机器学习预测nba
Paul the Octopus was a short-lived (26 January 2008–26 October 2010) cephalopod kept at the Sea Life Centre in Oberhausen, Germany, who became instantly famous because of his alleged ability to predict the results of FIFA World Cup football matches. All he had to do was to eat food from one of two boxes, identical in all aspects except for the flag of the contending national teams. As many regard octopuses as the closest to alien intelligence on Earth, one may wonder if the German invertebrate (no offence intended) knew some secret about football that presumably smarter hairless apes (a.k.a. humans) in fact didn’t.
保罗章鱼是一种短命(2008年1月26日至2010年10月26日)的头足纲动物,头足纲动物位于德国奥伯豪森的海洋生物中心 ,由于据称他有能力预测FIFA世界杯足球赛的结果而一举成名。 他所要做的就是从两个盒子之一中吃东西,除了竞争激烈的国家队的旗帜外,其他所有方面都一样。 许多人认为章鱼是地球上最接近外星人情报的人 ,也许有人会想知道,德国无脊椎动物(无意冒犯)是否知道足球的一些秘密,而事实上,聪明的无毛猿猴( 又名人类)却没有。
The history of computer-based predictions of the outcome of sport events is long. A good account is told in Nate Silver’s The Signal and Noise, a must-read for those who are interested in the subject. The book also reminds the reader that most of such predictions fails. However, especially since the advent of Deep Learning, applications of advanced statistical methods to sport events has become more and more important, leading for example to scouting of young players in baseball or to improved training e.g. to shoot 3-pointers in basketball. It is almost natural at this point in history to ask ourselves how much better than us artificial intelligence can be at making predictions about sports by exploiting historical data. In this post, we’ll explore the possibility to predict the NBA playoff bracket and, who knows, perhaps even winning 1 million dollars.
基于计算机的体育赛事结果预测的历史悠久。 内特·西尔弗 ( Nate Silver )的《信号与噪声 》( The Signal and Noise )讲述了一个很好的故事,这是对该主题感兴趣的人必读的。 该书还提醒读者,大多数此类预测都将失败。 但是,尤其是自从深度学习问世以来,高级统计方法在体育赛事中的应用就变得越来越重要,例如导致对年轻球员进行棒球选拔或改进训练, 例如在篮球比赛中投三分球 。 在历史的这一点上,几乎自然地要问自己,通过利用历史数据来进行体育运动预测时,人工智能比我们好得多。 在本文中,我们将探讨预测NBA季后赛阶段的可能性,而且,甚至可以赢得100万美元。
借助AI赢得NBA挑战赛 (Winning The NBA Bracket Challenge with AI)
This year, the National Basketball Association (NBA) launched a challenge to encourage people to predict the outcome of all playoffs series (plus a tie-breaker) called the NBA Bracket challenge. Although the window to join the challenge is now closed and by the time of writing some results are already in, it is interesting to see in general how a machine learning system can be arranged to make such predictions. This is of course a rather simplified approach, although more advanced examples have been proposed in the past e.g. based on the principle of maximum entropy. I prepared a Google Colab notebook which you can use to play around. You also need input data which you can copy from this shared folder.
今年,美国国家篮球协会(NBA)发起了一项挑战赛,以鼓励人们预测所有季后赛系列赛的结果(加上决胜局),这就是NBA挑战赛 。 尽管现在已经关闭了参加挑战的窗口,并且在撰写本文时已经有了一些结果,但是有趣的是,通常可以看到如何安排机器学习系统来进行此类预测。 尽管过去例如基于最大熵原理已经提出了更高级的示例,但是这当然是相当简化的方法。 我准备了一个Google Colab 笔记本 ,可以用来玩。 您还需要可以从此共享文件夹复制的输入数据。
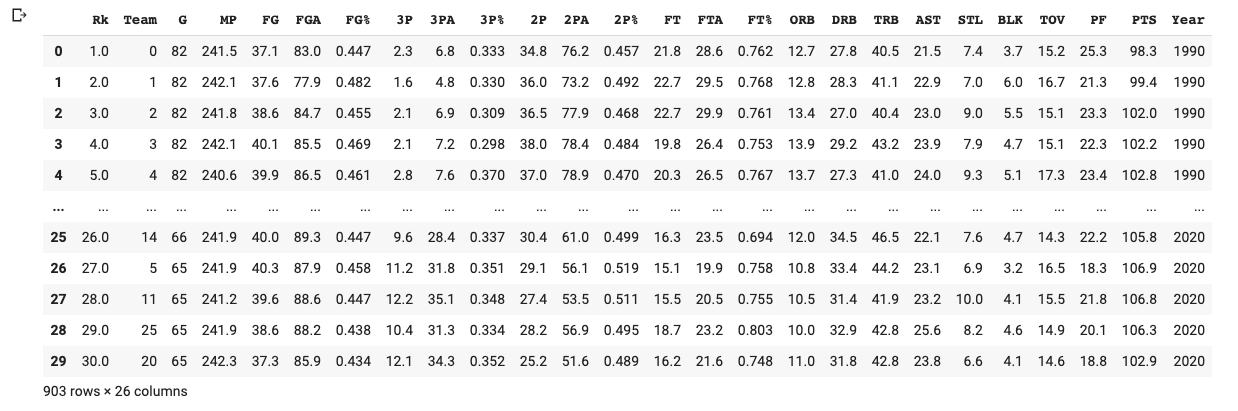
To start with, we collect data from the Basketball reference website. Conveniently, one can download statistics about both regular season and playoff games. Here we restrict to years 1990–2019, and we’ll use regular season data for 2020 to predict the 2020 bracket.
首先,我们从篮球参考网站收集数据。 可以方便地下载有关常规赛和季后赛的统计信息。 在这里,我们将年份限制为1990-2019年,我们将使用2020年的常规季节数据来预测2020年的水平。
For each team, and for each year, the following “classical” features are available (per-game averaged):
对于每个团队和每年,以下“经典”功能可用(按游戏平均):
- Rank at the end of the regular season (Rk) 常规赛结束时的排名(Rk)
- Number of played games (G) 游戏数(G)
- Minutes played (MP) 分钟数(MP)
- Field goals (FG) 实地目标(FG)
- Field goal attempts (FGA) 射门得分(FGA)
- Field goal percentage (FG%) 射门得分百分比(FG%)
- 3-points field goals (3P) 3点投篮命中率(3P)
- 3-points field goals attempts (3PA) 三分投篮命中率(3PA)
- 3-points field goals percentage (3P%) 三分球命中率(3P%)
- 2-points field goals (2P) 2点投篮命中率(2P)
- 2-points field goals attempts (2PA) 2分射门得分尝试(2PA)
- 2-points field goals percentage (2P%) 2分投篮命中率(2P%)
- Free-throws (FT) 罚球(FT)
- Free-throw attempts (FTA) 罚球尝试(FTA)
- Free-throw percentage (FT%) 罚球命中率(FT%)
- Offensive rebounds (ORB) 进攻篮板(ORB)
- Defensive rebounds (DRB) 防守篮板(DRB)
- Total rebounds (TRB) 总篮板(TRB)
- Assists (AST) 助攻(AST)
- Steals (STL) 偷(STL)
- Blocks (BLK) 积木(BLK)
- Turnovers (TOV) 营业额(TOV)
- Personal fouls (PF) 个人犯规(PF)
- Points 点数
One can download all this data in CSV format, which can be easily manipulated as a Pandas dataframe.
可以CSV格式下载所有这些数据,可以轻松地将其作为Pandas数据框进行操作。
Not surprisingly, there are correlations among these features. To reduce the number of input features and to remove correlations as much as possible, it is customary to standardize (i.e. remove mean and scale the variance) and then apply a Principal Component Analysis decomposition to the inputs.
毫不奇怪,这些功能之间存在关联。 为了减少输入特征的数量并尽可能消除相关性,习惯上先进行标准化 ( 即去除均值并缩放方差),然后对输入进行主成分分析分解。


To train the machine learning model, in this example just a shallow neural network, we assume that the regular season data contain enough information to predict the outcome of playoff matchups, which is a bit of a stretch but not too crazy either.
为了训练机器学习模型,在这个例子中,我们只是一个浅层的神经网络,我们假设常规赛季的数据包含足够的信息来预测季后赛对决的结果,这虽然有些困难,但也不太疯狂。
Model: "DNN_regresson" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_69 (InputLayer) [(None, 32)] 0 _________________________________________________________________ dense_185 (Dense) (None, 32) 1056 _________________________________________________________________ dropout_98 (Dropout) (None, 32) 0 _________________________________________________________________ dense_186 (Dense) (None, 16) 528 _________________________________________________________________ dropout_99 (Dropout) (None, 16) 0 _________________________________________________________________ dense_187 (Dense) (None, 14) 238 ================================================================= Total params: 1,822 Trainable params: 1,822 Non-trainable params: 0 _________________________________________________________________From a technical perspective, one has to create an array of input examples and the corresponding labels. Naively, one may think the most obvious way to predict the results of the matchup is to ask the model to output the number of games won by each team, e.g. 4–1, 2–4, etc. As a matter of fact, this sort of multi-dimensional prediction is not necessary and in general can give rise to impossible results such as 3–3, 1–3, etc. The problem can be simplified significantly by realizing that the number of possible outcomes is finite. For example, since each series has to end at the best-of-seven (or best-of-five in the first round until 2005), only the following ones are allowed and hence can be encoded in a map:
从技术角度来看,必须创建一系列输入示例和相应的标签。 天真的,可能会想到预测比赛结果的最明显方法是让模型输出每个团队赢得的比赛数, 例如 4-1、2-4等。事实上,这多维预测是不必要的,通常会产生诸如3–3、1–3等不可能的结果。通过意识到可能的结果数量有限,可以大大简化该问题。 例如,由于每个系列都必须以七个最佳(或直到2005年的第一轮最佳)结束,因此仅允许以下序列,因此可以在地图中进行编码:
valid_results = [(3,0), (3,1), (3,2), (4,0), (4,1), (4,2), (4,3), (3,4), (2,4), (1,4), (0,4), (2,3), (1,3), (0,3)]result_to_idx = {res: i for i, res in enumerate(valid_results)}
idx_to_result = {i: res for i, res in enumerate(valid_results)}This way, we can ask the network to output the softmax probability of each of the 14 possible outcomes. This way, no impossible results can be obtained as output. The loss function in this case is sparse_categorical_crossentropy, which is basically a categorical_crossentropy which does not need to represent the labels as one-hot vectors but just as integer numbers, in this case corresponding to the index of the valid games results.
这样,我们可以要求网络输出14种可能结果中每一种的softmax概率 。 这样,就不可能获得不可能的结果作为输出。 在这种情况下,损失函数为sparse_categorical_crossentropy ,它基本上是categorical_crossentropy,不需要将标签表示为一个热向量,而只需将整数表示为整数,在这种情况下,它对应于有效游戏结果的索引。
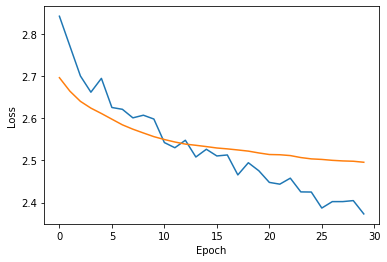
The network can be trained for a few tens of epochs and small batch size. The key feature in this kind of plots is the necessary agreement between the training and the validation losses.
可以训练该网络几十个纪元和小批量。 这种情节的关键特征是训练与验证损失之间的必要协议。
最终结果 (Final Results)
To get the final results, the trained network is called multiple times, one for each matchup. To start with, it is necessary to define the names of the teams confronting each other. Each name is converted to a integer representing an index, which in turn is used to get the input features for a given team and for a given year (in this case 2020).
为了获得最终结果,需要多次调用训练有素的网络,每次对决都调用一次。 首先,必须定义彼此面对的团队的名称。 每个名称都将转换为代表索引的整数,该索引又用于获取给定团队和给定年份(在本例中为2020)的输入特征。
first_round = [
["milwaukee bucks", "orlando magic"],
["miami heat", "indiana pacers"],
["boston celtics", "philadelphia 76ers"],
["toronto raptors", "brooklyn nets"],
["los angeles lakers", "portland trail blazers"],
["oklahoma city thunder", "houston rockets"],
["denver nuggets", "utah jazz"],
["los angeles clippers", "dallas mavericks"]]The program then calculates the outcome of the first round, and based on the results, creates a similar list for the Conference Semifinals, then Conference Finals, and the Finals.
然后,程序将计算第一轮的结果,并根据结果为会议半决赛,会议决赛和决赛创建相似的列表。
So…here’s the prediction:
所以……这是预测:
First Round
第一回合
- Milwaukee Bucks 4–3 Orlando Magic 密尔沃基雄鹿4–3奥兰多魔术
- Miami Heat 4–3 Indiana Pacers 迈阿密热火4-3印第安纳步行者
- Boston Celtics 4–1 Philadelphia 76ers 波士顿凯尔特人队4-1费城76人队
- Toronto Raptors 4–1 Brooklyn Nets 多伦多猛龙队4-1布鲁克林篮网
- Los Angeles Lakers 2–4 Portland Trail Blazers 洛杉矶湖人2–4波特兰开拓者队
- Oklahoma City Thunder 2–4 Houston Rockets 俄克拉荷马城雷霆2–4休斯顿火箭队
- Denver nuggets 2–4 Utah jazz 丹佛掘金2–4犹他爵士
- Los angeles Clippers 4–1 Dallas Mavericks 洛杉矶快船4-1达拉斯小牛
Conference Semifinals
会议半决赛
- Milwaukee Bucks 4–3 Miami Heat 密尔沃基雄鹿4-3迈阿密热火
- Boston Celtics 2–4 Toronto Raptors 波士顿凯尔特人2–4多伦多猛龙队
- Portland Trail Blazers 2–4 Houston Rockets 波特兰开拓者2–4休斯顿火箭
- Utah jazz 2–4 Los Angeles Clippers 犹他爵士2-4洛杉矶快船
Conference Finals
大会决赛
- Milwaukee Bucks 4–3 Toronto Raptors 密尔沃基雄鹿4–3多伦多猛龙队
- Houston Rockets 2–4 Los Angeles Clippers 休斯敦火箭2–4洛杉矶快船
Finals
决赛
- Milwaukee Bucks 4–1 Los Angeles Clippers 密尔沃基雄鹿4-1洛杉矶快船
So is this really the year of Giannis Antetokounmpo?
那么,今年真的是Giannis Antetokounmpo的一年吗?
翻译自: https://towardsdatascience.com/predicting-the-2020-nba-playoffs-bracket-with-machine-learning-2030f80fa62c
机器学习预测nba
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/64181.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

(十七)Mybatis自关联查询一对多查询

随机森林-科比生涯数据集分析与预测

python爬取NBA湖人队球星的数据,并且用Excel保存

基于HTML的静态网页的课程设计(NBA湖人队的网页设计)

雷神笔记本FN功能快捷键大全

雷神G150TH 拆机清理风扇

达人评测 雷神911mr怎么样

雷神911air 装黑苹果
springboot尚硅谷雷神学习笔记
怎样加速微软商店服务器,windows10系统如何加快应用商店打开速度【图文教程】...
怎么给雷神笔记本安装系统?
雷神台式计算机配置,雷神新用户手册:拿到新电脑时如何简易设置参数!

雷神台式计算机型号,【雷神台式机】雷神911黑武士III台式机评测,雷神台式机装机教程_什么值得买...
雷神之锤源码linux,雷神之锤3 的源代码查看
有关浏览器教程:开启加速模式

steam加速_玩转steam的新姿势:必备加速器推荐!
雷神电脑装linux双系统,雷神911Target(双显卡)双系统Ubuntu安装显卡驱动和CUDA

java 网游加速器源码_Java/C++算法与数据结构系列视频教程【源码+课件打包】
