论文地址:https://arxiv.org/pdf/2303.17568.pdf
相关博客
【自然语言处理】【大模型】CodeGen:一个用于多轮程序合成的代码大语言模型
【自然语言处理】【大模型】CodeGeeX:用于代码生成的多语言预训练模型
【自然语言处理】【大模型】LaMDA:用于对话应用程序的语言模型
【自然语言处理】【大模型】DeepMind的大模型Gopher
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
【自然语言处理】【chatGPT系列】大语言模型可以自我改进
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
一、简介
代码生成的目标是:给定人类意图的描述(例如:“写一个阶乘函数”),系统自动生成可执行程序。这个任务由来已久,解决的方案也层出不穷。近期,通过将程序看作是语言序列,利用深度学习的transformer架构进行建模,显著的改善了代码生成的质量。特别是当大规模的开源代码数据与大语言模型相结合。
OpenAI的12B模型CodeX证明了在数十亿行公开代码上预训练的大模型的潜力。通过使用生成式预训练的方式,CodeX能够很好地解决python中的入门级编程问题。研究显示,GitHub Copilot 88%的用户都表示编程效率提高了。随后,大量的代码大语言模型被开发出来,包括:DeepMind的AlphaCode、Salesforce的CodeGen、Meta的InCoder和Google的PaLM-Coder-540B。
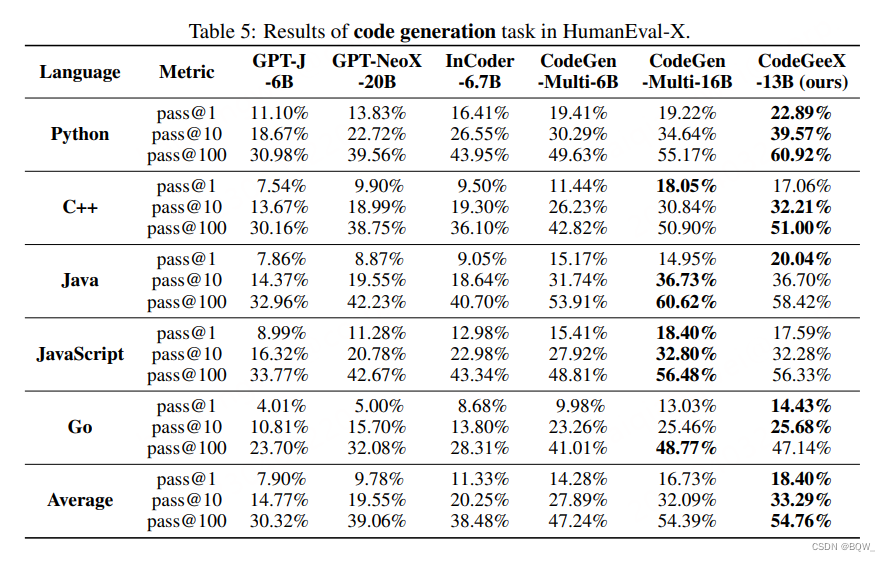
本文提出了13B参数量的多语言代码生成模型CodeGeeX,其是在23种编程语言上预训练的。该模型在具有1536个Ascend 910 AI处理器的集群上训练了2个月,共计训练了8500亿个tokens。CodeGeeX有以下的一些特性:(1) CodeGeeX不同于CodeX,其模型本身以及训练代码都是开源的,有助于理解和改进预训练代码模型。CodeGeeX也支持在Ascend和NVIDIA GPUs等不同平台上推理。(2) 除了代码生成和代码补全,CodeGeeX也支持代码解释和代码翻译。(3) 与知名的代码生成模型相比(CodeGen-16B、GPT-NeoX-20B、InCode-6.7B和GPT-J-6B),CodeGeeX的表现一致优于其他模型。
本文还开发了HumanEval-X基准来评估多语言代码模型,因为:(1) HumanEval和其他基准仅包含单个语言的编程问题;(2) 现有的多语言数据集使用BLEU这样的字符串相似度指标进行评估,而不是验证生成代码的正确性。具体来说,对于HumanEval中每个Python问题,都人工用C++、Java、JavaScript、GO来重写其prompt、标准解决方案和测试用例。总的来说,在HumanEval-X中包含了820个手写的"问题-解决方案对"。此外,HumanEval-X同时支持代码生成和代码翻译的评估。
二、CodeGeeX模型
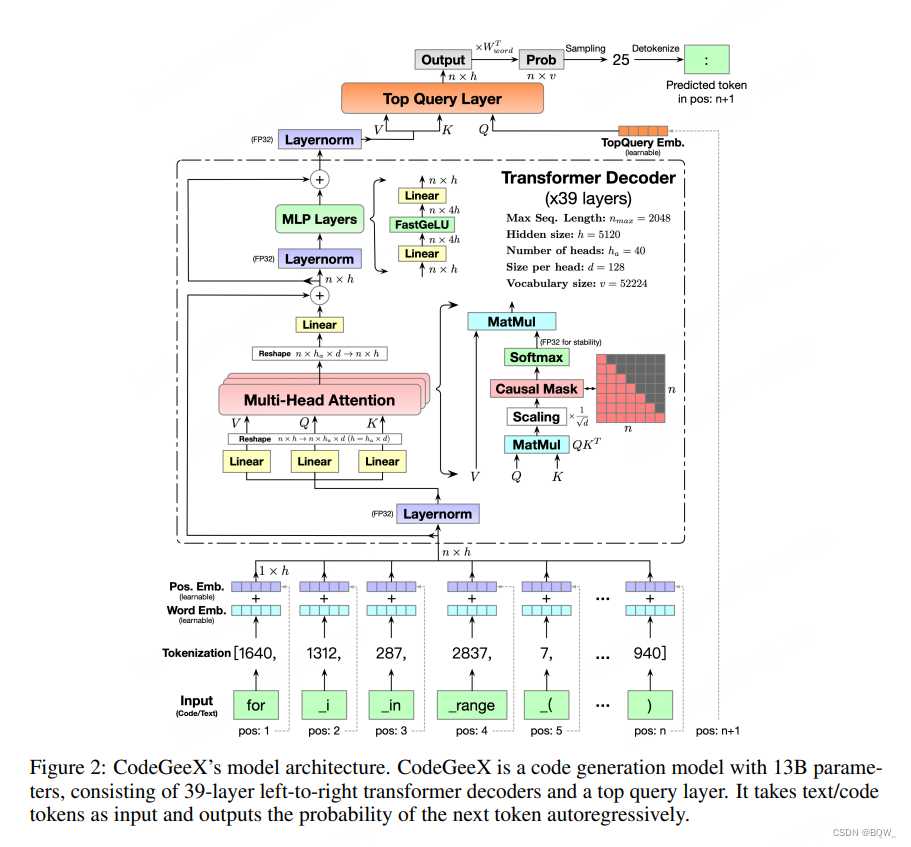
1.模型架构
Transformer Backbone。CodeGeeX使用纯解码器的GPT架构,并使用自回归语言建模。CodeGeeX的核心架构是39层的transformer解码器。在每个transformer层,包含:多头自注意力机制、MLP层、layer normalization和残差连接。使用类GELU的FaastGELU激活,其在Ascend 910 AI处理器上更加高效。
FastGELU ( X i ) = X i 1 + exp ( − 1.702 × ∣ X i ∣ ) × exp ( 0.851 × ( X i − ∣ X i ∣ ) ) (1) \text{FastGELU}(X_i)=\frac{X_i}{1+\exp(-1.702\times|X_i|)\times\exp(0.851\times(X_i-|X_i|))} \tag{1} FastGELU(Xi)=1+exp(−1.702×∣Xi∣)×exp(0.851×(Xi−∣Xi∣))Xi(1)
生成式预训练目标。采用GPT的范式,在大规模无监督代码数据上训练模型。总的来说,就是迭代地将代码token作为输入,预测下一个token并与真实的token进行比较。具体来说,对于长度为 n n n的任意输入序列 { x 1 , x 2 , … , x n } \{x_1,x_2,\dots,x_n\} {x1,x2,…,xn},CodeGeeX的输出都是下一个token的概率分布
P ( x n + 1 ∣ x 1 , x 2 , … , x n , Θ ) = p n + 1 ∈ [ 0 , 1 ] 1 × v (2) \mathbb{P}(x_{n+1}|x_1,x_2,\dots,x_n,\Theta)=p_{n+1}\in[0,1]^{1\times v} \tag{2} P(xn+1∣x1,x2,…,xn,Θ)=pn+1∈[0,1]1×v(2)
其中, Θ \Theta Θ表示所有参数, v v v是词表大小。通过将预测token与真实分布进行比较,可以优化交叉熵损失函数:
L = − ∑ n = 1 N − 1 y n + 1 log P ( x n + 1 ∣ x 1 , ) (3) \mathcal{L}=-\sum_{n=1}^{N-1}y_{n+1}\log \mathbb{P}(x_{n+1}|x_1,) \tag{3} L=−n=1∑N−1yn+1logP(xn+1∣x1,)(3)
Top Query层和解码。原始的GPT使用pooler函数来获得最终的输出。我们在所有transformer层上添加一个额外的查询层(华为"盘古"也使用了这种层)来获得最终的embedding。如上图所示,top query层的输入被替换为位置 n + 1 n+1 n+1的query embedding。最终的输出乘以词嵌入矩阵的转置来获得输出概率分布。对于解决策略,CodeGeeX支持贪心、温度采样、top-k采样、top-p采样和beam search。
2. 预训练设置
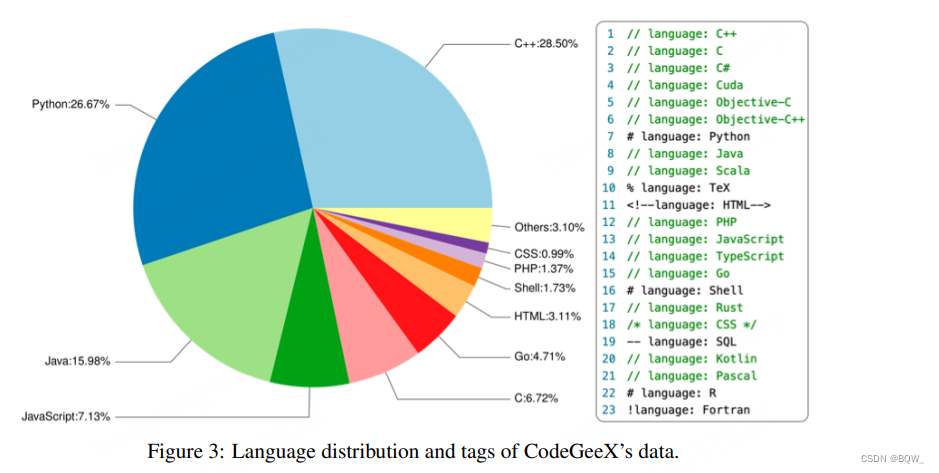
代码语料。训练语料包含两个部分。第一部分是开源代码数据集:Pile和CodeParrot。第二部分是直接从GitHub爬取的Python、Java和C++代码,用于补充第一部分。选择的代码仓库至少有一个star且小于10MB,然后过滤文件:(1) 每行超过100个字符;(2) 自动生成的;(3) 字母比例小于40%的;(4) 大于100KB或者小于1KB的。上图展示了训练数据中23种编程语言的占比。训练数据会被划分为等长的片段。为了帮助模型区分多种语言,在每个片段前添加了语言相关的标签,例如:language: Python。
Tokenization。考虑到代码数据中有大量的自然语言注释且变量、函数、类别的命名通常也是有意义的单词,因此将代码数据也做文本数据并使用GPT-2 tokenizer。初始词表尺寸为50000,并将多个空格编码为额外的tokens来增加编码效率。具体来说,L个空白符被表示为<|extratoken_X|>,其中X=8+L。由于词表包含各种语言的tokens,这允许CodeGeeX处理各种语言的token,例如中文、法语等。最终的词表尺寸为 v = 52224 v=52224 v=52224。
词嵌入和位置嵌入。词嵌入矩阵表示为 W w o r d ∈ R v × h W_{word}\in\mathbb{R}^{v\times h} Wword∈Rv×h,位置嵌入矩阵表示为 W p o s ∈ R n m a x × h W_{pos}\in\mathbb{R}^{n_{max}\times h} Wpos∈Rnmax×h,其中 h = 5120 h=5120 h=5120和 n m a x = 2048 n_{max}=2048 nmax=2048。每个token都对应一个可学习的词嵌入 x w o r d ∈ R h x_{word}\in\mathbb{R}^h xword∈Rh以及一个可学习的位置嵌入 x p o s ∈ R h x_{pos}\in\mathbb{R}^{h} xpos∈Rh。两个嵌入相加得到输入的嵌入向量 x i n = x w o r d + x p o s x_{in}=x_{word}+x_{pos} xin=xword+xpos。最终,整个序列被转换为嵌入矩阵 X i n ∈ R n × h X_{in}\in\mathbb{R}^{n\times h} Xin∈Rn×h, n n n是序列长度。
3. CodeGeeX训练
Ascend 910并行训练。CodeGeeX在Ascend 910 AI处理器(32GB)的集群上使用Mindspore进行训练。训练在192个节点的1526个AI处理器上进行了2个月。共计消耗了850B的tokens,约为5个epochs(213000steps)。为了提高训练效率,采用8路模型并行和192路数据并行,并使用ZeRO-2优化器来进一步降低显存消耗。最终,每个节点上的micro-batch size为16,全局batch size为3072。
具体来说,使用Adam优化器来优化loss。模型权重采用FP16的格式,为了更高的精度和稳定性layer-norm和softmax使用FP32。模型占用GPU显存为27GB。初始学习率为1e-4,并应用cosine学习率调度:
l r c u r r e n t = l r m i n + 0.5 ∗ ( l r m a x − l r m i n ) ∗ ( 1 + cos ( n c u r r e n t n d e c a y π ) ) (4) lr_{current}=lr_{min}+0.5*(lr_{max}-lr_{min})*(1+\cos(\frac{n_{current}}{n_{decay}}\pi)) \tag{4} lrcurrent=lrmin+0.5∗(lrmax−lrmin)∗(1+cos(ndecayncurrentπ))(4)
下表示详细的训练参数。
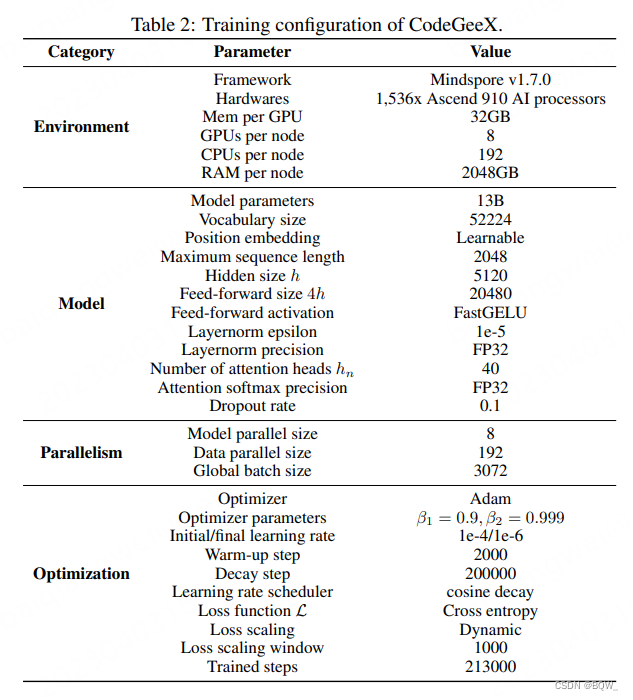
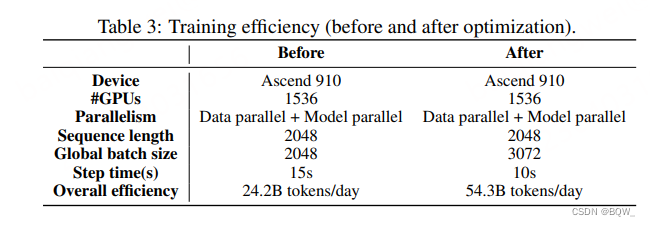
训练效率优化。为了优化Mindspore框架来释放Ascend 910的潜力。采用了两项技术来显著改善训练效率:(1) 核融合(Kernel fusion);(2) Auto Tune optimization。下表是优化前和优化后的对比。
4. 快速推理
量化。应用post-training量化技术来降低CodeGeeX推理时的显存消耗。使用absolute maximum量化将所有线性层的权重 W W W从FP16转换为INT8:
W q = Round ( W λ ) , λ = Max ( ∣ W ∣ ) 2 b − 1 − 1 (5) W_q=\text{Round}(\frac{W}{\lambda}),\lambda=\frac{\text{Max}(|W|)}{2^{b-1}-1} \tag{5} Wq=Round(λW),λ=2b−1−1Max(∣W∣)(5)
其中 b b b是比特宽度, b = 8 b=8 b=8。 λ \lambda λ是缩放因子。
加速。经过8bit量化后,使用NVIDIA的FasterTransformer实现了更快版本的CodeGeeX。
三、HumanEval-X基准
HumanEval基准类似于MBPP和APPS,仅包含手写的Python编程问题,并不能直接应用于多语言代码生成的系统性评估。因此,本文开发了一个HumanEval的多语言变体,HumanEval-X。HumanEval中的每个问题都是用Python定义的,我们用C++、Java、JavaScript和Go重写了prompt、标准解决方案和测试用例。在HumanEval-X中共有820个"问题-解决方案对"。
任务。HumanEval-X会评估2个任务:代码生成和代码翻译。代码生成任务将函数声明和文本描述作为输入,并生成函数的实现代码。代码翻译任务将源语言实现的解决方案作为输入,并生成目标语言的对应实现。
度量(Metric)。使用测试用例来评估生成代码的正确性并衡量其pass@k。具体来说,使用无偏方法来估计pass@k:
pass@k : = E [ 1 − ( n − c k ) ( n k ) ] , n = 200 , k ∈ { 1 , 10 , 100 } (6) \text{pass@k}:=\mathbb{E}[1-\frac{\left(\begin{array}{l}n-c \\ k\end{array}\right)}{\left(\begin{array}{l}n \\ k\end{array}\right)}],\quad n=200,k\in\{1,10,100\} \tag{6} pass@k:=E[1−(nk)(n−ck)],n=200,k∈{1,10,100}(6)
其中 n n n是生成的总数(200),k是采样数量, c c c是通过所有测试用例的样本数量。
四、CodeGeeX评估
- 多语言代码生成
- 多语言代码翻译