本篇论文是2021年新发表的一篇论文。也是目前有源码的论文中唯一一篇使用transformer模型和注意力机制的论文源码(pytorch和tensorflow版本均有)
论文及源码见个人主页:
https://download.csdn.net/download/qq_45874683/87658878
(论文加源码)基于deap数据集的transformer结合注意力机制脑电情绪识别(13条消息) (论文加源码)基于deap数据集的transformer结合注意力机制脑电情绪识别-深度学习文档类资源-CSDN文库
摘要:
对人类进行准确的情绪评估可以证明在医疗保健、安全调查和人际交往中是有益的。基于面部表情的情绪识别被证明是不准确的,而脑电图(EEG)活动的分析更准确地反映了一个人的精神状态。随着深度学习的进步,各种方法正在被用于这项任务。在本研究中,通过两种基于transformer的基于情绪的脑电信号分类方法,介绍了注意力机制在脑电信号中的重要性。第一种方法利用通过原始EEG信号的连续小波变换(CWT)生成的2-D图像,而第二种方法直接对原始信号进行操作。本研究使用了公开可用且被广泛接受的DEAP数据集来验证所提出的方法。所提出的方法报告了使用CWT的97%和95.75%的非常高的准确率,以及使用原始信号的99.4%和99.1%的准确率用于效价和唤醒分类,这清楚地突出了注意力机制对EEG信号的重要性。所提出的方法还确保了更快的训练和测试时间,以适应临床目的。
I.引文
情感是人类的本质,可以与思想、决策能力和认知过程联系在一起。因此,对情绪状态的研究可以增强当前的脑机接口(BCI)系统,该系统可以进一步应用于各种应用,如自闭症谱系障碍(ASD)、注意力缺陷多动障碍(ADHD)和焦虑症等疾病的治疗[1]。由于这些重要的应用,情绪状态的识别和分析已成为医学、神经科学、认知科学和大脑驱动的人工智能领域的一个重要研究领域。已经开发了几种用于情绪识别的方法,包括使用生理信号和非生理信号。非生理信号包括面部表情、语音信号、身体姿势,而生理信号包括脑电图、心电图信号等等。使用非生理信号相对容易,不需要任何特殊设备,但个人可以伪造此类信号,因此不被视为一个人情绪状态的真实反映。相比之下,生理信号超出了一个人的控制范围,因此更适合于给定的任务[7]。
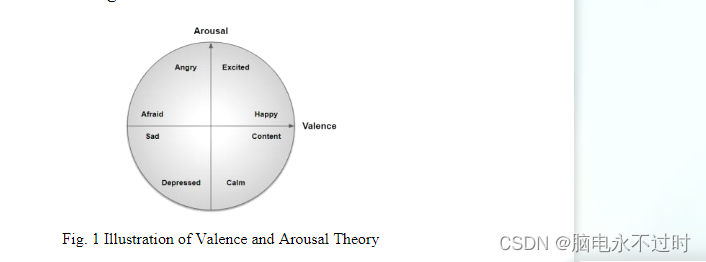
过去已经进行了各种研究,专门通过生理信号处理情绪识别,如[2-9]所述。使用Naive Bayes分类器的功率谱密度(PSD)特征的算法[2,3],使用本体论模型的PSD和统计特征[4],使用支持向量机分类器的基于深度置信网络(DBN)的特征[5],使用神经网络(NN)的功率谱和统计特征[6],使用SoftMax作为分类器的LP-1D-CNN模型提取的特征[7],以深度神经网络和稀疏自动编码器架构作为分类器[8]的Pearson相关系数特征,以及直接与MMResLSTM一起使用作为分类器[9]的原始EEG 1D时间信号是其中的一些。在大多数方法[2-9]中,情绪状态被理想地离散为许多状态,如喜悦、恐惧、愤怒、幸福、惊讶等,被广泛地分为两个基本的有意义的维度:效价和唤醒[18]。效价维度决定了情绪的积极或消极影响,唤醒维度决定了它的强度,如图1所示:
然而,必须记住,像情绪识别这样的任务发生在几秒钟内,而不是发生在几毫秒内的即时反应。由于几秒钟的时间对EEG来说是一个重要的数据量,因此在短暂的一段时间内发生的脉冲之间可能存在联系。在这种情况下,如果用于情绪分类的模型也考虑了很久以前发生的事件,那就太好了。卷积神经网络(CNN)和长短期存储器(LSTM)等架构可能无法考虑这种长期依赖性。CNN是由内核大小和各自的步长决定的局部网络,而LSTM由于遗忘因素而不具有良好的记忆保持能力[10,11]。另一方面,在不受序列中远距离约束的情况下对相关性进行建模的能力基本上是变压器网络中注意力机制的核心[12,13]。基于自注意机制的Transformer[10]因此在自然语言处理(NLP)中被广泛接受。在高水平上,该模型遍历每个向量,其中自注意力机制使其能够查看输入序列的其他部分,这有助于更好地编码向量。transformer 网络是这些注意力层的堆栈,具有一些残差连接。transformer 有能力在记忆极限范围内保留尽可能多的信息,并在过去发生的事情和现在发生的事情之间建立关系。LSTM和CNN以相对位置进行建模,而变换器依赖于输入的绝对位置表示(位置嵌入和它是置换不变的)[10,11]。
在这项研究中,一种名为Vision Transformer视觉转换器(ViT)[11]的 transformer变体专门为图像制作,已适用于脑电图中的情绪检测。选择ViT的原因是使用由小波变换生成的时频图像,该图像考虑了频率的局部变化。然而,与时频图像相比,将ViT直接应用于原始EEG信号在准确性上有了显著的提高,这从结果中可以明显看出。这清楚地表明了两个方面:1)注意机制对EEG信号的重要性;2)需要适当的编码方案。据我们所知,这是首次尝试将ViT用于EEG信号分析,也是首次尝试识别EEG信号中注意力的重要性。ViT简单设置的最大优势之一是它们具有可扩展性和高效性。
二、提议的方法
在本节中,详细解释了针对CWT图像和原始EEG信号提出的ViT方法。
A.模型体系结构
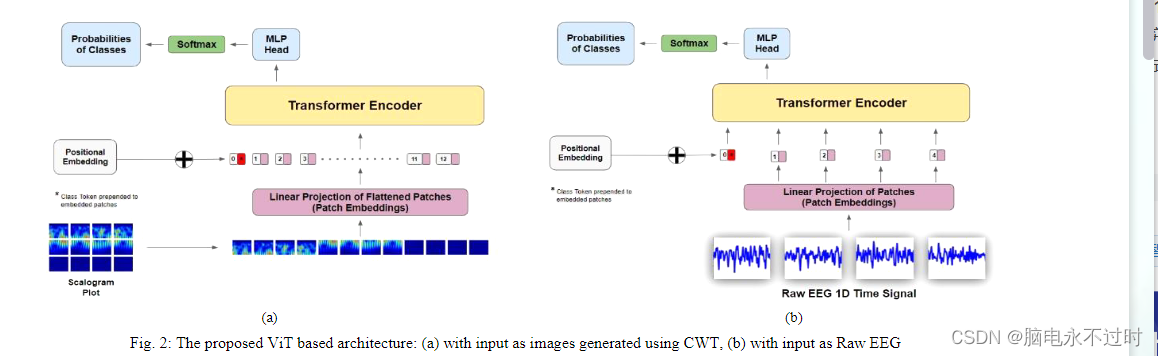
ViT[11]的架构与vanilla transformer [10]的架构非常相似。NLP转换器具有令牌嵌入,这意味着它接收具有已知字典大小的1D输入作为输入。然而,对于如在ViT的情况下的2D输入,图像被划分为用作标记的平坦的2D固定大小图像块的序列。因此,大小的图像𝑥 ∈ℝ𝐻×𝑊×𝐶 分为大小不等的补丁序列𝑥 ∈ℝ𝑁×(𝑃2 ×𝐶) 哪里𝑁 = 𝐻𝑊/𝑃2和𝑃 是选定的修补程序大小。最后,在将获得的补丁传递到vanilla transformer 之前,它通过如(1)[11]中所述的可训练线性投影层,以获得最终的补丁嵌入(z0)。ViT使用这些补丁嵌入,因此在NLP转换器中没有特定vocab的约束。
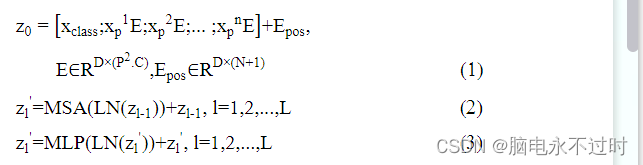
类似于来自Transformers(BERT)[14]架构的双向编码器表示,在补丁嵌入之前准备了可学习的类令牌嵌入。位置嵌入(E pos)也被添加到这些补丁嵌入中,用于引入序列中标记的位置信息。变换器模型包含交替层的多头自注意(MSA)和MLP(2层具有高斯误差线性单元(GELU)非线性)块(如(2)、(3)所示),每个块之前有一个层归一化(LN),并且每个块之后有剩余连接[15,16]。
B.特征提取
在所提出的基于ViT的EEG分类器网络中,ViT的输入数据以两种方式考虑,即原始EEG信号和通过CWT生成的图像。所提出的方法的体系结构如图2a和2b所示。小波变换由于其压缩和时频定位能力,在脑电中的应用非常受欢迎[17]。所使用的母小波的选择是基于其与时间信号的兼容性的一个重要方面。正如[17]中所研究的,EEG信号与近对称和正交的母小波(如sym24、db4、coif5)最兼容。在这项研究工作中,db4和coif5母小波被用于生成要被用作ViT的输入的图像。作为消融的一部分,已经尝试了其他压缩表示的实验,如自动编码器[8],而不是基于CWT的图像,但结果并不令人鼓舞。
三、 结果和分析
在本节中,介绍了用于分析所提出方法的数据集的细节以及分析结果。
A.数据集描述
所提出的方法在广泛使用的DEAP[2]数据集上得到了验证。在这个数据集中,记录了32名参与者的脑电图和外周生理信号。该数据集中的每个参与者观看了40个一分钟的音乐视频,同时他们的脑电图记录以512 Hz的采样率进行,32个通道随后被下采样到128 Hz,并带通滤波到4–45 Hz。每个视频都由参与者主要根据效价、唤醒度、喜欢度和主导度进行评分,评分范围为1-9。使用DEAP数据集,可以通过等分标签来提取许多类。在拟议的工作中,采用了效价和唤醒的两个类别标签。
B.训练
随着情绪等反应在几秒钟的时间内发展,每个视频的60秒记录被分别分解为不重叠的较小n大小的样本(n=6、15、20、30秒),因此将视频分解为这些大小将有助于我们正确地关注每种情绪的发展。将具有所有32个通道的上述大小样本的数据集输入到ViT模型,并通过以下两种方式进行训练,如图2所示。
• 通过CWT生成的图像:使用48个尺度的CWT并使用db4和coif5母小波对n尺寸32通道样本进行变换。作为48尺度CWT的一部分生成的尺度图图像随后被馈送到ViT,在ViT中应用形状为[补丁大小,补丁大小]的补丁嵌入。平坦的补丁通过可训练的线性投影层被映射到D维(如(1)所示)。现在,在从可训练线性投影层接收到的输出中预加一个类标记。最后,将位置嵌入添加到补丁嵌入中,并将其传输到转换器编码器。
• 原始EEG信号:在这种情况下,原始32通道EEG信号(使用4–45 Hz带通滤波器作为DEAP数据集的一部分进行预处理)直接发送到ViT,而不是任何变换或编码,如图2b所示。由于原始EEG信号是1D时间信号,因此以[1,补丁大小]的形状应用补丁嵌入。此外,在这种情况下,由于面片已经被展平,因此它们被直接映射到具有可训练线性投影的D维。类似地,类标记被预先添加到它,然后添加位置嵌入,最后传输到转换器编码器。
在CWT图像和基于原始EEG信号的模型中,变压器编码器的输出都通过MLP头层,在那里它被映射到类的数量。然后应用SoftMax层和ArgMax层以获得具有最大概率的类。使用嵌入尺寸为512的6层变压器和用于MSA的8个头进行训练。与NLP中的同类产品相比,该转换器的大小和内存使用量小了2-3倍,这导致了更快的训练和测试时间[11]。在这项工作中,实现是在Python 3.7.10和TensorFlow 2.5.0上完成的。学习率设置为0.00001。
C.结果
如第III.A节所述,为了验证所提出方法的有效性,在公开的DEAP数据集上进行了实验[2]。数据集被划分,使得80%的数据进入训练集,剩余的20%进入测试集。
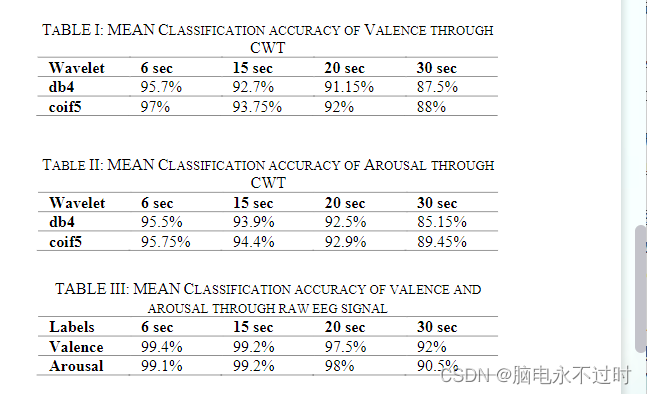
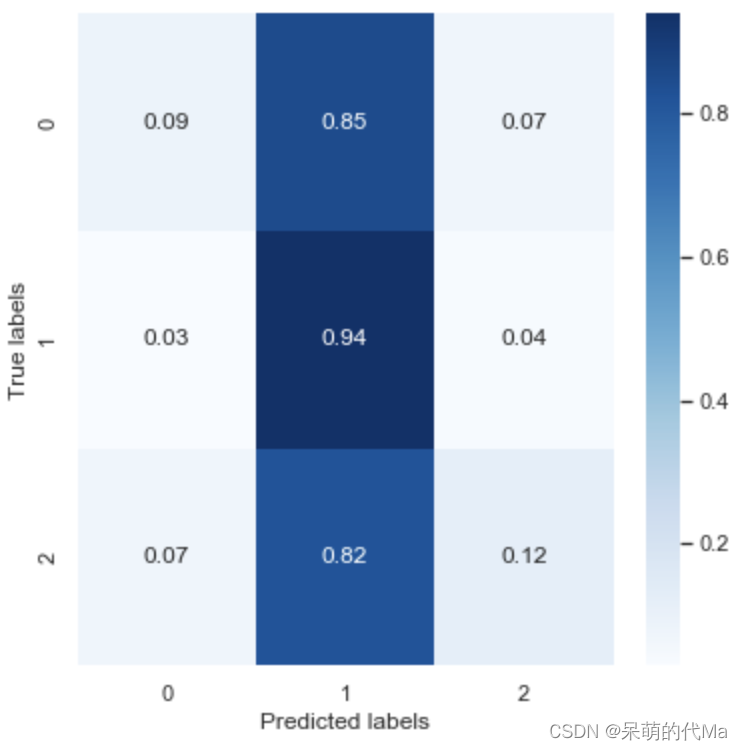
•通过CWT生成的图像:通过CWT产生的图像结果见表I和表II。如图所示,由6秒大小的样本形成的标度图表现明显好于15秒、20秒和30秒大小的样品。这清楚地表明了EEG信号的显著局部化行为以及可以获取EEG的局部化区域进行进一步处理的模型的重要性。
•原始脑电图信号:原始脑电图信号实验的结果如表III所示。在这种情况下,如图所示,6秒和15秒大小的样本的表现明显好于20秒和30秒大小的样品。更重要的是,在比较表I、表II和表III时,很明显,基于原始EEG信号的方法出人意料地比基于CWT的方法执行得好得多。这可能归因于这样一个事实,即EEG信号是随机的,情绪内容是局部的,在使用变压器[11]等注意力方法的情况下,不需要(或需要仔细应用)EEG信号的转换。作为未来研究的一部分,将对此进行详细分析。
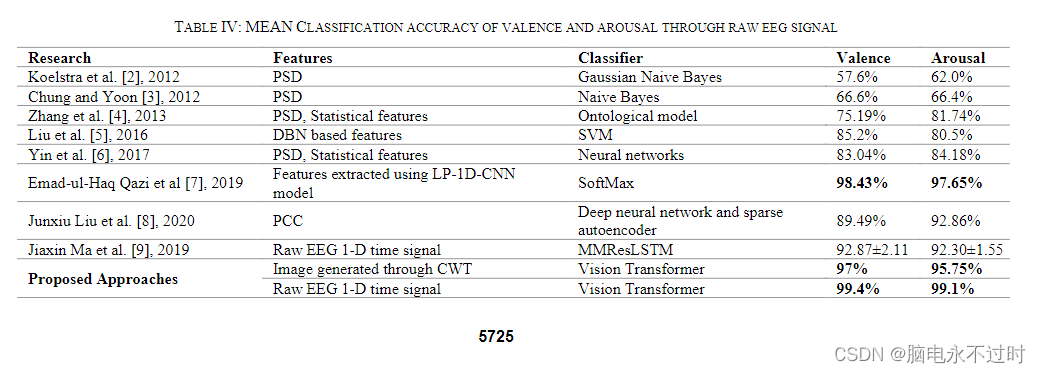
还将所提出的方法与文献中大多数公认的方法进行了全面比较,结果如表IV所示。从表IV可以看出,所提出的基于ViT的方法优于文献中记录的所有最近相关的最先进的研究。通过ViT获得良好结果的主要原因可以归因于基于注意力的机制。通过基于多头注意力的机制,该模型能够以比CNN和LSTM或手工制作的机器学习算法更好、更快的方式捕捉和记住情绪随时间的发展,这项工作中提出的结果与大多数已建立的通过EEG信号进行情绪分类的研究工作所报告的观察结果一致,即较小尺寸的样本比较长尺寸的样本表现更好。
四、 结论
在本文中,我们研究了两个实验装置,即通过CWT生成的图像和使用视觉变换器(ViT)进行基于EEG的情绪识别的原始信号。ViT在公开可用的DEAP数据集中产生了良好的结果,在通过Coif5母小波的CWT实验形成的图像中,效价和唤醒的准确率分别为97%和95.75%。另一方面,在原始脑电图信号实验中,效价和唤醒的准确率分别为99.4%和99.1%,从而优于现有的最先进的方法。ViT卓越性能的主要原因之一是基于注意力的机制,因此它能够捕获和保留比传统的cnn和LSTM更多的相关信息。进行的两项实验也证实,较小尺寸的样本更适合捕捉情绪,因为它们比其他样本产生更高的分类精度。此外,对于类似的任务,ViT在计算上比其他神经网络更快,这使得它们更适合实时分析任务。未来的工作涉及对作为ViT输入的各种压缩/编码方案的彻底比较,以及识别最具影响力的EEG通道的方法,并量化导致最高注意力分数的时间段的影响,特别是在原始EEG信号实验中。
论文及源码见个人主页:
https://download.csdn.net/download/qq_45874683/87658878
(论文加源码)基于deap数据集的transformer结合注意力机制脑电情绪识别(13条消息) (论文加源码)基于deap数据集的transformer结合注意力机制脑电情绪识别-深度学习文档类资源-CSDN文库