整理:微信公众号@5WPuss
今天分享一篇关于数据可视化设计的好文
前排提示,文末送2本Pandas相关的好书~
在如今的工作中(尤其是 B 端)越来越多的会开始出现数据可视化的身影,对于一部分小伙伴来说这个概念是较为陌生的,面对这道无形之中提升的“门槛”我们常常会表现的手足无措。所以,为了让大家对于数据可视化不再那么束手无措,我希望能通过这篇文章和大家一起交流学习,解决一些属于我们共同的问题。
那么我们还是老规矩,想要了解一个事物首先需要知道的是它的定义。

数据可视化的基本信息
1. 数据可视化的定义
较为笼统的来说数据可视化是一种由图形、图像、数字等元素组成的语言用于解释、呈现目标数据之间的关系。从这个定义上来看,数据可视化从外观层面来说是与图形、图像这些视觉元素密不可分,这也是数据可视化最为明显的特征。
而结合我们实际的生活与工作来说,数据可视化是一种以图形符号为主要表现形式,将不可见的、抽象的、复杂的、枯燥的、专业的、不直观的数据内容,有趣的、浅显的传递给用户的有效手段。用户可以通过这样的手段完成自己的目标(例如对选定范围内的数据进行分析,发现数据的周期与规律、迅速找到自己目标节点中的关键数值、对比几组数据以了解当下研究对象的情况等)这也是数据可视化最为明显的价值。

2. 可视化发展简史
关于可视化的发展史上可追溯至 1950 年,当时人们利用计算机创建出了首批图形图表,可以说是数据可视化图表最为早期的雏形,而在 50-60 年代的可视化中又以查尔斯·约瑟夫·米纳德的《1812-1813 对俄战争中法军人力持续损失示意图》为代表。
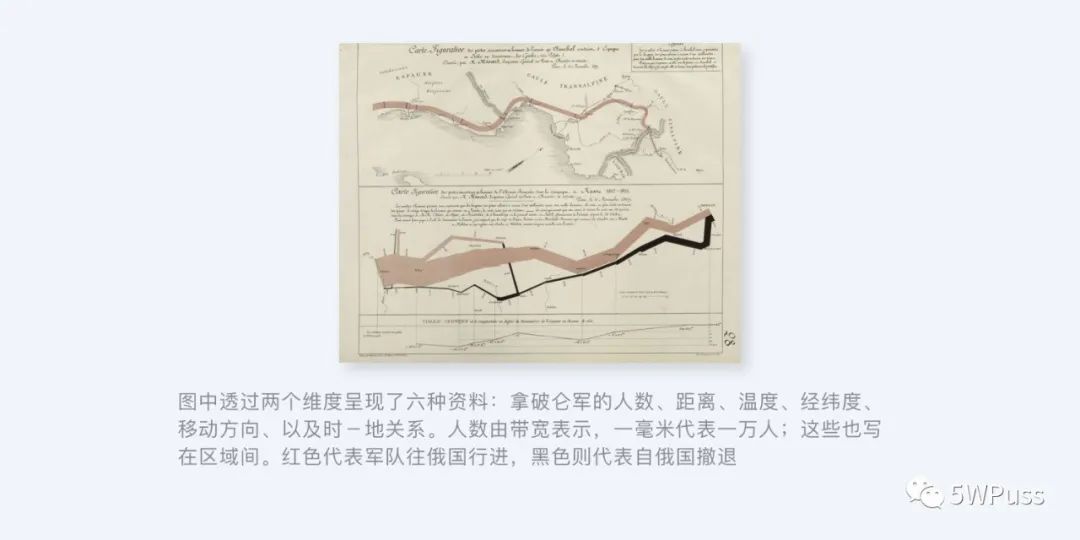
该图描绘了拿破仑的军队自离开波兰到俄罗斯边界后军力损失的状况,也是后世分析拿破仑对俄战争的重要数据分析资料,后来这种带状图被称为“桑基图”用来解释能量的流动。
而可视化真正被提到一个应用理论的高度是到了 1987 年布鲁斯·麦考梅克和马克沁·布朗所编写的美国国家科学基金会报告《Visualization in Scientific Computing》(科学计算之中的可视化),其意在强调了基于计算机的可视化技术方法的必要性,此时的概念已经与现在我们所接触的工作中的数据可视化是非常接近。
到了 90 年代初人们发起了一个称为“信息可视化”的研究领域旨在为许多应用领域(科学、商业、行政、财务、数字媒体)之中对于抽象的异质性数据集的分析工作提供支持,与前面提到的“科学可视化”交叉形成了现在耳熟能详的“数据可视化”,此时这个词汇才慢慢的被更多的专业领域的人所接受,并在之后互联网的不断发展中扩充着自己的分支。

3. 为什么会使用数据可视化
目前大量开始使用视觉可视化的原因其实非常简单大致的原因可以分为需要处理的数据量太大了和人脑不够用了。
据不完全统计 IBM 公司每天有 2.5 亿字节数据的吞吐量,麻省理工学院的研究科学家 Andrew McAfee 和 Erik Brynjolfsson 教授指出,如今在互联网上传递的数据量比过去 20 年的总和还多,而且根据 IDC 预测,到 2025 年将有 163 万亿 GB 的数据。
这是非常惊人的,而这么多需求的数据量单凭人脑的计算能力和处理能力来说是完全无法与之匹配的,研究表明人脑很难同时处理 5 组以上的抽象数据,所以这种单线程的处理方式就决定了需要借助外力。
而对于用户尤其是决策层的用户来说在现实的工作场景中经常需要同时处理超过 5 组以上的数据并需要对其建立精准的分析模型以便于做出最准确的决策所以基于这样的需求,数据可视化设计氤氲而生。
4. 数据可视化的优势

基于数据可视化的需求来看,数据可视化的优势是显而易见的,可以概括为两点:认知减负和传递赋能。
认知减负是使用者在使用数据可视化工具时候的最直观感受,当所面对的庞大的、复杂的枯燥海量数据集变成了图像化、通俗化、形象化的视觉符号时,我们会本能的放下对于面对冰冷数据时候的抗拒和戒备,这是因为人对于一目了然更加接近自己熟悉的有趣事物的时候,会更为亲切和愿意去主动理解。而且被处理过、规划过的简洁直观表现形式,能更为直接的让使用者看到数据与数据之间的关联,进而分析出其潜在关系,在人对数据的认知这个环节上降低了识别成本和分析成本。
传递赋能上图像传递更接近人类最本能的获取信息的方式,比起文字来说图像更像是一个解密的步骤,通过解开文字描述这重“密码”将最本质的信息进行呈现,而且对比文字,图像所能够承载的信息其实更为广泛,而且人类读图的效率要远远高于阅读文字。
无论是一个约定俗成的语义符号形象还是符合语境的配色都能够起到比文字直白表述更为强烈的深入人心效果,并且图解的形式并不受限于语言的障碍,极大的降低了沟通成本。
5. 使用目标
基于用户的使用目标来说,使用数据可视化其实就像是一个侦探用“蛛网图”辅助自己梳理思绪进行破案的过程:将一些有关的,但是较为零散信息数据用一根根线索穿插起来,形成体系化的联系,方便使用者迅速把握各个节点之间的关系进行推导。
所以说我们在设计数据可视化的时候并不是对我们拿到的数据的无脑映射,而是要基于用户的目标经过一定的处理和优化后才能进行呈现,随时记住我们是给用户在打辅助,所以我们每一步的设计一定要基于用户的思考。

用户的期望是能够高效、清晰、简洁地完成数据的对比、关键节点的查询、每组数据之间的分析等一系列交互,提升自己的工作效率,降低自己的学习和使用成本。
6. 应用场景

数据可视化的应用领域较为广泛涉及医疗、统计、管理、金融、娱乐、人工智能等一系列领域,在 UI 的设计中我们最常接触到的包括:PC 后台的数据概览、数据可视化大屏、游戏 UI、后台实时监控等。
设计师们的任务
当我们大致了解了数据可视化的历史、使用原因、优势、用户目标、应用领域后下面就要切入我们设计师最为关心的话题:我们在设计中的任务。
1. 设计难点
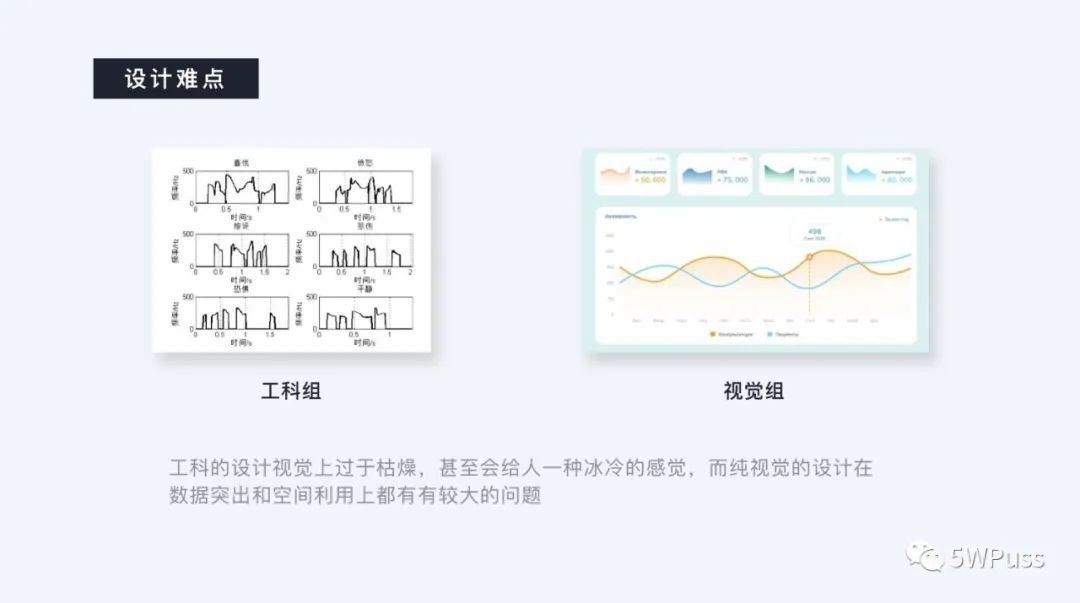
数据可视化作为一门跨领域的学科,本身对于从业者而言就有着一定的综合素质要求,但由于国内教育并没有垂直教学学科,所以在现在的阶段从业人员一部分由纯视觉设计专业的同学组成,另一部分由纯工科类型的专业的同学组成。
于是这就导致了非视觉设计师在进行设计时,会将全副精力放在强数据的准确性、合理性上,从而让视觉的易读性上有一定的损失,表现形式也较为单一枯燥,视觉感官较差,反观视觉设计师通常会将数据可视化在视觉表现形式上过度用力,虽然营造了很好的视觉体验,但是从其实用度、可用性上来说会大打折扣。
于是设计的难点很多时候就会集中在平衡视觉与实用之间的关系。
2. 设计目标
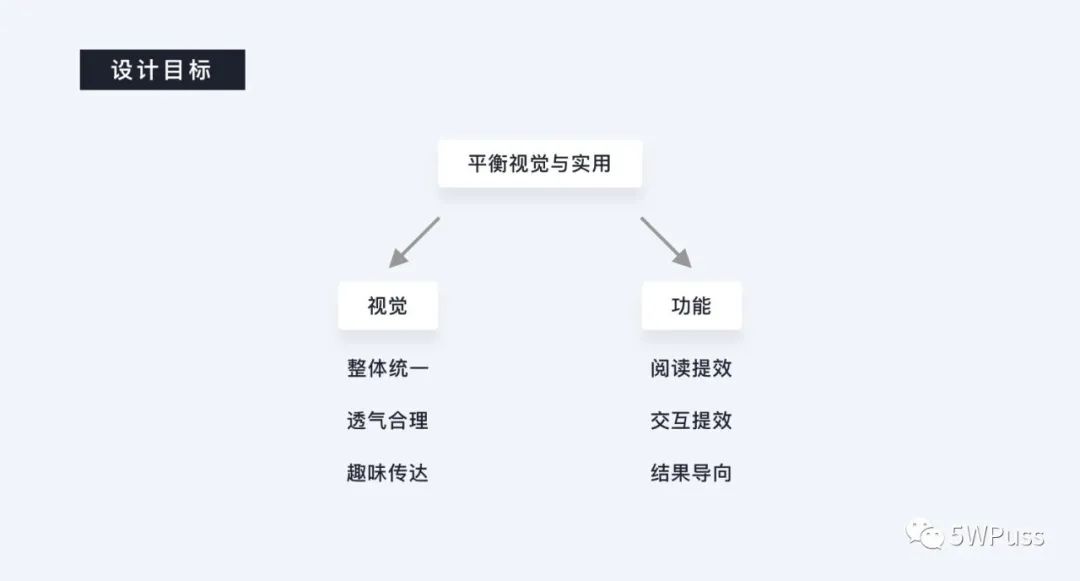
通过以上分析,不难看出设计的主要目标,而面对这句较为抽象的“把握设计与实用之间的平衡”其实无外乎也就是拆解到功能和视觉这两个方面。
从功能上来说,我的目标是提升用户的数据阅读效率、让用户能够迅速 Touch 到目标信息,提升交互效率,一切都是以结果为导向,以解决用户问题为导向,一定记住人们不愿意接受未处理过的数据。

而从视觉上来说,我们的目标是处理好在视觉上各个模块之间的统一、透气关系,将数据进行可视化的同时尽量提升感官上的审美体验与传达上的有趣。
以上会作为后文中我们每一步设计的指导和检验的方式,从实际操作的维度上来说二者也并不是五十比五十的分配,遵循的原则是:体验一定要让位于功能,所以在视觉的层面发挥的空间其实需要比较克制。
案例制作
了解了数据可视化的设计难点,明确了数据可视化的设计目标,那么我下面进入我们最重点的环节:可视化页面案例制作,由于数据可视化的形式较多,这次我们以工作中经常接触得到的 PC 页面数据概览页为例。
1. 明确性质
同样的,细化到数据概览这个分支项目,我们同样需要明确了解其基础定义和性质,严格意义上来说数据概览部分属于 Dashboard design(仪表盘设计)的一种,其主要的目的和功能可分为分析和操作两块。

所以从综合的角度来说数据概览部分可以理解为:
其它模块的摘要视图,并显示来自应用程序各个部分的关键信息,从这点上来说建议此模块可以在其余模块设计完后再进行设计,如此有利于设计师从一个全局的视角切入进行设计,理解上也会更加透彻,否则很可能会陷入在你设计其他模块的时候不断地返回对其进行修改的怪圈。
它也是核心功能、常用功能的快速操作助手和快捷页面跳转(有点类似于导航),交互功能的排布和关键信息的显示,其共同的要求点是显而易见的,即明确各个模块之间的层级,做好顺序、优先级排布。这就需要你对业务目标有一定的了解,记住,对业务目标不了解,你的设计将毫无意义。
你可以通过查询一些内部资料、报告、也可以询问产品经理等相关负责人,还可以通过用户调研得出,这里不展开说,在动手之前你需要搞清楚:各模块之间优先级如何、你需要在一张单独的图表内展示多少变量、想展示一段时间内的值是项目和项目之间还是组与组之间、每段变量中有多少关键数据需要展示等问题。
2. 定义模块优先级
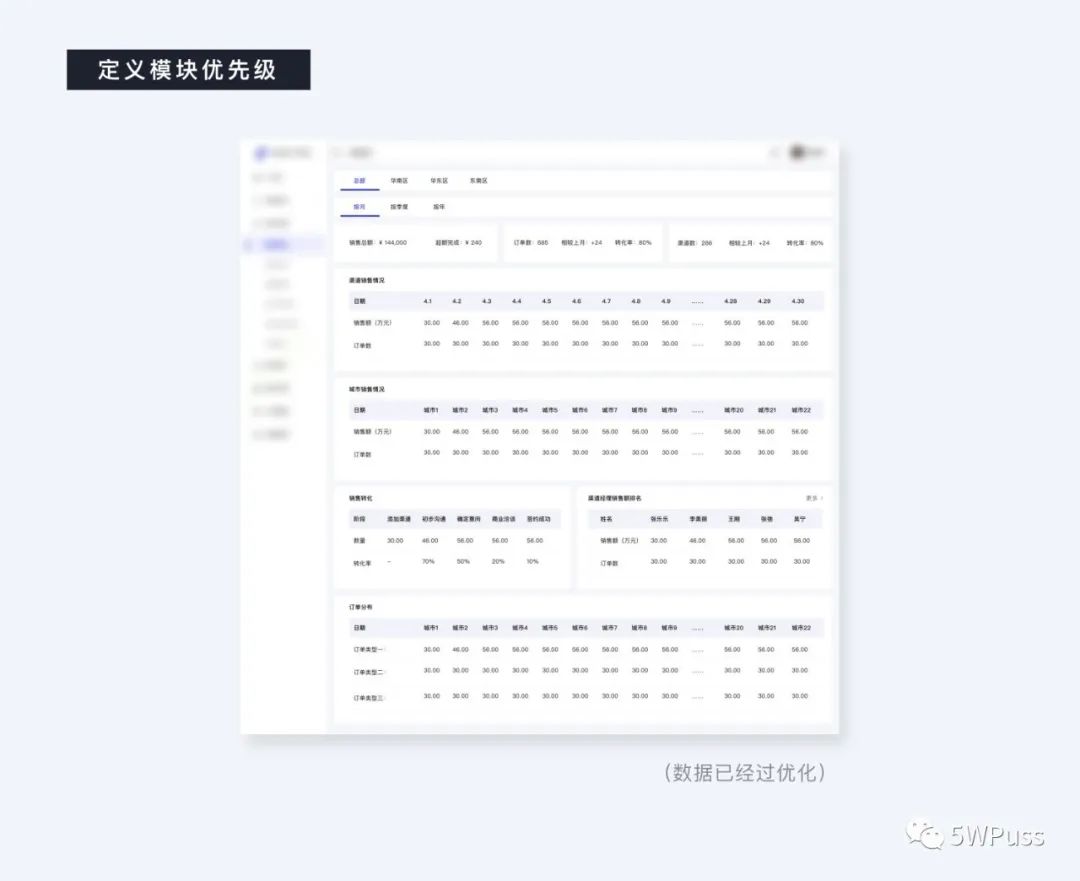
如上图所示,在工作中我们接到需求的时候是面对一堆冗杂的数据集,组成了若干个模块,但是正如上文所说,我们并不能对其进行无脑的可视化映射,所以首先要做的就是要对各个模块进行优先级的梳理排序

明确了各个模块的优先级排布之后,我们开始对每一个单独模块进行可视化转化,即哪一个部分分别用什么类型的可视化形式表现,这一步非常类似于土地使用规划,当你在将土地划分完后,为每一块土地定义其使用类型。
3. 明确图表选择
想准确的将图表与所要表现的数据进行对应,需要了解图表本身所包含的基本元素。
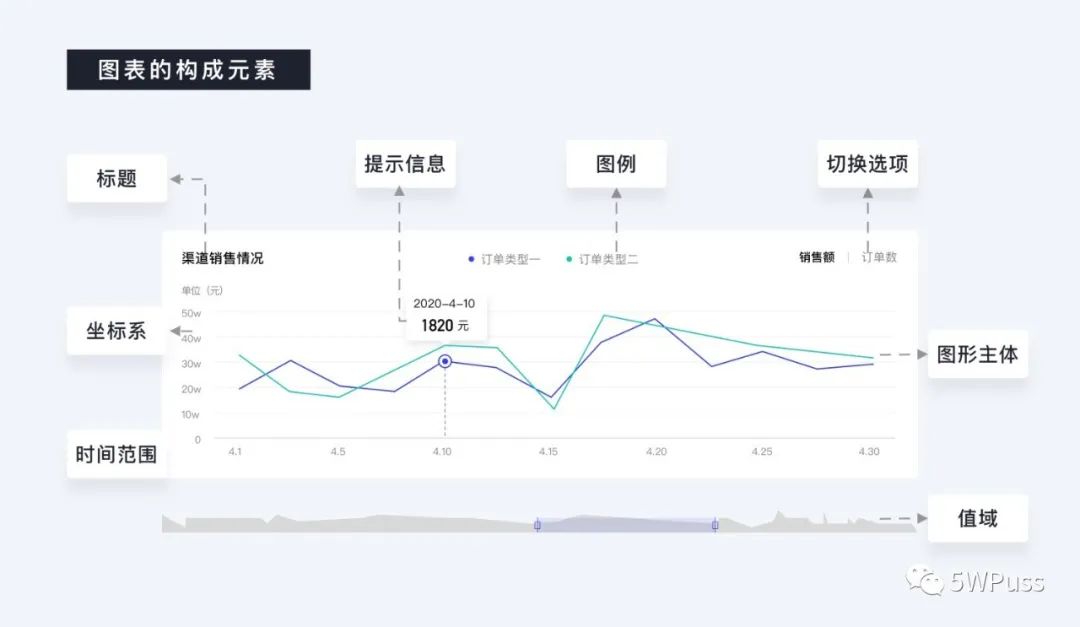
在这些元素中正常情况下一定在图表中的有:标题、时间范围、图形主体,经常出现的有:坐标系、图例、提示信息,有时候会有的有:切换选项和值域。
知道了这些重要的基础信息了,那么在面对这么多图表的时候我们该如何正确的选择来进行使用呢?

其实和之前说的一样:基于目的来进行思考,所谓的基于目的来进行思考也就是要明确你所确立的数据指标需要分析的维度,而日常使用的数据需要分析的维度无外乎:比较、构成、分布联系。
比较类图表
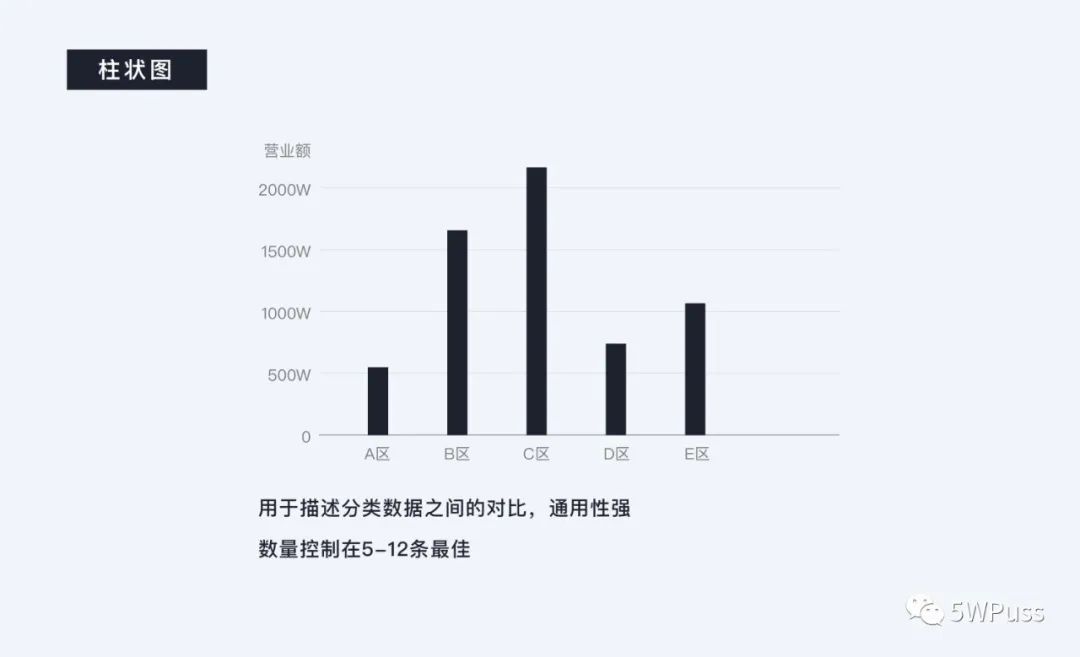
比较类图表应该是大家最为熟悉的范畴,第一时间能够想到的就是柱状图,这也是运用最为广泛的图表之一,经常出现在 PC 端之中,用于描述分类数据之间的对比,描述的数据可以是地区、品类甚至一个时间周期,但由于其扩展能力有限,所以一般不建议项目超过 12 条。
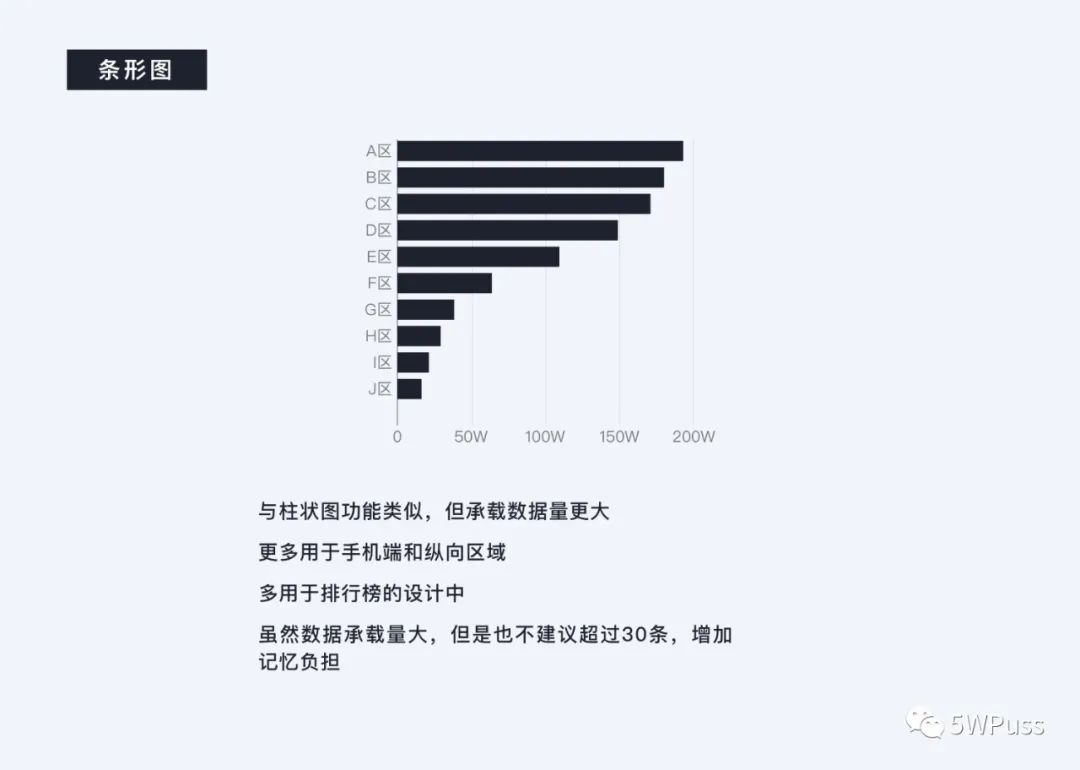
条形图与柱状图类似,看上去只是交换了 X 轴与 Y 轴,功能和承载数据种类较为类似,但不同的是,条形所能承载的项目数量相对于柱状图而言更多,由于其优良的纵向延展性一般用于手机端较多,而且从上到下的阅读方式符合人眼阅读习惯,所以也会经常用于排行榜的设计中。
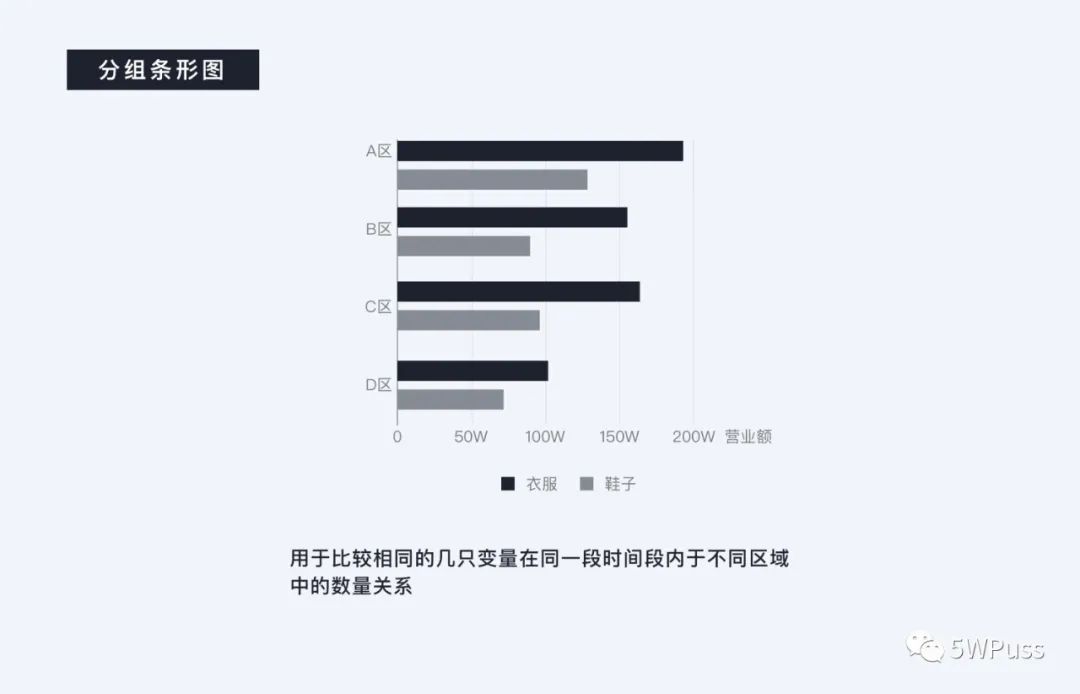
分组条形图是条形图的衍生之一用于比较多个变量在不同区域之间的数量关系,比如当想比较同样一款衣服和鞋子在四个门店中的一个季度的营业额时就可以使用分组条形图。
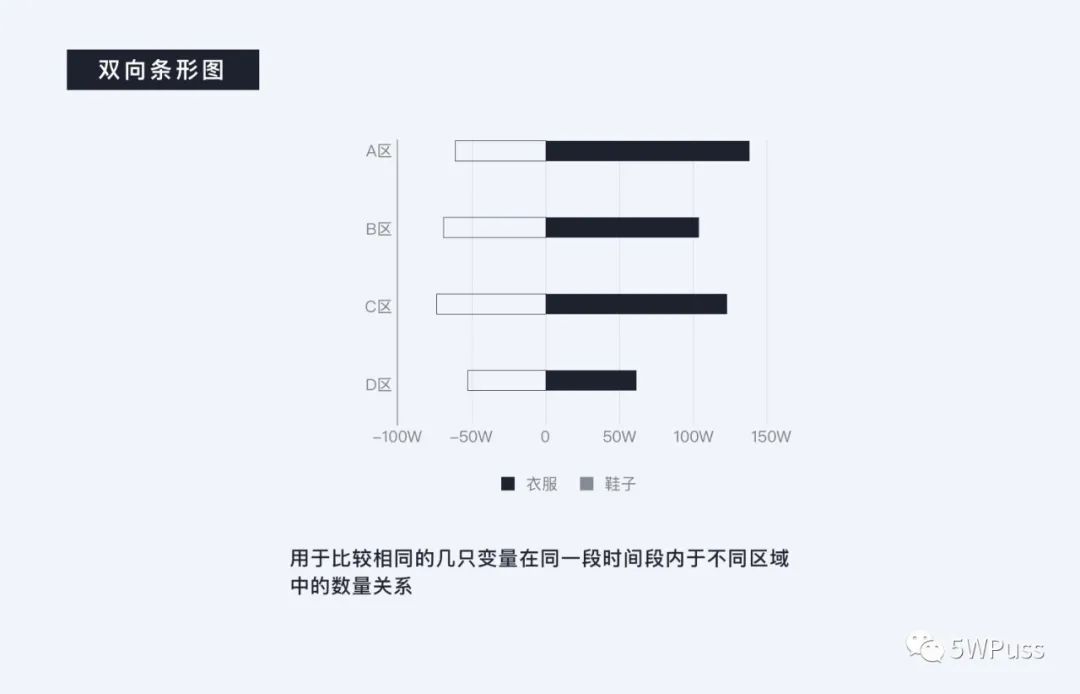
双向条形图表适合比较两组以上的分类数据比较,和分组条形图较为类似,但是由于自身外观特征更适合用于比较两组意义相反的数据,也正是如此,双向条形图的组内二级分类数量一般不要超过 3 条最好。
折线图与前者最大的不同就在于在坐标轴中加入了连续类别这个概念,数据基于时间等因素变得动态了起来,注重变化趋势的展现。
面积图是折线图的延伸,除了表示变化趋势之外还能比较所选范围内积累的值。

玫瑰图应该算是可视化图表中的“网红”,因为我们从小学的课本中就知道它还有一个别称叫“南丁格尔玫瑰图”。它是一种圆形的直方图,使用半径长短表示数值大小,其特点就在于因为其独特的外观可以将数值之间的差距在视觉层面进行放大,和将坐标轴范围缩小来提升视觉上数值的碾压是一个道理,发布会吹水最爱,但是要注意的是这不是一个表示占比构成的图,因为玫瑰图的每一份角度是一样的,一定要和饼状图等图区分开来,它用来表示的还是数值与数值之间的大小
雷达图经常用于分析一些多维的性能数据、评分数据,经常打游戏的朋友应该不陌生,有多少五边形选手可以扣个 1,每一项指标越接近圆心说明状态越差,越向外说明越佳。
子弹图用于比较当前数值与目标之间的关系,比如看当前业绩是否达标,也可以通过标记划分区域来进行更好的评估。

漏斗图适用于业务流程比较规范、周期长、环节多的单流程单项分析,一定要有清晰的环节,比如监控买家从浏览到最后下单的数量统计以求得转化率,不适合无逻辑、无流程的分类对比。
构成类图表
构成类图表整体上来说主要用于观察部分和整体的占比关系,最经典的莫过于饼状图,这个不用多说,通过每一份半圆角度所占整个圆的大小来表示部分和整体的关系,但是由于其所占面积较大,经常会让视觉过于集中,影响注意力。
相对于饼状图而言,环状图十分有效的避免的干扰视觉的问题,其本质是将饼图中间掏空,功能与饼图基本一致,但是视觉上做到了轻量化,目前在日常设计中较为常用。
旭日图相当于前面二者的结合,适用于展示多层级数据的占比关系,距离圆心越近代表层级越高,下一层级的总和构成上一层级,存在一定的父子层级关系。
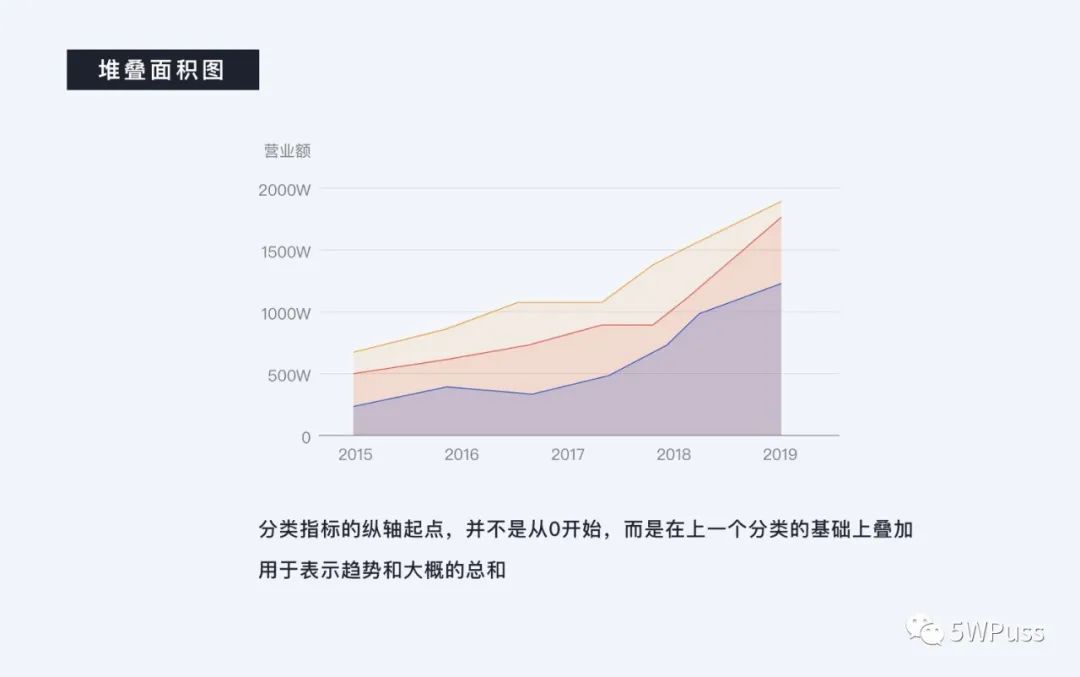
堆叠面积图出了可以表达趋势外,其优势在于能够表达总量和分量的构成关系,堆叠面积图上的最大的面积代表了所有的数据量的总和,是一个整体。各个叠起来的面积表示各个数据量的大小。
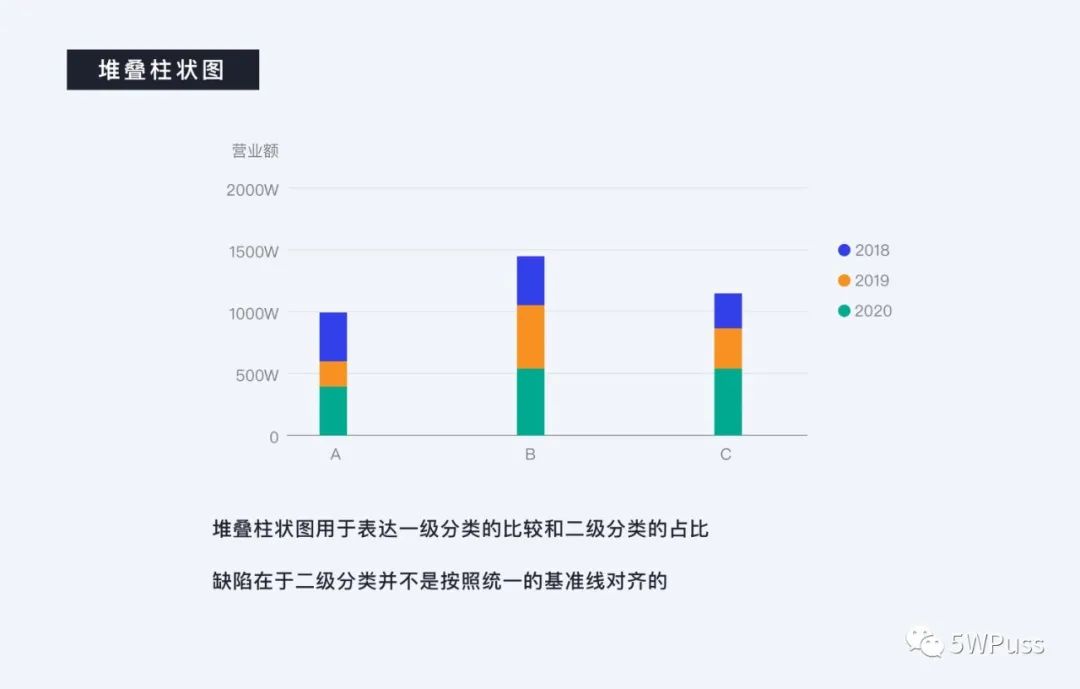
堆叠柱状图的优势在于它既可以表达一级分类的比较,同时还能看出二级分类在其一级分类中的占比,但是缺点在于二级分类并不是按照同一基准线对齐的,相比于堆叠面积图更为常用。
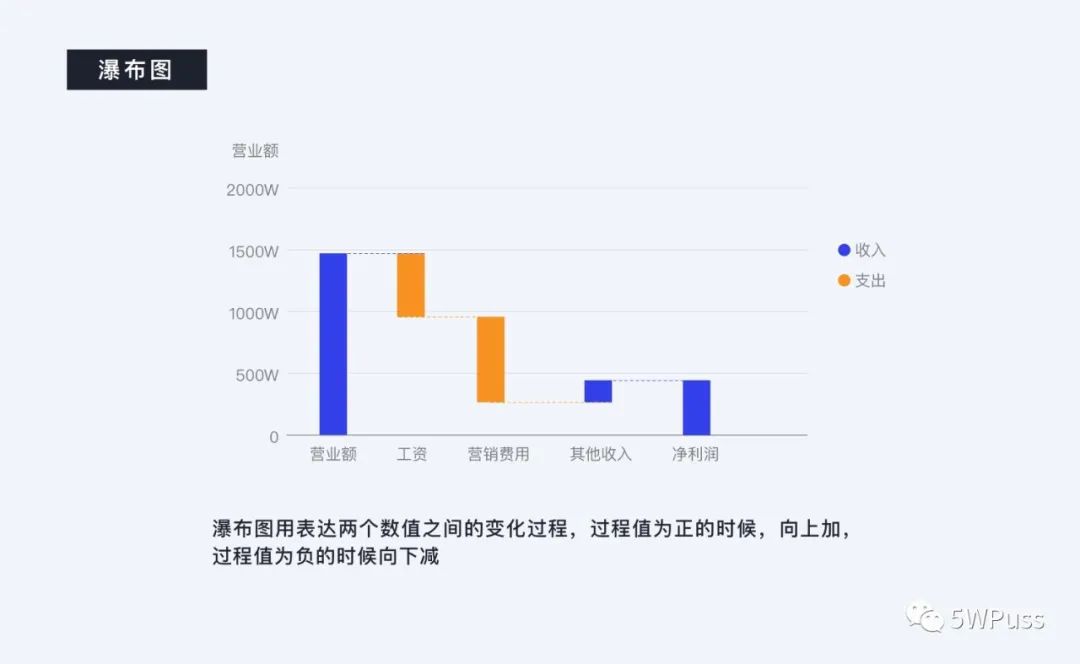
瀑布图用表达两个数值之间的变化过程,过程值为正的时候,向上加,过程值为负的时候向下减。
分布联系类图表
分布联系类地图在这两年在国人的心中其实已经非常熟悉了,因为疫情今年的地图可视化的应用经常出现在我们的生活中,地图可以结合不同的表达方式:
可以结合散点、可以结合动画、还可以结合引导线以及热力图的方式,图的形式使用视具体的业务需求来定
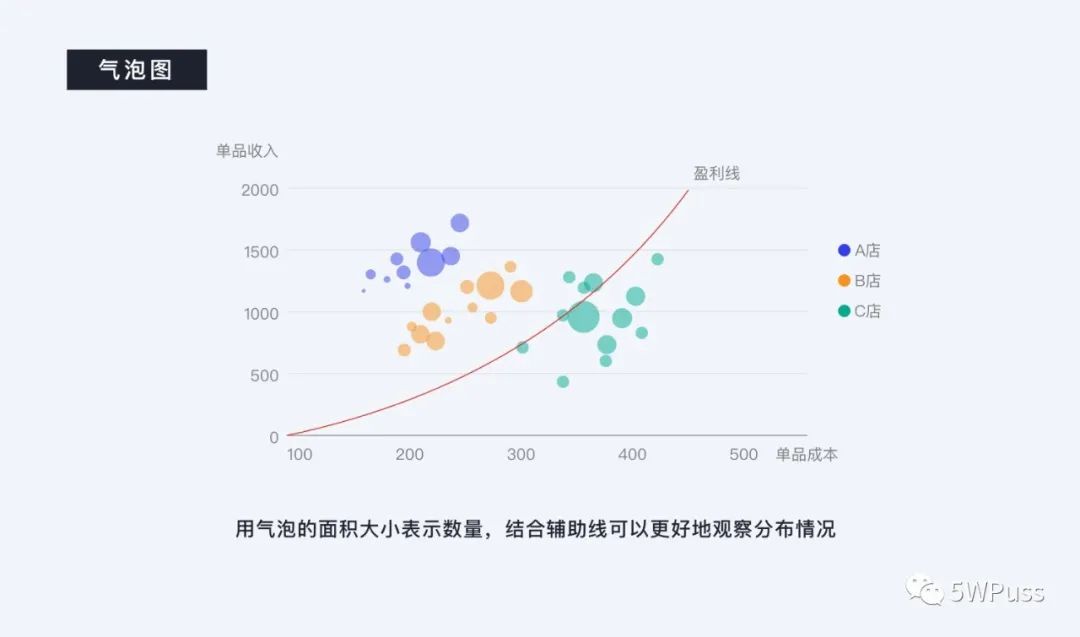
最后就是气泡图,这是在查看分布关系中最为经典的视觉模型,用气泡的面积大小表示数量,结合辅助线可以更好地观察分布情况
4. 匹配图表 重构布局

当我们对每种图表的功能和使用范围有了一个较为明确的认知之后,下面我们就可以对我们之前所规划好的优先级的模块进行可视化形式(图表)的匹配了。
进行匹配过后,我们将对布局进行重构,整体重构需要遵循的原则是
布局层级明确,首屏尽量曝光更多内容
统一透气,具有呼吸感
布局层级明确,首屏尽量曝光更多内容
从首屏曝光更多内容来说,主要是因为基于分析类的数据概览工作场景和 Analytical dashboard 自身特征决定的,用户希望能够通过仅仅一屏的的大小进行对各类信息的情况有基本的把控,达到一眼全局的目的,其主要注意力都会放在首屏,所以我们需要尽可能的在首屏安排更多的信息。

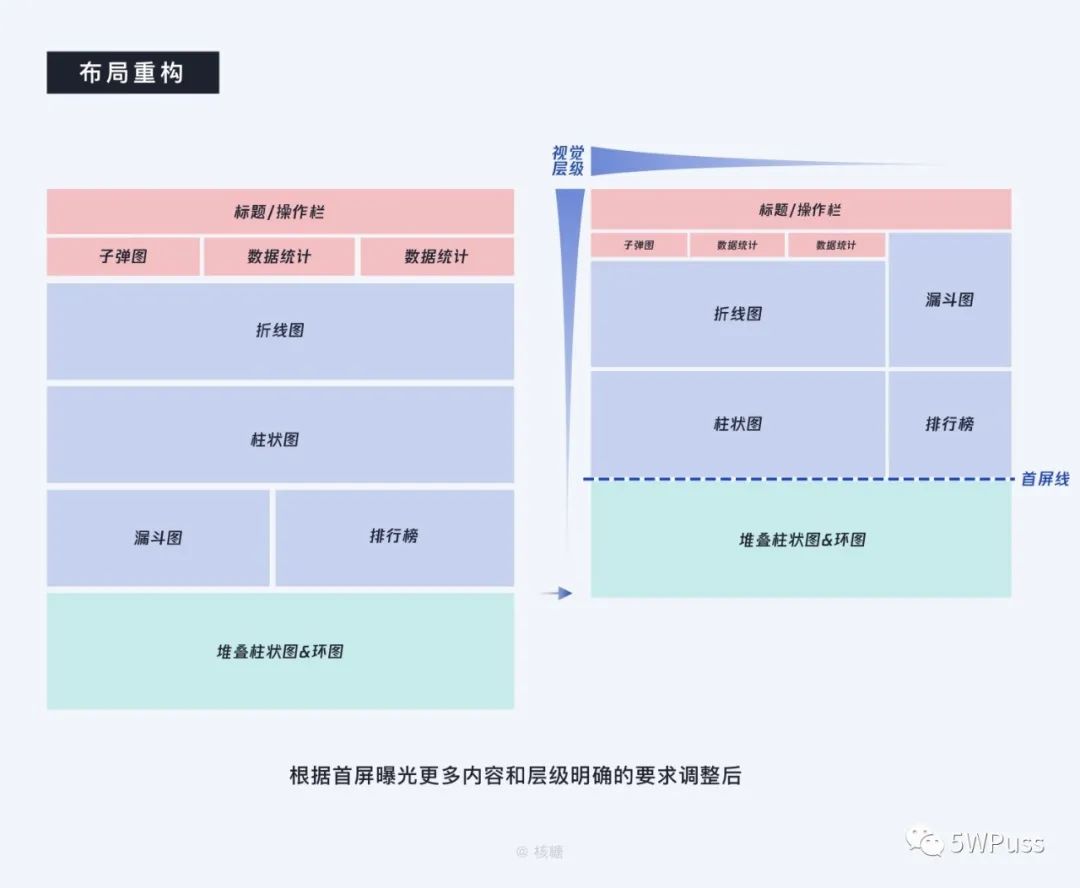
当然首屏内容也并不是越多越好,一般建议也尽量不要超过 7 组模块,而在层级明确这块儿主要是根据人眼阅读习惯所产生的优先级排布:正常情况下都是左上为优先级最高,而右下优先级较低,这是无数经典的眼动测试和设计总结产生的最常用结论,就不展开叙述了,所以当我们按照优先级、首屏曝光更多内容的原则进行处理后会得到如上图的布局。
统一透气 具有呼吸感

这主要是视觉层面的问题,统一透气的要求在首页概览中可以依靠栅格系统来解决,它可以有效的保持页面布局一致性,为页面建立基础布局框架,将页面中的所有元素都捆绑在一个体系之中,同时还能有效解决适配问题。
5. 模块拆解
完成了大规划之后,下面我们开始对一个一个的模块进行拆解,同样的以目标指导设计,边设计边验证
层级明确 突出重点
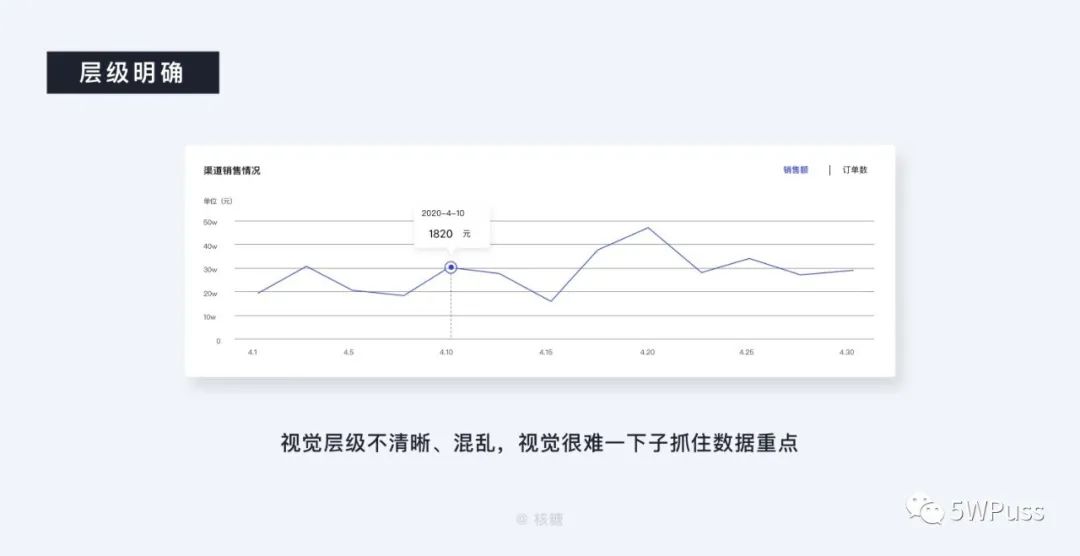
和大规划一样,单独到每一个图表同样要时刻注意层级的梳理,销售渠道部分很明确应该是运用一个折线图的形式,由于业务目标上来说更关注销售额而不是销售额和订单数的比较,所以我们选用了一个带有切换选项的折线图形式。
但是我们会很容易发现在读图时会出现较大的视觉干扰,并没有能够很好地突出重点信息,视觉层级不清晰、混乱。
于是我们对没有重点的视觉层级进行梳理,像之前划分模块那样,对视觉元素进行高、中、低的 P0、P1、P2 的设定,提升易读性

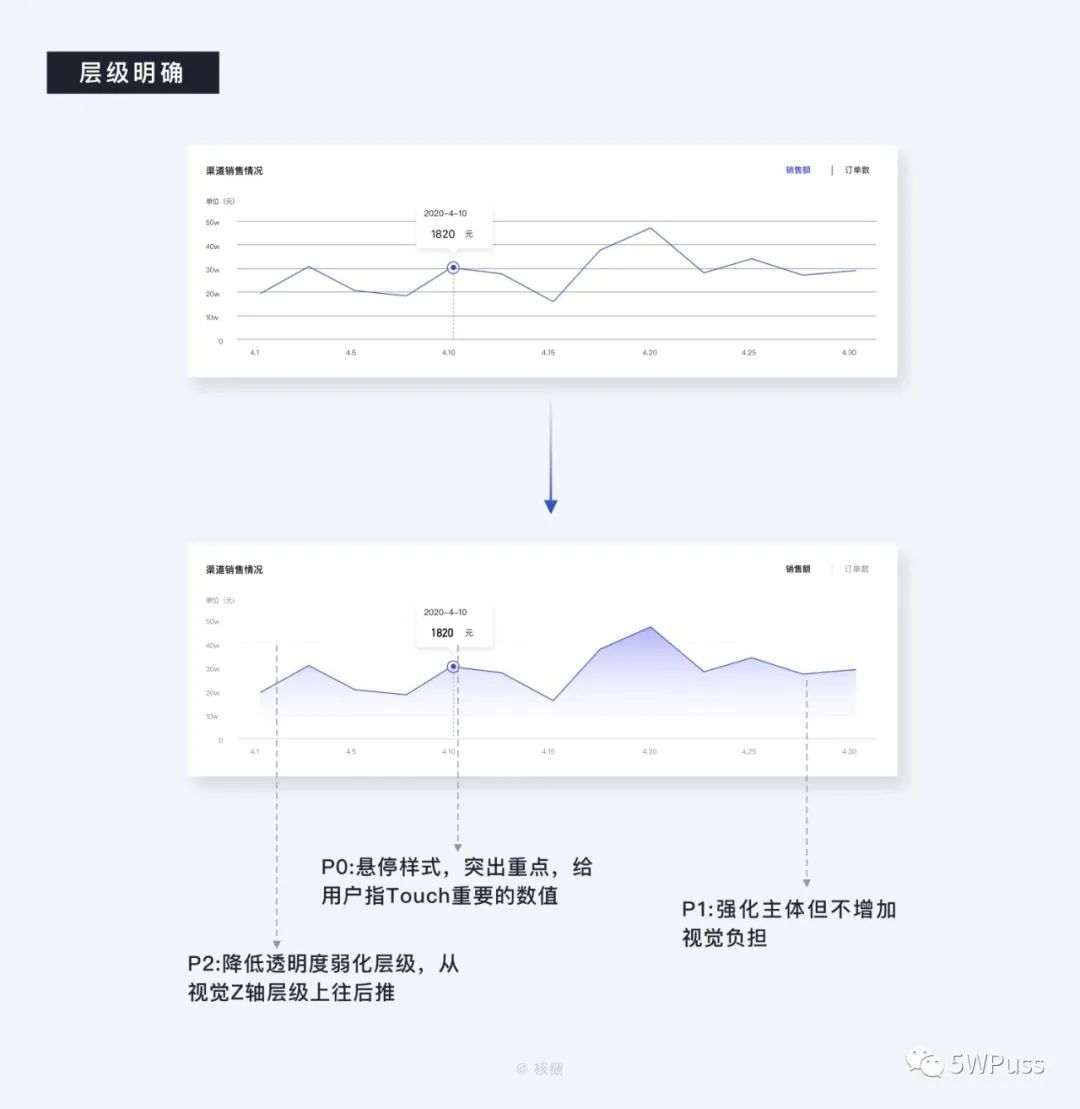
P0:层级最高的自然是重点信息突出部分,所以我们需要在其之上做加法,给予内容异形悬停样式进行具体强调,配合投影加强视觉效果,有效传递用户,拉开与别的元素的层级,同时数据部分用特殊字体并适当加大字号进行设计,方便用户第一时间能够看到所要强调的数据具体值。
P1: 其次就是主体图形部分,这是用户需要看到的重要部分,在使用场景中会长时间盯视,所以采用更低的明度与更高的饱和色颜色确保易读性,但是也不致于会让用户太晃眼产生视觉疲劳,最后考虑到该模块所处位置属于页面中较为核心的地带,给予一定的颜色透明度渐变装饰,在强化主体图形的同时不致于太显单薄。
P2:前两者都是一定程度的做加法,那么层级最低的元素需要开始做减法,此时轴线、刻度、切换选项等元素需要弱化视觉层级,降低透明度,尤其是背后的刻度线与背景的明度对比大概控制在 1.6:1 上较为合适。

销售总额、订单数、渠道数同属于一个数据统计的范畴,最忌讳的就是把以上提供的三个信息给做平,让用户抓不住重点,面对这样的情况还是一样,确立需要突出的重点信息给予特殊文字和大小的设计,选择合适的主体图形。
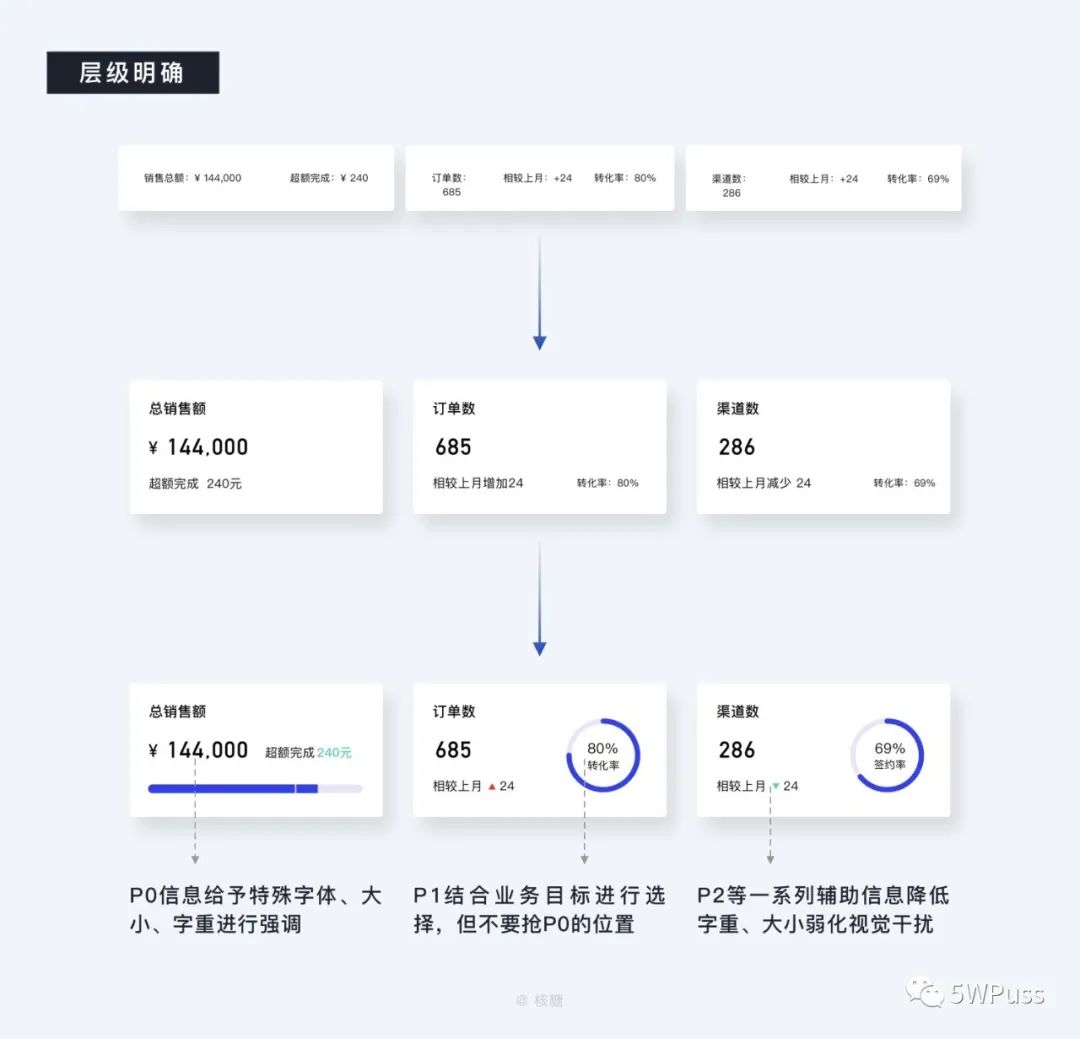
但在这里需要注意的是由于在这个模块中 P0 是金额数、订单数、渠道数这些重要值,所以可视化图形需要适当为其让步,不要放在阅读中心位置,按照 P1 来进行处理,而订单数、转换率这样的标题就成了 P2 需要适当降低透明度和文字大小,不干扰主要信息的表达。
统一营造
说到统一,最先想到的一定是色彩,无非也就是需要处理好对立统一关系,而这其中统一的比例又要大于对立,配色上尽量选用同类色系,不宜太过花哨,尤其是对于 B 端而言,建议在可能的情况下不要超过 5 种,而且主色、辅助色,对比色的比例建议控制在 6:3:1 的比例(但不绝对),既能做到有所区别又不致于过于绚丽干扰视觉。
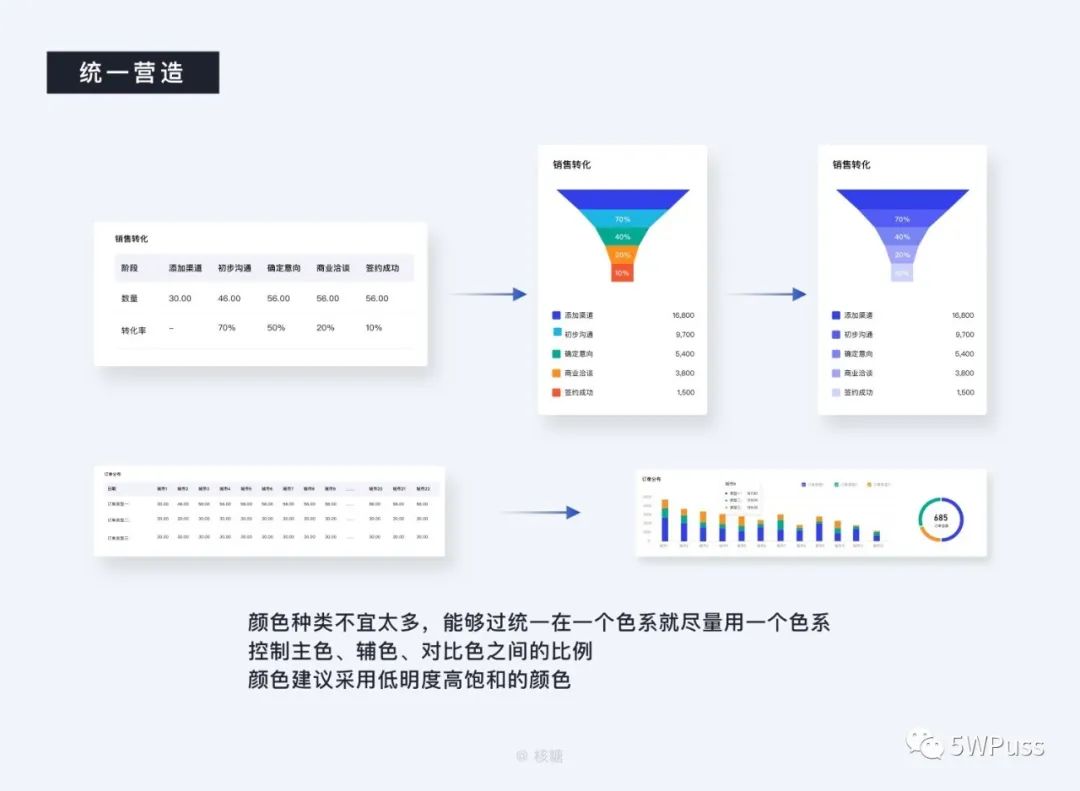
你的主色不一定要迁就你的品牌色,但是一定要是如上文说的尽量低明度高饱和,以适应于长时间的注视。
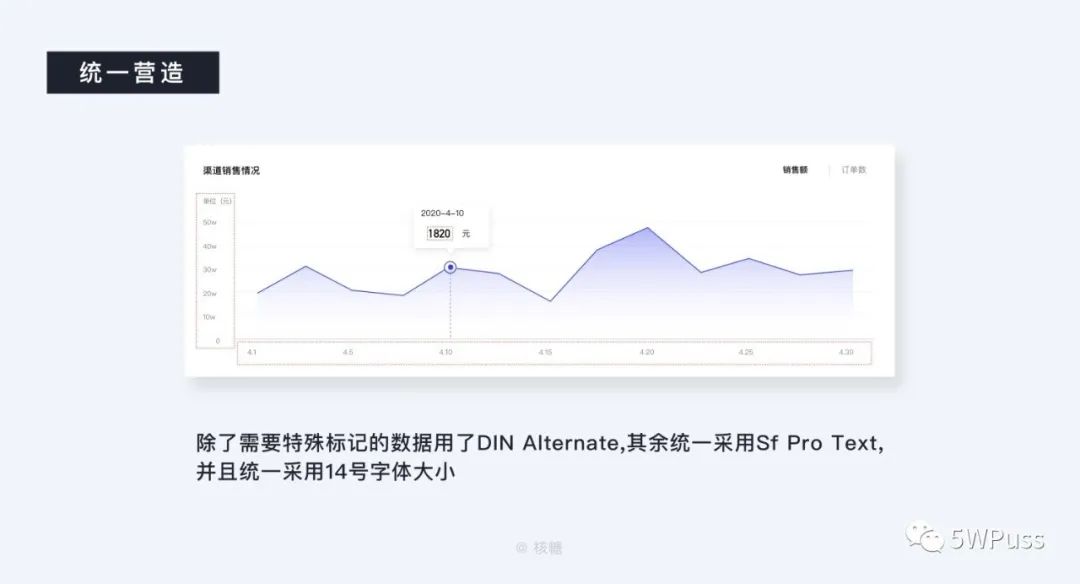
颜色过后就是字体,字体的使用需要极为谨慎,如果可以尽量只出现一种字体(但不要超过三种),并且只采用基础字体,正常情况下都是将其作为一个需要被降噪了的视觉元素来对待(比如降低透明度),在 PC 端中尽量也不要出现较多不同的字号、字重,造成没有必要的视觉干扰。
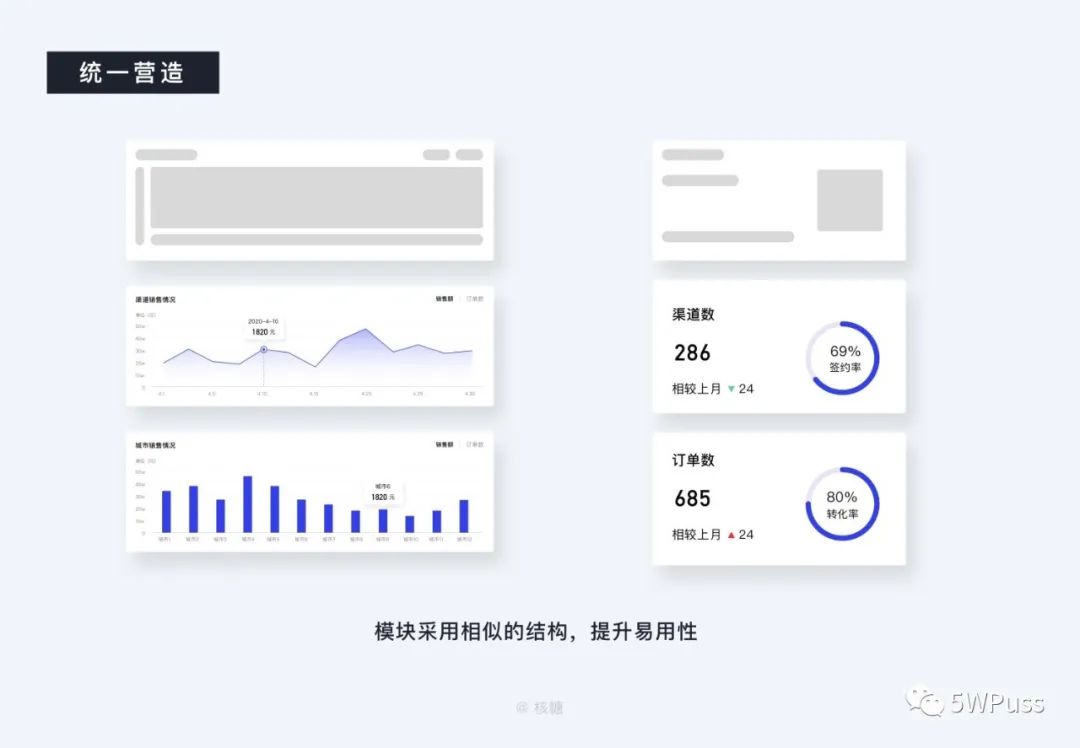
除了字体之外,在统一感的营造上卡片的布局结构也需要尽量保持一致,这是为了提升易用性,同一个产品内,相同布局会给予用户相同交互、相同功能的暗示,也更容易培养用户习惯,提升操作效率。
呼吸适中
呼吸感是留白的艺术,很考验设计师的排版能力,在单独的模块内,元素与元素之间尽量不要用实线进行间隔,可以的话利用亲密性原则通过元素间距的远近进行布局。
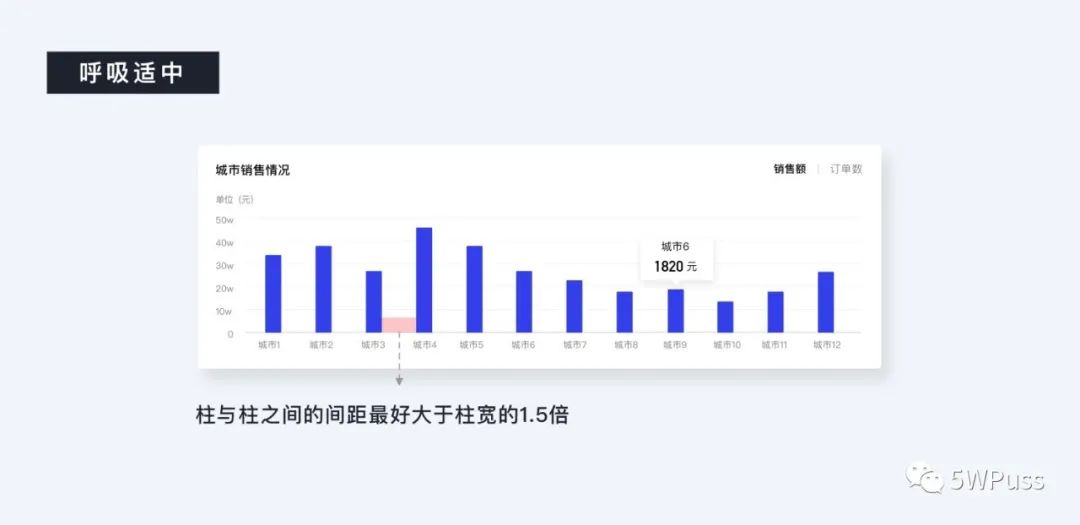
而柱状图的设计上,柱与柱之间的间距最好大于柱宽的 1.5 倍,这样才显得视觉上较为透气,不致于太臃肿。
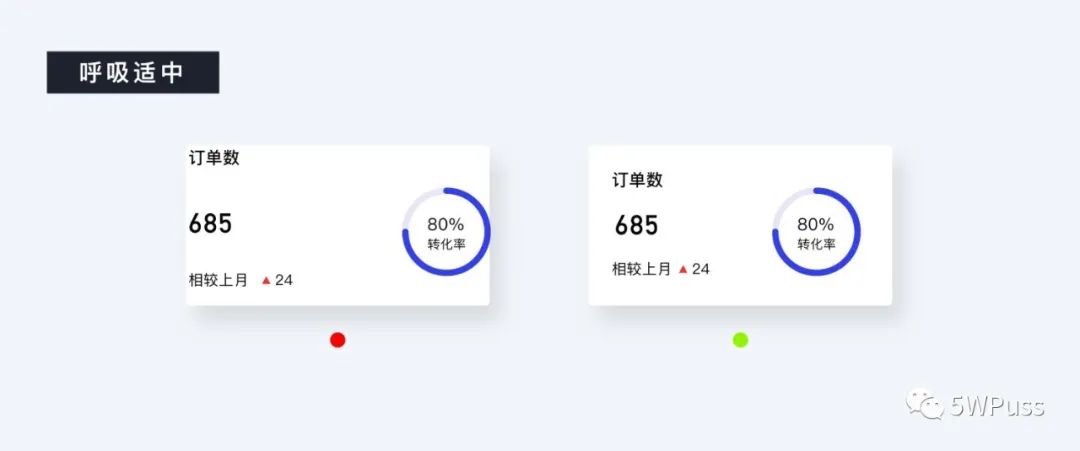
最后就是模块中的边距留白部分,这点一定要重视,不然不仅你的版心会变散,还会严重影响你的页面呼吸感。
细节处理
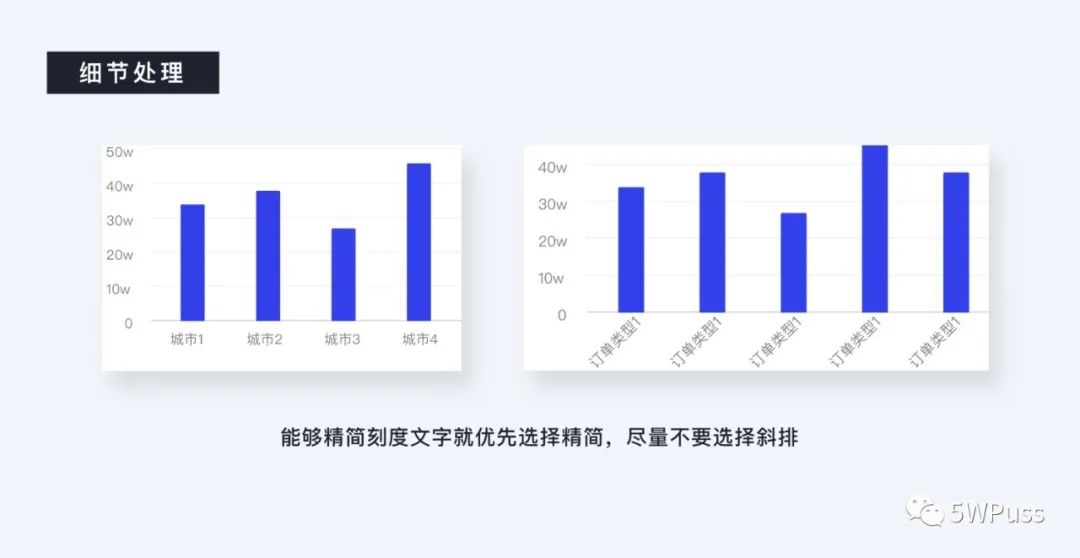
细节上首先要说的就是横纵坐标轴上的文字,上面的文字一定不要过长,最好的方式是将文字进行精简。然后横、竖排对齐处理,如果实在不能精简那么再进行斜排的方式。
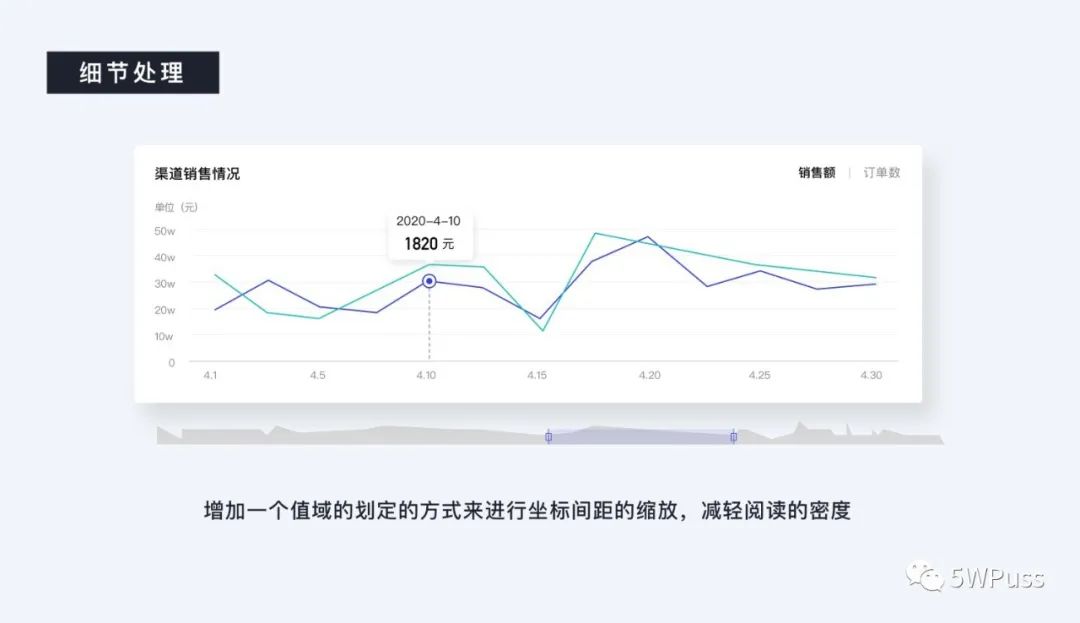
第二点就是横纵坐标轴有的时候会因为需要展示的数据过多而过于密集影响阅读,这个时候可以采用适当增加一个值域的划定的方式来进行坐标间距的缩放。

第三点就是,在排行榜等模块可以适当增加一些小设计,比如金、银、铜的设计,提升情感化元素的融入。

第四点就是,尽量不要选用一些 3D 的酷炫效果来做可视化,因为这种效果很容易对数据进行遮挡和扭曲,不是非常适用于高效阅读,也不适合 PC 页面上的交互,而且也不利于开发,比较得不偿失。
6. 组装自检
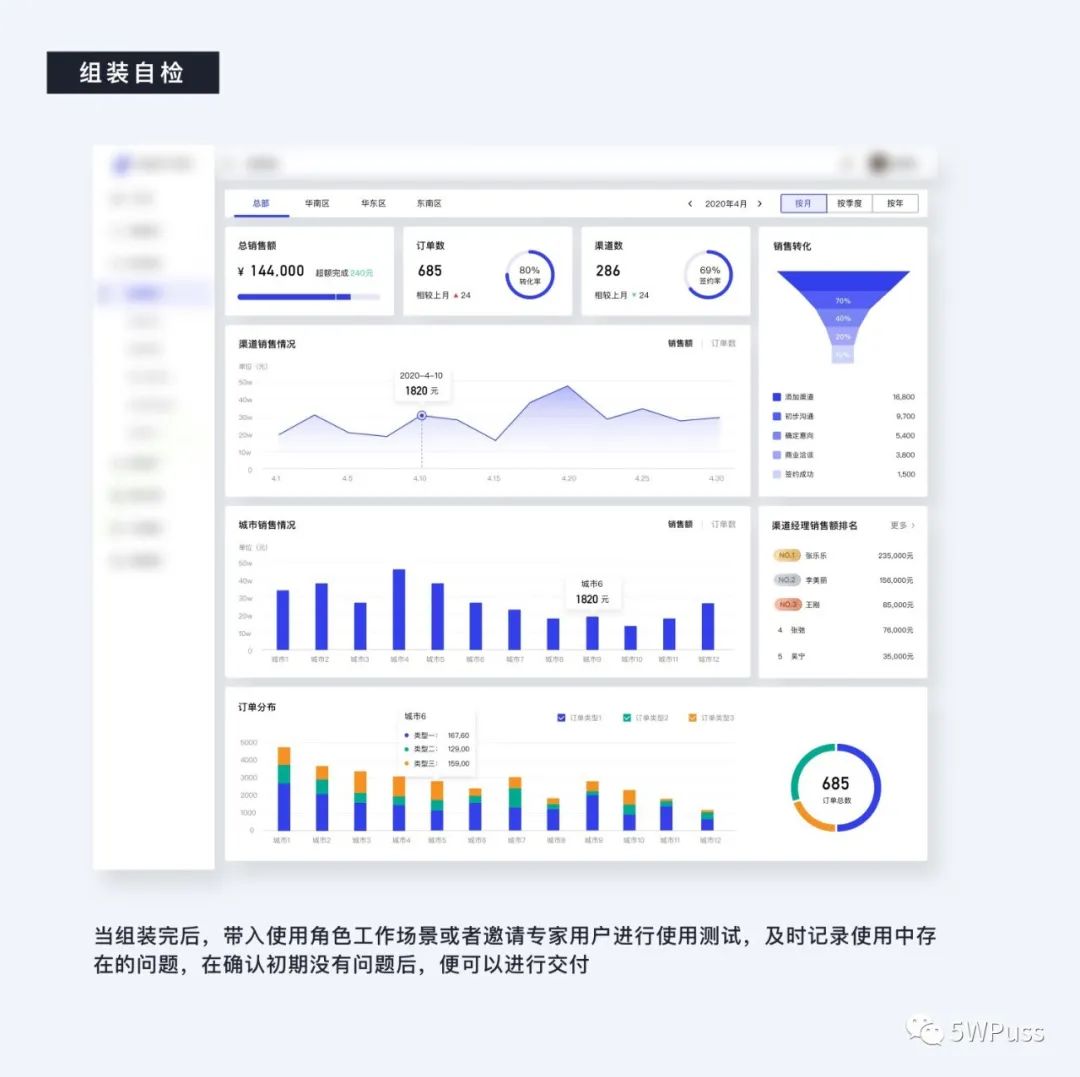
当所有的模块设计完成后,像拼高达一样进行组装,组装完成后适当调整其过于干扰视觉的地方,然后进行自检。
自检不只是从检查你的视觉、你的模块间的布局,更重要的是带入使用角色来进行检查,你可以模仿用户使用中的各种需求场景,对已经制作好的页面进行交互和阅读,看是否能够快速高效地完成使用目标。
当然除了自己之外,你还能在有条件的情况下找专家用户进行使用,即使记录使用中存在的问题并及时进行调整,当初步使用大致无问题后便可以交付。
最后的最后,送2本清华大学出版社的《Pandas1.x实例精解》,这本书详细阐述了与Pandas相关的基本解决方案,主要包括Pandas基础,DataFrame基本操作,创建和保留DataFrame,开始数据分析,探索性数据分析,选择数据子集,过滤行,对齐索引,分组以进行聚合、过滤和转换,将数据重组为规整形式,组合Pandas对象,时间序列分析,使用Matplotlib、Pandas和Seaborn进行可视化,调试和测试等内容。此外,本书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程,非常干货!

这次抽奖方式简单粗暴,本文点赞&在看后,留言点赞排名第1、第5分别送一本,8月5日22:00开奖,祝大家好运~