情感脑机接口与跨被试情感模型问题研究
- 基于最大分类器差异域对抗方法的跨被试脑电情绪识别研究
- 引言部分关键要点提取
- MCD_DA 模型解读
- 数据集创建以及处理
- 模型训练步骤
- 实验结果
- Multisource Transfer Learning for Cross-Subject EEG Emotion Recognition
- RELATED WORK
- METHODS
- Source Selection
- Style Transfer Mapping
- Mapping Origin and Destination
- Confidence Setup
- Algorithm Implementation
- 数据处理
- Baseline Method
- Transfer Learning With Multisource STM
- 结果
- Generalizing to Unseen Domains:A Survey on Domain Generalization
- Introduction
- Background
- Theory
- Domain generalization
- Methodology
- Data manipulation
- Representation learning
- Domain-invariant representation learning
- Kernel methods
- Domain adversarial learning
- Explicit feature alignment(显式特征对齐)
- Invariant risk minimization(IRM)
- Feature disentanglement-based DG(基于特征消除纠缠的DG):
- Learning strategy
基于最大分类器差异域对抗方法的跨被试脑电情绪识别研究
论文发表杂志:生物医学工程学杂志
论文发表日期:2021年6月

这篇文章为了解决跨被试,跨时间情绪分类的问题,提出了最大分类器差异域对抗方法(MCD_DA),通过建立神经网络情感识别模型,将浅层特征提取器分别对抗域分类器和情感分类器,进而使特征提取器产生域不变表达,在实现近似联合分布适配的同时训练分类器学习任务特异性的决策边界。实验结果表明,相较于通用分类器58.23%的平均分类准确率,该方法的平均分类准确率达到了88.33%。(疑问:这个平均分类准确率是在哪个数据集上做的,实验范式是什么)(答:SEED上的留一被试交叉验证)
引言部分关键要点提取
- 域适应是迁移学习的一个子领域 ,该研究的目标是降低不同域之间差异的同时,保持不同类别的判别信息
- 早期的预适应方法倾向于减小源域和目标域在特定空间的距离。(论文:郑伟龙2016年一篇文章,做的是直推式参数迁移,暂未找到),这篇文章的目的是最小化源域和目标与的最大平均偏差来适配边缘分布,SEED上能做到76.32%左右。
- JIN等人利用域对抗神经网络建立跨被试情感识别模型,通过特征提取器与域分类器的对抗减小域间距离,在SEED上做到了79.19%左右(论文地址(暂时无法下载)) 。这里想要补充的一点是,如果这样说,加入了DANN的方法相比直推式参数迁移的方法也没提升多少点。
- 针对早期域适应算法的问题,Li等人提出了一种联合分布自适应算法,使用对抗性训练适浅层边缘分布,并通过关联增强适应最后一层的条件分布,通过同时调整边缘分布和条件分布近似地调整联合分布,在SEED上做到了86.7%,为近年来最好的结果(域适应,联合分布自适应算法,到2021年6月为止,是SEED上做的最好的结果)。缺点:需要定义多种类型的损失值,各种损失值在最终的损失函数中的权重需要多次训练才能确认,从而带来训练调试中的困难,对不同的被试往往需要长时间的调参才能获得较好的分类结果。(这个就属实有点阴间,通过大量实验去确定多个损失的权重)
- 一句话概括这篇文章提出的最大分类器差异的域对抗:通过最大化两个包含源于条件分布信息的不同分类器间差异,寻找被源域排斥的目标域样本特征,在一分类器差异最小化为目标训练特征提取器,重新生成符合源域条件分布的特征,从而适配条件分布。
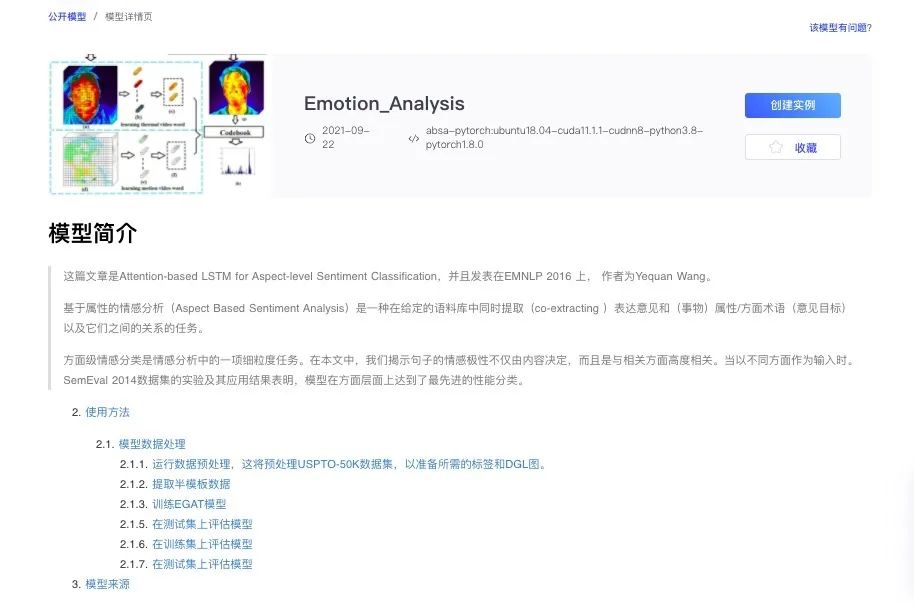
MCD_DA 模型解读

图中F(feature extractor)为特征提取器,C1,C2为情绪分类器,D为域分类器。F对于源域和目标域是共享权重的,未来对目标域的样本做出可靠的预测,F,C1,C2的更新准则不仅要来自源域的有标签样本进行情感分类,而且要尽可能地使源域与目标域更为相似(包括边缘分布和条件分布)。考虑到较浅地层倾向于生成任务不变特征,而较深地层更可能生成特定于任务的特征,在较浅的层F后设计了域分类器D,用于构建DANN。D是一个判断特征向量属于源域还是目标域的二元分类器,在前馈过程中,它是一个普通的分类器,而在反向传播过程中,她迫使F生成具有域不变性质的特征,这是通过D中的梯度反转层实现的。
数据集创建以及处理
- SEED:15个受试者,每个受试者5组3种情绪的实验,一共3次实验,所以是15×3×15=675组脑电数据。选择DE作为输入特征,DE样本维数:62×5=310
- 随机选取了5000源域样本作为训练数据,训练集中还包括目标域全部3394个未标记的数据。为加速神经网络输入收敛,所有输入特征进行归一化处理
- 深度网络主体采用多层感知机,相较于卷积神经网络等能获得更好的域适应效果。
模型训练步骤
- 步骤A:在尽可能拉近源域和目标域距离的前提下减少在源域的情绪分类损失。由于优化的侧重点不同,网络在这一步种使用了两种不同的参数更新方法。对于F,D,不是为了适应分类任务而特意优化的,而是为了使两个域的浅层输出特征在统计上相似。F,D的优化策略如下:




C1,C2的优化策略如下:

2. 步骤B:在这一步种,同样类比GAN,训练两个较深层的分类器C1,C2作为鉴别器,F作为生成器。训练分类器学习最大化目标样本差异:固定F的参数,训练两个不用类别的分类器C1,C2,使其目标域数据的预测差异最大,从而可以检测到目标域决策边界附近的样本。

步骤C:为了消除目标域决策边界附近的样本的模糊特征,使得模型重新生成任务的特异性特征,训练模型学习最小化分歧。

实验结果
基于MCD_DA的留一被试交叉验证。被试7的准确率最高(98.43%),被试3的准确率最低(74.57%),15个平均被试准确率为(88.33±5.86)%。(这里需要注意一下,我在另一篇2019年的硕士论文中看到域适应做法的WGANDA的留一被试结果在SEED做到了87.07%,这是一篇21年的文章,可见其实提示的点数并不多,只有1个点左右,不过两篇文章都做出了DANN为78%左右的效果,这个可以得到论证)
Multisource Transfer Learning for Cross-Subject EEG Emotion Recognition
多源迁移学习在跨被试脑电情绪识别中的应用
论文来源:IEEE TRANSACTIONS ON CYBERNETICS 时间:2020.6
这篇论文适用的情况是,有目标域少量的标记数据可以参与到训练中。
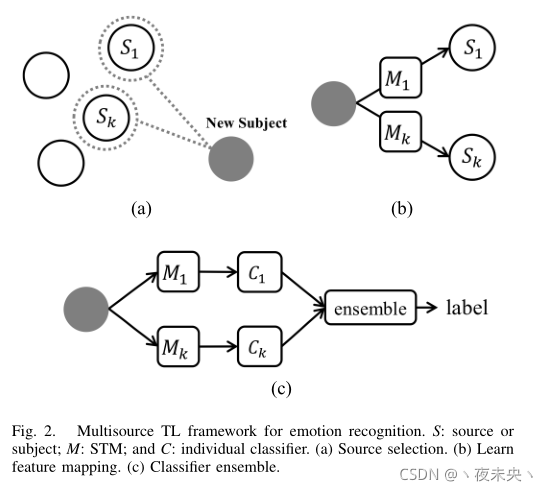
简单地说一下这篇文章地总体思路。首先我们需要获取目标域的有标签数据,把这些数据分为calibration sessions(校正集)和test sessions(测试集),校正集的数据量要远远小于验证集的数据量。因为作者也考虑到如果放到实际系统中,要尽可能减少新被试调整模型的时间,所以只需要少量的校正集数据用于微调模型就好了。然后怎么做呢?拿到一个新被试的数据,先要选出几个源域的合适的源数据,加上新被试的校正集数据去学一个映射关系style transfer mapping(STM)。在跑新被试的测试集的时候先用学到的STM映射关系transform一下,最后得到label的时候还用了集成学习,选了两个分类器 C 1 C_{1} C1, C 2 C_{2} C2来综合得到测试集的label。
RELATED WORK
在BCI中存在两种类型的泛化问题。
- 对于一个人来说,几个session所做的实验数据,虽然大致上会表现出一致性,但session之间肯定会存在非平稳性和差异性。说白了,就是你今天通过被刺激(例如电影)产生的情绪脑电信号和明天被同一刺激产生的情绪脑电信号未必一样。
- 跨被试,这个很好理解。
最常用的三类迁移学习方法:
3. 样本迁移。从源域中选择“加权”样本
4. 特征迁移。
5. 参数迁移
METHODS
Source Selection

A.就说我们先用源域数据训练出N个分类器来,然后用目标域数据的校准集跑一边,选出其中s个accuracy最高的分类器,然后学一个feature mapping function,在最后跑测试集的时候这几个分类器的要一起得出一个结果,每个分类器对得出结果中产生的权重由一开始他们跑校正集的accur决定(典型的集成学习)
补充,关于迁移学习的分类问题,什么是inductive transfer method?什么是transductive transfer method?
迁移学习技术概述(分类图很重要)
Style Transfer Mapping
先铺垫几个概念:
destination and origin: call the representational patterns(prototypical clustering centers,class mean values) in A S p A^{Sp} ASp the “destination,” and samples in A T A^{T} AT the “origin.”
D:The destination point set is noted as D = { d i ∈ R m ∣ i = 1 , . . . , n } D=\left \{ d_{i}\in R^{m}| i=1,...,n \right \} D={di∈Rm∣i=1,...,n},D is composed of the representational patterns of A S p A^{Sp} ASp
O:The mapping origin of STM is O = { o i ∈ R m ∣ i = 1 , . . . , n } O=\left \{ o_{i}\in R^{m}| i=1,...,n \right \} O={oi∈Rm∣i=1,...,n}
如何学习一个映射关系,我们假设这个映射关系为: A o i + b , A ∈ R m ∗ m , b ∈ R m Ao_{i}+b,A\in R^{m*m},b\in R^{m} Aoi+b,A∈Rm∗m,b∈Rm,则有

至于如何计算,论文中有公式,可以直接用,这不是理解的重点。
到这一步,我们知道了如何计算一个映射关系。
Mapping Origin and Destination
如何定义mapping destination A S p A^{Sp} ASp?
假设有M种情绪,先train M(M-1)/2种SVMs出来,然后使用一对一投票策略进行SVMs的组合。我倾向于这样做是便于它找到划分好4个类的几个超平面出来,超平面出来之后才好确定聚类中心和类均值。超平面的个数也是M(M-1)/2。
将超平面找出来后,因为支持向量是位于各个超平面上的点,这意味着它们是最不好分类的,所以在源分类器训练之后要除去支持向量。
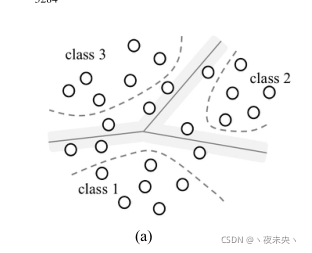
prototype(原型),也可以理解为聚类里面每个类的质心。
如何定义destination point of a sample x ∈ R m x\in R^{m} x∈Rm ?
第一种方式:Nearest Prototype这部分理解了挺长时间,画图说明一下。


一个类里面可能有很多个聚类中心,当我们得到一个新的origin的时候,就找它属于的那个类的离它最近的聚类中心的质心,所以才会有上图中类似 o 1 o_{1} o1离那么远去找 p 11 p_{11} p11作为destination的原因,因为它本身是一类的, p 12 p_{12} p12离它更远。
第二种方式:Gaussian Model


看图已经很明白是怎么找destination的了,假设每一个类是一个Gaussian Model,destination就位于origin和 μ \mu μ的连线和分布边界的焦点。
Confidence Setup
这里有两种策略来计算STM:
- 只使用目标域中的有标签数据的有监督方法,这是一种推导式迁移学习策略
- 既使用目标域中的有标签数据,也使用目标域中的无标签数据的半监督方法,这是一种直推式迁移学习策略
在监督学习中,我们不需要设置置信度,换句话说置信度为1.在半监督学习中,置信度非常重要。对于未标记的数据,我们需要推导出他的标签,并在相应的类中找到映射的目的地。如果推导出的标签是错误的,STM将会将数据映射到错误的目的地。
我们上文中介绍了,要计算STM先得知道origin的标签,是属于哪个类,这样才能去找origin的这个类离它最近的聚类中心 p i j p_{ij} pij。但如果origin没有标签呢?这里的置信度其实就是在算伪标签的可信度。针对目标域中无标签的数据,我们只有先给一个伪标签出来才能进一步计算STM。
下面介绍三种置信度的设置方式:

dist1 is the distance between the datum and its nearest prototype (e.g., in class 1), and dist2 is the distance between the datum and its nearest prototype in the rest of the classes (e.g.in class 2). The larger the value dist2−dist1 is, the higher confidence we gain when deducing its label.
The confidence is defined as:
F ( x ) = ψ ( d i s t 2 − d i s t 1 ) F\left ( x \right )=\psi \left ( dist2-dist1 \right ) F(x)=ψ(dist2−dist1)
ψ ( c ) = 1 1 + e θ c + π \psi \left ( c \right )=\frac{1}{1+e^{\theta c+\pi }} ψ(c)=1+eθc+π1
The two parameters are determined by cross-validation. For simplicity ,we designate θ \theta θ as -1 and τ \tau τ as 1.

计算方式和第一种一样,就是这次用x和高斯模型均值计算距离而不是x和prototypes(最近点)计算距离。
第三种计算置信度的方式如下:

The distances between a datum x ∈ R m x\in R^{m} x∈Rm and each hyper-planes are
d i s t i = W i x + b i ∥ W i ∥ 2 dist_{i}=\frac{W_{i}x+b_{i}}{\left \| W_{i} \right \|^{2}} disti=∥Wi∥2Wix+bi
c = ∑ w i d i s t i c=\sum w_{i}dist_{i} c=∑widisti
F ( x ) = ψ ( c ) F\left ( x \right )=\psi \left ( c \right ) F(x)=ψ(c)
Algorithm Implementation


数据处理
DE特征,切割为1s片段没有overlap,数据预处理方式基本是常规方式。
Baseline Method
使用集成分类器作为基线方法,并且使用投票加权策略整合分类器,投票权重由新受试者校准数据的分类准确率决定。15名受试者的留一被试实验的平均准确率为76.2%
Transfer Learning With Multisource STM
使用K-means++为每种情感找出15个聚类中心,并重复10次聚类操作来寻找可靠的聚类中心。
结果

No SV:支持向量被去除了,SV 支持向量被保留下来了。
总的来说,留一被试的结果,只用少量的被试有标签数据最好的做到了88.92%,少量被试有标签加大量无标签最好做到了91.31%。
接下来是几篇关于域适应(Domain Adaption)和域泛化(Domain Generalization)的文章,和脑机无关。
Generalizing to Unseen Domains:A Survey on Domain Generalization
Categorize recent algorithms into three classes:
- data manipulation
- representation learning
- learning strategy
Introduction
第二节:阐述了域泛化问题,并讨论了它与现有研究领域的关系。
第三节:展示了域泛化的相关理论。
第四节:讲了几个有代表性的DG方法。
第五节:讲了一些应用
第六节:讲了DG的一些基准数据集
第七节:讲了现有工作的见解和未来工作的展望。
Background



- Multi-task learning:联合优化多个模型在多个相关的任务上,通过在这些任务之间分享representations,我们能够使得模型在原任务上得到更好的泛化性。但必须要注意的一点是,多任务学习的目的不是为了在一个new unseen task上得到更好的泛化性。它在多个相关域上训练的原因是为每个原始领域学习好的模型,而不是新的测试域。
- Transfer learning:在源域上训练一个模型期望在目标域上得到好的performance,在DG中,不能访问目标域
- Domain adaptation:DA的目标也是在给定训练源域的情况下希望训一个在目标域上跑的好的模型出来。但是DA和DG不同的是,DG不能看目标域数据,而DA可以看目标域数据,这使得DG比DA更具挑战性,但在实际应用中更现实、更有利
- Meta-learning:目的通过以前的经验或任务中学习算法本身。metal-learning中学习任务是不同的,但是DG中的学习任务是相同的。Meta-learning 是一种可以被用在DG上的广泛的学习策略。
- Lifelong Learning:关注的是在多个相继领域/任务之间的学习能力。要求模型学习新知识/经验的同时保留旧知识。它也可以看源域数据。
- Zero-shot learning:目的是从看的见的类中学习模型,对训练中看不见类别的样本进行分类。
- Distributionally Robust optimization(DRO):在最坏分布情况下学习一个模型希望能够在测试集上泛化能力比较强。这个方法关注的是优化过程,DRO可以用于DG,但是DG也可以不用DRO,而用data manipulation 或者representation learning的方法解决。
Theory
Domain generalization
域泛化理论考虑的是目标域完全不知道并测量所有可能的目标域的平均风险。


The space of h h his taken as a reproducing kernel Hilbert space(RKHS)
分类器h也依赖于分布 P x Px Px,因此RKHS的内核应该定义为 k ˉ ( ( P X 1 , x 1 ) , ( P X 2 , x 2 ) ) \bar{k}\left ( \left ( P_{X}^{1},x_{1} \right ),\left ( P_{X}^{2},x_{2} \right ) \right ) kˉ((PX1,x1),(PX2,x2))
Methodology
Data manipulation
侧重于从数据出发,帮助学习更加一般的representation。一般有两种技术:Data augmentation和Data generation.
We formulate the general learning objective of data manipulation-based DG as:

- Domain randomization:It is commonly done by generating new data that can simulate complex environments based on the limited
training samples.such as: altering the location and texture of objects, changing the number and shape of objects, modifying the illumination and camera view, and adding different types of random noise to the data.- Adversarial data augmentation:Adversarial data augmentation aims to guide the augmentation to optimize the generalization capability, by enhancing the diversity of data while assuring their reliability.
例如有人利用贝叶斯网络对标签、领域和输入实例之间的依赖关系进行建模,提出了一种谨慎的数据增强策略CrossGrad,该策略沿着领域变化最大的方向扰动输入,同时尽可能少地改变类别标签。有人提出了一种迭代过程,利用当前模型下“硬”的虚拟目标域中的样本来扩充源数据集,在每次迭代中添加对抗性的样本,以实现自适应的数据扩充。有人相反地训练变换网络进行数据扩充,而不是通过梯度上升直接更新输入。
- Data generation-based DG:Here, the function mani(·)can be implemented using some generative models
such as V ariational Auto-encoder (V AE) , and Generative Adversarial Networks (GAN) .

除了上述生成模型之外,Mixup也是一种流行的数据生成技术。Mixup通过使用从Beta分布采样的权重在任意两个实例之间以及它们的标签之间执行线性插值来生成新数据,这不需要训练生成模型。最近,有几种使用DG的Mixup的方法,通过在原始空间中执行Mixup来生成新样本,或者在特征空间中执行Mixup来生成原始训练样本,该特征空间不显式地生成原始训练样本,这些方法在流行的基准测试中取得了令人满意的性能,同时在概念和计算上都保持简单。
Representation learning
这类方法是域泛化中最流行的,也有两种代表技术:Domain-invariant representation techniques和Feature disentanglement
Domain-invariant representation techniques:执行核,对抗性训练,域之间的显示特征对齐或不变风险最小化来学习域不变特征
Feature disentanglement:试图将特征分解成域共享或域特定的部分,以获得更好的泛化。
We decompose the prediction function h as f ∘ g f\circ g f∘g,where g is a representation learning function and f is the classifier function. The g is a representation learning can be formulated as:

where l r e g l_{reg} lreg denotes some regularization term and λ \lambda λ is the tradeoff parameter.
Domain-invariant representation learning
Kernel methods
基于核的机器学习依赖于核函数将原始数据变换到高维特征空间,而不需要计算该空间中数据的坐标,而是简单地计算特征空间中所有对样本之间的内积。
最有代表性的就是SVM。对于域泛化来说,大量的算法基于核方法,representation learning function g g g可以用一些核函数,比如RBF核,Laplacian核。

Domain adversarial learning
基于GAN的方法
【1】V . K. Garg, A. Kalai, K. Ligett, and Z. S. Wu, “Learn to expect the unexpected: Probably approximately correct domain generalization,” arXiv preprint arXiv:2002.05660, 2020.
【2】A. Sicilia, X. Zhao, and S. J. Hwang, “Domain adversarial neural networks for domain generalization: When it works and how to
improve,”arXiv preprint arXiv:2102.03924, 2021.
【3】I. Albuquerque, J. Monteiro, T. H. Falk, and I. Mitliagkas, “Adversarial target-invariant representation learning for domain generalization,”arXiv preprint arXiv:1911.00804, 2019.
Explicit feature alignment(显式特征对齐)
周等人通过最小化Wasserstein距离来对齐不同源域的边缘分布,从而获得域不变的特征空间。
F. Zhou, Z. Jiang, C. Shui, B. Wang, and B. Chaib-draa, “Domain generalization with optimal transport and metric learning,”ArXiv, vol.
abs/2007.10573, 2020.
BN层被批处理-实例归一化(BIN)层取代,BIN层通过选择性地使用BN和IN自适应地平衡每个通道的BN和IN。
H. Nam and H.-E. Kim, “Batch-instance normalization for adaptively style-invariant neural networks,” inNeurIPS, 2018, pp. 2558–2567.
这里主要讲了一个叫Instance Normalization的方法,结合Instance Normalization的各种方法。
Invariant risk minimization(IRM)
有点难理解
Feature disentanglement-based DG(基于特征消除纠缠的DG):
基于解纠缠的域泛化方法通常可以将特征分解为可理解的组合/子特征,其中一个特征是域共享或者不变的特征,另一个特征是每个域自己的特定特征。
基于解纠缠的域泛化算法的优化目标可以概括为:

g c g_{c} gc:domain-shared representations
g s g_{s} gs:domain-specific representations
The loss l r e g l_{reg} lreg显式地鼓励分离共享域, The loss l r e c o n l_{recon} lrecon表示防止信息丢失地一个重建损失。
Note that [ g c ( x ) , g s ( x ) ] [g_{c}(x),g_{s}(x)] [gc(x),gs(x)]denotes the combination/integration of two kinds of features(which is not limited to concatenation operation)
基于解纠缠的方法主要有两种,multi-component analysis and generative modeling

Peng et al. disentangled the fine-grained domain information and category information that are learned in VAEs.
[1]X. Peng, Z. Huang, X. Sun, and K. Saenko, “Domain agnostic learning with disentangled representations,” in ICML, 2019.
[2]M. Ilse, J. M. Tomczak, C. Louizos, and M. Welling, “Diva: Domain invariant variational autoencoders,” in Proceedings of the Third Con-ference on Medical Imaging with Deep Learning, 2020.
Learning strategy
这类方法侧重于开发通用学习策略来提高泛化能力,主要包括三种方法:
Ensemble learning:依靠集成的能力学习统一的、广义的预测函数;
Meta-learning:基于学习-学习机制,通过构造元学习任务来模拟领域转移来学习一般知识;
Gradient:试图通过直接对梯度进行操作来学习泛化表示。此外,还有其他的学习策略也可以用于DG,我们将它们归类为其他学习策略。