论文题目:Neural Machine Translation by Jointly Learning to Align and Translate
论文地址:http://pdfs.semanticscholar.org/071b/16f25117fb6133480c6259227d54fc2a5ea0.pdf
GIF来源:https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
摘要
神经机器翻译(Neural machine translation,NMT)是最近提出的机器翻译方法。与传统的统计机器翻译不同,NMT的目标是建立一个单一的神经网络,可以共同调整以最大化翻译性能。最近提出的用于神经机器翻译的模型经常属于编码器 - 解码器这种结构,他们将源句子编码成固定长度的矢量,解码器从该矢量生成翻译。在本文中,我们推测使用固定长度向量是提高这种基本编码器 - 解码器架构性能的瓶颈,提出让模型从源语句中自动寻找和目标单词相关的部分,而不是人为的将源语句显示分割进行关系对应。采用这种新方法,我们实现了与现有最先进的基于短语的系统相媲美的英文到法文翻译的翻译性能。此外,定性分析显示模型发现的(软)对齐与我们的直觉非常吻合。
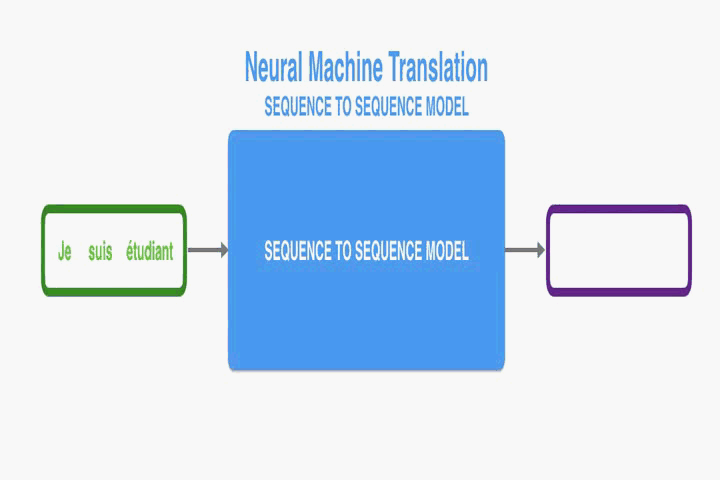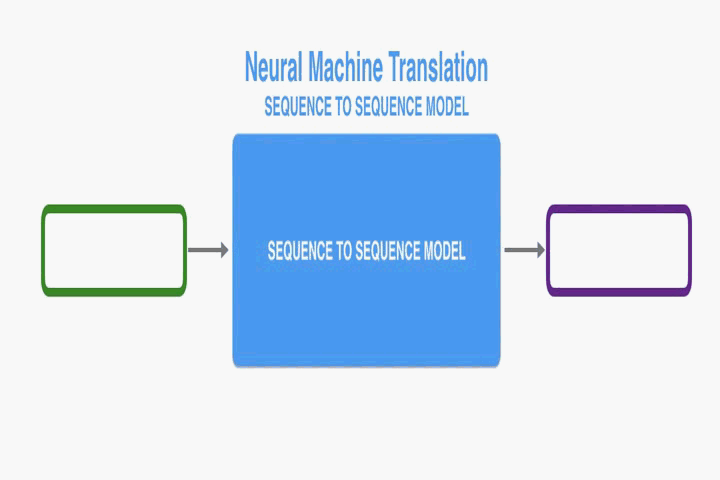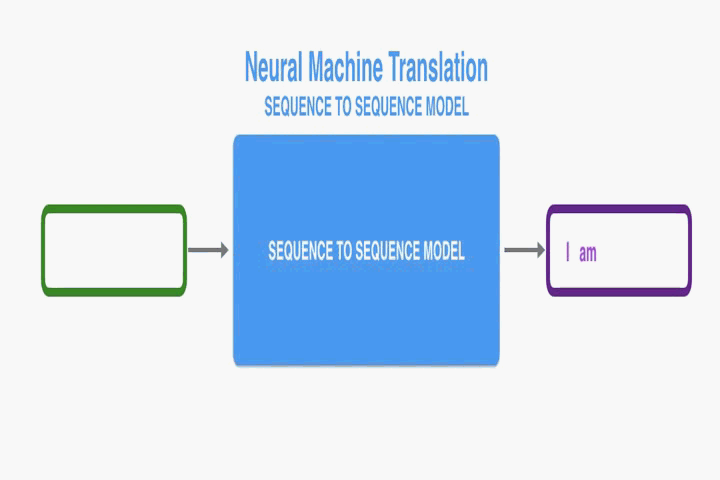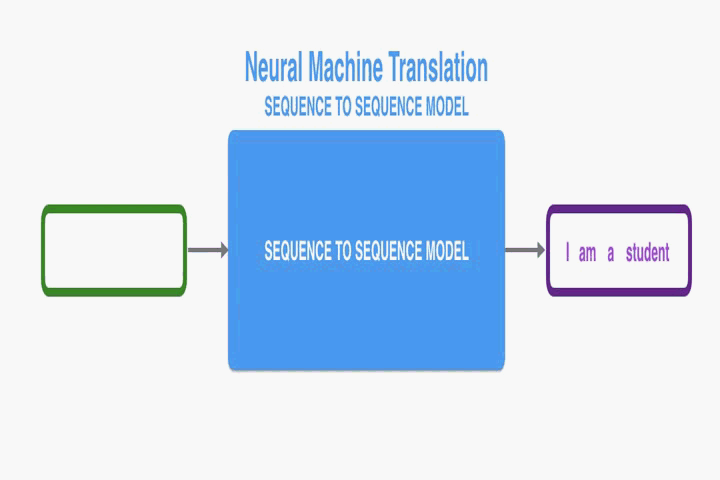
简介
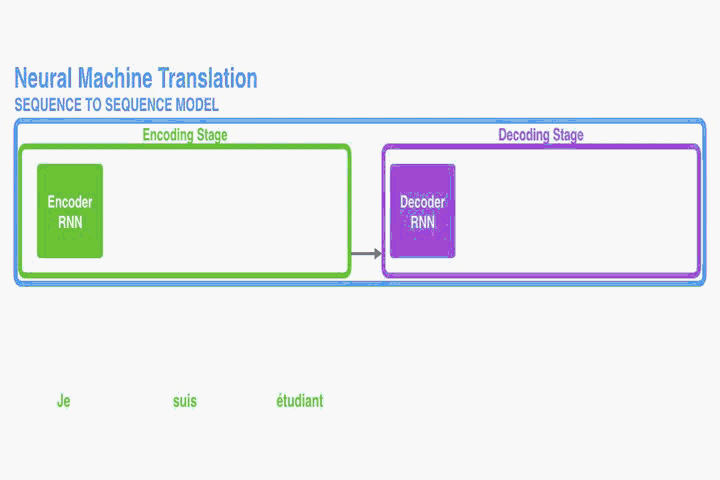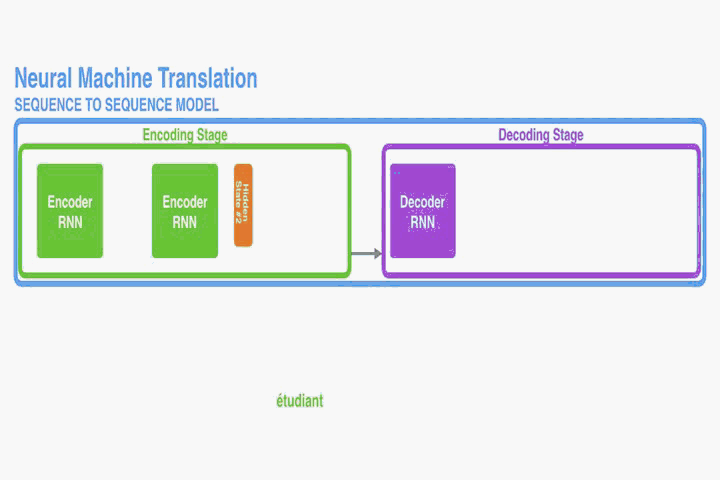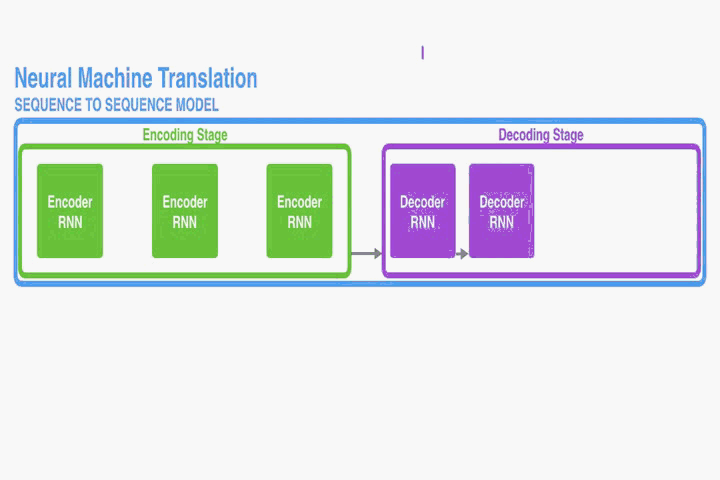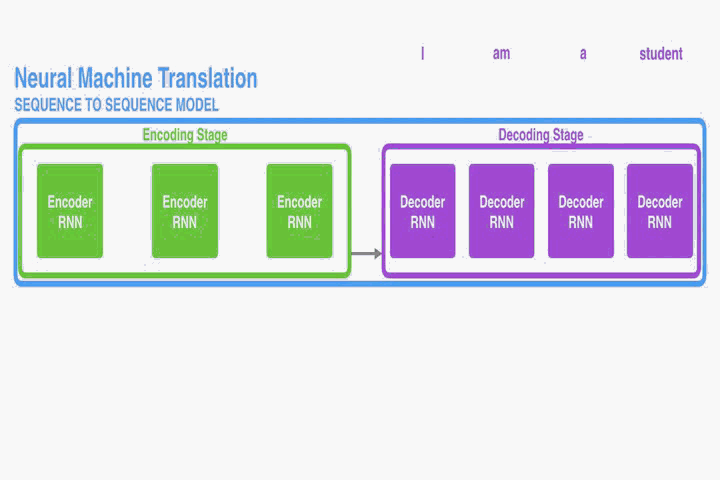
之前的NMT在处理长句子的时候会有些困难,尤其是比训练数据集更长的文本。随着数据句子长度增加,基本的编码解码器表现会急剧下降。因此,该论文提出将编码解码模型拓展,使其能够连带地学习去对齐和翻译。每翻译一个单词,它就在源语句中查找信息最相关的位置集合。这个模型基于与这些源位置相关联的上下文向量和所有之前形成的目标单词预测目标单词。
最大的区别在于它不是尝试去把一整个输入句子编码为一个单一的固定长度的向量。而是把输入的句子编码为向量的序列,解码翻译的时候选择这些向量的一个子集。这也就解放了NMT,不需要再把源语句所有的信息,不管有多长,压缩成一个固定长度的向量。这个模型对长句子表现要更好。不过任何长度上它的优势都很明显。在英法翻译的任务中,这个方法可以媲美基于短语的系统。而且分析显示这个模型在源语句和对应的目标语句之间的对齐效果更好。
背景:神经机器翻译
从概率的角度上来说,机器翻译的任务等同于找到一个目标序列,使得在给定源语句
的情况下生成
的概率最大。即:
,在NMT任务中,我们使用平行的训练语料库(即:x,y为相同内容的2种语言)来拟合参数化的模型,让模型学习到能最大化目标语句的条件概率分布。NMT一旦学会了这种条件概率分布,那么给予一个源语句,它都能通过搜索找出条件概率最大的句子作为相应的翻译。
RNN Encoder–Decoder:
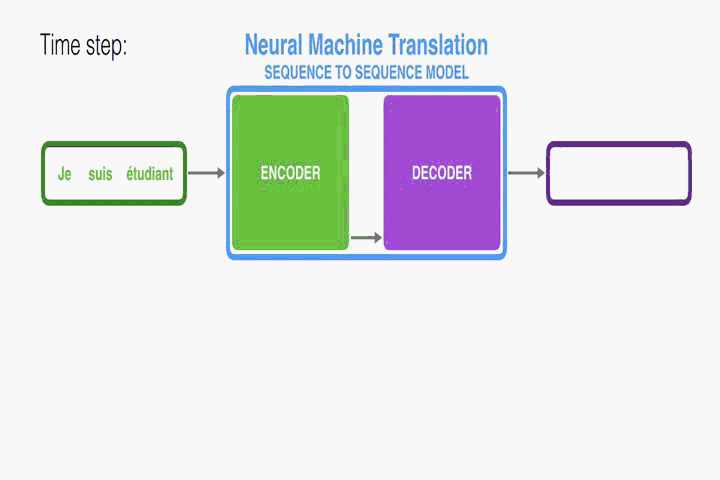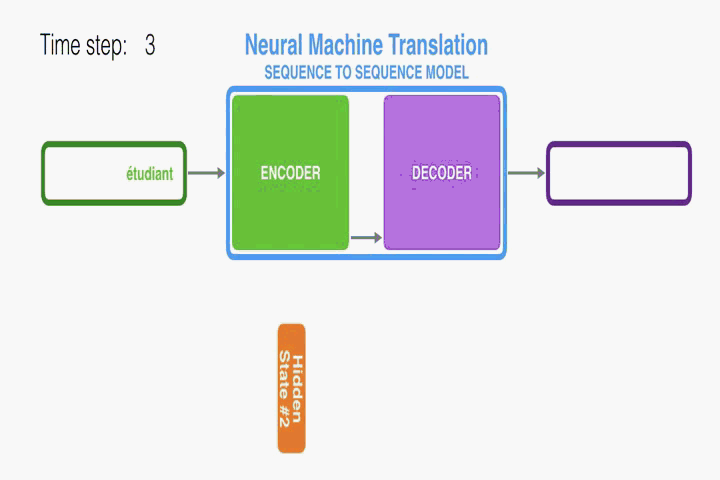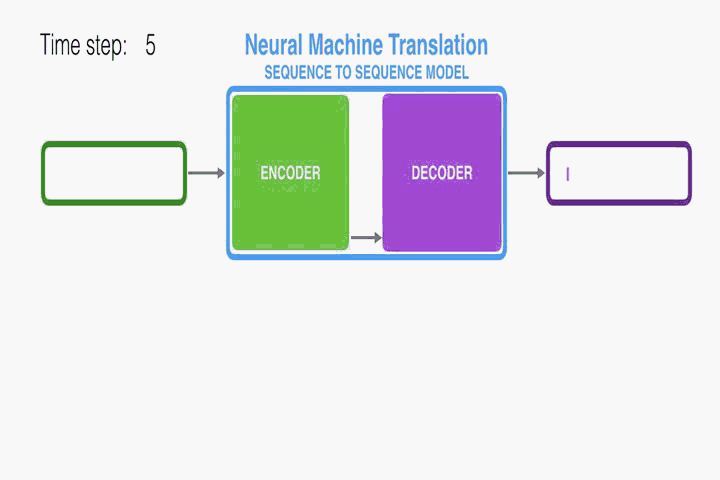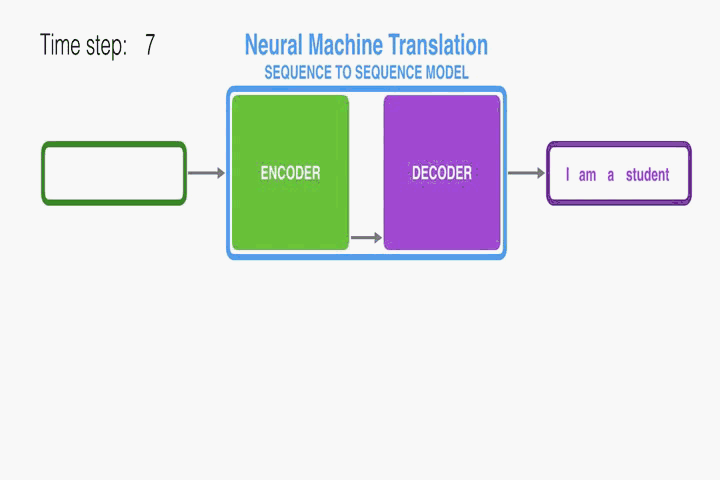
首先介绍一下本文使用的底层框架RNN Encoder–Decoder。本文是在此框架上进行修改从而提出的。Encoder读取一个向量化的输入序列,转化成向量
。最常见的方法是使用RNN:
其中是时间
时刻下的hidden state,
是由hidden state组成的序列生成的向量。
和
是2个非线性的函数。例如:你可以使用LSTM作为函数
来得到hidden state,同时你可以使用
来作为
的函数。
Decoder一般情况下是通过训练给定上下文向量和所有之前已经预测过的单词
来预测下一个单词
,换句话说,Decoder通过将联合概率分解成有序条件来定义翻译为序列
的概率:
(1)
其中,通过RNN,每个条件概率被建模为:
其中是一个非线性的(可能是多层的)函数,它的输出指的是输出结果为
的概率。
是RNN的hidden state。
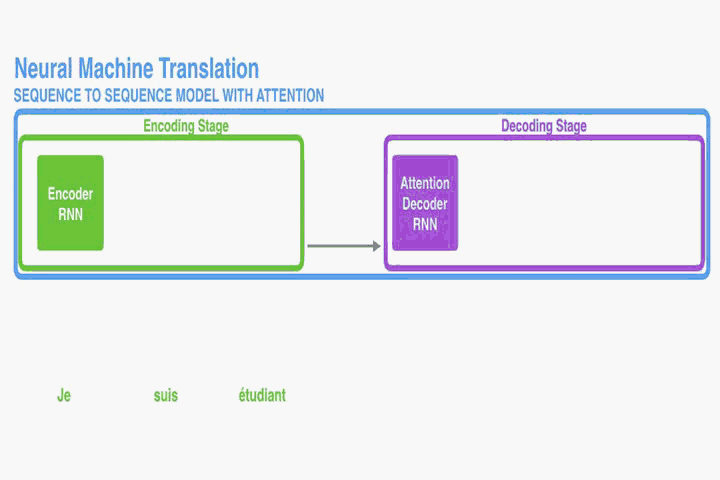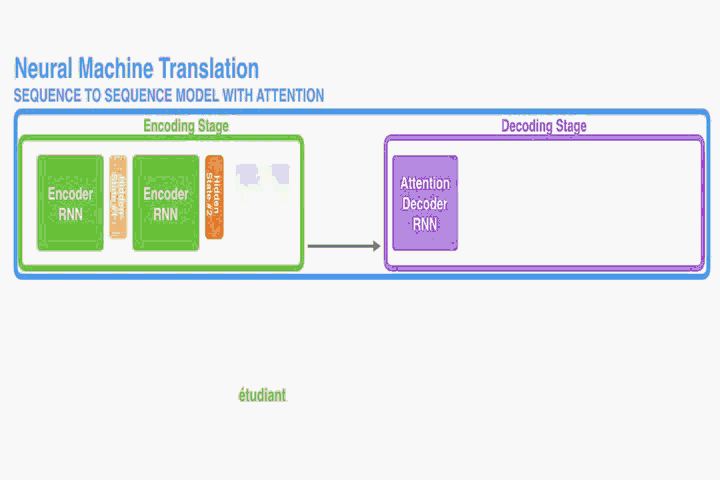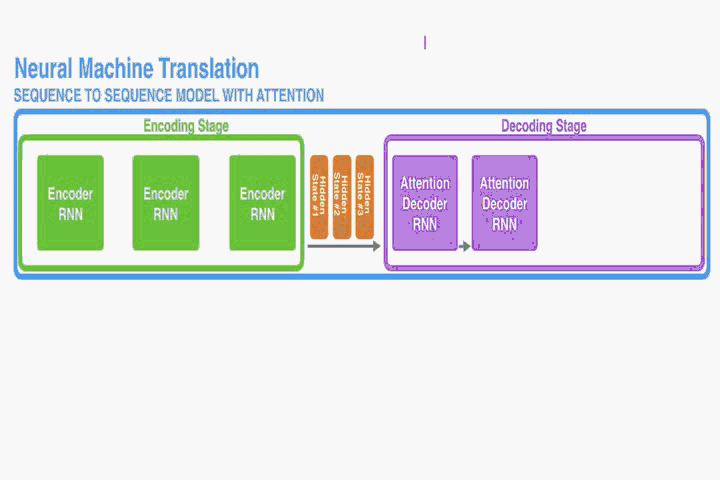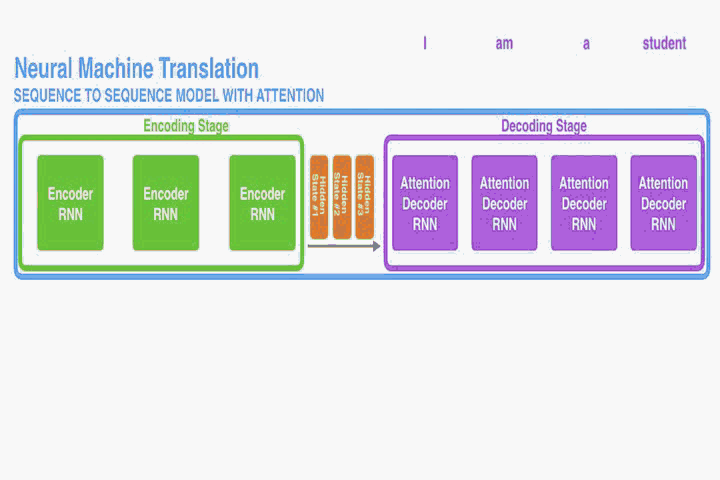
对齐翻译结构
这部分提出一个NMT的新结构。这个新结构包括一个双向RNN作为Encoder,一个模拟翻译过程中通过源语句进行搜索的Decoder。
Decoder:
在这个新的结构中,我们对公式(1)中的条件概率分布做了新的定义:
其中,是时间
时RNN的hidden state,由公式:
需要注意的是,与现有的Encoder–Decoder模式不同(如上节),这里概率是针对每个目标字的不同的上下文向量
。上下文向量
取决于Encoder将输入句子映射到的annotations(即序列
)。在annotations中,每个
包含了整个输入序列的信息,但重点关注(Attention)输入序列中第
个单词周围的部分。下一节会介绍annotations的计算方法。这一节我们先默认我们已知annotations。

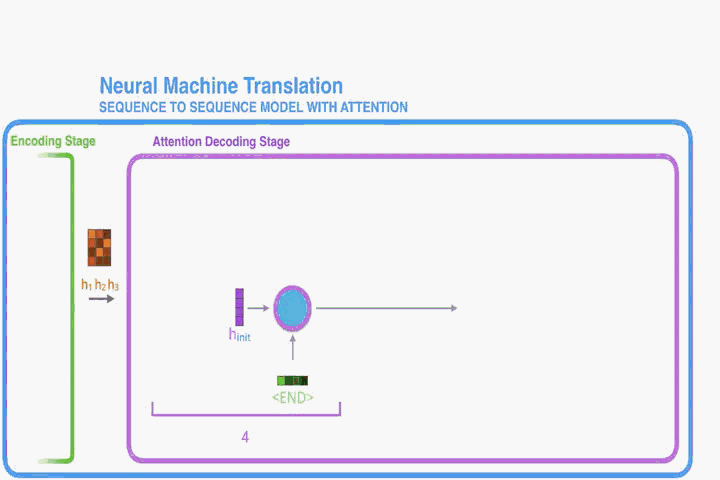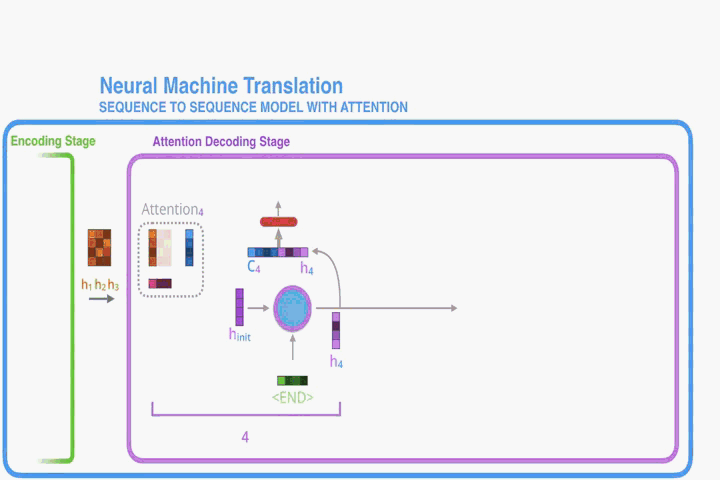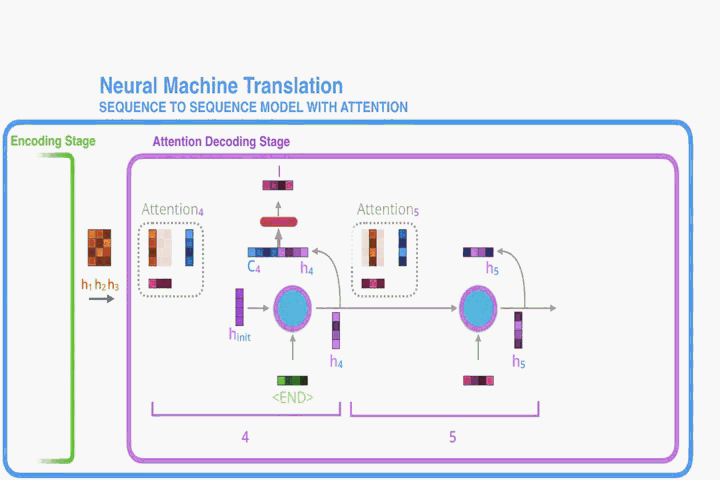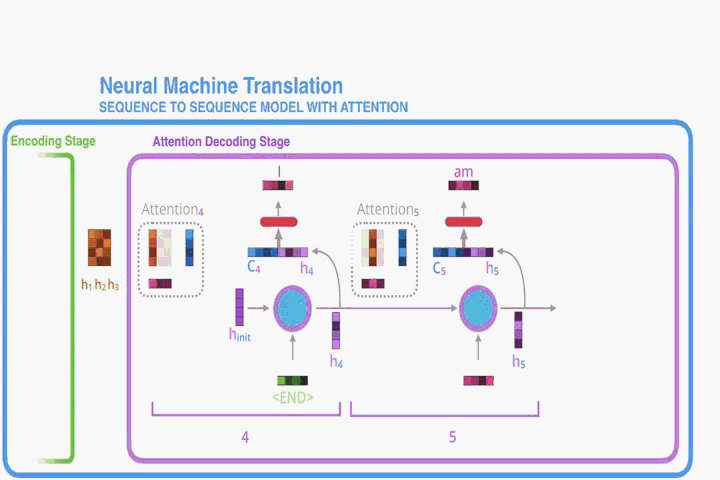
观察上图,上下文向量实则是对annotations序列
的逐个加权求和:
每个的权值
的计算:
其中
是一个对齐模型,它可以评估值位置
周围的输入和位置
的输出匹配程度。对匹配程度的打分依赖于RNN hidden state(
)和输入序列的第
个的值
。

我们将对齐函数参数化为一个前馈神经网络,让它和本文中的其它模块联合训练。需要注意的是,不同于传统的机器翻译,这里的对齐值不再被视为潜在的变量。与之相反,对齐模型定向地计算一个柔和的对齐,这就允许代价函数的梯度反向传播。这个梯度就可以随着整个翻译模型一起训练这个对齐模型。
我们可以将所有对annotations加权求和的方式看做是在计算数学期望,并且期望值是可能在对齐值之上的。设为目标单词
与源词
对齐的概率,(通俗说就是
的翻译结果为
的概率),然后,第
个上下文向量
是所有具有概率的
的数学期望。
概率(或者说
)反映了在决定下一个状态
和生成
的时候,考虑到之前的hidden state (
)的 annotation
的重要性。直观地说,这实现了Decoder中的Attention机制。 Decoder决定了源语句的哪些部分需要注意。 通过让Decoder具有注意力机制,我们可以免除Encoder将源句子中的所有信息编码成固定长度矢量的负担。 有了这个方法,信息就可以在annotations序列中传播,也可以被Decoder选择性地恢复。
Encoder: Bidirectional RNN for Annotating Sequences
一般的RNN模型,是按顺序由开始位置到结束位置
读取的。然而在本文提出的结构中我们希望每个单词的annotations不仅能总结前面的单词,而且能总结后面紧跟着的单词。因此,在此处我们将使用双向RNN(Bi-RNN)。
如图一,Bi-RNN包含了前向hidden states和反向hidden states,其读取序列的方式是正好相反的,举个例子对于一句话“我爱祖国”,前向做的读入顺序为(我,爱,祖,国)和反向读入顺序为(国,祖,爱,我)。
我们通过连接前向隐藏状态和后向隐藏状态来获得每个单词的annotations,可以表示为:
![]() ,通过这个方式,annotations
,通过这个方式,annotations 将集中在
的周围单词上。Decoder和对齐模块稍后会使用该序列来计算上下文向量
。
结构介绍:
RNN
当前状态:
更新状态:
更新门:
重置门:
对齐模型

![[机器翻译]——pivot-based zero-shot translation based on fairseq](https://img-blog.csdnimg.cn/65c2410e90f74c1dbb52b7fa15be808c.png)





![[小小项目]背单词的程序---1.0_纯C语言_单文件版本](https://img-blog.csdnimg.cn/393dc52352b2464d9b1a7089379a407d.png)