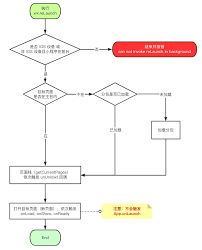
Mongodb 慢查询日志分析
使用 mloginfo 处理过的日志会在控制台输出, 显示还是比较友好的.
但是如果内容较大, 就不方便查看了, 如果可以导入到 excel 就比较方便筛选/排序. 但是 mloginfo 并没有提供生成到 excel 的功能. 可以通过一个 python 脚本辅助生成:
import pandas as pd
import re# 定义文件路径
mloginfo_output_file = "mloginfo_output.txt" # 假设已经保存了 mloginfo 的输出内容
excel_output_file = "mloginfo_slow_queries.xlsx"# 定义解析逻辑
def parse_mloginfo(file_path):parsed_data = []with open(file_path, "r", encoding="utf-8") as f:for line in f:# 跳过表头或空行if line.startswith("namespace") or not line.strip():continue# 用正则表达式解析每一行match = re.match(r'^(?P<namespace>\S+)\s+(?P<operation>\S+)\s+(?P<pattern>\{.*?\}|None)\s+(?P<count>\d+)\s+(?P<min_ms>\d+)\s+(?P<max_ms>\d+)\s+(?P<percentile_95>\d+\.?\d*)\s+(?P<sum_ms>\d+)\s+(?P<mean_ms>\d+\.?\d*)\s+(?P<allowDiskUse>\S+)',line)if match:parsed_data.append(match.groupdict())return parsed_data# 调用解析逻辑
parsed_data = parse_mloginfo(mloginfo_output_file)# 如果有数据,转换为 DataFrame 并保存为 Excel
if parsed_data:df = pd.DataFrame(parsed_data)# 转换数据类型(如数字列)numeric_columns = ["count", "min_ms", "max_ms", "percentile_95", "sum_ms", "mean_ms"]for col in numeric_columns:df[col] = pd.to_numeric(df[col])# 保存为 Excel 文件df.to_excel(excel_output_file, index=False)print(f"慢查询已成功保存到 {excel_output_file}")
else:print("未找到可解析的慢查询数据。")以下是一个更加完成的, 可以在命令参数中执行日志文件:
#!/usr/bin/env python
# -*- coding: utf-8 -*-import os
import re
import pandas as pd
import argparse# 设置命令行参数解析
parser = argparse.ArgumentParser(description="解析 mloginfo 输出并保存为 Excel")
parser.add_argument("log_file", type=str, help="mloginfo 输出文件路径")
args = parser.parse_args()# Step 1: 运行 mloginfo 命令,捕获输出
log_file = args.log_fileoutput_file = f"{log_file}.txt"excel_output_file = f"{log_file}.xlsx"os.system(f"mloginfo {log_file} --queries > {output_file}")# 定义解析逻辑
def parse_mloginfo(file_path):parsed_data = []with open(file_path, "r", encoding="utf-8") as f:for line in f:# 跳过表头或空行if line.startswith("namespace") or not line.strip():continue# 用正则表达式解析每一行match = re.match(r'^(?P<namespace>\S+)\s+(?P<operation>\S+)\s+(?P<pattern>\{.*?\}|None)\s+(?P<count>\d+)\s+(?P<min_ms>\d+)\s+(?P<max_ms>\d+)\s+(?P<percentile_95>\d+\.?\d*)\s+(?P<sum_ms>\d+)\s+(?P<mean_ms>\d+\.?\d*)\s+(?P<allowDiskUse>\S+)',line)if match:parsed_data.append(match.groupdict())return parsed_data# 调用解析逻辑
parsed_data = parse_mloginfo(output_file)# 如果有数据,转换为 DataFrame 并保存为 Excel
if parsed_data:df = pd.DataFrame(parsed_data)# 转换数据类型(如数字列)numeric_columns = ["count", "min_ms", "max_ms", "percentile_95", "sum_ms", "mean_ms"]for col in numeric_columns:df[col] = pd.to_numeric(df[col])# 调整列顺序,将 pattern 列移到最后columns = [col for col in df.columns if col != "pattern"] + ["pattern"]df = df[columns]# 保存为 Excel 文件df.to_excel(excel_output_file, index=False)print(f"慢查询已成功保存到 {excel_output_file}")
else:print("未找到可解析的慢查询数据。")