRGAN executable file (Remember to create the folder `out_frames` ahead)./realesrgan-ncnn-vulkan.exe -i tmp_frames -o out_frames -n realesr-animevideov3 -s 2 -f jpg3. Merge the enhanced frames back into a videoffmpeg -i out_frames/frame%08d.jpg -i onepiece_demo.mp4 -map 0:v:0 -map 1:a:0 -c:a copy -c:v libx264 -r 23.98 -pix_fmt yuv420p output_w_audio.mp4
相关参数解释:
Usage: realesrgan-ncnn-vulkan.exe -i infile -o outfile [options]...-h show this help"-i input-path input image path (jpg/png/webp) or directory"-o output-path output image path (jpg/png/webp) or directory"-s scale upscale ratio (can be 2, 3, 4. default=4)"-t tile-size tile size (>=32/0=auto, default=0) can be 0,0,0 for multi-gpu"-m model-path folder path to the pre-trained models. default=models"-n model-name model name (default=realesr-animevideov3, can be realesr-animevideov3 | realesrgan-x4plus | realesrgan-x4plus-anime | realesrnet-x4plus)"-g gpu-id gpu device to use (default=auto) can be 0,1,2 for multi-gpu"-j load:proc:save thread count for load/proc/save (default=1:2:2) can be 1:2,2,2:2 for multi-gpu"-x enable tta mode"-f format output image format (jpg/png/webp, default=ext/png)"-v verbose output"
作者还提供Linux和Mac脚本,如有需要可以去上面的仓库中下载。
源代码方式
如果需要在Real-ESRGAN算法上做一些研究,就必须把它的源代码clone下来了,此外,还必须在本地装好pytorch环境。
在此基础上,还需要手动安装basicsr、facexlib、gfpgan这三个库。
gfpgan库安装比较简单,直接使用pip安装即可。
pip install gfpgan
其它两个库用pip安装可能会报错,需要将这两个库的源代码clone下来,然后在目录下输入下面的命令进行安装。
python setup.py develop
这两个库的我也备份在此:
BasicSR:https://pan.baidu.com/s/1fNXn3uCFW4SGCwGXfZQJtw?pwd=yz3j
facexlib:https://pan.baidu.com/s/1UANS3Z5ue08S7JGAZZMkaw?pwd=idu8
安装好后,还需要将作者提供的训练好的模型权重放到如图所示的位置下:

下面是两个主函数:
- inference_realesrgan.py:推理图片
- inference_realesrgan_video.py:推理视频
以推理图片为例,使用时,只需修改下面几个参数:

- input:输入图片路径或者文件夹路径,若是文件夹路径,则批量将文件夹下所有图片进行转化
- model_name:选择模型名字
- outscale:放大倍数,尽量和模型中的x保持一致。
实践效果
下面先看使用anime模型对动漫图像进行修复,我这里选择了《Bleach》里面的主角黑崎一护:

可以看到,修复之后,一护的头发棱角变得清晰可见。
下面再尝试对真人照片进行修复,我选择了常驻嘉宾毕导的照片,选这张照片的原因不仅是这张照片原本分辨率就不高,而且图片中包含了文字、砖墙纹理和人物,修复难度更高。

可以看到图中地板、墙壁的修复效果还是显著的。然而,毕导的脸部修复依然没有想象中的清晰;x4修复之后,背景上的文字被AI“脑补”成了方块字。。
总体看来,对于三次元的照片修复效果不如二次元图片,也有可能是模特颜值的原因(狗头)…
代码备份
本次实验所用到的代码备份如下(包含作者提供的预训练权重):
https://pan.baidu.com/s/1dNTVgz4F_53xSOOBIL_0Ag?pwd=kmdf