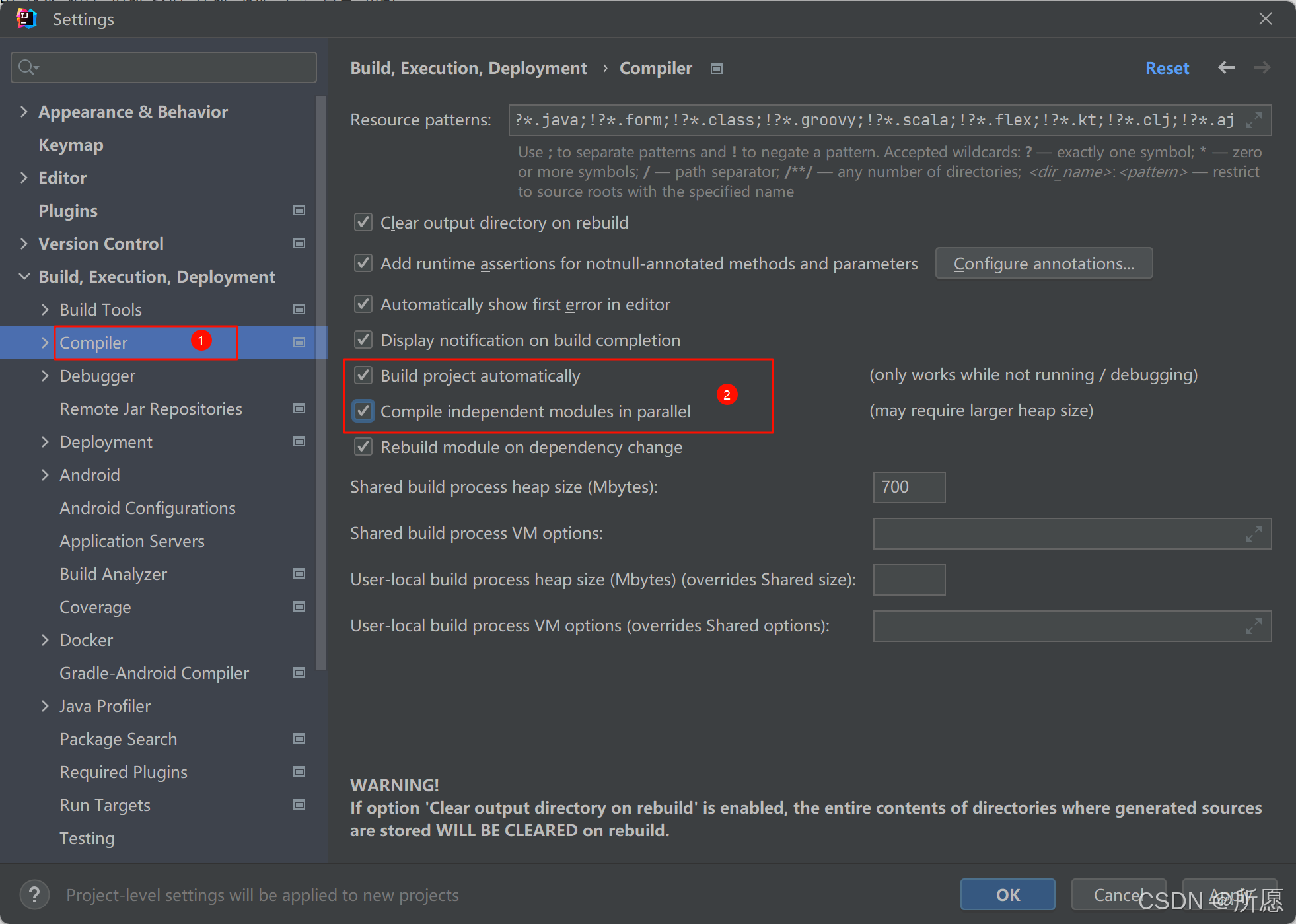
3.UI模板
当我们选择一条已经建好的业务对象点击功能按钮【UI模板】进入该业务对象的UI显示配置界面。

右边填写的是UI模板的编码以及对应名称;菜单界面配置以业务对象+UI模板编码获取显示界面。

3.1【列表-按钮】
展示的对应业务对象界面的功能按钮配置;其中【功能】那一列就是我们选择对应得功能按钮,比如最常用得【新建】、【编辑】、【查看】、【删除】等,后边【权限码】这一列是选择完功能按钮之后会自动带出对应权限码不需要我们单独修改。(底层框架统一设置,如需特殊定制联系开发)。

3.2【列表-条件】
是配置不同的查询条件来过滤展示数据
3.2.1【查询参数】
参数填写:IgnoreDisabled=true; 如果存在停用得数据一定要填写该参数否则停用数据不会显示出来。
3.2.2【非空】
如果勾选非空选项那么当我们在该业务对象下点击查询按钮时该条件为空时会提示我们“xx条件不能为空”,只有我们填入条件后才可以进行查询数据。
3.2.3【组件】
组件分为文本、日期、下拉框、搜索框等常用得组件

文本:当我们选择组件为文本时我们可以填入对应默认值

下拉框:组件使用下拉框,在右侧属性栏我们可以做不同得配置:1.引用【域】来做为选项;2.引用【业务对象】来做为值选择。
例:备货状态选项右侧属性栏右侧类型为【域】,域对应得就是【备货状态】;默认值填写对应得数据后页面展示默认值数据。

例:DAS类型选项右侧属性栏 组件为下拉选择框右侧类型为【业务对象】,业务对象选项对应得是业务对象类型,查询参数:BizObject=DAS (表示查询DAS这个业务对象得类型),标签属性:${Code}|${Name}`,值属性:Code 。

日期:当我们需要做日期条件查询时,首先要在前缀那里加上$Range_ 否则日期组件不生效;然后右边得属性栏就可以根据我们实际存储得日期属性(日期范围、日期时间、日期时间范围、年、月、日、单个日期等)来进行配置;

搜索框:当我们选择组件为搜索框时 ,我们需要在右侧属性栏选择对应得业务对象,然后如果有过滤要求得需要把URL参数填写上去例入底下这个业务类型得:BizObject=WMSPick


复选框:当我们组件选择复选框时,只需要看需不需要填写默认值即可,其它不用更改。复选框用于特定情况的。

3.3【列表-表格】
是配置业务展示的列数据

3.3.1排序字段、排序方式
当我们界面UI展示得数据需要进行排序时,我们可以在该界面下得排序字段来选择进行排序得字段,然后选择排序方式:升序、降序;当我们选择完毕后保存,下次在打开界面该界面就会按照选择得字段进行排序。

3.3.2属性
属性这一列也就是我们界面显示哪些字段内容;也有特殊得比如我们在备货单表数据库存储得是工厂编码但是我们一般展示界面都是展示名称,这就需要我们去把备货单得业务对象做一个对象依赖和工厂,那么我们在属性选择工厂时会出现二级菜单即通过工厂编码连查出的工厂业务对象得其它对应信息;注:最多到二级菜单不支持三级菜单

3.3.3标题
标题这一列就是我们显示得列名称
3.3.4类型
类型就是我们值内容显示得方式以及对值做对应得处理;例:数字,数据库存储4位小数在这里我们可以选择类型为数字小数点显示2位,那么我们在显示界面看到的数据就是2位小数得数值;日期,如果我们存储得时时间戳当我们选择类型位日期时那么界面展示得就是yyyy-mm-d得格式;注:类型为【域-值列表】,该类型为特殊项,一般用于单据状态得显示,即当我们选择该项时,需要我们在右侧得属性栏选择对应得域。



3.3.5宽度、排序、合计、锁定
宽度就是值该字段列在界面占得宽度,如果都不填写系统默认
排序当我们把对应字段勾选排序时,那么展示界面我们可以点击排序得箭头进行排序

合计是我们把勾选合计得列进行汇总;注:只用于数字类型得列
锁定可以参考excel表格得冻结列,即我们对该列进行左锁定那么我们向左滑动时该列不会跟着滑动,右锁定时即该列在我们导航栏往右滑动时不会跟着滑动同时滑动。
3.4【列表-新增/修改】
是配置该业务对象的新增以及编辑界面显示字段

3.4.1类型、标签宽度、列宽、分组
类型分为单个、批量;单个就是指一次只能新建一个单据/数据;批量就是可以一次新建在该界面维护多个数据。
标签宽度、列宽、分组默认项即可不需要单独进行修改

3.4.2属性、标签
属性就是对应得业务对象编码,也就是我们得数据库字段内容;标签就是我们在新建界面得显示得属性名称,标签可以根据自己需要进行修改,比如Code 默认标签名为编码 我们可以更改为出入库单编码等。

3.4.3组件
组件参考【列表-条件】中得组件配置;不过新增这里右侧属性栏增加了一项校验,我们可以对组件得长度以及是否非空进行校验;注:支持同时多个校验条件在一个组件生效


所有数据配置完成后,点击保存则该UI模板配置完成。
慧集通操作指南 - 飞书云文档






![[Transformer] The Structure of GPT, Generative Pretrained Transformer](https://i-blog.csdnimg.cn/direct/6b9d738c744f4cbeb6e9aec049578b91.png)