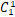试着自己做了下爬虫,从星座屋网站爬取十二星座30天的运势数据。
import requests
from bs4 import BeautifulSoup
import pandas as pd#获取12星座的网址
urll='http://www.xzw.com'
r=requests.get(url='http://www.xzw.com/fortune/aries/')
soup=BeautifulSoup(r.text,'lxml')
a=soup.find('div',class_="card_xingzuo").find_all('a')
urllst=[]
for each in a:urllst.append(urll+each.get('href'))#获取每个星座30天的数据
datalst=[]
for ui in urllst:ri=requests.get(url=ui)soupi=BeautifulSoup(ri.text,'lxml')alst=soupi.find('div',class_="lday").find_all('a')urllst2=[]for each in alst:urllst2.append(urll+each.get('href'))for u in urllst2:r=requests.get(url=u)soup=BeautifulSoup(r.text,'lxml')dic={}lilst1=soup.find('div',class_="c_main")if lilst1 is None: #狮子座有一个网页是空的continueelse:lilst=lilst1.find_all('li')dic['星座']=lilst1.find('h4').textfor i in range(4):dic[lilst[i].text.replace(':','')]=lilst[i].find('em').get('style').split(':')[-1].replace(';','')for i in range(4,10):dic['字段'+str(i)]=lilst[i].textp=soup.find('div',class_="c_cont").find_all('p')for i in range(5):dic[p[i].find('strong',class_="p"+str(i+1)).text+'_文字']=p[i].find('span').textdatalst.append(dic)df=pd.DataFrame(datalst)#数据清洗
df['健康指数']=df['字段4'].str.split(':').str[-1]
df['商谈指数']=df['字段5'].str.split(':').str[-1]
df['幸运颜色']=df['字段6'].str.split(':').str[-1]
df['幸运数字']=df['字段7'].str.split(':').str[-1]
df['速配星座']=df['字段8'].str.split(':').str[-1]
df['短评']=df['字段9'].str.split(':').str[-1]
df['星座名称']=df['星座'].str.split('运势').str[0]
df['日期']=df['星座'].str.split('运势').str[-1]df.drop(['字段4'],axis=1,inplace=True)
df.drop(['字段5'],axis=1,inplace=True)
df.drop(['字段6'],axis=1,inplace=True)
df.drop(['字段7'],axis=1,inplace=True)
df.drop(['字段8'],axis=1,inplace=True)
df.drop(['字段9'],axis=1,inplace=True)
df.drop(['星座'],axis=1,inplace=True)#导出为excel表格
df.to_excel('C:/Users/del/Desktop/星座运势数据.xlsx')#词频分析
pl_cnz=df[df['星座名称']=='处女座']['综合运势_文字']
words=''.join(pl_cnz.values.tolist()) #将处女座的综合运势拼成一段话
#用在线语料库进行分词
words_clh='适合/v 放松/v 的/u 一天/r ,/w 今天/nt ........' ###句子太长,不粘过来了
wordslst=words_clh.split(' ')word_df=pd.DataFrame({'词性拆分':wordslst})
word_df['词']=word_df['词性拆分'].str.split('/').str[0]
word_df['词性']=word_df['词性拆分'].str.split('/').str[1]#统计各种名词出现的次数/频率
mc=word_df[word_df['词性']=='n']
word_count=mc['词'].value_counts()#导出为excel表格
word_count.to_excel('C:/Users/del/Desktop/result.xlsx')
导出为excel表格之后,复制result.xlsx的内容,通过在线制作词云分析。
得到下面的结果:

语料库在线
词云分析