来源:量子位
家人们,AI做视频这事今天又被推向了舆论的风口浪尖。
起因是有人在网上发布了这么一只小企鹅的视频:
而这个近50秒视频的诞生,靠的仅仅是6句话!

陆陆续续的,网友们还在发布着这个AI的其它杰作:

这次给它投喂的提示词也是极短,仅4行:

如此“所写即所得”、丝滑连贯的视频生成方式,也是令不少网友发出感慨:
未来已至。

甚至还有人开始“拉仇恨”,说AI正在用各种方式摧毁行业……
然后就有很多人发问了:“这又是哪家新搞的AI哇?”
不过眼尖的网友发现它其实是一位“老朋友”了——
谷歌去年10月份便发布的一个文本转视频(Text-to-Video)模型:Phenaki。
只需一段提示词,分分钟可以生成长达两分钟的视频。

而相比Phenaki刚发布的时候,谷歌又来了一波上新操作。
那么我们现在就来一同看看这些新视频吧~
打字就能生成的视频
与以往AI生成的视频不同,Phenaki最大的特点便是有故事、有长度。
例如,我们再给这么一段场景描述:
在一座未来感十足的城市里,交通纷繁复杂,这时,一艘外星飞船抵达了城市。
随着镜头的拉近,画面进入到了飞船内部;而后镜头沿着船内长廊继续向前推进,直到看到一名宇航员在蓝色的房间里敲键盘打字。
镜头逐渐移向宇航员的左侧,身后出现蓝色海洋,鱼儿们在水里徜徉;画面快速放大聚焦到一条鱼的身上。
随后镜头快速从海里浮出,直到看到摩天大楼高耸林立的未来城市;镜头再快速拉近到一撞大楼的办公室。
这时,一只狮子突然跳到办公桌上并开始奔跑;镜头先聚焦到狮子的脸上,等再次拉远时,这只狮子已经幻化成西装革履的“兽人”。
最后,镜头从办公室拉出,落日余晖下鸟瞰这座城市。
想必不少友友们在读这段文字过程中,脑中已经浮现相应的画面了。
接下来,我们一起看看Phenaki生成的效果如何:
是不是和你脑补出来的画面一致呢?
总体来说,这个AI即便面对这种脑洞大开的场景提示词,也是做到了无缝衔接的转场。
也难怪网友们看完这段视频后惊呼“(科技)发展得真快啊”。

而对于篇幅稍短的提示词,Phenaki就更不在话下了。
例如,给Phenaki投喂这样一段文字:
一只逼真的泰迪熊正在潜水;随后它慢慢浮出水面;走上沙滩;这时镜头拉远,泰迪熊行走在海滩边篝火旁。

没看够?那再来一段,这次换个主角:
在火星上,宇航员走过一个水坑,水里倒映着他的侧影;他在水旁起舞;然后宇航员开始遛狗;最后他和小狗一起看火星上看烟花。

而在谷歌更早发布Phenaki之际,还展示了向Phenaki输入一个初始帧以及一个提示词,便可以生成一段视频的能力。
例如给定这样一张静态图:

然后再给它Phenaki简单“投喂”一句:白猫用猫爪触摸摄像机。效果就出来了:

还是基于这张图,把提示词改成“一只白猫打哈欠”,效果就成这样了:

当然,任意切换视频整体风格也是可以hold得住的:

网友:视频行业要被AI冲击了吗?
但除了Phenaki之外,谷歌当时还一道发布过Imagen Video,能够生成1280*768分辨率、每秒24帧的高清视频片段。

它基于图像生成SOTA模型Imagen,展示出了三种特别的能力:
能理解并生成不同艺术风格的作品,水彩、像素甚至梵高风格
能理解物体的3D结构
继承了Imagen准确描绘文字的能力
更早的,Meta也发布了Make-A-Video,不仅能够通过文字转换视频,还能根据图像生成视频,比如:
将静态图像转成视频
插帧:根据前后两张图片生成一段视频
根据原视频生成新视频
……

对于这如“雨后春笋”突然冒出的生成视频模型,不免会让有些人担心:
当然也有人认为现在时机还未到:
0-1总会很快,1-100还是会很漫长。

不过已经有网友在期待靠AI拿奥斯卡奖了:
AI要多久才能成为新的视频编辑器,或者拿下奥斯卡?

原理介绍
再说回Phenaki,有不少网友都比较好奇它是如何通过文字生成这么丝滑的视频的?
简单来说,Phenaki相较于以往的生成视频模型,它更注重时间长度任意性和连贯性。
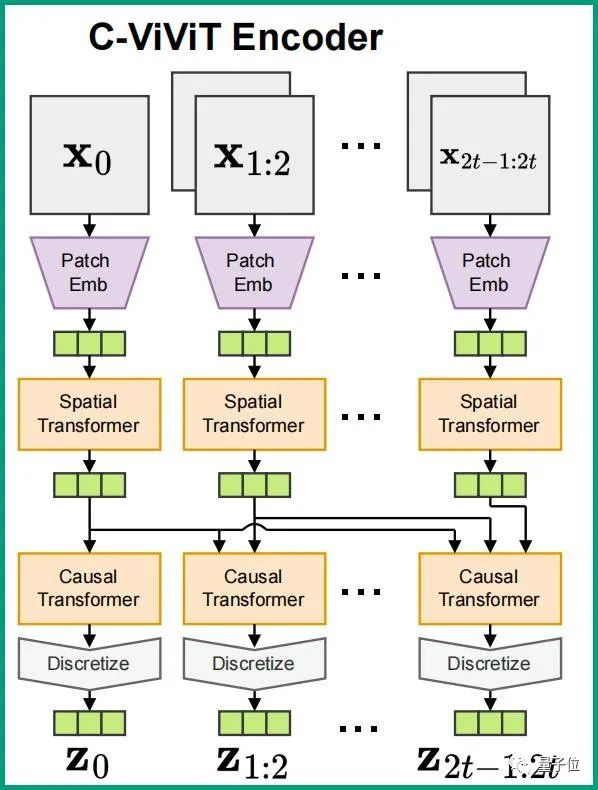
Phenaki之所以能够生成任意时间长度的视频,很大程度上要归功于新的编码器-解码器架构:C-ViViT。
它是ViViT的一个因果变体,能够将视频压缩为离散嵌入。
要知道,以往获取视频压缩,要么就是编码器不能及时压缩视频,导致最终生成的视频过短,例如VQ-GAN,要么就是编码器只支持固定视频长度,最终生成视频的长度不能任意调节,例如VideoVQVAE。
但C-ViViT就不一样了,它可谓是兼顾了上面两种架构的优点,能够在时间和空间维度上压缩视频,并且在时间上保持自回归的同时,还可以自回归生成任意长度的视频。
C-ViViT可以使模型生成任意长度的视频,那最终视频的逻辑性又是怎么保证的呢?
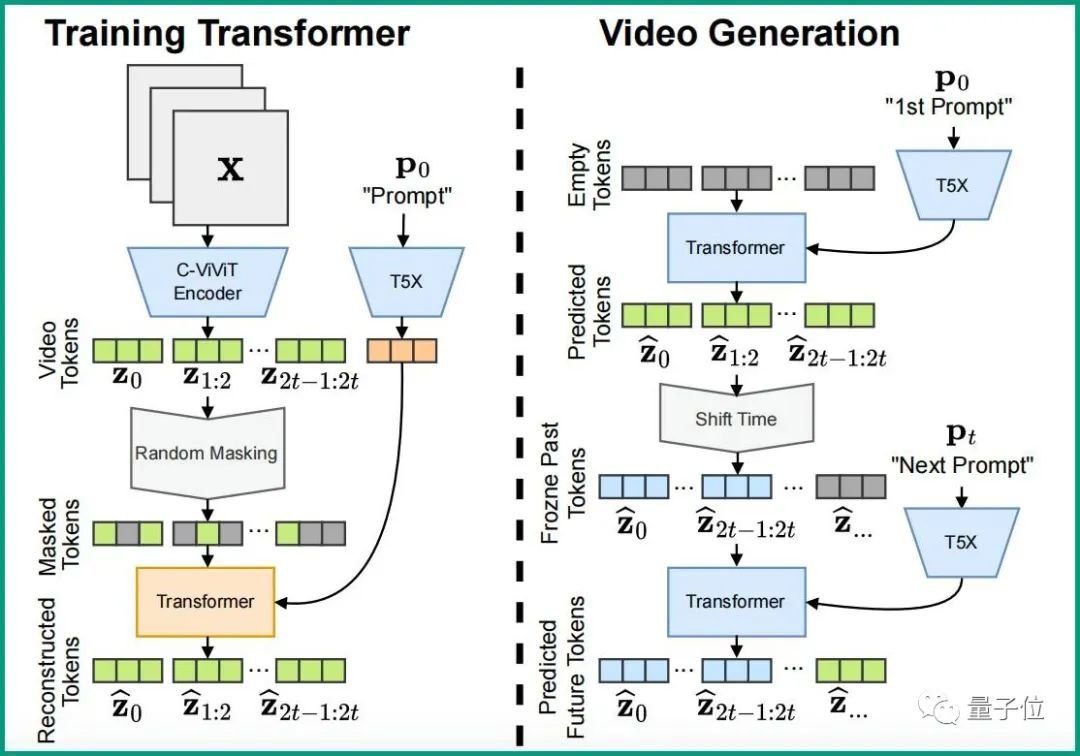
这就得靠Phenaki另外一个比较重要的部分:双向Transformer。
在这其中,为节省时间,采样步骤是固定的,并且在处理文本提示的过程中,能同时预测不同的视频token。
这样一来,结合前面提到的,C-ViViT能够在时间和空间维度上压缩视频,压缩出来的token是具有时间逻辑性的。
也就是说,在这些token上经过掩码训练的Transformer也具备时间逻辑性,最终生成的视频在连贯性自然也就有了保证。
如果还想了解更多关于Phenaki的东西,可以戳这里查看。
Phenaki:
https://phenaki.github.io
参考链接:
[1] https://phenaki.video/
[2] https://phenaki.research.google/
[3] https://twitter.com/AiBreakfast/status/1614647018554822658
[4] https://twitter.com/EvanKirstel/status/1614676882758275072
推荐阅读
西电IEEE Fellow团队出品!最新《Transformer视觉表征学习全面综述》
润了!大龄码农从北京到荷兰的躺平生活(文末有福利哟!)
如何做好科研?这份《科研阅读、写作与报告》PPT,手把手教你做科研
奖金675万!3位科学家,斩获“中国诺贝尔奖”!
又一名视觉大牛从大厂离开!阿里达摩院 XR 实验室负责人谭平离职
最新 2022「深度学习视觉注意力 」研究概述,包括50种注意力机制和方法!
【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载!
2021李宏毅老师最新40节机器学习课程!附课件+视频资料
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!