现在用Python做爬虫很是盛行,在学Java的本人寻思着Java如何做爬虫。
本爬虫例子为体育彩票网http://www.sporttery.cn/


本例实现对“足球赛果开奖”的爬取;若要对体育彩票站其他页面爬取,稍微修改代码中URL规则即可;若要爬取非体彩网的其他网站,则需要重新分析其站结构,修改其爬取方式。
进入正题,编译器为intellij IDEA,大略分析工程构成,上图为其结构:

所含jar包:
第一类 jsoup包,为java爬取页面利器,传送门https://segmentfault.com/a/1190000007967145
第二类 poi包,将数据保存为本地word、excel等利器,传送门http://www.voidcn.com/article/p-odzwqxka-er.html
所含代码:
1.main类
完成对足球赛果开奖”页面分析,制定爬取规则。eg页面http://info.sporttery.cn/football/match_result.php?page=1&search_league=0&start_date=2018-10-21&end_date=2018-10-23&dan= 感兴趣同学可去分析下页面结构。
指挥DownloadWord对象将页面数据爬到中list中。
指挥SaveEveryRow对象将list数据保存本机Excel中。
package DownloadWord;import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;import java.lang.String;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Calendar;
import java.util.Date;
import java.util.List;public class Main {public static void main(String[] args) {int allRows = 0;SaveEveryRow save = new SaveEveryRow();HSSFWorkbook workbook = new HSSFWorkbook();HSSFSheet spreadsheet = workbook.createSheet("try");DownloadWord down = new DownloadWord();try {Date d1 = new SimpleDateFormat("yyyy-MM-dd").parse("2018-08-22");Date d2 = new SimpleDateFormat("yyyy-MM-dd").parse("2018-10-23");Calendar dd = Calendar.getInstance();dd.setTime(d1);while (dd.getTime().before(d2)) {SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");String str = sdf.format(dd.getTime());String url = "http://info.sporttery.cn/football/match_result.php?page=1&search_league=0&start_date=" + str + "&end_date=" + str+ "&dan=";if (down.getM_page(url) <= 0) {List lis = down.getTexts(url);save.Save(url, (ArrayList) lis,allRows,workbook,spreadsheet);allRows = allRows + lis.size();dd.add(Calendar.DAY_OF_YEAR, 1);}else{for(int j=1;j<=down.getM_page(url);j++){String u = "http://info.sporttery.cn/football/match_result.php?page="+j+"&search_league=0&start_date=" + str + "&end_date=" + str+ "&dan=";List lis = down.getTexts(u);save.Save(u, (ArrayList) lis,allRows,workbook,spreadsheet);allRows = allRows + lis.size();}dd.add(Calendar.DAY_OF_YEAR, 1);}}}catch (Exception e) {e.printStackTrace();}System.out.println("成功爬取到本机!");}
}2.DownloadWord类,需熟悉jsoup包中函数相关函数、对页面源码分析。
将爬取页面的信息保存到自己定义的ArrayList数据结构中.
package DownloadWord;import java.io.IOException;
import java.util.*;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;public class DownloadWord {private int rows;private int page;public List getTexts(String u){List list = new ArrayList();try {Document document = Jsoup.connect(u).get();Elements a = document.select(".m-tab").select("tr");rows = a.size()-2;for(int i = 0;i < rows;i++) {Elements b= a.get(i).select("td");Match e = new Match();e.setTime( b.get(0).text());e.setNum(b.get(1).text());e.setMatch(b.get(2).text());e.setVs(b.get(3).text());e.setMidScore(b.get(4).text());e.setFullScore(b.get(5).text());e.setConditon(b.get(6).text());list.add(e);}} catch (IOException e) {e.printStackTrace();}return list;}public int getM_page(String u) throws IOException {Document document = Jsoup.connect(u).get();Elements a = document.select(".m-page").select("li");page = a.size()-3;return page;}
}- SaveEveryRow类,需熟悉POI包中相关函数、对数据源字符串进行分割。
将ArrayList数据结构数据存放到本机excel文档中。
package DownloadWord;import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;import java.io.FileOutputStream;
import java.io.IOException;
import java.util.ArrayList;public class SaveEveryRow {private String[] STR;private static String outputFile = "D:\\try.xls";public void Save(String url, ArrayList lis, int allRows, HSSFWorkbook workbook, HSSFSheet spreadsheet) throws IOException {for (int i = 0; i<lis.size(); i++) {Match obj = (Match) lis.get(i);HSSFRow row = spreadsheet.createRow((short) i + allRows);HSSFCell cell0 = row.createCell((short) 0);cell0.setCellValue(obj.getTime());HSSFCell cell1 = row.createCell((short) 1);cell1.setCellValue(obj.getNum().substring(0, 2));HSSFCell cell2 = row.createCell((short) 2);cell2.setCellValue(obj.getNum().substring(2, 5));HSSFCell cell3 = row.createCell((short) 3);cell3.setCellValue(obj.getMatch());STR = obj.getVs().split("[()]", 3);HSSFCell cell4 = row.createCell((short) 4);cell4.setCellValue(STR[0]);HSSFCell cell5 = row.createCell((short) 5);cell5.setCellValue(STR[1]);HSSFCell cell6 = row.createCell((short) 6);cell6.setCellValue(STR[2].substring(2, STR[2].length()));HSSFCell cell7 = row.createCell((short) 7);cell7.setCellValue(obj.getMidScore());HSSFCell cell8 = row.createCell((short) 8);cell8.setCellValue(obj.getFullScore());HSSFCell cell9 = row.createCell((short) 9);cell9.setCellValue(obj.getConditon());}FileOutputStream out = new FileOutputStream(outputFile);workbook.write(out);out.flush();out.close();System.out.println(url);}
}4.Match类,竞赛基本信息类。
定义的各变量、get、set函数。
package DownloadWord;public class Match {private String time;private String num;private String match;private String vs;private String midScore;private String fullScore;private String conditon;public String getTime() {return time;}public void setTime(String time) {this.time = time;}public String getNum() {return num;}public void setNum(String num) {this.num = num;}public String getMatch() {return match;}public void setMatch(String match) {this.match = match;}public String getVs() {return vs;}public void setVs(String vs) {this.vs = vs;}public String getMidScore() {return midScore;}public void setMidScore(String midScore) {this.midScore = midScore;}public String getFullScore() {return fullScore;}public void setFullScore(String fullScore) {this.fullScore = fullScore;}public String getConditon() {return conditon;}public void setConditon(String conditon) {this.conditon = conditon;}
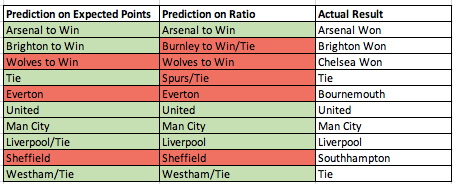
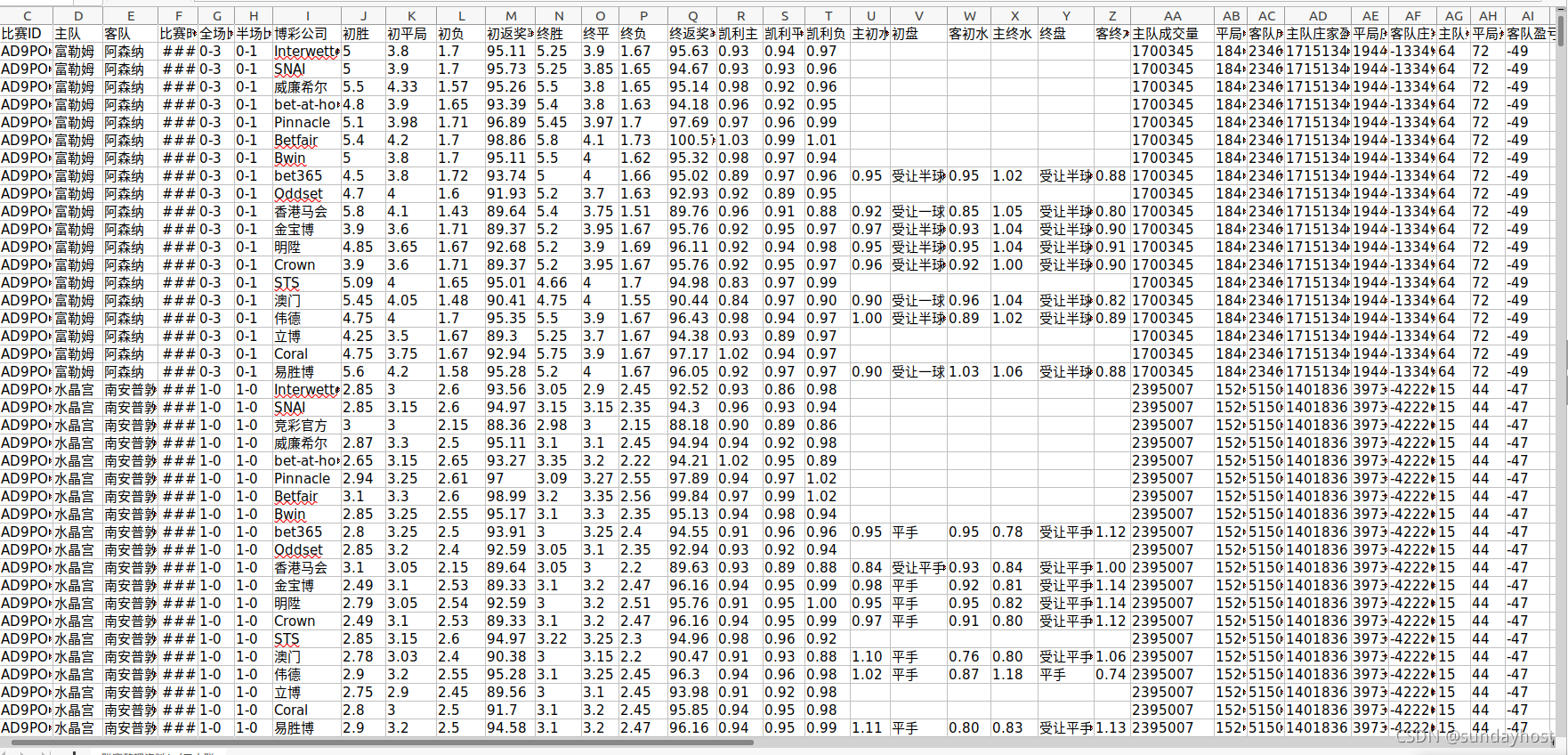
}效果:爬取足球竞彩结果8月22号到10月22号,一共2292条信息,存储到本机D:\try.xls文件中。(注意main方法引用的函数dd.getTime().before(d2)是指在d2时间前,即23号之前指22号、21号等等,所以d2应该多设置一天)
图为页面信息 共2292条信息

图为爬虫运行结束

图为保存到本地Excel,2292条完全保存。

结语:用java爬虫相对Python麻烦(好友飞哥的Python代码更简洁),但是亦可通过其java各类jar包所提供的功能丰富接口完工,这也是java强大的一点。
每当需要爬取一个站点时,需分析站点结构,然后这个站及其子站基本就是你的了。
代码与其包含jar包已传到github:https://github.com/Bicycleful/javaCrawler