本文使用的语言为Python, 用到的几个模块有:BeautifulSoup(爬数据),pandas(数据处理),seaborn(可视化),部分图表由Tableau生成。
1. 数据获取
计划要抓取的字段包括:片名,导演,年份,国别,评分,评价数量,看过数量,想看数量,短评数量,长评数量。
需要抓取的影片信息有250条,每页25部影片,一共有10页。简单浏览网页不难发现,翻页的链接不需要从页面底端抓取,直接修改url参数即可。

例如,第二页的url只需要在base url后面加上?start={start}&filter=即可。因此,第一步的任务就是抓取榜单上的每一部电影的详细信息链接即可。同时,影片的排名信息也可以通过简单计数得到,不需要从页面中抓取。具体代码如下。
import requests
from bs4 import BeautifulSoup
from time import sleep
from csv import DictWriter
base_url = r'https://movie.douban.com/top250'
records = []
for start in [x*25 for x in range(10)]:#Every single pageurl = base_url+f'?start={start}&filter='response = requests.get(url).textsoup = BeautifulSoup(response,'html.parser')movies = soup.find(class_='grid_view').find_all('li')rank=1+startfor movie in movies:#Every single movie on the pagemovie_link = movie.find(class_='info').find(class_='hd').find('a')['href']movie_dict = {'rank':rank, 'link':movie_link}records.append(movie_dict)rank += 1
这样我们就得到了一个list, list中有250个dictionary,每个dictionary中有影片在榜单中的排名和影片详细信息页面链接。
下一步就是进一步从已经得到的链接中抓取影片的详细信息。具体代码如下,仔细分析html标签做简单的测试即可。注意,爬取数据的过程中要加上sleep(5),礼貌爬取,防止IP被封。
#Use the scapped link to further scrape movie details
for record in records:rank = record.get('rank')print(f'Scarpping rank {rank} of 250')link = record.get('link')response = requests.get(link).textsoup = BeautifulSoup(response,'html.parser')record['title'] = soup.find('h1').find('span').get_text()record['year'] = soup.find('h1').find(class_='year').get_text()[1:5]record['director'] = soup.find(id='info').find(class_='attrs').find('a').get_text()record['length'] = soup.find(id='info').find(property='v:runtime').get_text()[:-2]attrs = soup.find(id='info').find_all(class_='pl')for attr in attrs:if attr.get_text().startswith('制片国家'):record['country_region']=attr.nextSibling.strip()elif attr.get_text().startswith('语言'):record['language']=attr.nextSibling.strip()record['avg_rating'] = soup.find(class_='ll rating_num').get_text()record['num_of_ratings'] = soup.find(class_='rating_people').find('span').get_text()interests = soup.find(class_='subject-others-interests-ft').find_all('a')record['people_watched'] = interests[0].get_text()[:-3]record['people_wants_to_watch'] = interests[1].get_text()[:-3]record['num_comment'] = soup.find(id='comments-section').find('h2').find('a').get_text().split()[1]record['num_reviews'] = soup.find(class_='reviews mod movie-content').find('h2').find('a').get_text().split()[1]#Set scrapping interval in case of ip blockingsleep(5)
下一步是将爬取的数据存入csv文件,代码如下:
注意,写入文件时中文可能会乱码,需要加上encoding=‘utf-8-sig’,加上newline=’'解决每行记录之间存在空行的问题。
#Write the 250 movies into a csv file
with open('douban_top_250.csv','w', newline='', encoding='utf-8-sig') as file:headers = [key for key in records[0].keys()]csv_writer = DictWriter(file, fieldnames=headers)csv_writer.writeheader()for record in records:csv_writer.writerow(record)
2. 数据清洗
由于抓取的数据只有250条,可以直接用excel打开,简单看一下数据有没有问题。

部分片名中可能有夹杂英文名称(中间有空格),部分片长末尾有多余字符,部分记录含有多个国家/地区或者多个语言(中间有空格)。
因为中间存在空格,片名、国家/地区、语言可以通过split()[0]取出第一个词。
片长多余字符的问题可以通过regular expression,用""替换非数字字符。代码如下,注意读取数据的时候需要加上encoding=‘utf-8-sig’:
import numpy as np
import pandas as pd
import re
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as statspath = r'C:\Users\yingk\Desktop\Douban_Top250\douban_top_250.csv'
data = pd.read_csv(path,encoding='utf-8-sig')#Preprocessing
#extract Chinese title
data['Chinese_title'] = data['title'].apply(lambda title:title.split()[0])
data.drop(['title'],axis=1,inplace=True)#re.sub() - Use "" to repleace characters which are not digit
data['movie_length'] = data['length'].apply(lambda length:re.sub("\D","",length))
data.drop(['length'], axis=1, inplace=True)#extract main country_region when there are multiple
data['main_country_region'] = data['country_region'].apply(lambda cr:cr.split()[0])
data.drop(['country_region'],axis=1,inplace=True)#extract main language
data['main_language'] = data['language'].apply(lambda lan:lan.split()[0])
data.drop(['language'],axis=1,inplace=True)data.to_csv(r'C:\Users\yingk\Desktop\Douban_Top250\cleaned_data.csv',encoding='utf-8-sig')
3. 探索分析
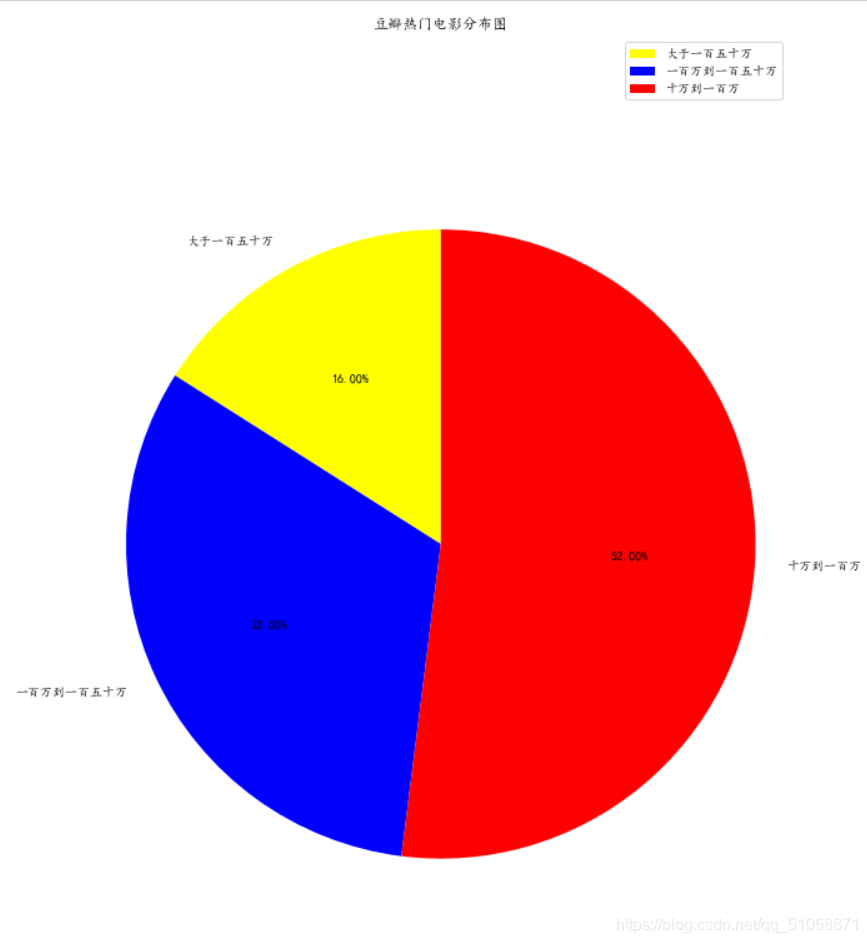
将清洗好的csv文件导入Tableau,下面是豆瓣电影TOP250上的制片国家/地区分布和各个语言所占的比重。比重越大,字体越大。类似的图表也可以用Python wordcloud来做。

榜单上的美国影片占了相当大的比重,其次是日本,然后才是中国大陆、中国香港和英国。

从制片国家/地区上不难推断,榜单上英语将会占很大的比重,其次是日语,然后是普通话和粤语。
下面是榜单上影片的年代分布,在Tableau中可以创建组来实现对上映时间的划分。

1990年之后上映的电影几乎占据了整个榜单的85%,这应该和电影技术的发展有关系。更早期的电影在数量、画面、主题、拍摄手法等方面上可能比较难征服现在的观众。
“豆瓣用户每天都在对“看过”的电影进行“很差”到“力荐”的评价,豆瓣根据每部影片看过的人数以及该影片所得的评价等综合数据,通过算法分析产生豆瓣电影 Top 250。”
以上摘自豆瓣。
下面简单分析一下哪些特征会榜单排名产生比较大的影响。
首先需要拿掉诸如链接,片名,导演等非量化字段。
metrics = data.drop(['link','director','Chinese_title','main_country_region','main_language'],axis=1)
增加/转化一些字段:
相较于平均评分,评价人数,可能增加一个总评分=avg_rating*num_of_ratings会更直接体现影片的质量。
上映年份可以转换成已经上映了多少年,即2019-year,在时间显得更直观。
metrics.eval('total_rating_scores = avg_rating*num_of_ratings', inplace=True)
metrics['years to 2019'] = metrics['year'].apply(lambda y:2019-y)
metrics.drop(['year'],axis=1,inplace=True)
生成相关系数和heatmap。
corr = metrics.corr()
plt.figure(figsize=(6,5), dpi=100)
sns.heatmap(corr,cmap='coolwarm',linewidths=0.5)

观察heatmap的第一行不难发现,rank和多个字段存在较高的相关性。下面看一下具体的相关系数:
corr.head(1)
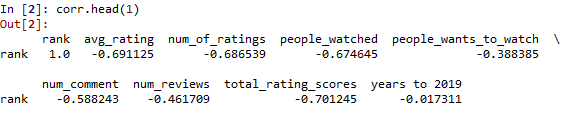
新建的字段total_rating_scores相关系数最高,进一步做显著性检验:
#total_rating_scores t-test
x = list(metrics['rank'])
y = list(metrics['total_rating_scores'])
r,p = stats.pearsonr(x,y)
print(r)
print(p)
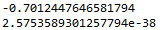
相关系数为-0.7,显著性水平小于0.001,说明豆瓣电影TOP250榜单的排名与影片得到总评分存在较强的相关性。总评分越高,排名越靠前。
类似的字段还有平均评分、评分人数、观看人数,而想看人数、短评数、长评数相关性相对较弱,与上映时间几乎没有相关性。
因此,想要影片挤进这份榜单,需要影片能够得到足够多的评分和较好的评价。
由于样本数量只有250个,加上豆瓣内部可能还有其他隐藏的特征,现有的数据可能很难构建出比较满意的模型。可以尝试爬取更多的数据并增加其他特征然后再来构建榜单排名的预测模型。
豆瓣上每部影片都有很多短评/长评,观察heatmap的第6、7行可以发现,平均评分与影片短评/长评的相关性较弱。这与我们平常看到的烂片常常反而能够引来热烈讨论的现象相一致。同样与影评数量相关性较弱的还有标记为想看的数量和影片上映的时间。
可以通过boxplot来进一步了解。代码如下:
comment_reviews = metrics.loc[:,['num_comment','num_reviews']]
def bin_years(value):for i in range(10,91,10):if value<i:return f'{i-9}-{i}'
comment_reviews['years_bin'] = metrics['years to 2019'].apply(bin_years)
bins = [f'{i-9}-{i}' for i in range(10,91,10)]
plt.figure(figsize=(12,5), dpi=100)
sns.boxplot(x='years_bin', y='num_comment', data=comment_reviews, order=bins)
plt.figure(figsize=(12,5), dpi=100)
sns.boxplot(x='years_bin', y='num_reviews', data=comment_reviews, order=bins)


豆瓣电影TOP250榜单上,除了最近10年的影片获得的影评相比较高以外,其他上映时间的电影得到的影评数量大体保持在同一水平。这也与这两组特征之间较低的相关系数相吻合。
数据来源: 豆瓣Top250榜单:https://movie.douban.com/top250
完整代码: https://github.com/Yinstinctive/douban_top_250