分类目录:《知识图谱从入门到应用》总目录
相关文章:
· 知识图谱的基础知识
· 知识图谱的发展
· 知识图谱的应用
· 知识图谱的技术结构
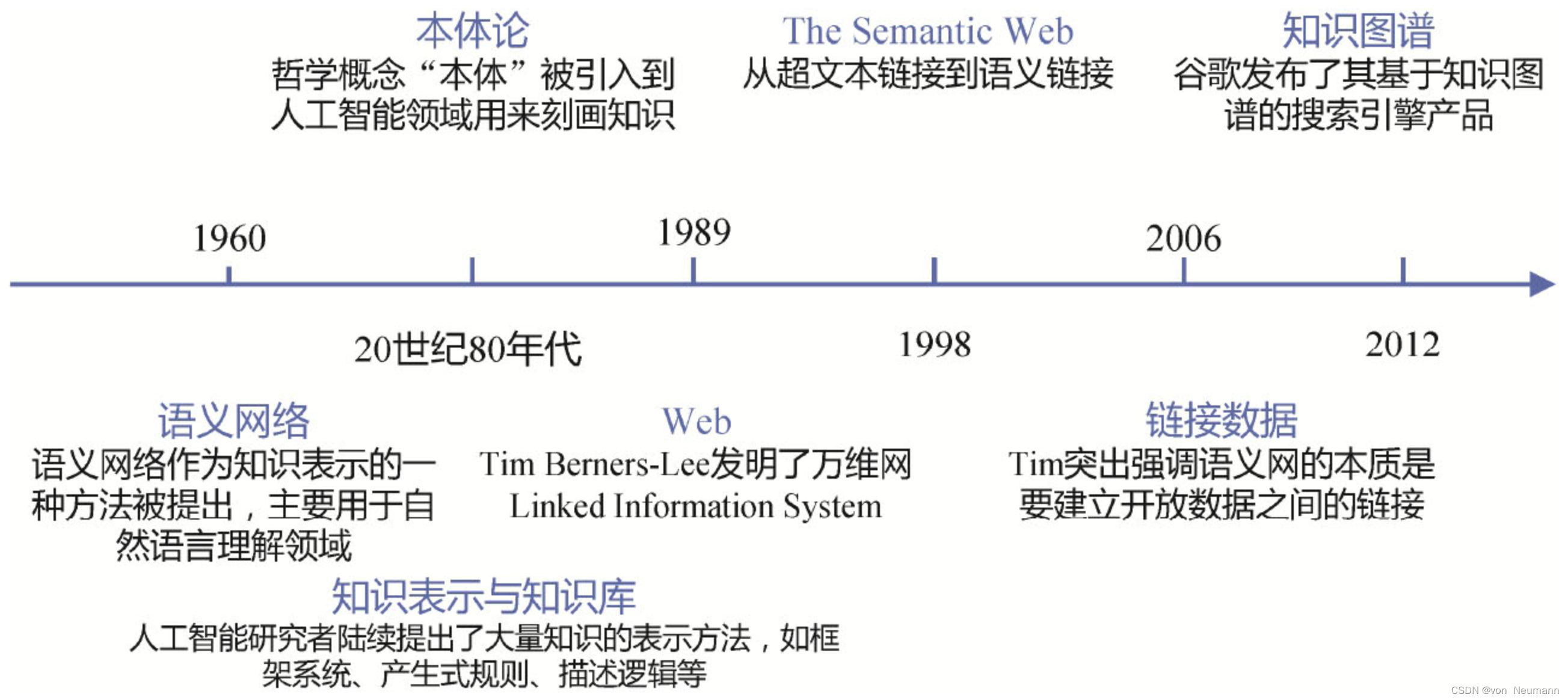
1945年,美国首任总统科学顾问Vannevar Bush曾提出了一个称为MEMEX的“记忆机器”的设想。他认为人的记忆偏重关联,而非像图书馆那样采用严格的层次分类目录组织大脑中的信息。因此,他提出设计一种Mesh关联网络来存储电子化的百科全书。MEMEX记忆机器的设想启发了超文本技术Hypertext的实现,而超文本技术则直接促成了互联网的最大应用——World Wide Web的发明。Web是由英国人Tim Berners-Lee提出的,他因为Web技术的贡献获得了2016年的图灵奖。1989年,Tim作为欧洲高能物理研究中心的计算机工程师,提出了一种基于超文本技术的信息管理系统建议书。如图1-8所示,在建议书中,就可以看到知识图谱的影子。
起初,他只是希望为高能物理研究中心的科学家设计一种新型的科技文献管理系统。他利用超文本链接技术实现科技文献之间的相互关联,并实现了世界上第一个能处理这种超文本链接的Web服务器和浏览器。他认为,信息应该以图的方式组织,图中的节点可以是任何事物,节点之间的链接代表事物之间的关联,这样将大幅提升信息检索的效率和能力。这种以图和链接为中心的系统,在开放的互联网环境里面更容易生长和扩展。这一理念逐步被人们实现,并演化发展成为今天的World Wide Web。
Semantic Web
1994年,Web已经在全世界范围内快速发展起来,成为互联网上的最大应用。但Tim指出,这种以文本链接为主的Web并非他设想中的终极Web的样子。他认为终极的Web应该是Web of Everythings。例如,一位教授的个人主页实际上描述的是他的各种属性信息,如果他的主页上有一个超链接指向浙江大学的官方主页,这个超链接实际上指的是这名教授和浙江大学是雇佣关系,但这个超链接没有这方面的语义描述,搜索引擎也无法识别和处理这种语义关系。因此,他于1998年正式提出了Semantic Web(语义网)的概念。与经典Web一样,Semantic Web也是以图和链接为中心的信息管理系统,但不同之处是,图中的节点可以是粒度更细的事物,如一本书、个人、机构和概念等,图中的链接也标明这些事物之间的语义关系,如雇佣、朋友和作者等。这就是知识图谱的早期理念。
在Semantic Web提出以后的10余年里,催生了众多的语义网数据项目,比较著名的如谷歌知识图谱的核心数据来源Freebase,欧洲的LinkingOpenData,维基基金会倡导的WikiData等。由国内科研机构和企业共同发起的OpenKG收录了很多中文领域的语义网开放数据集。
谷歌公司于2010年收购了开发Freebase的Meta Web公司,并于2012年发布了首个基于知识图谱实现的搜索引擎。谷歌知识图谱本质上是Semantic Web理念的商业化实现。对于搜索引擎,知识图谱解决了一个难题,即精确的对象级搜索问题。传统搜索引擎只能返回很多相关页面,用户需要从海量文本中自行寻找答案,即所谓字符串级别的搜索。但用户希望直接搜索最终的答案,例如用户问:“浙江大学位于哪个城市”,希望得到对事物的精准描述——杭州市,而非返回很多页面,让用户自己从众多页面中寻找正确答案,即所谓事物对象级别的搜索。谷歌通过构建庞大的知识图谱,以结构化而非纯文本的方式描述事物的属性以及事物之间的关联关系,就可以实现这种对象级的精准搜索。当然,知识图谱的价值不止搜索。
典型的知识图谱项目
接下来简要介绍历史上出现过的典型知识图谱项目。Freebase是早期的语义网项目,主要通过开放社区协作方式构建,在经过近8年的开发和数据积累后,其母公司MetaWeb于2010年被谷歌收购。谷歌随后在Freebase基础之上发布了其面向搜索的知识图谱。Wikidata在一定程度上可以看作Freebase的后续发展,它由维基基金会支持,同样也是依靠开放社区众包构建。它的目标是要成为世界上最大的免费知识库,并采用了CC0完全自由的开放许可协议。Schema.org是谷歌等搜索引擎公司共同推动的Web数据Schema标准。Schema.org本质上是一种轻量级的本体,定义了有关人物、机构和地点等最常用的1000多个类和关系。任何人都可以利用这个Schema描述自己的数据,并以RDFa、Mcirodata等格式插入网页或邮件中。这使得每个人或机构都可以定制自己的知识图谱信息,并被搜索引擎快速地抓取和更新到后台数据库中。
DBPedia也是早期的语义网项目。DBPedia意指数据库版本的Wikipedia,是从Wikipedia抽取出来的链接数据集。DBPedia采用了一个较为严格的本体,包含人、地点、音乐、电影、组织机构、物种和疾病等类定义。YAGO是由德国马普研究所研制的链接数据库。YAGO主要集成了Wikipedia、WordNet和GeoNames三个来源的数据。其主要特点是考虑了时间和空间维度的知识表示。YAGO是IBM Watson的后端知识库之一。WordNet是最著名的词典知识库,主要用于词义消歧等自然语言处理任务。由普林斯顿大学认知科学实验室从1985年开始开发,与谷歌知识图谱以实体关系为主不同,它主要定义词与词之间的语义关系。ConceptNet源于MIT的Open Mind Common Sense项目,由著名的人工智能专家Marvin Minsky于1999年建议创立。与谷歌知识图谱相比,ConceptNet侧重于词与词之间的关系,更加接近于WordNet,但比WordNet包含的关系类型更多。
BabelNet是多语言词典知识库,它集成了WordNet在词语关系上的优势和Wikipedia在多语言方面的优势。通过机器翻译技术,自动化地构建了目前最大规模的多语言词典知识库,目前包含了271种语言和1400万个同义词组。前面介绍的主要是英文领域的部分较为典型的知识图谱项目。在中文领域,中国中文信息学会语言与知识计算专业委员会于2015年启动了OpenKG中文开放知识图谱项目的建设,系统地收集和整理了中文领域的众多开放知识图谱,读者可以访问OpenKG官网了解。
知识图谱的演进
知识图谱并非突然出现的全新技术,而是很多相关领域不断发展融合的结果。一方面,知识图谱具有人工智能的基因,这可以追溯到1960年,人工智能领域学者提出的知识表示方法——语义网络的本质就是一种知识图谱的表示方式,如下图所示。人工智能发展历史上提出的一些典型的知识表示方法,如框架系统、产生式规则、本体论和描述逻辑等。另外一方面,知识图谱也具有很鲜明的互联网基因。互联网的发展特别是万维网的发展促进了人类知识的共享和开放领域数据如Wikipedia的众包积累,没有万维网数十年积累的开放数据,也不会有谷歌的知识图谱。此外,利用图结构的方式描述万物关系和记录事物知识的理念也来源于万维网。因此,需要从多个不同的技术视角全面地掌握知识图谱的本质内涵。
参考文献:
[1] 陈华钧.知识图谱导论[M].电子工业出版社