淘宝APP用户行为数据分析案例
一.分析背景与目的
1.1背景与数据限制
电商平台的最核心的功能就是为买卖双方提供高效和体验良好的交易服务。得益于算法技术的发展,淘宝APP给买方提供了搜索、推荐及广告等系统和功能,使用户能高效地触达感兴趣或有购买意愿的商品。上述系统和功能来源于海量的用户行为数据,而此后的数据变化又反馈到系统中,不断提升系统和功能的能效。此外,对于其他的如优惠活动,购物节,APP改版等运营行为,也能通过用户行为数据表现来衡量优劣。
本案例使用的数据集有相当的限制:时间维度限制在9天内,商品数据经脱敏,行为数据只有4种。以下分析内容都在此数据集的限制范围内开展。
1.2核心业务描述
1.2.1核心功能
淘宝作为商品交易平台,对于用户群体,核心功能为用户高效、优质的购物体验,并且尽可能让用户被动接触到有潜在购物意愿的商品。
1.2.2用户侧核心指标
根据淘宝APP的核心业务,用户侧的核心指标要能有效反映用户的量、粘性、使用频率和购买转化。
1)流量类:
访问数:pv,当日淘宝APP的页面访问数
用户数:uv,当日在淘宝AAP产生数据的去重用户数
活跃用户数:active_user,当日在淘宝APP上产生超过3次行为数据的用户数
交易用户数:buy_user,当日在淘宝APP上产生购买行为数据的去重用户数
2)比例与均值:
活跃用户比例:日活跃用户/日uv
交易用户比例:日交易用户数/日uv
用户pv日均值:日pv/日uv
9天内用户访问天数:统计9天内,用户有多少天活跃
1.3 分析用户行为的目的
1.3.1用户行为的定义
用户在使用淘宝APP时发生的行为动作,包括以上数据集的四类,以及取消收藏/清空购物车/搜索/关注店铺等情况,由于数据局限性,在此仅分析数据集中的数据行为。
1.3.2分析数据用户行为目的和意义
1)分析指标和结果可用作监控日常业务;
2)指标分析或进一步的下钻分析,挖掘业务增长点;
3)数据可用作训练集,指标和结果可用作为检验推荐系统,搜索系统及广告系统性能的指标之一。
备注:上述提到的挖掘增长点,围绕1.2.2的核心指标进行,即增加用户粘性,促进用户交易。
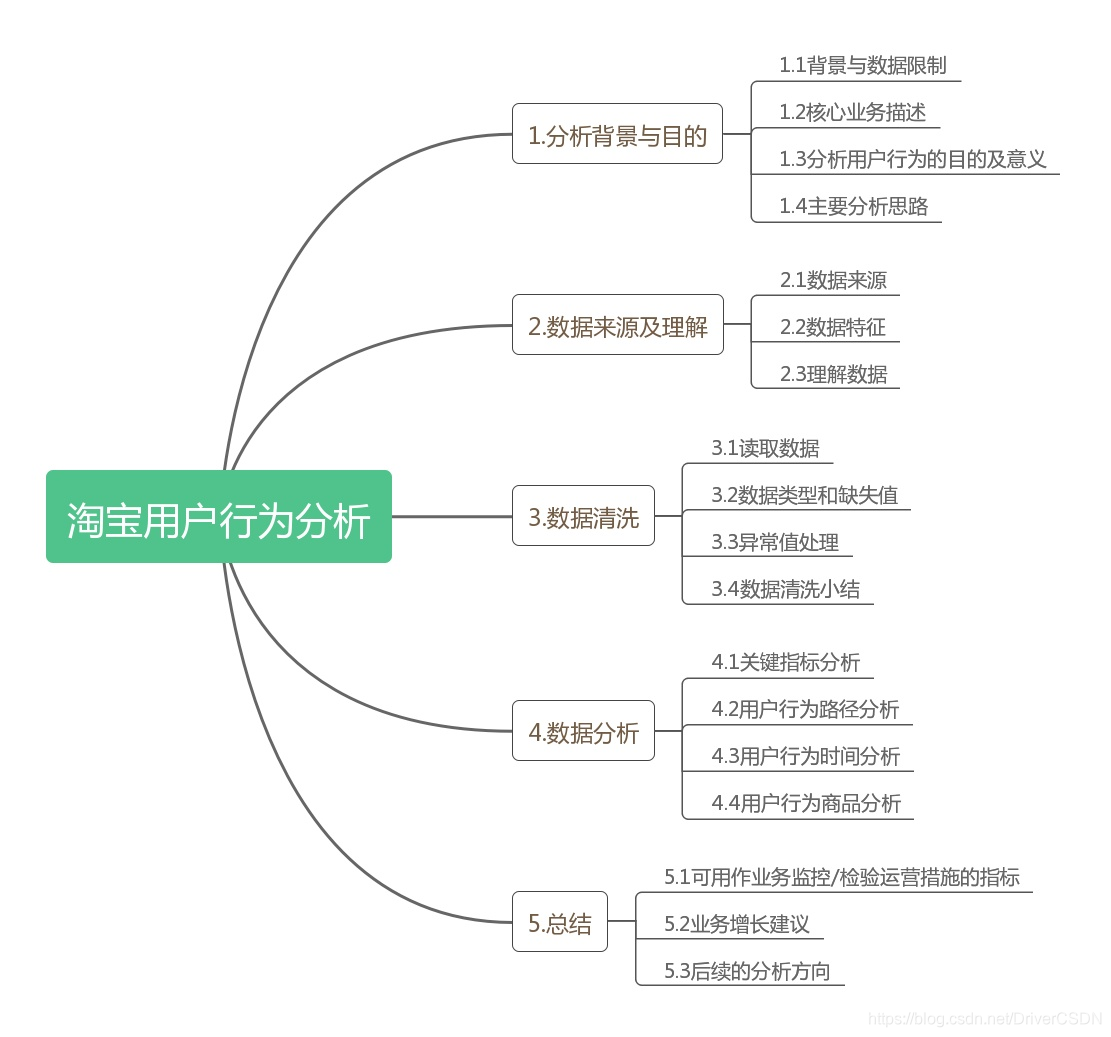
1.4主要分析思路
根据上述,,案例的分析应主要围绕三个目的和两个核心业务开展,如下图
但由于数据集的限制,提升和检验方面也受到很大限制
二.数据集来源及理解
2.1数据来源
阿里天池官方数据集:User Behavior Data from Taobao for Recommendation
2.2数据特征
2.2.1总体描述
数据时间范围:2017-11-25至2017-12-03
文件类型:csv
文件大小:0.9G
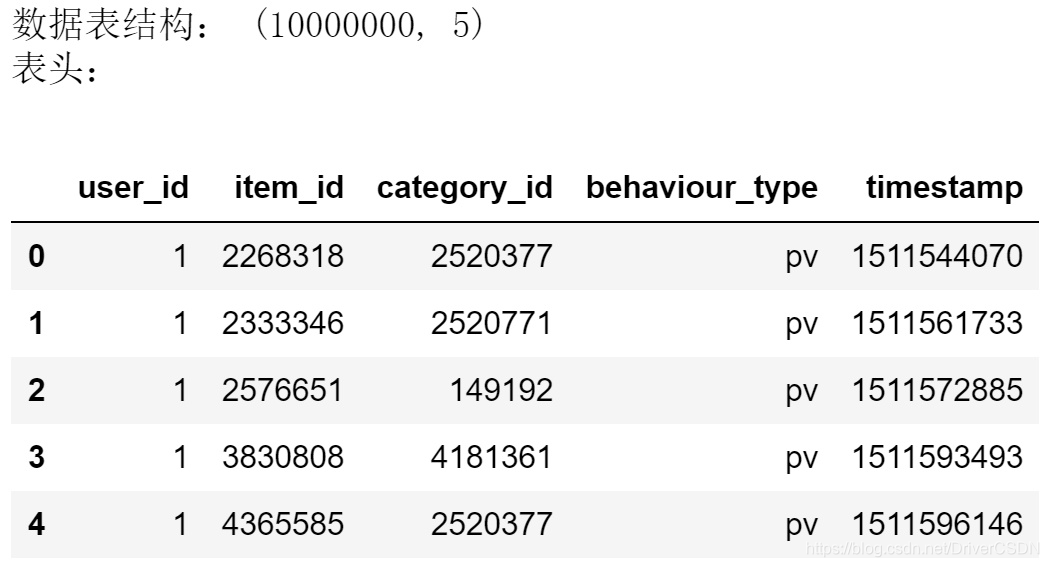
数据表shape:1亿行,5字段
2.2.1字段描述
user_id:整数类型,序列化后的用户id
item_id:整数类型,序列化后的商品ID
category_id:整数类型,序列化后的商品所属类目ID
behaviour_type:用户行为,分成四类:
1)pv:商品详情页pv,等价于点击
2)buy:商品购买
3)fav:商品收藏
4)cart:商品加入购物车
timestamp:行为发生时的时间戳
2.3理解数据
1)数据集具有较大局限性:如时间短,无地域因素、商品id经脱敏等;
2)比较有分析价值的是行为与时间这两个维度
三.数据清洗
由于笔记本电脑内存不够,将数据集分成10份后,用其中1份进行统计分析,将所有代码封装好后跑其余的数据再合并就可以了。
3.1读取数据
3.2查看数据类型和缺失值


3.3异常值处理:
1)将timestamp转化成北京时间,并筛选出11月25日至11月3日的数据,被筛掉的数据约有5.5千条,只有总体数据的0.055%
2)behaviour-type中没有异常值
3.4数据清洗小结:
淘宝官方给出的数据集很干净,只有极少部分数据时间字段有异常值。
四.数据分析
4.1关键指标分析
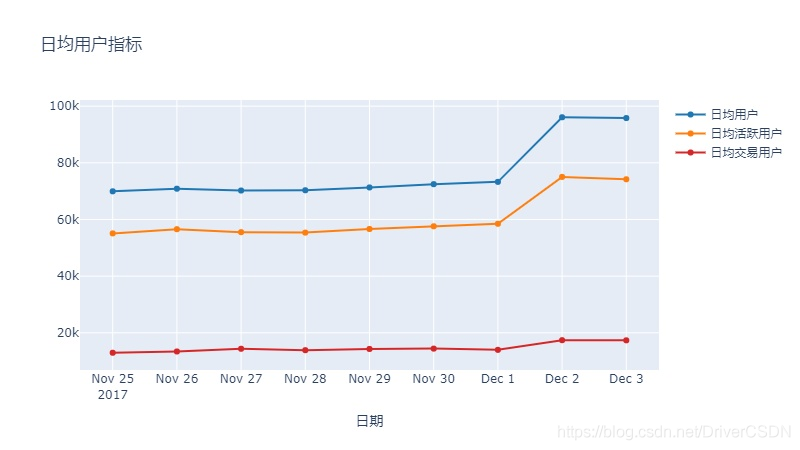
4.1.1日均用户指标
4.1.2日均用户比例指标

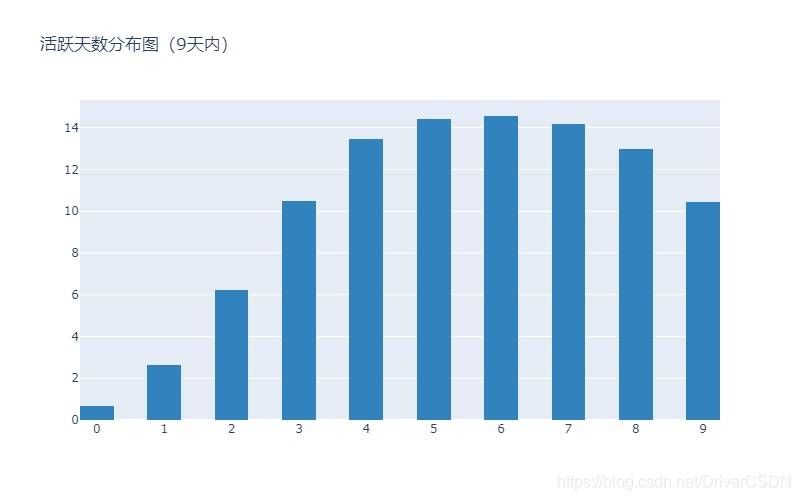
4.1.3用户活跃天数分布
4.1.4关键指标小结分析
1)APP的日均用户较为稳定,曲线从12月2日起大幅上升,较大可能的原因是双12系列活动开始,后续可单独分析这几天的各项转化率。
2)日均活跃用户比例和日均购买用户比例相对稳定在79%和19%,推测可能是方差较小的正态分布,后续可手机长时间数据范围内的数据进行验证,用于假设检验业务是否出现异常。
3)12月2至3日用户数上升了32.3%,但活跃比例和购买比例分别下降了3.2%和6.7%,(数据由后两天均值除以前7天均值得出),说明由于活动吸引而来的用户,购买比例并没有比平时的用户高,建议在引流时要更加精准。要说明这几天数据的好坏,还要等到整个活动结束后复盘分析。
4)在9天的数据范围内,超过90%的用户9天内活跃超过两天,用户粘性高,后续可用周活跃天数比例来监控用户粘性的高低。
5)上述指标均可作为平台业务监控指标,当指标数据异常时(异常好/异常坏),分析人员都应该深挖异常的产生原因,从而增长业务,或避免问题再次发生。
4.2用户行为路径分析
单纯的转化漏斗图在此场景下会过于简化,参考意义不大,数据的4个行为可组合成16个路径,可清晰地区分用户路径行为。
4.2.1用户行为路径
数据根据用户id、商品id和行为去重后赋值计算得出,因此数据会少了用户复购的情况,核实后复购9天范围内同用户同商品的复购订单数为5单,影响可忽略不计;详情见附录代码。
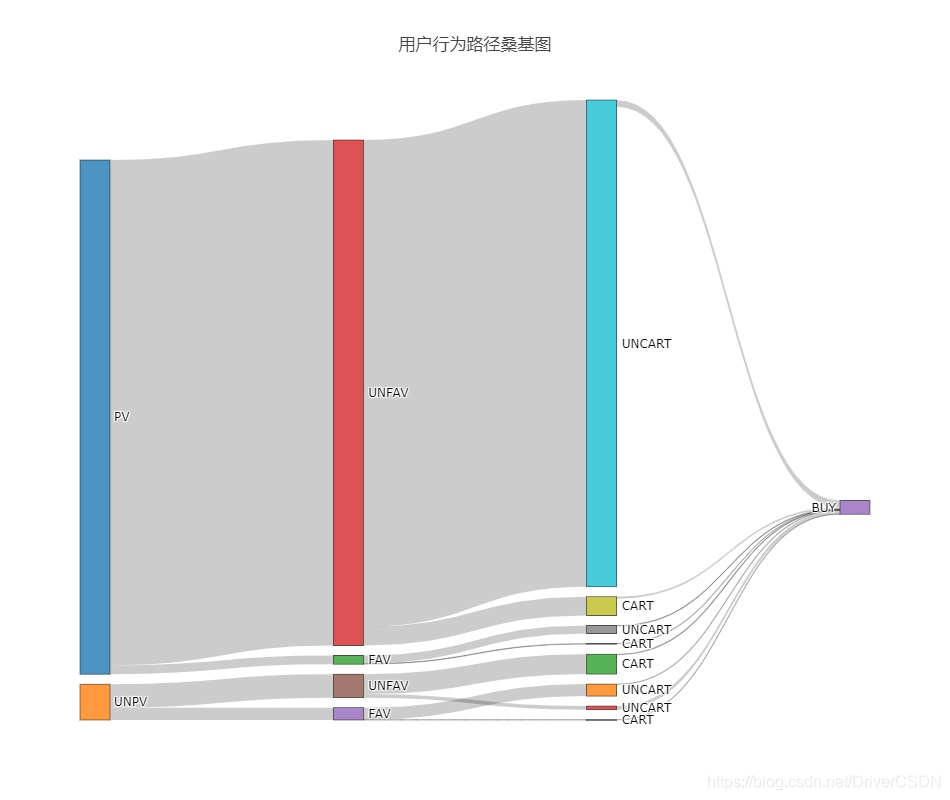
3条高占比的购买路径分析:
a:unpv_unfav_uncart_buy: 50292
此路径除了购买其他行为,应是数据集时间范围外产生的,此处不作讨论。
b:pv_unfav_uncart_buy: 数量92426,占比:69%,uncart→buy的转化率为:1.4%
购买路径中,占比最高的是访问后直接购买,无加入购物车行为,可以认为是单件购买。此路径的意义在于,得出用户购买占比最大的路径数据,后续可根据商品类型,用户标签,是否包邮等特征继续下钻分析,提高该类商品/营销策略/广告的数据表现。
c:pv_unfav_cart_buy: 数量25351,占比19%,cart→buy的转化率为:9.9%;
访问后加入购物车购买是另外一种较典型的购买路径,一般可能为多件购买或者提前加入购物车(后续数据验证)上述3条高占比路径,都是无收藏的商品,但我们不能说收藏了的商品购买转化率低,因为此处时间范围短,在4.3中将分析用户时间行为分析路径。此外,分析高占比购买路径的对立路径,如pv_unfav_uncart_buy与pv_unfav_uncart_unbuy对立,可以分析流失原因。
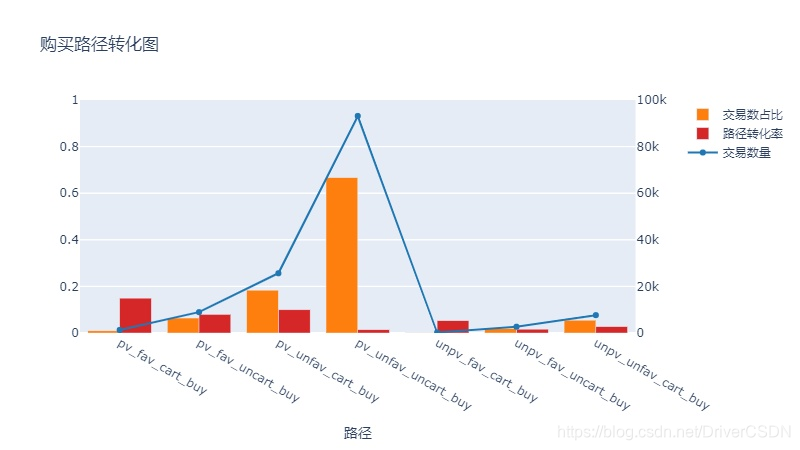
4.2.2购买转化率
4.2.3小结
1)总体转化比例:
在这9天的数据中
收藏fav行为的转化率为 3.82%
加入购物车cart行为的转化率为 7.17%
购买buy行为的转化率为2.51%
2)不同路径的交易占比和购买转化率有较大差别,它们都代表用户行为的一种特征,通过比较路径转化率,比如有访问、收藏及加入购物车的路径的总体购买意愿大于只访问和收藏的路径,针对不同路径的用户及商品开展不一样的运营策略,逻辑上是可以提高业务效能的。此处的逻辑不是说让用户收藏和加购物车的商品越多越好,而是让用户接触到更多潜在消费商品越好。
3)细致分解用户行为和路径,是开展进一步多特征分析的基础,也是开始解释数据差异的基础。基于淘宝APP的巨量数据,我们可以将数据分解到比较细的维度来分类、预测、检验算法和模型,进而实施高效的运营策略。
4.3用户行为时间分析
4.3.1用户活跃时间
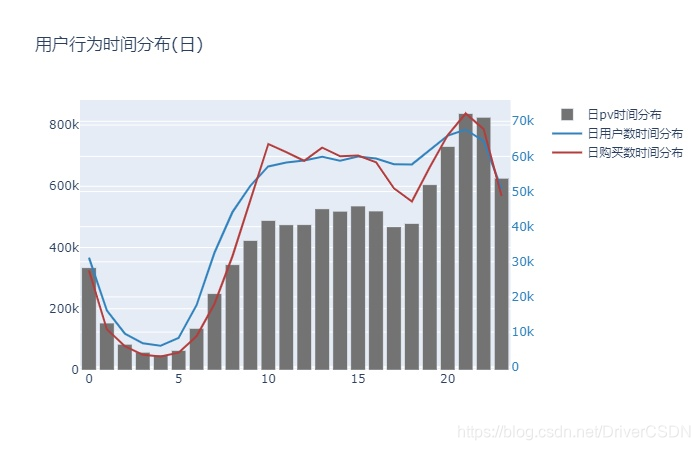
下图汇总了9天每个小时的pv,uv,和商品购买数量(乘5处理)
4.3.2购买行为时间分布

4.3.3小结
1)从pv和和用户数的时间分布上看,19:00-24:00是访问高峰期,符合人们的工作休息节律,并应在此时间段开展日常运营活动。日用户数和购买时间曲线趋势基本吻合,但17-19时购买数量减少的幅度较大,后续应分解分析其原因。
2)从购买行为时间分布图上看,收藏且有购物意愿的用户,超过95%会在3天内购买,加入购物车且有购物意愿的用户,超过92%会在5天内购买,可以在这些期限作适当的提示或活动,提高购买转化率。
4.4用户行为商品分析:
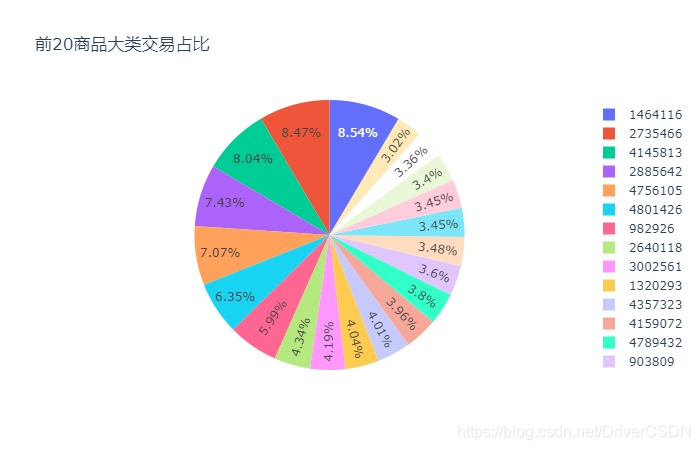
4.4.1 商品大类交易数占比
数据集中商品大类经脱敏,因此筛选出的商品大类交易数没有进一步的分析。
4.4.2商品大类购买行为
分析产生购买行为的数据中,一件商品的购买要经过多少个行为;由此可以分类商品大类的用户行为。
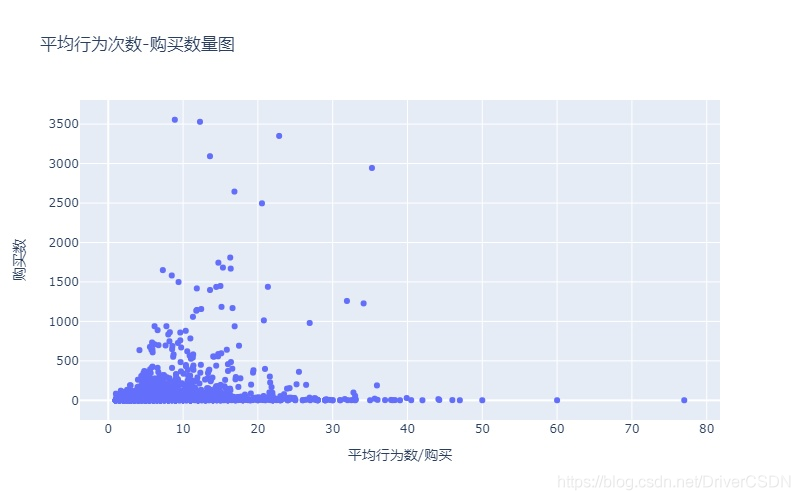
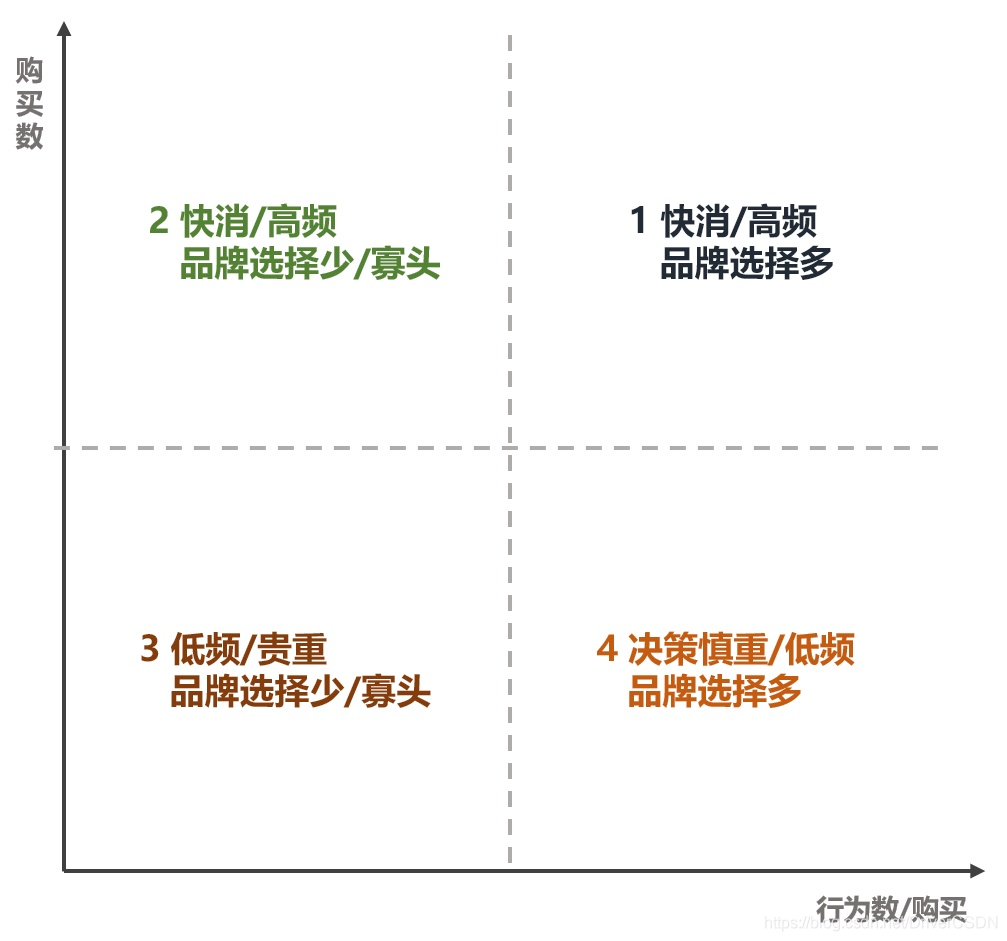
分析小结:由上图可见,大部分购买行为平均只会产生20次以的,对于划分开的不同用户行为的商品大类,实施不同的运营策略
区域1:购买数大,行为数也大,推测该区域商品是快消或高频物品,且品牌选择多,如服装、日用品、零食等,平台可根据区域1中商品大类的总体交易额、关注用户数及商品品类数等因素,为商品大类建设专区,减少用户的搜索对比,提升用户体验和沉浸度。
区域2:购买数大,行为数少,推测该区域商品是高频、网红产品,品牌不多用户选择少,或者是有头部品牌,又或者是品牌建立了一定的依赖度;此类区域的商品,用户决策相对会轻松,因此应着重快速让用户触达商品,如用户搜索酱油,则应优先展示用户购买过的品牌。
区域3:购买数相对小,行为数相对小,大部分商品大类都在这个区域,想让这些点往什么方向移动,还需具体类型具体分析。
区域4:购买数小,行为数多,推测该区域商品低频/贵重,用户决策谨慎,如电视机,由于行为数多,同样可以考虑建设专区,可对相关用户增加靠谱的推送信息,增加用户的粘性及辅助用户合理决策。
4.4.3 商品关联性分析
提取数据集中各商品大类/商品出现在同一个订单中的次数,次数越大,两种商品大类/商品的关联性越高;用户在购买/加入购物车/收藏一种商品时,可适当推荐展示关联性高的商品。
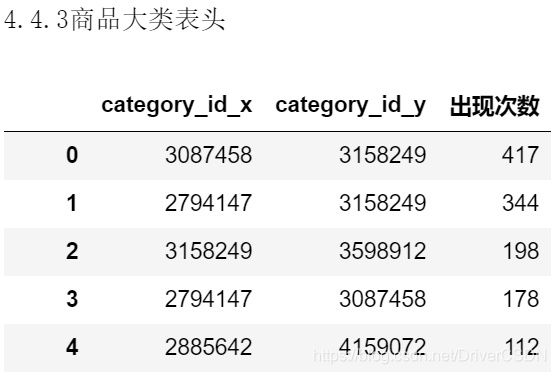

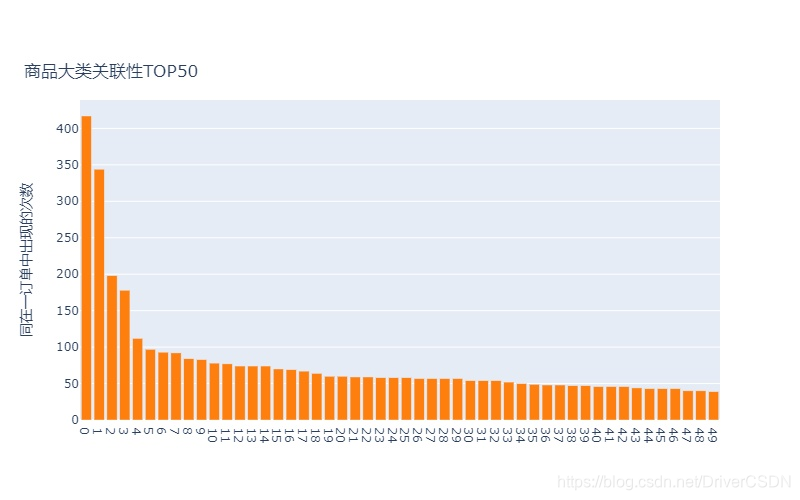
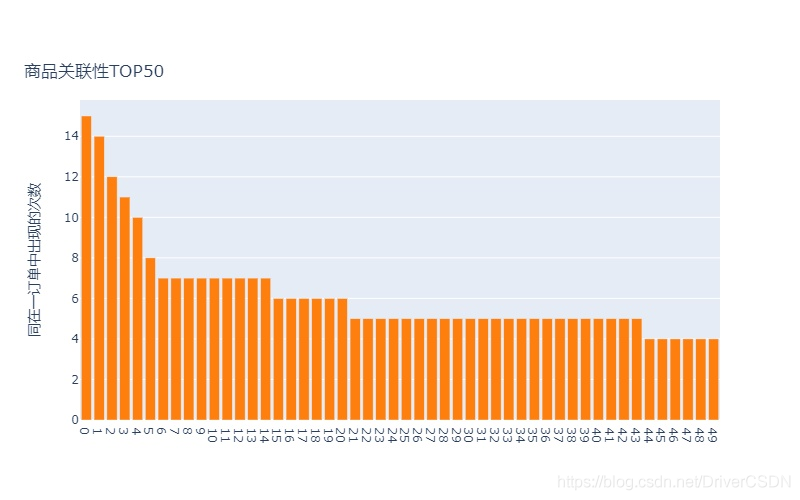
分析小结:
1)总订单数为:178673,商品种类大于1的订单数为12165,商品大类关联性TOP1只有417次,约占3.4%;商品大类的关联性强于单个商品之间的关联性,从上表头看到,关联度最高的商品大类组合是3087458-3158249,其中在TOP3中,都有商品大类3158249;
2)总体来说由购买行为计算的商品关联性不低,有一定的分类和推荐价值,按照关联性高的商品推荐,理论上可促成商品交易;后续可用同样的方法或其他复杂算法来研究pv/fav/cart等行为的商品关联性。
五.总结
5.1可用作业务监控/检验运营措施的指标
由于淘宝APP用户基数大,骤降理论上很少出现,对于这些指标,更多可以考虑如比例3天连续下降,哪怕幅度很小。
1)日均用户数、日均活跃用户数/比例、日均交易用户数/比例
2)活跃天数分布
3)各路径交易占比数/购买转化率
4)pv值/用户数/购买数时间分布
5)收藏-购买/加入购物车-购买行为时间分布
6)商品大类购买次数-购买决策行为数
7)商品大类关联性次数与订单数比例
5.2业务增长建议
5.2.1提升用户体验和粘性
1)考虑为购买量大、决策过程长、品牌繁多的商品建立专区,并适当增加科普推送,辅助用户决策,提升沉浸度。
2)对于决策过程很短的商品,应着重提升购买效率,如搜索结果有限显示/提示曾经买过的商品品牌或店铺、在购买过的订单中设置和突出搜索功能
5.2.2促进用户交易
1)基于用户购物行为,可以在收藏/加入购物车-购买完成90%的时间点上实施一定的优惠信息/提醒等运营措施,促进用户交易。
2)双12活动带来的用户增长,并没有维持到日常水平的购买转化率,建议调整或ABTEST用户需求/定向模型,提升购买转化率
3)对于关联性高的商品,优先向相关用户展示。
5.3后续的分析方向
由于数据集的局限性,案例分析更多在于发现用户、规律以及建立指标。后续的分析方向应把数据分解得更深入,考虑更多维度,长追踪时间,如:
1)利用上述指标监控业务,追踪运营措施效果,挖掘数据异常的原因;
2)多维度的排列组合分析,如不同购买路径的人群的购买决策特征,多维度构建人物画像等;
3)建立数据指标BI体系,高效地供内部各人员参考。
附录:代码及注释(计算部分)import pandas as pd
import numpy as np
import datetime
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import plotly.offline as py#三.数据清洗
#数据清洗-读取数据
row_data = pd.read_csv(r'D:\kaggle资料\天池-淘宝用户行为数据\UserBehavior.csv',names=['user_id','item_id','category_id','behaviour_type','timestamp'],iterator=True)
data1=row_data.get_chunk(10000000)#数据清洗-数据描述
print('UV:',data1['user_id'].nunique())
print('商品SKU:',data1['item_id'].nunique())
print('商品大类:',data1['category_id'].nunique())
print('---------')
print('数据类型:','\n',data1.dtypes)#数据清洗-查看缺失值
a = data1.isnull().sum()
if a.sum() == 0:print('数据集无缺失值')
else:print(a[a > 0])#数据清洗-异常值
#用户行为异常值
if data1['behaviour_type'].nunique() == 4:print('行为数据无缺失值')
else:print('数据行为存在缺失值,检查')#时间异常值
#将时间戳转化为北京时间、筛选要分析的时间范围
data1=data1.assign(time = pd.to_datetime(data1['timestamp'],unit='s')+datetime.timedelta(hours=8))
data1 = data1[(data1['time']>'2017-11-25') &(data1['time']<'2017-12-4')]
print('时间筛选过后的表结构:',data1.shape)#四.数据分析#4.1用户侧核心指标
#这部分主要用到日期,所以从time中提取date,这里使用map+匿名函数
data1 = data1.assign(date = data1['time'].map(lambda x:x.strftime('%Y-%m-%d')))#日均用户数
df_uvpd = data1[['user_id','date']].groupby('date').nunique()
df_uvpd = df_uvpd.drop(columns='date')
df_uvpd = df_uvpd.rename(columns={"user_id": "uv"})#日均活跃用户数
df_aupd = data1[['user_id','behaviour_type','date']].groupby(['date','user_id']).count()
df_aupd = df_aupd[df_aupd['behaviour_type']>2]
df_aupd = df_aupd.count(level = 0)
df_aupd.rename(columns={'behaviour_type':'active_user'},inplace =True)#计算日均交易用户数
df_bupd = data1[data1['behaviour_type'] == 'buy']
df_bupd = df_bupd[['user_id','behaviour_type','date']].groupby(['date','user_id']).count()
df_bupd = df_bupd.count(level = 0)
df_bupd.rename(columns={'behaviour_type':'buy_user'},inplace =True)#每日pv数:
df_pvpd = data1[['date','user_id']].groupby('date').count()
df_pvpd = df_pvpd.rename(columns = {'user_id':'pv'})#将上述各表连接后生成指标表格,用assign函数可以避免copywarning
df41 = df_pvpd.join(df_uvpd).join(df_aupd).join(df_bupd)
df41 = df41.assign(pv_per_user = df41['pv']/df41['uv'],active_user_rate = df41['active_user']/df41['uv'],buy_user_rate = df41['buy_user']/df41['uv'])#4.1.3用户活跃天数分布
df_user_active_days = data1[['user_id','behaviour_type','date']].groupby(['date','user_id']).count()
df_user_active_days = df_user_active_days[df_user_active_days['behaviour_type']>2]
df_user_active_days = df_user_active_days.count(level = 1)
df_user_active_days = df_user_active_days.rename(columns = {'behaviour_type':'days'})#4.2用户行为路径分析
#为区分各用户行为及其组合,为行为数据赋值:1,2,4,8,排列组合后为0-15
df1 = data1.drop_duplicates(['user_id','item_id','behaviour_type'])
df1 = df1.assign(type_num=df1['behaviour_type'].map({'pv':1,'fav':2,'cart':4,'buy':8}))#聚合求和,每一个路径都有不同的值
df1_gb = df1[['user_id','item_id','type_num']].groupby(['user_id','item_id']).sum()#划分各路径dataframe:buy
unpv_unfav_uncart_buy = df1_gb[df1_gb['type_num'] == 8]
pv_unfav_uncart_buy = df1_gb[df1_gb['type_num'] == 9]
unpv_fav_uncart_buy = df1_gb[df1_gb['type_num'] == 10]
pv_fav_uncart_buy = df1_gb[df1_gb['type_num'] == 11]
unpv_unfav_cart_buy = df1_gb[df1_gb['type_num'] == 12]
pv_unfav_cart_buy = df1_gb[df1_gb['type_num'] == 13]
unpv_fav_cart_buy = df1_gb[df1_gb['type_num'] == 14]
pv_fav_cart_buy = df1_gb[df1_gb['type_num'] == 15]print('unpv_unfav_uncart_buy:',unpv_unfav_uncart_buy.shape[0],' ;pv_unfav_uncart_buy:',pv_unfav_uncart_buy.shape[0])
print('unpv_fav_uncart_buy:',unpv_fav_uncart_buy.shape[0],' ;pv_fav_uncart_buy:',pv_fav_uncart_buy.shape[0])
print('unpv_unfav_cart_buy:',unpv_unfav_cart_buy.shape[0],' ;pv_unfav_cart_buy:',pv_unfav_cart_buy.shape[0])
print('unpv_fav_cart_buy:',unpv_fav_cart_buy.shape[0],' ;pv_fav_cart_buy:',pv_fav_cart_buy.shape[0])
print('--------------')#划分各路径dataframe:unbuy
unpv_unfav_uncart_unbuy = df1_gb[df1_gb['type_num'] == 0]
pv_unfav_uncart_unbuy = df1_gb[df1_gb['type_num'] == 1]
unpv_fav_uncart_unbuy = df1_gb[df1_gb['type_num'] == 2]
pv_fav_uncart_unbuy = df1_gb[df1_gb['type_num'] == 3]
unpv_unfav_cart_unbuy = df1_gb[df1_gb['type_num'] == 4]
pv_unfav_cart_unbuy = df1_gb[df1_gb['type_num'] == 5]
unpv_fav_cart_unbuy = df1_gb[df1_gb['type_num'] == 6]
pv_fav_cart_unbuy = df1_gb[df1_gb['type_num'] == 7]print('unpv_unfav_uncart_unbuy:',unpv_unfav_uncart_unbuy.shape[0],' ;pv_unfav_uncart_unbuy:',pv_unfav_uncart_unbuy.shape[0])
print('unpv_fav_uncart_unbuy:',unpv_fav_uncart_unbuy.shape[0],' ;pv_fav_uncart_unbuy:',pv_fav_uncart_unbuy.shape[0])
print('unpv_unfav_cart_unbuy:',unpv_unfav_cart_unbuy.shape[0],' ;pv_unfav_cart_unbuy:',pv_unfav_cart_unbuy.shape[0])
print('unpv_fav_cart_unbuy:',unpv_fav_cart_unbuy.shape[0],' ;pv_fav_cart_unbuy:',pv_fav_cart_unbuy.shape[0])#4.3用户行为时间分析
#4.3.1用户活跃时间分布,划分成24小时,求9天的总和
df43 = data1
df43['hour'] = df43['time'].dt.hour#pv数
df431_pv = df43[['hour','user_id']].groupby('hour').count()
df431_pv.rename(columns={'user_id':'访问数'},inplace =True)#uv数
df431_uv = df43[['hour','user_id']].groupby('hour').nunique()
df431_uv.rename(columns={'user_id':'用户数'},inplace =True)#购买数
df431_buy = df43[df43['behaviour_type'] == 'buy']
df431_buy = df431_buy[['hour','user_id']].groupby('hour').count()
df431_buy.rename(columns={'user_id':'购买数'},inplace =True)#4.3.2购买行为时间分布
#求fav/cart与buy行为的交集
data1_buy = data1[data1['behaviour_type'] == 'buy']
data1_fav = data1[data1['behaviour_type'] == 'fav']
data1_cart = data1[data1['behaviour_type'] == 'cart']
df432_fav_buy = pd.merge(data1_buy,data1_fav,on = ['user_id','item_id'],how = 'inner')
df432_cart_buy = pd.merge(data1_buy,data1_cart,on = ['user_id','item_id'],how = 'inner')#fav-buy行为时间分布
df432_fav_buy = df432_fav_buy.assign(dtime = (df432_fav_buy['time_x'] - df432_fav_buy['time_y']))#这里datetime时间类型相减后是deltatime类型,转化为hour要自己计算,下面同理
df432_fav_buy['dtime'] = df432_fav_buy['dtime'].map(lambda x : x.days * 24 + x.seconds/3600)
df432_fav_buy = df432_fav_buy[df432_fav_buy['dtime'] > 0]#cart-buy行为时间分布
df432_cart_buy = df432_cart_buy.assign(dtime = (df432_cart_buy['time_x'] - df432_cart_buy['time_y']))
df432_cart_buy['dtime'] = df432_cart_buy['dtime'].map(lambda x : x.days * 24 + x.seconds/3600)
df432_cart_buy = df432_cart_buy[df432_cart_buy['dtime'] > 0]#4.4商品分类分析
#4.4.1 商品大类交易数
data1_buy = data1[data1['behaviour_type'] == 'buy']#聚合计数每商品大类的交易数
data1_buy_category = data1_buy[['category_id','behaviour_type']].groupby('category_id').count()
data1_buy_category = data1_buy_category.rename(columns = {'behaviour_type':'buy_count'})#排序
data1_buy_category = data1_buy_category.sort_values('buy_count',ascending=False)
data1_buy_category = data1_buy_category.reset_index()data1_buy_category.head()#4.4.2商品大类购买行为
#有购买行为的商品大类与原始数据连接,可得到以用户id及商品大类id为键的包含其他行为数据的dataframe,并聚合计数其行为数据
data1_behav_category = pd.merge(data1_buy[['user_id','category_id']],data1,on = ['user_id','category_id'],how = 'left')
data1_behav_category = data1_behav_category[['category_id','behaviour_type']].groupby('category_id').count()
data1_behav_category = data1_behav_category.rename(columns = {'behaviour_type':'behav_count'})
data1_behav_category = data1_behav_category.reset_index()#只分析最终有购买的用户行为,与上一步商品大类交易数占比中的dataframe连接,计算比值
df_cate_buy_behav = pd.merge(data1_buy_category,data1_behav_category,on = 'category_id',how='inner')
df_cate_buy_behav = df_cate_buy_behav.assign(behav_per_buy = df_cate_buy_behav['behav_count']/df_cate_buy_behav['buy_count'])#4.4.3 商品关联性分析
#计算总订单数
df_oneorder_buycount = data1_buy.groupby(['user_id','timestamp']).count()
print('总订单数:',df_oneorder_buycount.shape[0])#筛选出商品id多于一个的订单数
df_oneorder_buycount = df_oneorder_buycount[df_oneorder_buycount['item_id'] > 1]
df_oneorder_buycount = df_oneorder_buycount.reset_index()
df_oneorder_buycount = df_oneorder_buycount[['user_id','timestamp','item_id']]
df_oneorder_buycount = df_oneorder_buycount.rename(columns = {'item_id':'num_in_one_order'})
print('商品id多于一个的订单数:',df_oneorder_buycount.shape[0])
df_oneorder_buycount.head()#表连接补充表-'商品id多于一个的订单数'的数据内容
df_buy_multi = pd.merge(df_oneorder_buycount,data1_buy,on=['user_id','timestamp'],how='inner')
df_buy_multi.head()#计算商品大类相关性
#上表中同一订单中的不同category_id都显示出来了,通过自连接实现组合
rel_a = df_buy_multi
rel_b = df_buy_multi[['user_id','timestamp','category_id']]
rel = pd.merge(rel_a,rel_b,on=['user_id','timestamp'],how = 'left')
rel = rel[rel['category_id_x'] < rel['category_id_y']]#去除连接相同大类的数据#组合好并去重后,聚合就可以计数两两商品大类的出现次数,在这里简单认为次数越多,相关性越高
rel_count = rel[['category_id_x','category_id_y','user_id']].groupby(['category_id_x','category_id_y']).count()
rel_count = rel_count.rename(columns={'user_id':'出现次数'})
rel_count = rel_count.sort_values('出现次数',ascending = False)
rel_count = rel_count.reset_index()#计算商品相关性
#代码同上一项一样,将category_id换成item_id就可以了
rel_a = df_buy_multi
rel_b = df_buy_multi[['user_id','timestamp','item_id']]
rel = pd.merge(rel_a,rel_b,on=['user_id','timestamp'],how = 'left')
rel = rel[rel['item_id_x'] <= rel['item_id_y']]#去连接重复的rel_count = rel[['item_id_x','item_id_y','user_id']].groupby(['item_id_x','item_id_y']).count()
rel_count = rel_count.rename(columns={'user_id':'出现次数'})
rel_count = rel_count.sort_values('出现次数',ascending = False)
rel_count = rel_count.reset_index()
画图代码(部分)#画图-4.1.1日均用户指标fig = go.Figure()fig.add_trace(go.Scatter(x=df41.index, y=df41['uv'], name="日均用户",line_color ="#1f77b4")
)
fig.add_trace(go.Scatter(x=df41.index, y=df41['active_user'], name="日均活跃用户",line_color = "#ff7f0e")
)
fig.add_trace(go.Scatter(x=df41.index, y=df41['buy_user'], name="日均交易用户",line_color = "#d62728")
)fig.update_layout(title_text="日均用户指标",width=800)fig.update_xaxes(title_text="日期",dtick='d')fig.show()#画图-4.1.3用户活跃天数分布
fig = go.Figure()
fig.add_trace(go.Histogram(x=df_user_active_days['days'], histnorm='percent',name = '活跃天数分布图(9天内)',xbins=dict(size= 0.5),marker_color= 'rgb(49,130,189)') )
fig.update_xaxes(dtick=1)fig.update_layout(height=450, width=800, title_text='活跃天数分布图(9天内)')
fig.show()#画图-4.3.1用户活跃时间分布
fig = make_subplots(specs=[[{"secondary_y": True}]])fig.add_trace(go.Bar(x=df431_pv.index,y=df431_pv['访问数'],name='日pv时间分布',marker_color = 'rgb(115,115,115)')
)
fig.add_trace(go.Scatter(x=df431_pv.index,y=df431_uv['用户数'],name = '日用户数时间分布', connectgaps=True,line_color = 'rgb(49,130,189)'),secondary_y = True
)
fig.add_trace(go.Scatter(x=df431_pv.index,y=df431_buy['购买数'] * 5,name = '日购买数时间分布', connectgaps=True,line_color = 'rgb(180,60,60)'),secondary_y = True
)
fig.update_layout(yaxis2=dict(tickfont=dict(color='rgb(49,130,189)'))
)
fig.update_layout(title_text="用户行为时间分布(日)")
fig.show()